一种基于局部异常因子(LOF)的k-means算法
2016-07-06青岛职业技术学院山东青岛266555
陈 静,王 伟(青岛职业技术学院,山东青岛,266555)
一种基于局部异常因子(LOF)的k-means算法
陈 静,王 伟
(青岛职业技术学院,山东青岛,266555)
摘要:聚类分析算法是数据挖掘技术的一个重要分支,目前其研究已经广泛应用于教育、金融、零售等众多领域并取得了较好的效果。本文结合了基于划分和密度的聚类思想,提出了一个适用于挖掘任意形状的、密度不均的、高效的聚类算法。
关键词:数据挖掘;聚类算法;局部异常因子
0 引言
随着数据挖掘技术应用领域越来越广泛,聚类分析也接受着各种严峻的“考验”:处理的数据类型的多样化,对大数据集进行高效处理的迫切需求,对任意形状聚类的有效识别等等。这些都要求聚类算法能够具体高效、灵活等特点,因此,寻求一个高效、灵活的聚类算法,是研究人员的当务之急。
1 聚类算法
聚类分析方法是数据挖掘技术应用最广泛的算法之一。在机器学习领域,聚类分析算法属于无指导型学习算法。给定一组对象,聚类分析自动地将其聚集成k个集群,每个集群中的对象具有极高的相似度,而属于不同集群的对象间的相似度很低。因此,聚类分析挖掘算法在科学和工程的各个领域,包括生物信息学、市场分析、图像分析、网络搜索等起着极其重要的作用。目前提出了很多聚类算法,例如分割的方法、层次的方法、基于密度的方法等。但是这些聚类方法主要存在如下的问题:
1)符号属性:大部分聚类方法因为是基于欧氏距离的,所以只能处理数值属性的数据;
2)初值的选择对聚类算法的最终结果有很大的影响;
3)算法对输入参数存在依赖性。
这些问题的存在使得研究高正确性,低复杂度的聚类方法迫在眉睫,这也是今后聚类分析的研究方向。因此,本文提出了基于局部异常因子(LOF)的k-means算法,该算法适用于任意形状、大小和密度的群体聚类。
2 基于局部异常因子(LOF)的k-means算法
基于局部异常因子的初始聚类中心选择算法,利用了基于线性的运行时间的k-means算法,同时避免了该算法的缺陷。为了获得任意形状的簇,将要聚类的任意形状划分为凸形,这种方法是基于计算几何的凸分解的概念。一个凸分解即是一个划分,如果片重叠,则是覆盖区域。根据形状的复杂性,应尽量减少中心点的数目,而且各中心所覆盖的空间仍能构成一个集群。本文采用迭代式的基于局部异常因子(LOF)的k-means方法来寻找近似最优中心点。
基于局部异常因子(LOF)的k-means算法的伪代码如下所示:
LOF-k-means(D,K, mp):
1.Cinit=seed_center_initialization(D,k,mp)
2.Cseed=K-means(Cinit, k)
3.For every two nearest pairs(Ci, Cj)∈Cseed* Cseed
4.DA(i,j)=density _arrived(Ci,Cj)
5.If DA(i,j)& DA(j,i)is True
6.Merge(Ci, Cj)produced new Cluster Cn
7.Cluster_centers(Cseed,DA)
该算法有三个参数:D是输入数据集;参数 k代表初始中心点的数目;mp定义了初始中心点必须满足的条件——最近邻点数,通过限制最近邻点的数目来避免选择离群点为中心。
LOF-k-means算法的第一阶段如上伪代码所描述的第1-2步。这个阶段涉及到运行k-means算法的初始中心选择Cinit,直到收敛为止,得到最终初始中心点集群Cseed。在此步骤中,算法初始仍然是随机选择中心点,但是在迭代过程中,使用集群中最接近中心平均值的数据点而不是k-means每一次迭代中的平均值。为了避免这种情况,改进后的算法的初始化考虑局部异常因子LOF(Local Outlier Factor),通过局部异常因子LOF来选择初始聚类中心。
对于点x∈D,给定一个最小阈值mp,定义x点附近的邻近点如下:

其中,y为x的mp个点内的一点。因此N(x, mp)包含至少mp个数据点。基于mp的x密度计算如下:
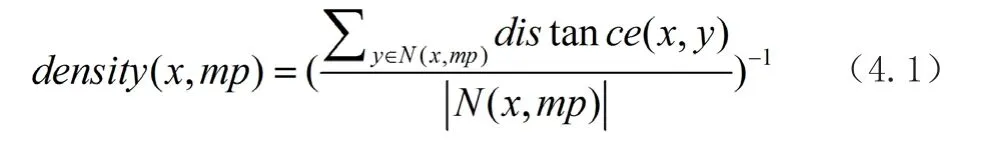
从本质上讲,x和相邻点之间的距离越近,x的密度越高。基于mp的x的平均相对密度(ard)被计算为x的密度比率和其近邻的平均密度,计算公式如下:

最后,局部异常因子LOF定义为平均相对密度的倒数。

LOF值更为准确地表示了一个点在何种程度上属于离群点。一个属于某一集群的点,其LOF值约等于1,这是由于它的密度与它邻近点的密度大致相同。

图4.1 基于LOF的初始聚类中心选择Fig. 4.1 LOF-based Clustering Seed Selection
图4.1所示为基于LOF选择初始中心点的结果展示。
为了获得高质量的聚类结果,相邻的两个集群会进行合并操作以得到最终的k个自然集群。假设点A被选择作为一个伪中心点。为了将点B分配到除以A为中心点的集群中,应该存在另一个中心点比cdistmin距离更接近于B。距离B点的任何小于cdistmin的值都属于集群B。如果数据集被分布到一个二维区域A,则K的值可由给出,其中式是一个对中心点周围聚类面积的近似值,无需精确地进行计算。
4 算法实验分析与验证
本文提出的LOF-K-means算法由C++语言实现。采用监督度量机制,通过一个已知的先验的真实聚类同时结合聚类纯度来评价聚类结果的质量。给定真实的集群Ct={c1,c2,…,cl},由LOFK-means算法产生的聚类Cs={s1,s2,…,sm},纯度由以下公式给出:

其中,N为数据集中包含的点数,纯度的取值范围在[0,1],一个完美聚类其纯度值为1。
聚类质量实验选择在数据集DS-4上进行。图4.2为改进后算法在定义的不同聚类中心个数时的纯度得分。实验设置的聚类中心个数从60到540不等,从图中可以看出,基于LOF的聚类算法的聚类质量受初始参数K的影响不大,其纯度得分均在0.8以上,均可以达到良好的聚类效果。这一点,也是基于LOF的聚类算法优于其它算法之处。
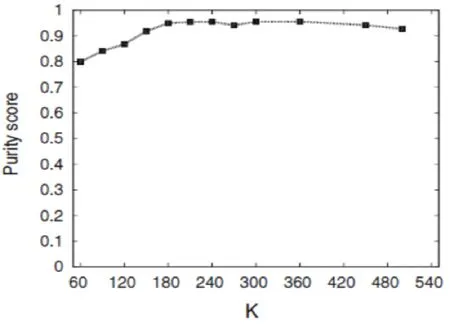
图4.2 基于不同K值的聚类质量Fig. 4.2 Cluster quality based on Varying of seedclusters
5 结束语
聚类分析是数据挖掘的一个重要的研究领域,国内外都对其研究及应用倾注了大量的关注。为了得到更加精确的聚类结果,更准确地应用于实际业务当中,研究者对聚类分析算法在各个方面都进行了大量的改进,更不乏将其它领域的算法应用于聚类分析算法,将两者或多个算法结合,这也表明,将算法进行融会贯通,应用于特定行业,也是未来聚类分析研究的热门方向。
参考文献
[1]《数据挖掘中聚类分析算法研究与应用》, 严勇, 软件工程,电子科技大学.2007
[2]Sack JR, Urrutia J(2000)Handbook of computational geometry. North-Holland, Amsterdam.
[3]Chazelle B, Palios L(1994)Decomposition algorithms in geometry. In: Bajaj C(ed)Algebraic geometry and its applications. Springer, Berlin:419-447.
A k-means algorithm based on local outlier factor(LOF)
Chen Jing,Wang Wei
(Qingdao Technical College,Qingdao,Shandong,266555)
Abstract:Cluster analysis is an important research field in data mining,at present,the research has been applied to the financial, retail and other fields, and have achieved good results.This paper studied partition and density clustering algorithm, proposed a new algorithm which is suitable for mining arbitrary shape and uneven density.
Keywords:Data Mining;Clustering algorithm;Local Outlier Factor
