基于Spark的大数据处理平台的搭建与研究
2016-07-04许礼捷


摘要:该文阐述了Spark处理技术在大数据框架上的性能提升优势,分析了BDAS生态系统框架中Spark的任务处理流程图。详细说明了Spark集群的搭建过程和运行状态,并通过Spark Shell的交互界面进行交互式编程,实现对文本内容中单词出现次数的统计。
关键词:大数据; Spark; 集群; Yarn; 交互式编程
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)15-0014-03
Abstract: The performance advantages of Spark processing technical in big data framework is described, the process flowchart of Spark in the framework of BDAS ecosystem is analyzed. The construction process and running state of Spark cluster are described in detail.Statistics on the number of words in the text content by interactive programming through the Shell Spark interactive interface.
Key words: big data; spark; cluster; yarn; interactive programming
随着计算机和信息技术的迅猛发展和普及,传统的计算技术和信息系统的处理能力已经无法满足数百TB甚至数十到数百PB规模的行业企业大数据,因此,处于大数据时代的今天,更为高效的大数据处理技术、方法和手段取得了巨大的发展。
1 大数据处理技术概述
Hadoop和Spark两者都是大数据框架。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件。而Spark是基于内存计算的大数据并行计算框架,它基于内存计算。相比Hadoop MapReduce,Spark在性能上提高了100倍[1],不仅提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性。
Hadoop的MapReduce在过去10年的时间成了大数据处理的代名词,而Spark作为一个崭新的大数据生态系统,逐渐取代传统的MapReduce而成为新一代大数据处理技术。以下通过Spark集群大数据处理平台的搭建与测试来进行研究。
2 Spark技术分析
2.1 Spark生态系统BDAS
目前Spark已经发展成为包含众多子项目的大数据计算平台。伯克利将Spark的整个生态系统成为伯克利数据分析栈(BDAS),其核心框架就是Spark,其他子项目在Spark上层提供了更高层、更丰富的计算范式。BDAS结构框架,如图1所示。
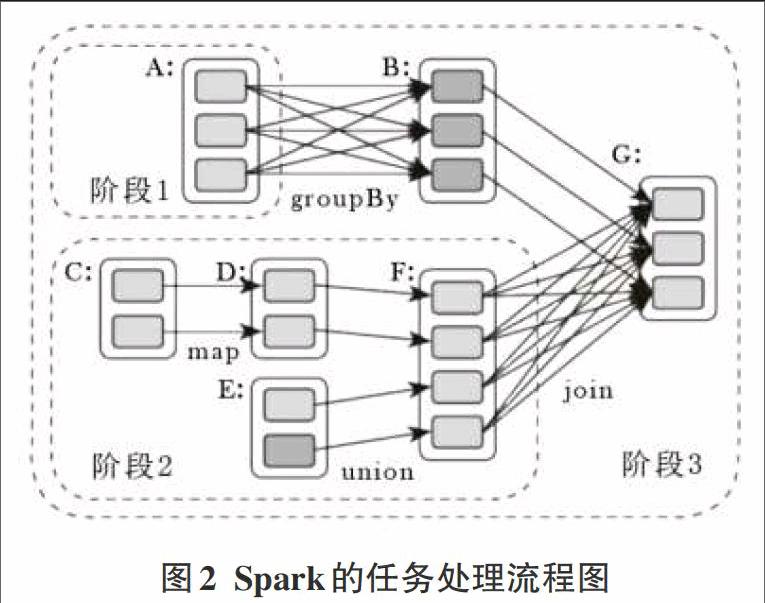
2.2 Spark的任务处理流程图
Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。Spark将分布式数据抽象为天性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala函数式语言编写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。如图2为Spark的任务处理流程。
3 Spark集群的安装与部署
实际应用中,Spark主要部署在Linux系统的集群中。如果要完整使用Spark,需要预先安装Hadoop,因此在Linux系统中安装Spark需要预先安装JDK、Scala等依赖。以1个Master节点和3个Slave节点进行部署,首先在主节点和子节点上完成基础步骤的安装,包括:JDK安装、Scala安装、配置SSH免密码登录、Hadoop安装配置及启动[3],然后再开始进行Spark集群的安装与部署。
3.1 Spark集群的搭建
已经完成基础安装的1个主节点和3个子节点IP地址分别为:Master:10.230.10.160;Slave1: 10.230.10.161;Slave2: 10.230.10.162;Slave3: 10.230.10.163。
1)下载并解压Spark安装文件
从官网下载spark1.3.1安装文件(集群采用的软件版本是Hadoop2.6.0和Spark1.3.1),并在主节点Master的usr/local/spark/spark1.3.1的目录下,解压下载好的spark-1.3.1-bin-hadoop2.6.tgz。命令行如下:
[root@Master ~]# tar -xzvf /root/down-spark/spark-1.3.1-bin-hadoop2.6.tgz /usr/local/spark
并将释放后的文件夹名改为spark1.3.1。
2)配置spark的环境变量
配置Spark的环境变量,使用命令行:vi /etc/profile
在profile文件最后添加:
## SPARK
export SPARK_HOME=spark的绝对路径(此处是:/usr/local/spark/spark1.3.1)
export PATH=$PATH:$SPARK_HOME/bin
然后保存退出
并重新运行profile,使其生效。命令行:
[root@Master spark1.3.1]# source /etc/profile
3)配置spark的相关文件
(1)slaves文件的配置
拷贝conf/slaves.template为slaves,并使用vi命令编辑slaves,将Worker节点添加进去。添加子节点slave名称的内容如下:
Master
Slave1
Slave2
Slave3
(2)spark-env.sh的配置
进入Spark的conf目录,将spark-env.sh.template拷贝到spark-env.sh,并编辑该配置文件,将各种路径添加进去。命令行:vi spark-env.sh。向文件添加:
export JAVA_HOME=Java安装的绝对路径(此处:/usr/lib/java/jdk1.8.0_45)
export SCALA_HOME=Scala安装的绝对路径(此处:/root/app/scala2.10)
export HADOOP_CONF_DIR=hadoop环境下的配置文件目录etc/hadoop的绝对路径(此处是:/usr/local/hadoop/hadoop-2.6.0/etc/Hadoop)
export SPARK_MASTER_IP=主节点IP或主节点IP映射名称(此处是:Master)
export SPARK_MASTER_PORT=主节点启动端口(默认7077)
export SPARK_MASTER_WEBUI_PORT=集群web监控页面端口(默认8080)
export SPARK_WORKER_CORES=从节点工作的CPU核心数目(默认1)
export SPARK_WORKER_PORT=从节点启动端口(默认7078)
export SPARK_WORKER_MEMORY=分配给Spark master和 worker 守护进程的内存空间(默认512m)
export SPARK_WORKER_WEBUI_PORT=从节点监控端口(默认8081)
export SPARK_WORKER_INSTANCES=每台从节点上运行的worker数量 (默认: 1)
该配置文件中的yarn部署是按照spark配置文件的默认部署的,如果想根据实际情况来部署的话,可以做相应的修改。
(3)Spark文件复制
将配置好的Spark文件复制到各个子节点slave对应的目录上:即将spark下的spark1.3.1拷贝到子节点的对应目录上。
[root@Master spark]# scp -r ./spark1.3.1/ root@Slave1:/usr/local/spark
[root@Master spark]# scp -r ./spark1.3.1/ root@Slave2:/usr/local/spark
[root@Master spark]# scp -r ./spark1.3.1/ root@Slave3:/usr/local/spark
至此,Spark集群的安装搭建基本完成。
3.2 Spark On Yarn的集群启动
(1)Yarn的启动:
先进入hadoop目录下,运行命令 ./sbin/start-all.sh,然后运行jps命令检测yarn是否正常启动,如果发现有ResourceManager进程,说明yarn启动完成
(2)Spark的启动
先进入spark目录下,运行命令 ./sbin/start-all.sh,然后运行jps命令检测spark是否正常启动,如果发现主节点有Master进程,子节点有Worker进程,说明spark启动完成。
(3)Spark集群监控
Spark启动之后,可以通过Web查看Spark集群的运行状态,一般都是masterIP:8080,如果打不开监控页面,则要检查一下防火墙有没有禁用。
如图3所示,通过监控页面,可以看到由1个Master节点和3个Slave节点组成的Spark集群已经正常运行。至此,Spark On Yarn的集群搭建完成。
3.3 Spark集群控制台
(1)在Master端,进入spark-shell控制台
启动spark on yarn集群后,进入Spark的bin目录,使用spark-shell进入控制台,命令行为:[root@Master bin]# ./spark-shell ,执行后出现操作符提示scala>。
而如果要在spark 客户端(在 Slave节点),使用 spark-shell 连接集群,以Slave1为例,在子节点进入spark-shell控制台的命令行:
[root@Slave1 bin]# ./spark-shell --master spark://Master:7077 --executor-memory 1g
说明:其中的“--executor-memory 1g”,根据实际内存情况进行分配
(2)查看SparkUI情况
进入Spark的shell世界,根据输出的提示信息,可以通过 http://Master:4040,从Web的角度看一下SparkUI的情况。包括:集群的Jobs、Stages、Storage、Environment、Executors等信息。
4 Spark集群的测试
完成Spark集群的搭建之后,可以通过Spark Shell的交互界面进行交互式编程[4],以下实例是对HDFS系统上的一个文本文档readme.txt,统计一下“Spark”一共出现了多少次。
在Spark Shell交互界面 scala> 运行如下程序代码
val file = sc.textFile("hdfs://10.230.10.160:9000/usr/xu/test/readme.txt")
val sparks = file.filter(line => line.contains("Spark"))
sparks.count
最后从执行结果中我们发现“Spark”这个词一共出现了19次。
此时,我们查看Spark Shell的Web控制台,发现控制台中显示我们提交了一个任务并成功完成,点击任务可以看到其执行详情。
那如何验证Spark Shell对readme.txt这个文件中的“Spark”出现的19次是正确的呢?其实方法很简单,我们可以使用Linux自带的wc命令来统计,即如下命令:
[root@Master spark1.3.1]# grep Spark readme.txt|wc
19 156 1232
发现此时的执行结果也是19次,和Spark Shell的计数是一样的。
5 结束语
以上的Spark集群安装是在CentOS6.5操作系统上完成,集群采用1个Master和3个Slaves。在实际行业企业应用中,可以根据需要增加子节点数量,通过Spark进行大规模机器学习、图形计算以及流数据分析,以达到快速分布式计算的要求。基于Spark的应用已经逐步落地,尤其是在互联网领域,如淘宝、腾讯、网易等公司的发展已经成熟,同时电信、银行等传统行业也开始逐步应用Spark并取得了较好的效果。因此,在大数据分析平台中Spark技术将会得到更为广泛的发展和应用。
参考文献:
[1] 陈虹君.基于Hadoop平台的Spark框架研究[J].电脑知识与技术,2014(35).
[2] 高彦杰. Spark大数据处理技术、应用与性能优化[M] .北京:机械工业出版社,2015.12.
[3] 许礼捷.基于CentOS的Hadoop分布式集群的构建方法研究[J].沙洲职业工学院学报,2016(1):23-28.
[4] Spark编程指南[EB/OL].http://spark.apache.org/docs/1.3.1/programming-guide.html,2015.
