连续空间中的随机技能发现算法
2016-06-23栾咏红苏州工业职业技术学院江苏苏州15104苏州大学计算机科学与技术学院江苏苏州15006吉林大学符号计算与知识工程教育部重点实验室吉林长春13001
栾咏红,刘 全,章 鹏(1.苏州工业职业技术学院,江苏苏州 15104;.苏州大学计算机科学与技术学院,江苏苏州 15006;3.吉林大学符号计算与知识工程教育部重点实验室,吉林长春 13001)
连续空间中的随机技能发现算法
栾咏红1,2,刘全2,3,章鹏2
(1.苏州工业职业技术学院,江苏苏州215104;2.苏州大学计算机科学与技术学院,江苏苏州215006;3.吉林大学符号计算与知识工程教育部重点实验室,吉林长春130012)
摘要:针对大规模、连续空间随着状态维度指数级增加造成的“维数灾”问题,提出基于Option分层强化学习基础框架的改进的随机技能发现算法。通过定义随机Option生成一棵随机技能树,构造一个随机技能树集合。将任务目标分成子目标,通过学习低阶Option策略,减少因智能体增大而引起学习参数的指数增大。以二维有障碍栅格连续空间内两点间最短路径规划为任务,进行仿真实验和分析,实验结果表明:由于Option被随机定义,因此算法在初始性能上具有间歇的不稳定性,但是随着随机技能树集合的增加,能较快地收敛到近似最优解,能有效克服因为维数灾引起的难以求取最优策略或收敛速度过慢的问题。
关键词:强化学习;Option;连续空间;随机技能发现
0 引 言
强化学习[1⁃2](Reinforcement Learning,RL)是Agent通过与环境直接交互,学习状态到行为的映射策略。经典的强化学习算法试图在所有领域中寻求一个最优策略,这在小规模或离散环境中是很有效的,但是在大规模和连续状态空间中会面临着“维数灾”的问题。为了解决“维数灾”等问题,研究者们提出了状态聚类法、有限策略空间搜索法、值函数逼近法以及分层强化学习等方法[3]。分层强化学习的层次结构的构建实质是通过在强化学习的基础上增加抽象机制来实现的,也就是利用了强化学习方法中的原始动作和高层次的技能动作[3](也称为Option)来实现。
分层强化学习的主要研究目标之一是自动发现层次技能。近年来虽然有很多研究分层强化学习的方法,多数针对在较小规模的、离散领域中寻找层次技能。譬如Simsek与Osentoski等人通过划分由最近经验构成的局部状态转移图来寻找子目标[4⁃5]。McGovern和Batro等根据状态出现的频率选择子目标[6]。Matthew提出将成功路径上的高频访问状态作为子目标,Jong和Stone提出从状态变量的无关性选择子目标[7]。但是,这些方法都是针对较小规模、离散的强化学习领域。2009年Konidaris和Barto等人提出了在连续强化学习空间中的一种技能发现方法,称为技能链[8]。2010年Konidaris又提出根据改变子目标点检测方法[9]来分割每个求解路径为技能的CST算法,这种方法仅限于路径不是太长且能被获取的情况。
本文介绍了一种在连续RL域的随机技能发现算法。采用Option分层强化学习中自适应、分层最优特点,将每个高层次的技能定义为一个Option,且随机定义的,方法的复杂度与复杂学习领域的Option构建数量成比例。虽然Option的随机选择可能不是最合适的,但是由于构建的Option不仅是一个技能树还是一个技能树的集合,因此弥补了这个不足之处。
1 分层强化学习与Option框架
分层强化学习(Hierarchical Reinforcement Learn⁃ing,HRL)的核心思想是引入抽象机制对整个学习任务进行分解。在HRL方法中,智能体不仅能处理给定的原始动作集,同时也能处理高层次技能。
Option是Sutton提出的一种应用比较广泛的HRL方法,它对学习任务的分层是一个在状态空间上发现子目标和构造Option的过程[10]。Option方法是对MDP (Markov Decision Process)中的基本动作进行扩展,一个Option可以理解为到达子目标而定义在相关状态子空间上的按一定策略执行的动作或Option序列,即动作选择集[11]。
简单的Option直接定义在MDP上,由三元组o =I,π,β表示。其中s∈I为Option输入状态集,它包含且仅包含Option经历的所有可能状态,当且仅当智能体的当前状态s∈I时,Option才可以根据内部策略展开执行。π:S×A→[0,1]表示Option的内部策略;其中AI为I上可以执行的动作集;β:S→[0,1]是Option结束的终止判断函数,Option在某一状态s′依概率β(s′)终止,通常将Option要达到子目标状态sG定义为β(sG) = 1。每个Option在被执行时,动作的选择仅依赖于自身内部策略π,即智能体根据策略π(s,a)选择下一动作a作用于环境,使环境状态s转移到s′。
如果将策略定义在Option之上,即μ:S×OI→[0,1]。其中OI为状态集I上可以执行的Op⁃ tion集;I和β定义不变,则I,μ,β形成分层的Option,初始Option启动后,根据策略μ依次选择其他Option执行,直到根据终止条件β结束,被选中的Option可以按照各自的策略再选择其他Option执行。若将所有Op⁃tion都展开到基本动作层,则μ确定了MDP的一个常规策略,Sutton称其为与μ对应的平坦策略,记为flat(μ)。
利用单步Q⁃学习算法来对值函数进行学习,值函数的每次更新都发生在Option执行结束之后。Precup引入多时间步模型对传统的单步模型进行泛化[12],并证明在标准Q⁃学习收敛条件下,基于Option的Q⁃学习算法依概率1收敛到:
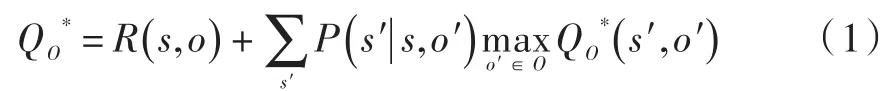
式中:R(s,o)为状态s下o的奖赏值;P(s′|s,o′)为状态转移概率。假设Option o在状态s开始执行了τ步后在状态s′终止,则Option值函数Q(s,o)的迭代算法如下:

式中:r为Option o在整个执行过程中的累计折扣奖赏值。
基于Option的自动分层方法一般分为两步:首先,通过对任务状态空间的分割得到各子任务的状态集合;然后,再在此状态集上采用强化学习方法学习相应的策略[12⁃13]。学习新的Option算法必须包括确定何时创建一个Option或展开它的起始集,如何定义它的终止条件(技能发现),以及如何学习它的策略的方法。策略学习通常是由一个离策略强化学习算法,使得智能体可以在采取动作后同时更新多个Option[14]。
2 随机技能发现算法
在小规模状态空间或离散状态空间的强化学习任务中,可以通过层次将学习任务分解成一系列的子目标,它们的终止状态是在关键路径中,这些关键的状态可以由设计者定义,但是当环境为连续或大规模时,面临大空间的MDP任务时,将会带来很大的计算代价。因此,在连续状态空间中提出了一种随机技能发现算法(RSD),该算法引入随机Option和随机的技能树(Skill tree),在算法中对其进行形式化。
2.1随机Option
Option创建与终止通常都是由目标状态识别完成的,它可以创建一个目标状态,并在结束时终止它。
定义1随机Option对于一个给定的输入集(状态空间区域),定义o的终止状态和奖赏函数。假定目标状态为So,其中对于所有的s∈So至少有一个a∈A,使得s′∉Io(其中,s′是在状态s处执行动作a得到的下一个状态)。换句话说,终止状态是由输入集Io的前端定义的。设置o的奖赏函数是Option启动下一个Op⁃tion完成所获得的奖赏。
使用标准强化学习算法来学习o的策略,采用一个线性函数逼近器与一套合适的基函数来表示Option的值函数,如式(3)所示。

式中:ω∈Rn为n维的参数向量;ϕ(s,a) = [ϕ1(s,a) ,ϕ2(s,a) ,…,ϕn(s,a)]T为状态动作对(s,a)的n维特征向量;ϕ1(s,a) ,ϕ2(s,a) ,…,ϕn(s,a)称为基函数(Ba⁃sis Functions,BFs)。
Option学习中只在一个Option结束时更新,有时无法确定目标状态是Option的终止状态,也就说存在一些非终止的Option,其目标状态是包含在输入集中的。在本文算法中采用了intra⁃option模型。只考虑Markov⁃Option模型o =I,π,β的intra⁃option学习,则状态Op⁃tion对(s,o)的值函数计算如式(4)、式(5)所示。

式中:r是在状态s′处的立即奖赏;s′是在状态s处执行动作a得到的下一状态。
根据式(3)~式(5)可以从状态空间区域中得到所有的样本。由于o的奖赏函数是根据它临近Option设置的,则它的学习策略可以在临近Option的值改变时被更新。随着状态求解路径的不断规划,最终只有在求解路径中的那些状态可以被导航到学习的策略,而在终止状态中剪掉的状态不会包含在求解路径中。
2.2随机技能树
本文介绍的随机技能树(Random Skill tree)是一个自上而下的,首先从单个子集的划分开始,然后逐步重新定义子集并进行划分。它不同于RL中经典树的方法,技能树中的每个叶子节点不仅表示某个区域的值同时也表示了从某个空间区域的一个Option < I,π,β>。每个Option都有自己的线性函数逼近器集中在状态空间的一个子集中。对于某个指定的连续空间来说,一个随机的技能树开始于一个Option,即树的根,它的输入集包含了整个空间。整个技能树的建立通过不断地对节点不同方向的随机选择、并对每个随机方向选择一个随机样本点进行预分割,将输入集划分为2个子集,而新的Option如同原来描述的一样(但是对于包含目标状态的区域,非终止的Option将会被建立),直到满足终止条件。从训练集中建立一个随机技能树的过程,每个节点的剪切点和剪切方向都是随机选择的。定义终止条件为训练集的大小,即为每个空间区域中的#TS。如果#TS≤nmin,则停止划分Option节点,其中,nmin是用于划分节点训练集的最小尺寸。建立随机技能树的过程如算法1所示。
算法1:Build_a_tree(TS,D)
输入训练集TS,状态空间D;
判断#TS≤nmin成立时;
Step1:如果目标状态不包含在状态空间D,则返回一个Op⁃tion o < I,π,β>,where I:{s|s falls in D};β:{s|s∈I and ∃as′∉I};
Step2:否则根据式(4)、式(5)建立一个非终止的Option;
随机分割状态空间D为两个子区域D1和D2,同时训练集合TS分割为TS1和TS2;
根据分割后的样本集TS1和TS2,递归调用算法1建立技能树T1和T2;
创建节点,令T1和T2作为该节点的左右子树,并返回该节点。
该算法首次被调用是建立整个任务的一个随机技能树,所以第一次调用TS和D分别表示整个训练集和整个状态空间。然后这个树将通过递归调用算法来建立。
2.3RSD算法描述
针对给定的一个训练集,RSD算法建立随机技能树集合,参数为M。每个集合都是在整个训练集中建立的,如第2.2节中所描述的,这个训练集是从单个路径中或者在整个状态空间中随机获取的。对于一个状态来说,有M个Option可以采用,其中每个Option集合都覆盖整个任务。RSD算法的学习规则,对于无法确定目标状态是某些Option的终止状态,采用式(4)、式(5)学习Option内部策略,生成Option。RSD算法描述如下所示。
算法2:随机技能发现算法(RSD算法)

Step3:根据式(6)使用TSN计算基函数权重,确定QN(s,o)。
在本文中,由于考虑的是连续状态空间,主要集中在以大量的数值型输入变量和单个的目标变量为特征的离线学习问题上。当值函数逼近模型为线性模型时,典型的离线训练方法一般采用最小二乘回归方法来求解。最小二乘回归是在一定的样本集合下,以最小化目标函数估计值与真实值之差的平方和为目标的回归优化问题。在这个算法中,计算了采用最小二乘方法得到的基函数权重,它的目标是获得合适的权重去最小化真实数据和模型之间的最小二乘误差,等价于最小化下面的表达式:

3 实验结果与分析
为了验证所提出算法的性能,实验采用10×10的连续不规则障碍栅格空间内两点间最短路径规划为任务背景,如图1所示。目标状态就是图1中的红色格子,黑色栅格表示障碍物,其他网格为可以通行的区域。学习任务就是找到智能体各个状态到达目标状态的最优动作策略。在每个位置,智能体有4个可能的动作:向右、向左、向下和向上。当这些动作执行完毕后,智能体都会以概率1移动到下一个位置上。如果移动的方向是有障碍物的,则智能体仍然在同一位置上。智能体达到目标时,就能得到一个立即奖赏为+1,否则得到的立即奖赏为0。

图1 连续的有障碍栅格空间
在此比较三个智能体:一个是在连续域中采用原始动作;一个是采用RSD算法中技能发现;一个是在学习之前使用已定义的Option。每个智能体的训练集采样都是从10个简单路径上获取的(所有的都开始于一个随机位置)。智能体采用Q⁃学习算法(折扣因子γ= 0.9)并结合线性函数逼近。如图2所示,实验结果是三个智能体在连续迷宫区域,具有相同的训练集,从100个不同起始位置到达目标状态的平均步数。在图2中,可以看到智能体在初始的一些情节中采用给定的Option表现的更好,远远优于在没有任何Option下智能体所学习的结果,在很多情节后,它能表现出在平坦策略下的更快的收敛结果。这表明了Option增加了学习的性能表现,同时也在其他工作也证明了这一点。
图2同样也展示了具有不同输入集下RSD算法得到的性能结果。智能体采用RSD算法,设置技能树集合参数M = 5,训练集最小尺寸nmin= 100时,由于在初始情节中,在没有Option的情况下执行的更差,它的平均步数维持在一个较大的值,但是它最终收敛到与给定合适的Option情况下的相同质量的解。由于Option通过智能体利用RSD算法随机获取的,因此,性能表现在每轮迭代中是不稳定的。在某些情况下,它能提高性能,但在某些情况下,它也许会降低学习率。从图2中可以看到,当参数M = 20时,智能体在初始情节中表现的很好,然后能以一个更快的收敛速度收敛到一个近似最优解。智能体利用RSD算法得到的三条学习曲线,其中参数M = 20与nmin= 50,比其他两个利用RSD算法得到的学习曲线效果好些。尽管初始性能不如前面算法,但是能在少数情节后获得连续的最优方法。实验结果分析表明,RSD算法能产生好的学习性能,能收敛到与定义合适的给定Option算法相同质量的解。性能上的改进也随着随机技能树的集合尺寸的增加变得更好。

图2 连续有障碍栅格空间的学习性能
4 结 语
实验的性能结果表明了RSD算法能显著提高连续域中RL问题的性能,通过采用随机技能树集合和对每个树叶学习一个低阶的Option策略。RSD算法的优点,与其他的技能发现方法相比,可以采用Option框架更好地处理RL连续域的问题,无需分析训练集的图或值自动创建Option。因此,它可以降低搜索特定Option的负担,能使它更适应于大规模或连续状态空间,能分析一些困难较大的领域问题。
参考文献
[1]SUTTON R S,BARTO A G. Reinforcement learning:An intro⁃duction [M]. Cambridge,MA:MIT Press,1998.
[2]KAELBLING L P,LITTMAN M L,MOORE A W. Reinforce⁃ment learning:A survey [EB/OL]. [1996⁃05⁃01]. http:// www.cs. cmu.edu/afs/cs...vey.html.
[3]BARTO A G,MAHADEVAN S. Recent advances in hierarchi⁃cal reinforcement learning [J]. Discrete event dynamic systems.2003,13(4):341⁃379.
[4]SIMSEK O,WOLFE A P,BARTO A G. Identifying useful sub⁃goals in reinforcement learning by local graph partitioning [C]// Proceedings of the 22nd International Conference on Machine learning. USA:ACM,2005,8:816⁃823.
[5]OSENTOSKI S,MAHADEVAN S. Learning state⁃action basis functions for hierarchical MDPs [C]// Proceedings of the 24th International Conference on Machine learning. USA:ACM,2007,7:705⁃712.
[6]MCGOVERN A,BARTO A. Autonomous discovery of subgolas in reinfoeremente learning using deverse density [C]// Pro⁃ceedings of the 8th Intemational Coference on Machine Learning. San Fransisco:Morgan Kaufmann,2001:36l⁃368.
[7]JONG N K,STONE P. State abstraction discovery from irrele⁃vant state variables [J]. IJCAI,2005,8:752⁃757.
[8]KONIDARIS G,BARTO A G. Skill discovery in continuous re⁃inforcement learning domains using skill chaining [J]. NIPS,2009,8:1015⁃1023.
[9]KONIDARIS G,KUINDERSMA S,BARTO A G,et al. Con⁃structing skill trees for reinforcement learning agents from demonstration trajectories [J]. NIPS,2010,23:1162⁃1170.
[10]刘全,闫其粹,伏玉琛,等.一种基于启发式奖赏函数的分层强化学习方法[J].计算机研究与发展,2011,48(12):2352⁃2358.
[11]沈晶,刘海波,张汝波,等.基于半马尔科夫对策的多机器人分层强化学习[J].山东大学学报(工学版),2010,40(4):1⁃7.
[12]KONIDARIS G,BARTO A. Efficient skill learning using ab⁃straction selection [C]// Proceedings of the 21st International Joint Conference on Artificial Intelligence. Pasadena,CA,USA:[S.l.],2009:1107⁃1113.
[13]XIAO Ding,LI Yitong,SHI Chuan. Autonomic discovery of subgoals in hierarchical reinforcement learning [J]. Journal of china universities of posts and telecommunications,2014,21 (5):94⁃104.
[14]CHEN Chunlin,DONG Daoyi,LI Hanxiong,et al. Hybrid MDP based integrated hierarchical Q⁃learning [J]. Science Chi⁃na(information sciences),2011,54(11):2279⁃2294.
A random skill discovery algorithm in continuous spaces
LUAN Yonghong1,2,LIU Quan2,3,ZHANG Peng2
(1. Suzhou Institute of Industrial Technology,Suzhou 215104,China;2. Institute of Computer Science and Technology,Soochow University,Suzhou 215006,China;3. MOE Key Laboratory of Symbolic Computation and Knowledge Engineering,Jilin University,Changchun 130012,China)
Abstract:In allusion to the large and continuous space’s“dimension curse”problem caused by the increase of state di⁃mension exponential order,an improved random skill finding algorithm based on Option hierarchical reinforcement learning framework is proposed. A random skill tree set is generated via defining random Option to construct a random skill tree set. The task goal is divided into several sub⁃goals,and then the increase of learning parameter exponent due to the increase of the intel⁃ligent agent is reduced through learning low⁃order Option policy. The simulation experiment and analysis were implemented by taking a shortest path between any two points in two⁃dimension maze with barriers in the continuous space as the task. The experiment result shows that the algorithm may have some intermittent instability in the initial performance because Option is de⁃fined randomly,but it can be converged to the approximate optimal solution quickly with the increase of the random skill tree set,which can effectively overcome the problem being hard to obtain the optimal policy and slow convergence due to“dimension curse”.
Keywords:reinforcement learning;Option;continuous space;random skill discovery
中图分类号:TN911⁃34; TP18
文献标识码:A
文章编号:1004⁃373X(2016)10⁃0014⁃04
doi:10.16652/j.issn.1004⁃373x.2016.10.004
收稿日期:2015⁃10⁃22
基金项目:国家自然科学基金项目(61303108;61373094;61472262);江苏省高校自然科学研究项目资助(13KJB520020);吉林大学符号计算与知识工程教育部重点实验室资助项目(93K172014K04);江苏省高等职业院校国内高级访问学者计划资助项目(2014FX058)
作者简介:栾咏红(1971—),女,青岛人,副教授,中国计算机学会(CCF)会员。研究方向为数据挖掘和强化学习。刘全(1969—),男,教授,博士,博士生导师,中国计算机学会高级会员。研究领域为智能信息处理、自动推理等。章鹏(1992—),男,硕士研究生。研究方向为强化学习。
