一种基于RDF知识库的二元组实体解析方法研究
2016-06-18伯为翰兰雨晴
伯为翰,兰雨晴
(北京航空航天大学计算机学院,100191)
一种基于RDF知识库的二元组实体解析方法研究
伯为翰,兰雨晴
(北京航空航天大学计算机学院,100191)
摘要:实体解析是数据清理过程中的基本问题,随着异构数据源的大量涌现,要求能够对包含有多种属性类型的实体描述对象进行解析。针对含有两类属性的实体解析问题,本文提出了一种基于RDF知识库的二元组实体解析方法:通过知识库检索来确定二元组内属性的相互关系并获取实体描述对象的具体类型,得到实体解析的分类结果。本文最后提出了基于该方法的算法框架及步骤,并通过实验进行了验证。
关键词:实体解析;RDF;知识库;数据清理
0 引言
实体解析(Entity Resolution,也称为 Object Matching , Reference Reconciliation)是数据清理过程中的普遍问题,是数据集成的重要步骤。他的作用是分析、判别数据集中的哪些关于实体(entity)的描述(reference)是指向现实世界中的同一个实体。进而对重复数据进行删除、合并、集成。
实体解析方法的种类很多,按其解析过程主要分为以下两类:
(1)基于实体属性的方法(character-based approaches),对每一对实体描述对象的属性值计算其相似性,满足设定的相似性阈值的实体表示为某一实体的共同引用(conference)。通常包括以下步骤:根据属性的取值特点,为每一属性设计合适的相似度度量方法,并计算两条记录对应属性的相似度;然后选择一个统计模型来判定两个记录的相似度或者匹配与否。简单的统计模型如线性回归,涉及到学习每一个属性的权重,从而对所有属性的相似度进行加权得到两条记录最终的相似度。通常会设定一个阈值,只有相似度不低于该阈值的记录对,才会被认为是匹配的。传统的统计模型根据有无训练集分为监督模型和非监督模型,比如朴素贝叶斯模型和层次聚类模型。无论使用哪一种模型,基于实体属性匹配的方法都要涉及到计算属性的相似度。根据属性的取值特点,人们提出了不同的相似度度量方法。这些相似度度量方法大致分为基于字符的相似度度量方法和基于词的相似度度量方法。
(2)基于实体关系的方法(relation-based approaches),根据实体描述,通过找出实体间相互关系的方法来进行解析。举例来说,在学术网络中,研究者们通常会和特定的一些研究者合作比较频繁。这种朋友关系或者合作关系可以通过观察实体在记录中的共现情况得到。利用这些关系可以进行深层次的分析。这些方法包括:Ananthakrishna等人利用链接之间存在的维度层次结构等信息来解决数据仓库应用领域中存在的重复问题;Bhattacharta等人提出了将基于属性的实体解析方法直接进行改进的关系型实体解析方法,将实体之间的相似性定义为二者基于关系的实体相似性和基于边(链接)的实体相似性的线性组合;将实体解析转换为聚类问题的方法。无论用什么样的关系表示,这种基于实体关系的方法本质上都是基于实体值的的相似度测量值基础上的改进。
以上的这些方法首先都要对每个实体描述对象对进行相似度测量,特别是对较大规模的数据集即便设计高效的算法其比对量也很大;其次大多数解析场景是针对具有相同类型的这一类实体描述对象进行比较,例如包含有文章名称和作者描述的文字的这一类实体描述对象。
而现实中情况更为复杂,实体的描述信息可能来自于不同类型的数据集,可能是关系型数据库、文本字段等。即便是在关系型数据库中,由于字段名属性不同,同一实体在不同数据源中可能有多个不同的表达方式;即使是相同字段名属性的描述可能表示多个不同的实体。例如最普遍的情况:对于同一部电影,一条文字是包含有电影名字、电影演员的实体描述,而另一条文字是包含有电影名字、导演的实体描述;而对于包含有电影名字、导演这两种属性的实体描述又表示不同的电影实体;此外,具有相同描述主体的文字可能指向不同类型的实体。
考虑现实中经常出现的以下场景:以包含有某个实体名称属性值和其他属性值的实体描述为例,可能存在的实体描述文字为:(表1)
由表1可知7种实体描述中,共得到4个不同的实体,其中4个描述是关于电影“卧虎藏龙”的实体,1个描述关于小说“卧虎藏龙”的实体,1个描述关于电影“少年派”的实体和1个描述关于小说“少年派”的实体。表中关于电影“卧虎藏龙”的描述有4个,其导演李安还执导了“少年派”这部电影。如果用传统的相似度方法或者聚类方法解析,即使描述文字的相似度很高,得到的结果也不尽如人意。考虑到每一条实体描述语言都是对现实世界中的实体的某种表示,即具有语义性,我们寻求一种通过RDF类型知识库来建立实体描述中属性值的某种关系,进而对该实体描述进行类型匹配的方法来进行实体解析。
1 RDF类型知识库研究
1.1RDF数据模型
RDF是一种数据模型,全称是资源描述框架(resource description framework),由万维网联盟(World Wide Web Consortium,W3C)组织的资源描述框架工作组于1999年提出的一个解决方案,并于2004年2月正式成为万维网联盟推荐标准。目标是构建一个综合性的框架来整合不同领域的元数据。RDF的基本数据模型包括资源(resource)、属性(property)及陈述(statements)。RDF模型中一条标准的陈述(statement)由一个三元组构成:主体(<subject>)、谓词(<predicate>)、客体(<object>),表示对主体的某种描述。
基于信息抽取技术,可以自动地从大规模的非结构化数据中抽取并构造开放领域的RDF数据集,如Freebase、IMDB、Wikipedia等等。

表1 包含有“卧虎藏龙(Crouching Tiger Hidden Dragon)”和“Life Of Pie(少年派)”实体的可能描述
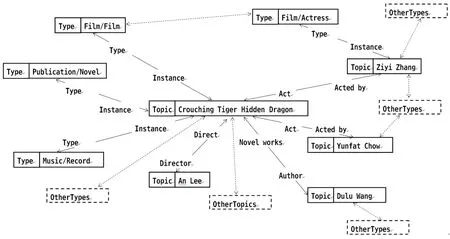
图1 Freebase 知识库中关于“卧虎藏龙(Crouching Tiger Hidden Dragon)”名称图的结构
1.2Freebase知识库结构
以Freebase知识库为例,按照类型分类它的结构可分为三层:域(Domain)->类型(Type)->实体(Topic)。
(1) 在Freebase中,每个Topic,即为主体(<subject>),每个Topic中的固定字段,叫做“属性”(Property)即谓词(<predicate>);对应某种属性的值即为客体(<object>),这样建立了主体与客体之间的双向关系;
(2) 所有同类的Topic组成一个Type,比如所有电影Topic就属于同一个Type,每个Type都有一套固定的Property,因此同类信息可以直接比较和关联;
(3) 所有相关的Type组成一个“域”(Domain),比如电影和音乐都属于“艺术和娱乐”域,可将域看做一个大的类型(Type)。
同时对每一个主体它的某个属性值可能为另一个主体, 这样所有的主体通过属性的关系构建成了一张图(Graph),图中的顶点表示主体(Topic)和类型(Type),边表示顶点之间的对应属性,考虑从表1中抽取的实例在Freebase库中的结构(图1):
如图1所示,该图是与“卧虎藏龙(Crouching Tiger Hidden Dragon)”这个名字的主体(topic)所对应的所有关系图,由图中可知,“卧虎藏龙”对应属于3个不同类型,同时它也继承了这3类的所有属性,它同时与n个不同的主体之间存在某种关系,不同的主体又属于不同的其它类型。
2 基于RDF结构知识库的二元组实体解析算法(RDF-Tow-Tuple Entity Resolution, RDF-TER)
2.1概念定义
(1)实体描述对象
假设实体数据集中的每一个实体描述对象由两种属性值表示成一个二元组,R=(S,Oi),S,Oi为该二元组的元素:其中S表示实体描述对象的名称,Oi表示实体描述对象的某种属性的值。
(2)实体描述对象类型定义
由于不同种类的实体属性不同,会导致其属性值也不同,则在实体解析过程中所起的作用也不同,因而用比较的方法将将二元组中的元素分为决定元素和辅助元素。
定义1 决定元素 (dominant element, DE)把实体描述对象中较为稳定的、不具有较多歧义参考表示的元素称为决定元素。决定元素在实体分类过程中起到决定性的作用。
定义2 辅助元素 (assistant element, AE)把实体描述对象中属性较为繁多并可能有较多歧义的元素称为辅助元素。辅助元素在实体解析过程中起到辅助的作用。
根据定义,实体描述对象R中S为决定元素(DE), Oi为辅助元素(AE)。例如表1中所描述的,“Crouching Tiger Hidden Dragon”为决定元素,表中的其他属性值为辅助元素。为简化讨论,本文中暂时先假设辅助元素为1个的情况。
2.2算法原理
基于RDF结构的知识库,将实体描述对象的二元组的值分别在知识库图中进行检索,找出二元组中属性值之间的绝对属性关系,再通过对这两类属性值的类型的遍历与筛选,得到一个包含决定元素(DE)的属性类型(Type)的基本回路,回路的结点包含元素值和类型,边由他们之间的相互关系组成。即确定了该实体描述对象的类型,最终得到具体的实体。
综上,本文提出的基于RDF结构知识库的二元组实体解析算法(RDF-TER)的框架(图2),包括两个阶段:第一阶段检索二元组值之间的关系,第二阶段通过遍历匹配二元组之间的类型关系,最后得到决定元素的类型。
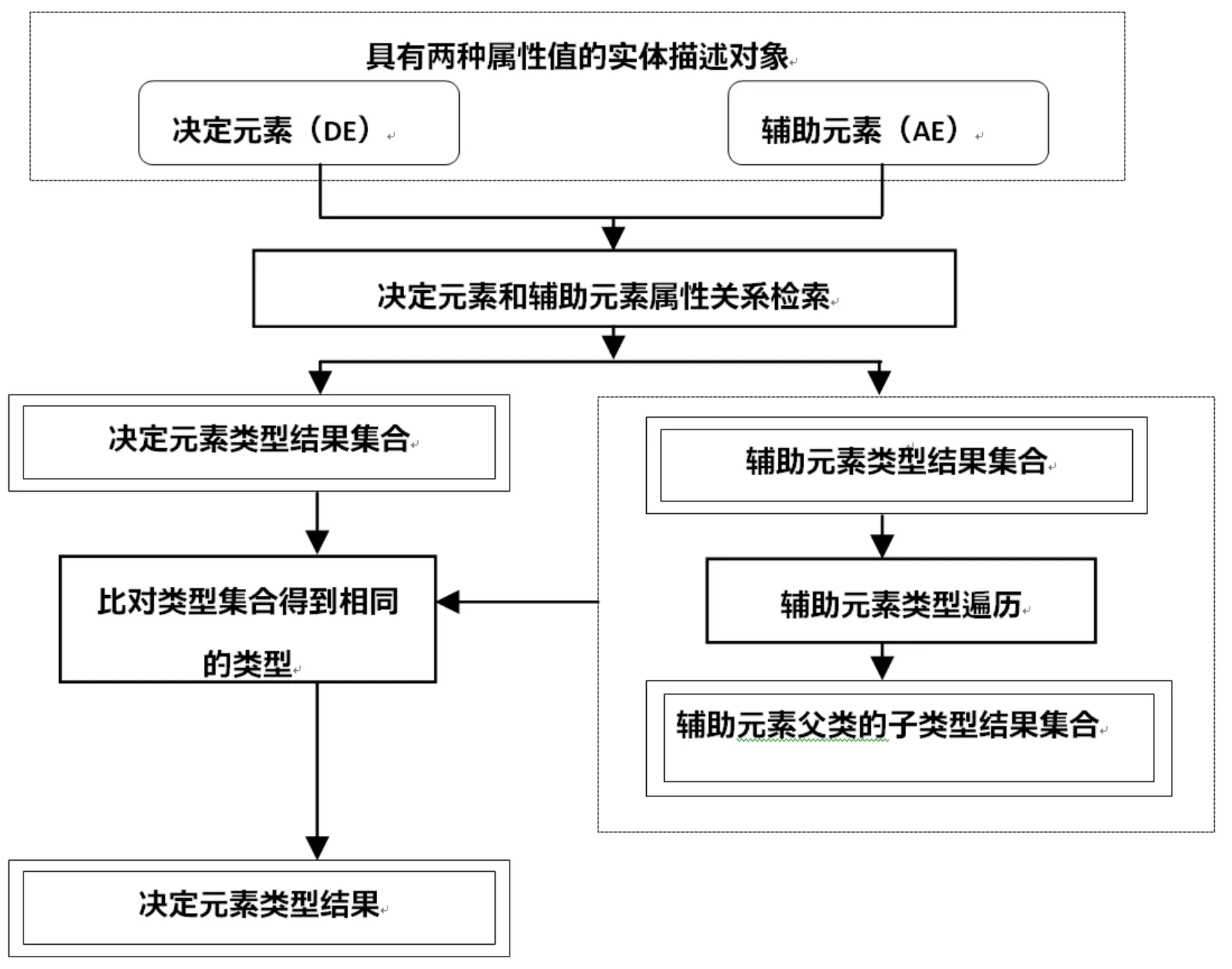
图2 基于RDF结构知识库的二元组实体解析算法(RDF-TER)的框架
2.3算法步骤
输入 规模为n的,包含两种元素的数据集D;
输出 决定元素类型结果。
基于RDF结构知识库的二元组实体解析算法(RDF-TER)主要步骤(图3):

图3 RDF-TER算法伪代码
3 实验及结果分析
3.1实验数据
为验证本方法的有效性,我们对一个真实的数据集进行测试,该数据集是从关系数据库和网页中抽取的包含电影、小说、音乐等类型数据集作为比对数据,其中每一条记录由实体名称描述和实体某一类属性描述构成,截取数据部分参考如下(表2)。
实验测试环境为:操作系统为WIN7,CPU为Intel Core 3.40GHz、内存为4GB。
3.2结果分析
对实体描述中的所有对象分别抽取为决定元素和辅助元素的二元组对,再通过RDF-TER算法在知识库中检索后得到的分类实体解析结果,对照表2的实例部分,得到的解析结果集
合如下(图4):由解析得到的结果可知,表2中的包含有3个相同实体描述名称(决定元素)的12条实体描述最终得到了6个不同的实体,数据子集中的1,4, 8,11为同一个实体,6为另一个实体,尽管他们都有相同的实体描述名称,而1,9,10即便都是同一类型的描述,但是实体描述名称不同,其实体也不同,最特殊的,1,9的中属性描述(辅助元素)即便相同,其得到的实体也不一样。
最终在1000条、5000条数据上得到的解析结果与数据集标准值比较,准确率分别为
88.32%、81.47%。其检索比对时间包括二元组词检索和结果类型比对,分别为40.572秒、320.915秒。考虑到数据的规模,该算法能够在较短时间内处理大规模的实体解析数据集。
4 结论
本文针对具有二元属性因素的实体解析问题,采用了与以往基于相似度测量和基于相似度关系等途径不同的思路,提出了通过RDF类型知识库来建立实体描述中属性值之间的确定关系,进而对该实体描述进行类型匹配的方法来进行实体解析。通过实验得出的准确率分析,能较好地解决具有相似属性和不同属性的实体描述对象的解析问题,并根据运行时间,认为该算法能能够在较短时间内处理大规模的实体解析数据集。作为一种探索性的思路与算法,下一步将继续研究其与传统解析方法的性能比较与分析,扩展解析场景,进一步提高算法运行效率与准确率。
参考文献
[1] Hanna Köpcke,Andreas Thor,Erhard Rahm,Evaluation of entity resolution approaches on real-world match problems,2010 VLDB.
[2] Bhattacharya I, Getoor L. Collective entity resolution in relational data [J] . ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): 1-36.
[3] Yu P S, Han J W, Faloutsos C. Link mining: Models, algorithms, and applications[M] . New York: Springer-Verlag, 2010: 118-119.
[4] David Menestrina, Steven Euijong Whang, and Hector GarciaMolina. Evaluating Entity Resolution Results . 2010 VLDB .
[5] Kalashnikov D V, Mehrotra S, Chen Z Q. Exploiting relationships for domain-independent data cleaning[C] // Proceedings of the Fifth SIAM International Conference on Data Mining, Philadelphia: Society for Industrialand Applied Mathematics, 2005: 262-273.
[6] W. Winkler, Overview of record linkage and current research directions, Statistical Research Division, U.S. Bureau of the Census, Washington, DC, Tech. Rep., 2006.
[7] David Menestrina, Steven Euijong Whang, and Hector GarciaMolina. Evaluating Entity Resolution Results.2010 VLDB .
[8] Ananthakrishna R, Chaudhuri S, Ganti V. Eliminating fuzzy duplicates in data warehouses[C] // Proceedings of the 28th International Conference on Very Large Databases, Massachusetts: Morgan Kaufmann Publishers, 2002: 586-597.
[9] Hannah Bast, Florian Bäurle, Björn Buchhold, Elmar Haussmann. A Case for Semantic Full-Text Search. JIWES ’12 August 12 2012, Portland, OR, USA
[10] RDF Current Status. http://www.w3.org/standards/ techs/rdf#w3c_all
[11] Thanh Tran, Haofen Wang, Sebastian Rudolph, Philipp Cimiano. Top-k Exploration of Query Candidates for Efficient Keyword Search on Graph-Shaped (RDF) Data. In Proceedings of ICDE'2009. 405~416
[12] Shady Elbassuoni, Maya Ramanath, Ralf Schenkel,Gerhard Weikum: Searching RDF Graphs with SPARQL and Keywords. IEEE Data Eng. Bull. (2010), 33(1):16~24
[13] Freebase API reference. https://developers.google.com/ freebase/v1/
[14] https://freebase.com/
[15] http://freebase-easy.cs.uni-freiburg.de/dump/

表2 包含实体名称描述和实体某类属性的数据子集
A method for two-tuple entity resolution based on RDF knowledge base
Bo Weihan,Lan Yuqing
(School of Computer Science and Engineering,Beihang University,Beijing,100191,China)
Abstract:Entity resolution is a fundamental issue in the process of data cleaning.With the advent of heterogeneous data source,it is necessary to identify entities with different properties simultaneously.We propose a method for two-tuple entity resolution based on RDF knowledge base.By retrieving knowledge base we can identify the relationship between two tuples and obtain a specific type of the entity resolution object in each. We also present an algorithm framework and experiment results.
Keywords:Entity parsing;RDF;knowledge base;data cleaning
通讯作者:伯为翰
