WEB网站缓存性能优化
2016-06-16黄杰周国祥石雷
黄杰+周国祥+石雷
摘要:为了满足网站对于信息发布后实时性的要求,针对于当前内存保存数据库备份的缓存模式,建立了以内存作为缓存模型的第一保存点,数据库作为数据备份方式,从而既满足了信息的实时性,又保证了数据的安全性。通过在券妈妈网站的实际使用,验证了该方法的实用性。
关键词:内存;缓存;数据库;WEB网站;性能优化
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)10-0040-04
Abstract: In order to meet the requirement of real-time information after release.To change the memory as the first save point,make the database as backup of of memory.Its not only meet the demand of security but also real-time.The method is verified by the actual use of the quanmama website.
Key words: memory; cache; database; WEB site; performance optimization
1 背景
缓存技术目前广泛应用于各类型WEB网站中,根据网站的访问量,每个网站都有自身一套的缓存方案,缓存实质上是将存在于硬盘上的数据,以KEY-VALUE模式存储在内存中,以增加访问者获取数据的速度。
国内外的大型网站,都有一套自身的缓存方案,比如淘宝的tair系统[1],这些网站都拥有着足够的服务器资源,而对于很多中小型网站受限于服务器资源,并不能使用这些方案来解决自身的网站缓存问题。而传统的缓存方案多是将数据库中数据保存到内存中,设定失效时间,失效时间到期后重新从数据库中获取,再重新保存到内存中[2],这种方案对于对数据时效性要求不高的网站可以使用,而对于数据时效性相对敏感的券妈妈网站这套基本方案并不合适。券妈妈网站主要的任务是发布各种优惠信息,而优惠信息对时效性要求较高,所以需要尽量的加快优惠信息从产生到被网站曝光的速度。如果采用传统的缓存失效,从数据库中重新获取这套方案,会大幅度减慢曝光速度,而如果减少缓存失效时间,使得缓存在内存中更新频率加快,使得网站硬件资源负担加重[3],增加网站安全隐患。
在券妈妈实际运营中,网站建立了一套适用于券妈妈网站特点的缓存机制,将内存作为数据的第一保存点,再定期的将数据备份到数据库中,通过服务器的内存作为第一时间保存,且同时与数据库之间保持一致性[4]。以期同时满足数据的安全性和时效性。
2 缓存技术方案优化
2.1 网站简介
券妈妈网站是以发布各大B2C优惠信息为主的导购类网站,日均访问约10万PV(page view即页面浏览量),3万UV(user view即用户浏览量),网站访问者在时间上有高度的重叠性,在访问的内容上有高度的相似性,非常适合使用缓存机制。
灰色线UV表示userview,代表有多少用户访问。
黑色线PV表示pageview,代步这些用户一共看了多少个页面。
大致可以可以得出每个用户大约看三个优惠信息页面,这使得我们在设计内存中缓存的页面数时,将每个分类对应缓存在内存中的数据定为5页,以尽量满足用户对于实时性的要求。
2.2 缓存模型
2.2.1 缓存基本框架
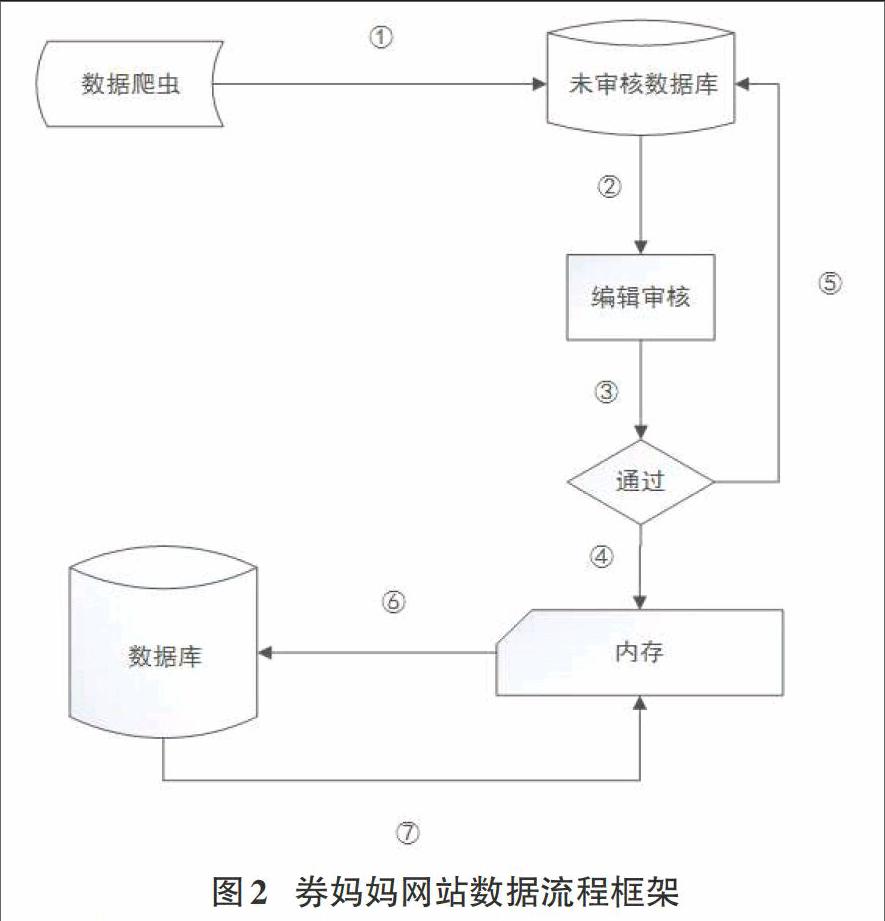
①:数据爬虫获取各大商家的优惠信息,以时间属性,不重复的保存至数据库。
②:在数据库中的数据进入待审核状态。
③:被审核的数据分为通过和不通过两类。
④:通过的数据,首先直接保存到内存的循环数组中。
⑤:不通过的数据,将原始数据库中对应的数据,置为无效状态。
⑥:保存到内存中的数据,定时同步到数据中。
⑦:当网站首次启动时,会从数据库中将对应的数据同步到内存中来。
网站缓存采用的是以内存为第一保存点,审核即发布的方式,加快信息曝光速度。首先网站在内存中定义了一个长度为5000的常驻循环数组,作为优惠信息的基本保存数据结构(5000条数据基本上可以保证三天内的数据都能保存在数组里面),并且数组初始化时就为其初始化赋值,每个中都保存着优惠信息数据结构的空字段信息,这样省了在有新的优惠信息插入时new的动作,节约了内存分配的一些时耗(网站服务器端使用的是IIS服务,基于的.net平台,使用了垃圾回收机制,这种机制会导致在分配和回收资源时对CPU和内存的消耗)[5],这样每次插入新的数据时,实质上是执行了更新操作。我们为循环数组的头和尾分表定义了整形变量HeadIndex,TailIndex来表示当前数组中第一位和最后一位的数据位置。
当每次有新数据需要插入到数组时会根据循环数组的头指针(HeadIndex)和尾指针(TailIndex)的大小来执行不同的操作:
①:当TailIndex>HeadIndex且TailIndex不等于4999的时候,此时表示数组TailIndex后的数组中数据均可更新,只需要将TailIndex加1,同时将TailIndex所指向的数据更新为插入的数据即可。
②:当TailIndex
③:当重新部署网站的时候,网站部署的同时,会将数据库中按时间逆序的前5000条数据插入到循环数组中。再次插入新数据时,执行步骤②。
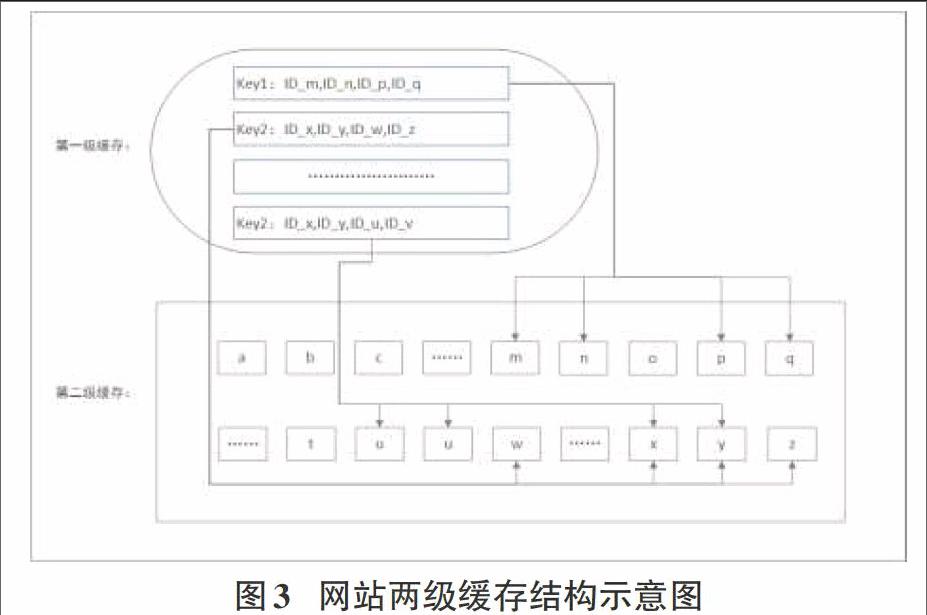
分页缓存控制:由于用户浏览数据都是按页来获取数据的[6],当数据通过循环数组的结构保存在内存中,就需要对数据进行按页为单位进行组织,以方便用户访问。网站采用两级Key-Value形式组织。
第一级:以分页条件为Key值,分页条件以优惠信息分类为基本组合,以当前分页条件中所含的数据对应的ID号为Value值,Value采用链表结构来保存数据(因为涉及到删除操作)[7],链表的长度为20。每个分页条件最多保留五页数据,即同分类条件在第一次缓存中最多对应5个Key,当用户访问第6页时从数据库中获取,另建缓存(这点基于每个用户在券妈妈大约看3个页面,PV为3)[8]。当插入新数据时,首先会以当前数据的分类条件定位到key,再遍历该Key所对应的Value链表,如果有当前数据所对应的ID则将该节点,插入到链表的第一位。如果没有当前数据的ID则判断是否链表已经20个数据了,满20则到该分类条件对应分页的下一页中执行同样的操作。其次会遍历所有的key所对应的Value链表,对所有其中包含ID的,进行删除操作,由于被替换的ID,都是最旧的数据,肯定都保存在链表的最后一位,故只需查询每个链表的最后一位,直接删除即可。因为下一页的数据永远比上一页的数据早出现,所以删除的节点一定是当前分页条件的最后一页的链表的最后一个数据,不会出现第一页19条数据,第二页20条数据的情况。
第二级:Value所对应的链表中保存的是当前分页所对应的数据在数组中的下标ID,用户访问到当前分页时,即首先获取链表中的ID值,再根据ID值直接从数组中将对应的数据取出来,生成HTML值,返回给用户。同时数组设计成循环模式[9],在插入数据时,选择到最早插入的数据,直接对其进行更新成最新的数据。第二级的数据,在网站部署/重启时,会与数据库直接通信,从数据库中选择前5000条数据,并根据数据的分类对第一级数据进行重构。
2.2.2 数据的更新删除
由于优惠信息有过期和错误的属性,所以对于已保存到数组中对应的数据有需要更新,删除的操作。
更新:即找到对应的数据在数组中保存的位置,直接更新,同时将数据对应于数据库中的也同时更新,保持数据一致性。
删除:由于数组的特殊数据结构,其删除操作会比较耗费时间[10],所以对于要删除的数据在数组中只是将其状态设置为删除状态,并不真正操作数组删除行为。同时对于第一级缓存中的value进行更改[11]。删除操作大致为如下:
①:遍历当前数据对应分类第一页的链表,如果存在,则直接删除当前链表中对应的数据,并且同时判断第二页链表是否有数据,如果有将第二页链表的数据的第一个摘下,插入到第一页链表的尾端。再判断第三页链表是否有数据,如果有将第一个数据摘下保存到第二页链表的的尾端。
②:如果遍历第一页数据不存在要删除的数据,则遍历第二页链表,如果存在执行步骤①。
③:如果前两页链表都不存在要删除的数据,则遍历第三页链表,同时直接删除对应的数据。
3 实验分析
由于网站的部署基本都选择在夜晚访问者最少的时间,所以我们分析的是网站稳定后,新数据审核通过后,网站的整体性能,以及网页数据的更新速度[12]。实验条件将网站部署在券妈妈的图片服务器上。由于实验对比的是不同的地方,所以对于网络传输速度等不予考虑。
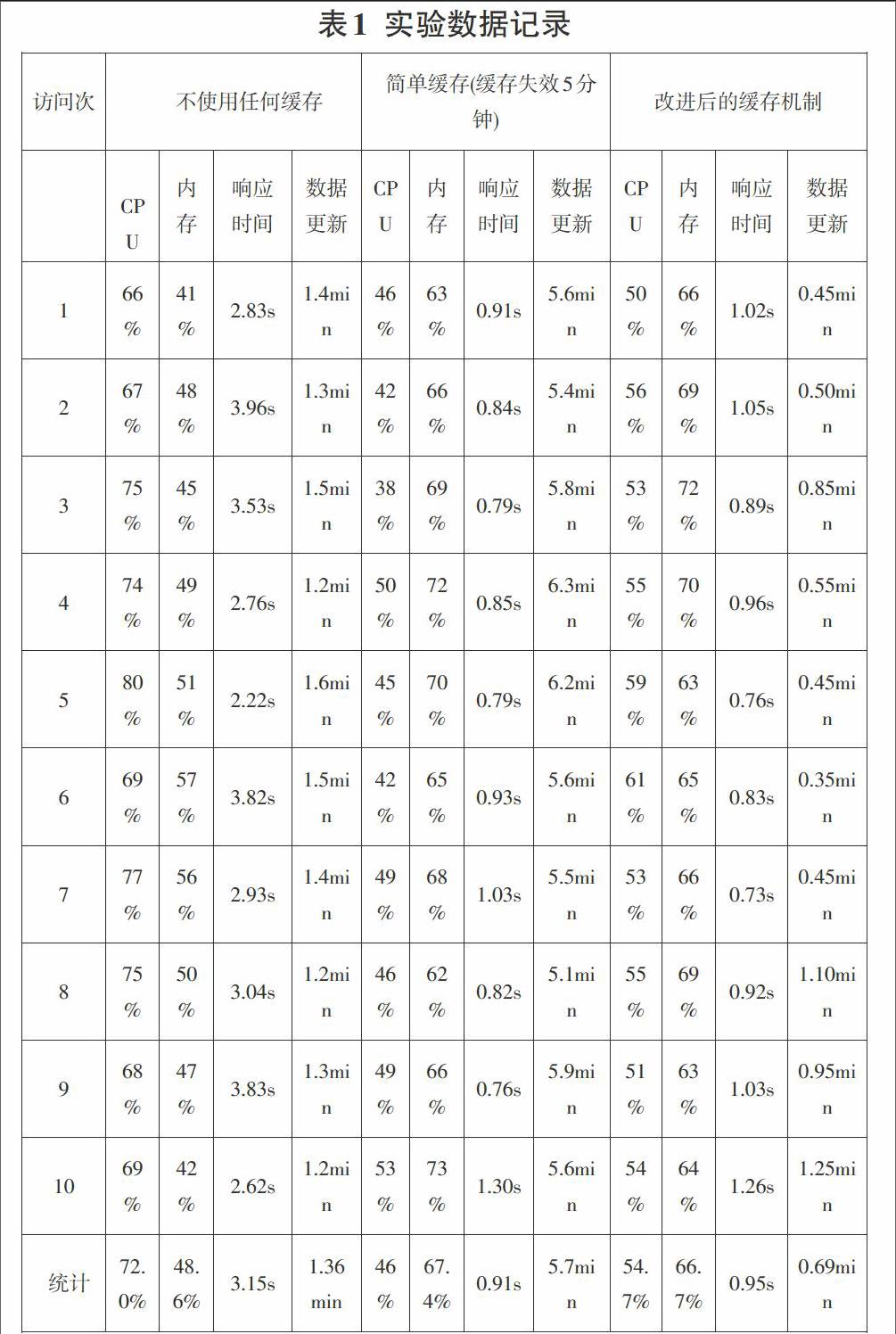
①不使用任何缓存:每次数据插入都直接插入到数据库之中,每个用户访问都是直接通过执行SQL来返回给用户对应的数据,所以其时耗主要在数据库执行上,当用户访问过多时,数据库会负载过重。
②使用简单的缓存:每次用户第一次访问时,从数据库中将对应的数据保存到缓存中并设定失效时间,其余任何用户访问相同的页面时,返回的都是直接从内存中对应的数据,当数据失效后,用户再次访问时会重新从数据库中获取。这种方式最为简单,但是会出现用户看不到最新的数据情况。用户会看到已经失效的优惠信息。如果将失效时间设置过短,又会使得缓存更新过快,加重数据库负担。
③网站自用缓存机制:当新数据插入到内存中,首先会将数据插入的数组中时间复杂度为o(1),然后会遍历第一级缓存,对应的key,执行插入操作,时间复杂度为o(1)。对此外的key进行删除操作时间复杂度为o(1)。遍历整个第一级缓存时间复杂度为o(n)。数据从数组中获取,并返回的时间复杂度为o(20)。如果出现删除操作,其时间复杂度为o(60)。这样其对数据库压力远远小于方式①和方式②,页面的更新速度也远超过方式②,整体其时间复杂度为线性。对于网站的整体性能也基本不会产生影响。
3.1 实验数据采集
我们按上述三种方式分别部署了不同性质的网站,并且不断地向网站插入新的数据,并对实验数据进行了采集。每次访问间隔10分钟。
CPU:访问时,服务器端的CPU使用率。
内存:访问时,服务器端的内存使用率。
响应时间:从访问开始到网页渲染(即数据已经返回)[13]。
数据更新:数据插入后,多久页面被更新。
可以看出采用方式③无论是从对CPU,内存的消耗,还是响应时间以及数据的及时性,都得到了一定的提升,在有限的条件下,使得网站性能得以明显的提升。
4 结束语
网站的打开速度和用户的离开速度有着直接的关联,而在有限的硬件资源下,就必须通过合理的优化方案来实现高速的响应效果,通过常态化的一些优化手段和网站自用的缓存方案,券妈妈网站基本上保证了日均10万PV的正常访问,这也基本上证明了,这套方案的实用性。网站的优化方案,必须得切合好网站的实际使用情况,网站的真实访问流量情况来决定,用户对于不同的网站,其期待的效果不一致。券妈妈网站主要提供的优惠信息和商品导购,这类信息用户更加期望有效,准确,及时。故而针对于此网站采用内存为第一保存点,以便直接将审核好的信息快速反馈给用户。
参考文献:
[1] 子柳. 淘宝技术这十年[M]. 北京: 电子工业出版社, 2013.
[2] Patrick Killelea. 优化 Web 性能[M]. 周新红, 译.北京: 中国电力出版社, 2000: 78-80.
[3] 吴安. 基于 MVC 设计模式的系统框架研究与设计[D]. 江苏: 江苏大学, 2009: 56-59.
[4] 张熙. Web 应用性能优化模型及测试框架的研究[D]. 南京: 南京航空航天大学, 2008: 38-40.
[5] Jeffrey Richter.CLR via C#[M]. 3版.北京: 清华大学出版社, 2010.
[6] Steve Holzner. Design Patterns For Dummies[M]. John Wiley & Son, 2006, 230-235.
[7] 王珊, 肖艳芹, 刘大为, 等. 内存数据库关键技术研究[J]. 计算机应用, 2007, 10.
[8] 程舒通, 徐从富. 网站结构优化技术研究进展[J]. 计算机应用研究, 2009, 26(6): 2013-2015.
[9] 奚冬芹, 林文龙, 竺炯林. 基于隐马尔可夫模型的电子商务网站结构优化[J]. 计算机应用研究, 2009, 26(3): 946-948.
[10] 严蔚敏. 数据结构(c语言版)[M]. 北京: 清华大学出版社, 2007.
[11] 谭骏珊, 吴昌盛. 基于 B/S 模式应用系统性能优化的研究[J]. 计算机应用, 2003: 2-3.
[12] Garcia-Molina H, Salem K. Main memory database systems: an overview[J]. Knowledge and Data Engineering,IEEE Transactions, 1992, 4(6): 509-516.
[13] 李守振, 张南平. Web应用分层与开发框架设计研究[J]. 计算机工程, 2006, 32(22): 274-276.
