爬虫技术在互联网领域的应用探索
2016-07-04杨青松
杨青松
摘要:随着云计算和大数据技术的深入发展,网页上的大量结构化和非结构化的信息搜索和挖掘技术成为一个热点研究问题。该文首先探讨了爬虫技术在互联网领域的应用情况,尤其针对互联网金融信息数据的获取和搜集上目前研究的难点问题,进一步针对三种网络爬虫技术的搜索技术进行比较分析,对深度优化搜索和广度优先搜索进行理论分析,继而对一种改进算法——最好优先搜索方法进行JAVA程序实现,运用到的多线程技术可以提高程序的搜素效率。
关键词:爬虫技术;互联网;JAVA多线程;网页挖掘
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)15-0062-03
1 引言
随着云时代的来临,大数据的发展也越来越成为一种潮流。大数据通常用来指公司创造的大量结构化和非机构化化数据,这些数据被获取并存放到关系型数据库,在分析数据时往往会花费大量的时间和精力。“大数据”在互联网领域是指:互联网公司在正常运行过程中会生成、累积用户行为的网络数据。这些数据的规模是非常庞大,甚至大到不能用G或T的计量单位来衡量。在大数据时代,爬虫技术成为获取网络数据的重要方式。
互联网金融发展过程中需要搜集大量的数据资源,这个过程非常关键,并且实施起来较为困难。金融数据的搜集,是通过计算机技术与金融领域相关知识的综合,将金融经济的发展与相关数据进行集中处理,能够为金融领域的各个方面如经济发展趋势、经融投资、风险分析等提供“数据平台”,真实的数据资源还可以推进金融经济的快速发展和金融理论的创新。当今互联网的快速发展,网络上也充满各种金融信息,并且更新速度快,这使互联网成为金融领域获取数据资源重要一大方式。例如Butler,Leone,Willenborg和 Frank等公司都是利用互联网采集技术来抓取所需的数据资源。
2 互联网金融数据抓取的特点
2.1 互联网上金融方面的数据一般具有的特点
1)数据量大、种类繁多。对于一些规模较小且只需抓取一次的数据,一般复制粘贴或者手工记录即可,没有什么技术上的要求。但是,金融经济市场领域的数据一般规模巨大,例如需要获取某个结构一年的交易记录,数据量就是非常大的,而且数据资源往往来源于不同的机构或者不同的部门,想要准确地获取数据资源不是很容易。
2)可靠性、实时性。在研究金融理论或者做金融分析时,对数据的可靠性、实时性要求非常高。金融经济的发展模式瞬息万变,更新速度很快,为了及时的反映市场上经济发展状况,要求数据的来源具有实时性和可靠性。
3)金融经济领域的数据类型一般以文本和数值型为主,图片和视屏等多媒体类型的数据较少。
4)数据一般会从较官方的网站抓取。为了保证数据来源的可靠性和准确性,数据一般从较权威的机构获取,例如金融交易所、国家有关权威决策与信息发布部门和国内外各大互联网信息提供商。
5)抓取数据的目标网页主要有两种类型。第一类是URL固定但是信息实时更新的网页要定期访问并获取数据,例如一些网站的股票行情类数据;第二类是规模较大且近似网页中具有固定特征的数据。例如某些国家权威机关按时以某一固定格式发布各种数据报告。
我们可根据金融经济数据的这些特点,制定相应的方法与策略抓取数据资源。对于地址相对固定的网页,所面临的数据采集问题比较集中,不需要考虑各种技术因素的变化对采集的影响,我们可以更有针对性的收集数据,制定更高效、更合理的抓取策略。
2.2 获取网页信息
目前主流的网站开发技术主要有php、net和java的Alexa等,虽然说开发的网页格式五花八门,但它们传输数据的原理都一样,都是通过超文本传输协议(HTTP协议)将数据资源传送到客户的。微软公司提供的可扩展标记语言(XML)服务集合中的组件 MSXML(执行或开发xml所设计的程序)里面有个 XMLHTTP浏览器对象。该对象的原理基于HTTP 协议的,里面封装着很多方法和属性,这些方法和属性与网站信息双向交流有关。客户端调用 XMLHTTP对象搜集网页信息的过程主要包括以下几个步骤:
①首先建立XMLHTTP对象;
②利用XMLHTTP对象里面的Open方法与服务端建立连接,制定网页的地址(URL)和命令的发送方式;
③通过XMLHTTP中的Send 方法发送信息;
④等待服务端处理并返回结果。
数据的抓取在金融领域的研究中是一个关键环节。互联网中的数据具有规模庞大、实时性、准确性等特点,为金融经济的发展提供了重要的数据来源。通过爬虫技术抓取数据资源,可以高效的在互联网海量的数据中提取所需的数据资源。灵活而方便地定制抓取数据地方案,使抓取到的数据成为金融经济发展的可靠保证。
3 爬虫技术的实现
爬虫技术的设计是搜索引擎实现的关键技术,爬虫算法的好坏直接关系到搜索引擎性能的优良。经过多方面研究表明,“最好优先算法”应用于多重搜索中效果较好,但是这个算法本身也存在缺陷,例如收敛速度过快致使搜索的数据不全面,“查全率”太低。基于这个问题,本文研究如何改进这种算法,并实现网络爬虫。
3.1 网络爬虫的算法分析
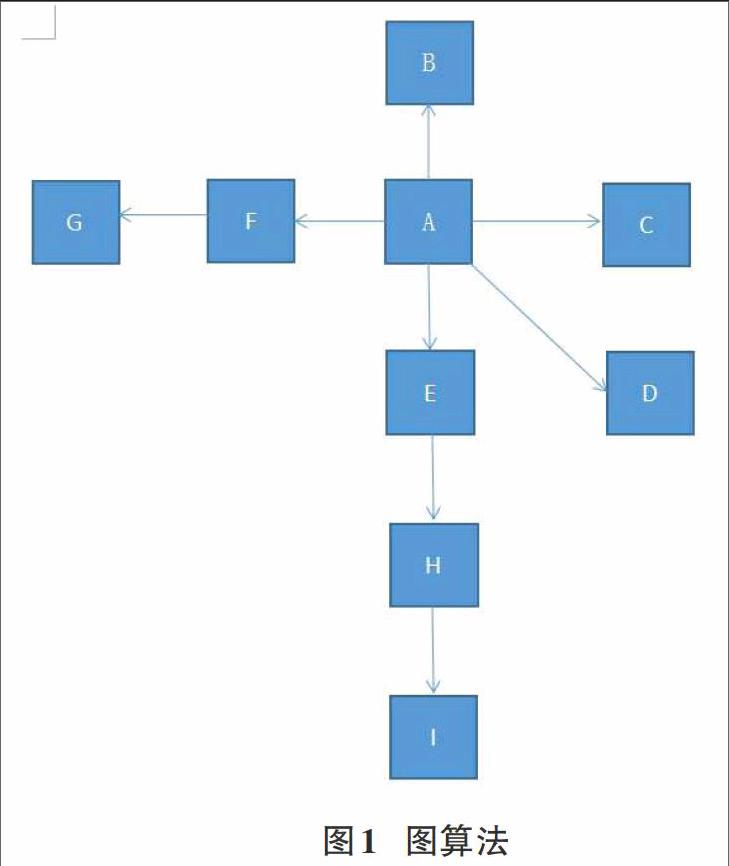
爬虫在整个网络系统中自由搜索,能够自动识别URL,自动下载网页,并提取数据信息,存放到数据库中。整个过程都不需要人工的参与。当前主流的爬虫算法主要有广度优先算法、深度优先算法和最好优先算法等。传统的图算法主要应用在第一代web爬虫索引整个网络,该算法是以一个网页链接集作为核心,去递归的链接其他的网络页面,不关心网络中的数据内容,只追求在网络上最大的覆盖率,网页的个数越多越好。算法如图1所示。
3.1.1 深度优先搜索算法
深度优先搜索算法(DFS)在研究爬虫技术早期使用较多,它的搜索目标是要到达结构的最外结点,即搜索到不包含超链接的HTML文件。在一个网页中,当一个链接被选择后,链接的HTML文件执行DFS算法,完整的沿着一条链接搜索,走到边缘节点为止(即不包含任何链接的HTML文件),然后返回上一个页面链接的但是未搜索过的页面,再沿着这个搜索到的页面执行DFS算法即可。直到所有连接到的页面被搜索完成,算法结束。DFS算法的优点是能根据一个HTML文件查找到其所链接的所有HTML文件,能查出这个网页在互联网中的链接结构。但是DFS算法也有很大的缺点,因为整个网络的结构是非常深的,各个网页之间的链接关系也很复杂,很有可能陷入其中就无法返回。对于图4-1中的结构,使用深度优先遍历算法的返回结果是:A-F-G;E-H-I;B;C;D。
3.1.2 宽度优先搜索算法
广度优先(BFS),也叫宽度优先,在这里的定义就是层层爬行,沿着结构的宽度方向层层搜索。给定一个网页的URL时,首先搜索这个URL所链接的所有网页,遍历完这网页链接的所有网页之后,再遍历子网页所链接的所有网页,直至遍历完所有的网页为止,一般采用BFS策略来覆盖范围更广的网页。广度搜索相对于深度搜索,对数据抓取更容易控制些。对服务器的负载相应也明显减轻了许多,爬虫的分布式处理使得速度明显提高。而且BFS算法能够找到两个网页之间的最短路径,并且不会像DFS那样使程序陷入深层查找无法返回。缺点查找深层网页时效率较低。对于图4-1中的机构,BFS算法的访问顺序为A-B;C;D;F-G;E-H-I。
3.1.3 最好优先搜索算法
最好优先搜索(Best-First)是宽度优先搜索的扩展,基本算法思想是将各个节点表按照据目标的距离排序,再以节点的估计距离为标准选择待扩展的节点。
搜索过程为:
1)先建立一个搜索图G,里面包含初始节点集合S,open=(S), closed=()表示空表;
2)若集合open为空,则查找失败,并退出程序;
3)n = first(open); remove(n, open); add(n, closed);
4)若 n为目标结点,则查找成功 ,并可给出S到n的路径;
5)否则,扩展结点n, 生成不是n的祖先的后继结点集M={m} 把每个m作为n的后继结点加入G;
6)If m没有在open和closed集合中出现过Then add(m, open);
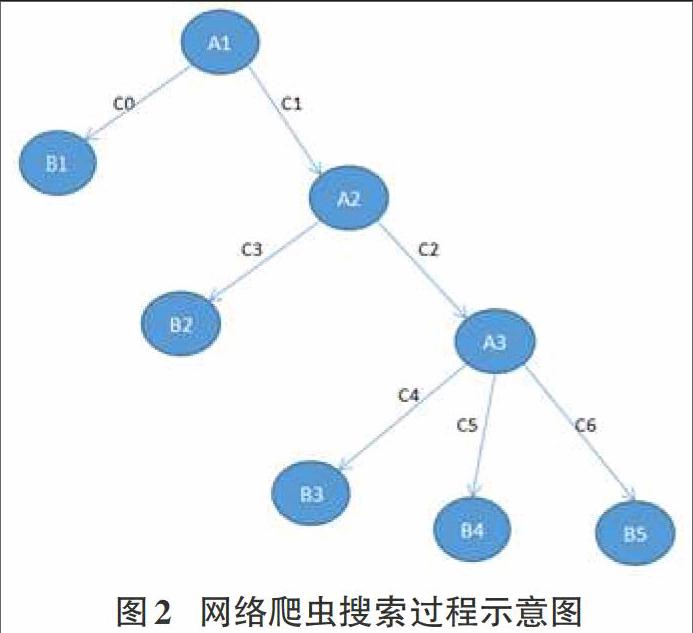
7)If m在open集合中有重复结点k,且g(m) 8) If m在closed集合中有重复结点k,且g(m) ①将closed集合中的结点k改为结点m(只需修改主链指针和f、g); ②按后继元素,修改k在open集合和closed集合中的后继元素f,g的值; 9) 按f值,按从小到大的顺序对open表中的结点排序,并重新返回到2步。 这些算法虽然都有各自的优点,但是它们的综合性能都不是很优。本文对这些算法进行了测试,结果表明最好最优搜索算法在爬虫技术应用上性能最佳。所以重点对Best-First算法进行研究并发现,虽然算法查找网页的准确率很高,但是由于算法存在收敛速度过快的缺点,使得不能在较大规模的网络上全面查找数据,即“查全率”太低。如何设计程序,提高最好最优算法的“查全率”才是网络爬虫技术实现的关键问题。 3.2 算法改进 对图2中的网络模型进行最佳优先算法的搜索,假设A1,A3,B1,B2,B3,B4,B5是相关的URL,A2是干扰页面,网络爬虫从A1开始查找。算法思想是:爬虫程序经过一定的计算,如果发现A2是不是查找目标,但是发现A1是要查找的网络页面,程序就会把A2的链接直接忽略掉,沿着A1的链接继续搜索。这样就会导致A3、B2、B3、B4、B5这些相关的页面被爬虫程序给忽略掉,从而大大降低了搜索效果,不能时爬虫全面搜索整个网络页面。 其中:A1、A3、B1、B2、B3、B4、B5是相关页面; A2是干扰页面; C0、C1、C2、C3、C4、C5、C6是访问路径。 本文提出的改进算法思想是,当查找到A2页面时,虽然这个页面与主题无关,但程序并不忽略这个链接,而是暂时保存起来,然后爬虫程序计算A2所链接的页面中是否存在需要用户需要查找的页面。算法设定一个参数f记录crawler在遇到干扰页面的链接时搜索的深度。只有当爬虫程序在搜索到f深度仍然没有发现所需要的页面,这时才会A2页面忽略掉。例如在上图中,如果爬虫经过c2、c3、c4、c5、c6这几条路径能够找到相关页面,就说明A2这个网页包含很多所需要的网页链接。根据这个思想,对最好优先搜索算了进行改进,以提高爬虫程序的“查全率”。改进算法利用了JAVA中的多线程机制,核心算法如下: BF-BF(topic,starting-urls){ link_1=fetch link(starting_url); While(visited doc=fetch(link_1); if(score_r1>r1) { enqueue_1(frontier,extract_links(doc),score_r1); } else {score_r2=link_score_r2(D,links); if(score_r2>r2) enqueue_1(frontier,extract_links(doc),score_r2); else enqueue_2(links); }}} 4 结束语 本文阐述了爬虫技术在互联网中的应用,并以爬虫搜索方法为研究目标,通过Java多线程对其中的最好最全算法进行算法实现。随着硬件技术、信息技术和物联网技术的不断发展,未来必将会出现大规模基于网页信息攫取的算法设计,各种新型的网络应用协议也会不断问世,这些技术成果都将极大地促进各类异构网络的融合过程,进一步提高计算机通信网络的数据分析功能。 参考文献: [1] Otis Gospodnetic,Erik Hatcher.Lucene IN ACTION[M]. Manning Publication Co,2006. [2] 袁津生,李群. 搜索引擎基础教程[M]. 清华大学出版社,2010. [3] 刘兵. Web数据挖掘[M]. 余勇,等,译.北京:清华大学出版社,2009. [4] Ricardo Baeza-Yates等.现代信息检索[M]. 王知津,等,译. 北京:机械工业出版社,2005. [5] 龚秋燕.并行网络爬虫设计与实现[D],上海:华东师范大学,2010.
