多目标人工蜂群双聚类算法在基因表达数据中的应用研究
2016-05-25林斯达何明清
林 勤, 薛 云, 林斯达, 何明清
(1.广东医学院信息工程学院,东莞 523808;2.华南师范大学物理与电信工程学院,广州 510006;3.广东医学院公共卫生学院,东莞 523808)
多目标人工蜂群双聚类算法在基因表达数据中的应用研究
林勤1, 薛云2*, 林斯达3, 何明清3
(1.广东医学院信息工程学院,东莞 523808;2.华南师范大学物理与电信工程学院,广州 510006;3.广东医学院公共卫生学院,东莞 523808)
摘要:基于多目标优化的双聚类算法能够同时优化均方残差和尺寸等多个相互冲突的目标,更好地挖掘出均方残差较小、尺寸较大的双聚类,提出了一个多目标人工蜂群双聚类算法.该方法首先采用组信息对蜜源进行编码,然后使用2种交叉和1种变异操作分别实现算法的局部搜索和全局搜索,最后根据非劣排序和拥挤距离对外部档案进行修剪.在2套真实的基因表达数据集上进行实验,结果表明:与其他公开算法相比,多目标人工蜂群双聚类算法具有较好的收敛性和种群多样性,同时挖掘出具有显著生物意义的双聚类.
关键词:基因表达数据; 双聚类; 多目标优化; 人工蜂群
DNA微阵列技术产生了大量的基因表达数据集,这些数据集为深入认知生命过程和本质提供支撑,也为当前分析方法带来了严峻的挑战.聚类是基因表达数据分析的基础,可以用来发现具有相似表达行为的基因集,以预测未知基因的功能以及构建基因调控网络[1].传统聚类(如层次聚类[2]、K均值聚类[3]等)要求同类基因在所有条件下表达行为都要相似.但通常情况下,一些基因只在某些条件下有着相似的表达行为.在基因表达数据量少、维度低的情况下,这种方法对实际结果影响不大.但随着基因表达数据维度的不断增长,采用这种方法会丢失很多具有生物意义的局部模式.
为了发现部分实验条件下表达高度相似的基因集合,CHENG和CHURCH[4]提出了1种在基因和实验条件2个维度进行聚类的双聚类方法,定义了均方残差(Mean Squared Residue,MSR)作为衡量双聚类质量的指标,并采用增删节点的贪婪启发式策略和随机数替换来寻找双聚类.随后,FLOC、OPSM、DBF等基于贪心策略的双聚类算法相继被提出[5-7].虽然贪心策略比穷举策略的效率高,但是容易陷入局部最优,导致双聚类质量较差.2004年,BLEULER等[8]提出了基于进化算法的双聚类分析框架.2005年,BRYAN等[9]将模拟退火应用于基因表达数据双聚类分析中并得到较好的结果.然而,在求解过程中,搜索质量较高的双聚类不仅需要优化均方残差,同时还需优化尺寸(Size)等多个相互冲突的目标,因此,文献[10]提出了多目标进化双聚类(Multi-Objective Evolution Biclustering,MOEB)的框架,应用非支配排序遗传算法(Non-dominated Sorting Genetic Algorithm Ⅱ,NSGAⅡ),并结合局部搜索得到了质量较优的结果.文献[11]提出了改进的多目标遗传双聚类算法(Enhanced Multi-objective Genetic Biclustering,eMOGB),采用了新颖的组信息编码方式来高效地编码双聚类,并减少了局部搜索环节,提高了算法的执行效率.文献[12]提出了多目标粒子群双聚类算法(Multi-Objective Particle Swarm Optimization Biclustering,MOPSOB).文献[13]在MOPOSB的基础上,引入了ε-支配、拥挤距离和最近搜索等优化技术,提出了基于拥挤距离的多目标粒子群双聚类算法(Crowding distance based Multi-Objective Particle Swarm Optimization Biclustering,CMOPSOB,),进一步提高了最优解的多样性和收敛性.
人工蜂群算法(Artificial Bee Colony,ABC)是1种新型的智能仿生算法[14].对比于遗传、粒子群等常见的智能算法,ABC算法具有多种蜂种的分工协作,可通过不同的搜索策略来更好地完成搜索最优解的工作.这使得算法更加灵活、更容易与其他技术融合,全局搜索能力更强[15].本文以人工蜂群算法为框架,提出了多目标人工蜂群双聚类算法(Multi-Objective Artificial Bee Colony Biclustering,MOABCB).为了更好地优化均方残差和尺寸这2个目标,该算法在编码、不同蜂群搜索方式、蜜源替换规则和外部档案的维护等方面对框架进行了关键设计和改进.最后,将该算法应用于酵母菌和人类B细胞2套真实的基因表达数据集,并与多个基于多目标优化的双聚类算法进行实验结果的比较.结果表明:所提算法能挖掘到更优的双聚类,所得种群具有较好的多样性和收敛性.此外,使用GO和KEGG这2个重要的生物数据库对所提算法得到的聚类结果进行验证,结果表明所提算法可以挖掘出具有显著生物意义的双聚类.
1问题的描述
基因表达数据可以看成一个m×n的实数矩阵A.A的m行代表m个不同的基因,n列代表n种不同的实验条件.定义A的基因集G={x1,x2,…,xm}和实验条件集C={y1,y2,…,yn}.双聚类是A的一个子矩阵AIJ,可表示为:AIJ=(I,J),其中I={i1,i2,…,ik}是基因集G的子集,J={j1,j2,…,jl}是实验条件集C的子集.
定义1均方残差是用于度量双聚类内数据相似性的指标.在给定的子矩阵AIJ中,其均方残差定义为:
(I⊆G,J⊆C),
(1)
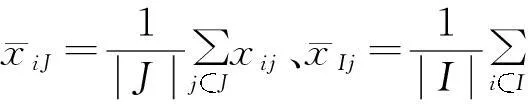
定义2尺寸的大小是用来衡量双聚类好坏的另一个指标.在给定的子矩阵AIJ中,其尺寸定义为:
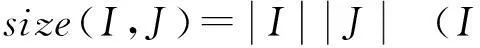
(2)
算法的目标是挖掘出基因数据之间的表达水平波动趋势尽可能一致的簇,同时这些簇的规模不会太小,也就是说均方残差较小且尺寸较大的双聚类.
2多目标人工蜂群双聚类算法
2.1人工蜂群算法
人工蜂群算法是一种模拟蜂群分工采蜜的智能优化算法[14],将寻找最优解转化成蜜蜂搜索高质量蜜源位置的过程.蜂群中有3种角色:采蜜蜂、观察蜂和侦查蜂.蜜源代表当前可行解,采蜜蜂与蜜源一一对应.蜜源的寻找过程通过不同角色间的信息交流、身份转换实现.在采蜜蜂阶段,每只采蜜蜂在对应的蜜源周围搜索更优解,并以摇摆舞的方式,将蜜源信息分享给观察蜂.观察蜂根据采蜜蜂提供的信息采用轮盘赌策略选择蜜源,蜜源质量越高,观察蜂前往的概率越大.观察蜂选取蜜源后对蜜源进行更新.在算法中,参数trial用来记录蜜源未被更新的次数,若trial超出阈值,即经过若干次搜索后,蜜源质量仍无法改善,相应的采蜜蜂会放弃该蜜源,变成侦查蜂在可行解的范围内进行随机搜索,产生新蜜源.之后侦查蜂转变为采蜜蜂,继续与其他蜜蜂分享蜜源信息.
2.2多目标人工蜂群双聚类算法的框架设计
为了更好地优化双聚类的均方残差和尺寸这2个相互冲突的目标,采用了多目标优化的方法来求解基因表达数据的双聚类问题.同时,蜂群算法相对于遗传、粒子群等常见的智能算法具有更优的全局寻优潜力,应用了多目标人工蜂群双聚类算法来求解基因表达数据的双聚类问题,并给出了一个具体的解决框架,具体流程见图1.
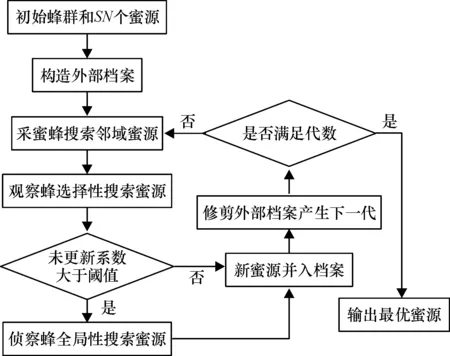
图1 多目标人工蜂群双聚类算法流程图
2.2.1编码方式采用文献[11]224的组信息编码方式.编码规则如下:每个蜜源拥有2条序列:基因序列和条件序列.如果基因序列中拥有值为g的元素,表示第g个基因在指定双聚类中.条件序列同理.这种编码方式只保留双聚类在基因表达数据矩阵中基因以及实验条件的实际序号,具有简洁高效的特点.例如,对图2A所示的嵌入在基因表达数据矩阵中由灰色背景元素组成的双聚类进行编码,根据组信息编码规则,可知其编码的结果(图2B).相反,组编码所译码的双聚类如图2C所示.
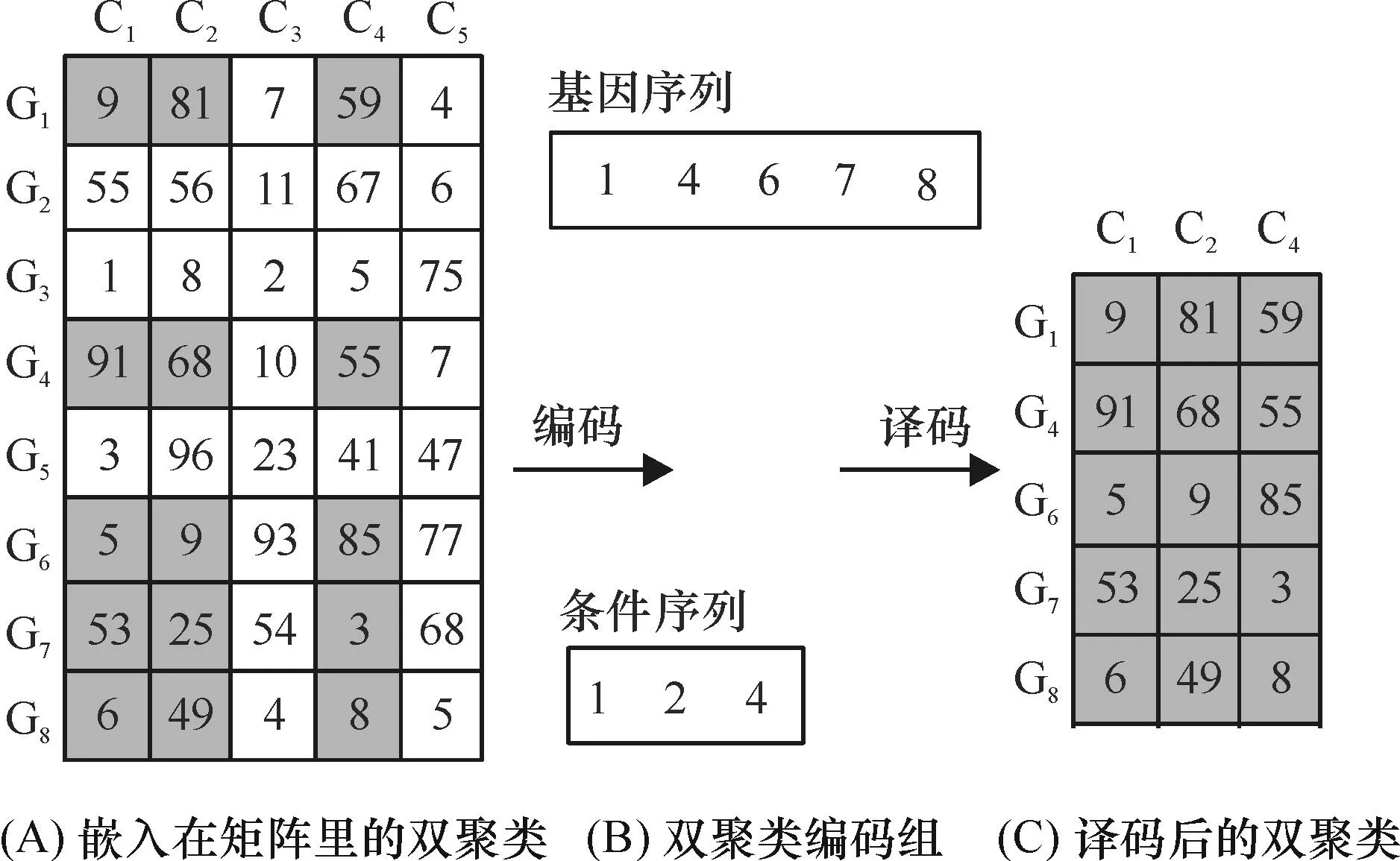
图2 一个双聚类编码和译码的例子
2.2.2适应度函数为了便于求解,把目标函数(1)、(2)统一转换为最大化问题:

(3)

(4)
其中,δ是待设定的均方残差阈值.
2.2.3搜索方式对不同蜂种的蜜蜂设计了不同的搜索策略,以克服传统蜂群算法容易陷入局部最优解的问题.
在采蜜蜂阶段,规定第i只采蜜蜂(蜜源1)在进行搜索时限定选取第n+i-1个蜜源(蜜源2)作为参照.利用eMOGB算法中的交叉规则[11]225进行局部搜索.在两蜜源的基因序列中随机产生一个基因交叉位点Gpivot,将蜜源1的基因序列中基因序号小于等于Gpivot所在基因的序号赋予子代1,大于Gpivot所在基因的序号赋予子代2;将蜜源2的基因序列中基因序号大于等于Gpivot所在基因的序号赋予子代1,小于Gpivot所在基因的序号赋予子代2,条件序列同理.例如,对图3A所示的2个蜜源进行采蜜蜂领域搜索,其过程如下:随机在2个蜜源选择基因交叉位点(Gpivot=5)和条件交叉位点(Cpivot=2),由于选择的基因交叉位点对应的基因序号是4,条件交叉位点对应的条件序号是5,根据采蜜蜂的交叉规则,可知其子代1和子代2的基因序列和条件序列(图3B).
在观察蜂阶段,对文献[11]225的交叉规则进行改进:观察蜂通过轮盘赌策略选中蜜源1后,随机选取蜜源2作为参照,在两蜜源的基因序列中随机产生一个基因交叉位点Gpivot,将蜜源1和蜜源2的基因序列中小于等于Gpivot所在基因的序号都赋予子代1,将大于Gpivot所在基因的序号赋予子代2,条件序列的交叉规则同理.例如,对图4A所示的2个蜜源进行观察蜂领域搜索,其过程如下:随机在2个蜜源选择基因交叉位点(Gpivot=5)和条件交叉位点(Cpivot=2),由于选择的基因交叉位点对应的基因序号是4,基因交叉位点对应的基因序号是5,根据观察蜂的交叉规则,可知其子代1、子代2的基因序列和条件序列(图4B).
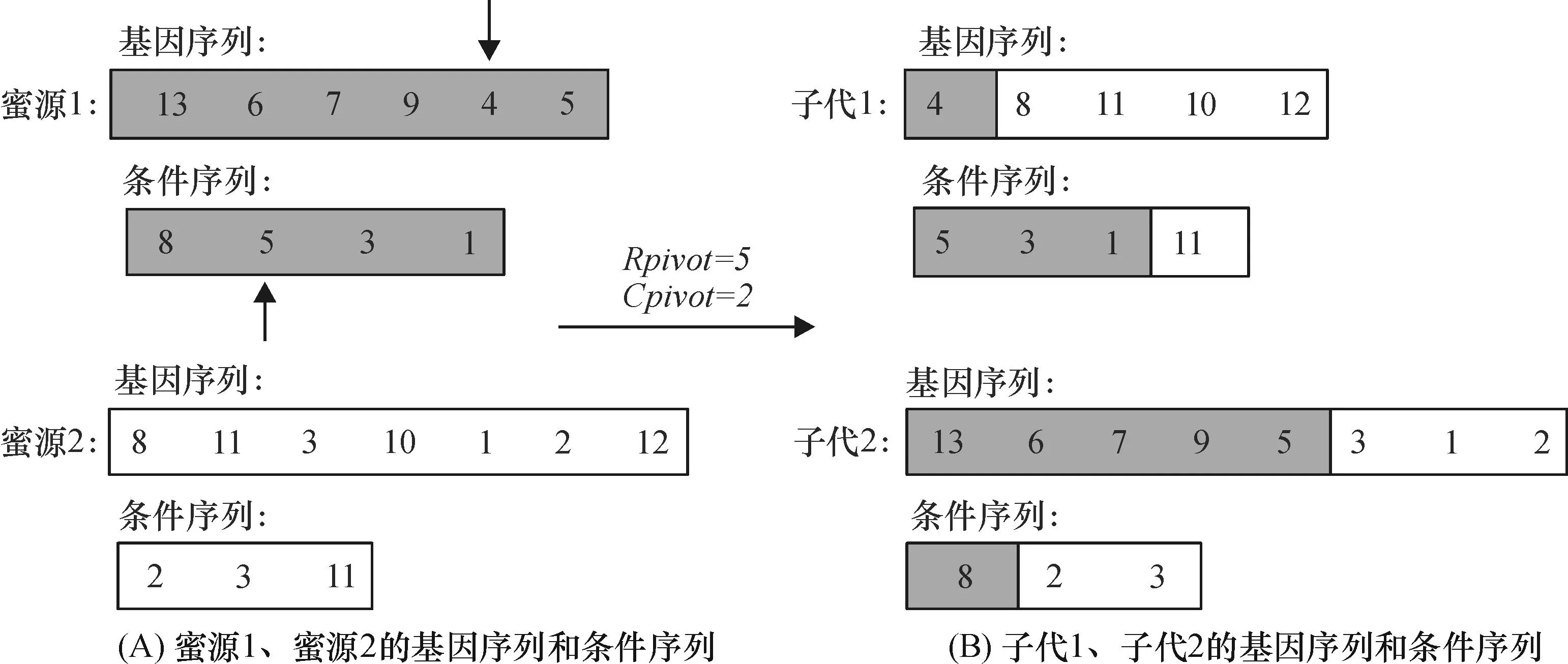
图3 采蜜蜂进行邻域搜索的例子
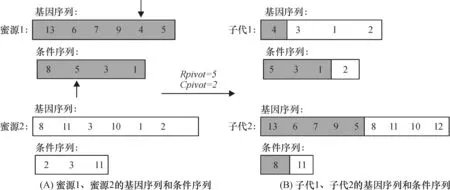
图4 观察蜂进行邻域搜索的例子
在侦查蜂阶段,对于未更新系数trial超出阈值Limit的蜜源,引入变异操作,通过随机增减蜜源的一行或一列的方式对蜜源进行更新,以实现全局搜索更优的蜜源.该侦查策略丢弃了蜜源的全部信息,导致ABC算法收敛速度减缓.本文设计的变异操作,使得侦查蜂能受到原蜜源部分有利信息的引导,在原蜜源的基础上更快寻找到更优解,加快算法的收敛速度.例如,对图5A所示的蜜源进行侦查蜂全局搜索,其具体的过程如下:按照基因70%、条件30%的概率来选择新增加的一行或者一列.比如按上述概率选中了第5个实验条件,根据侦查蜂的变异规则,可知其变异后的蜜源(图5B).
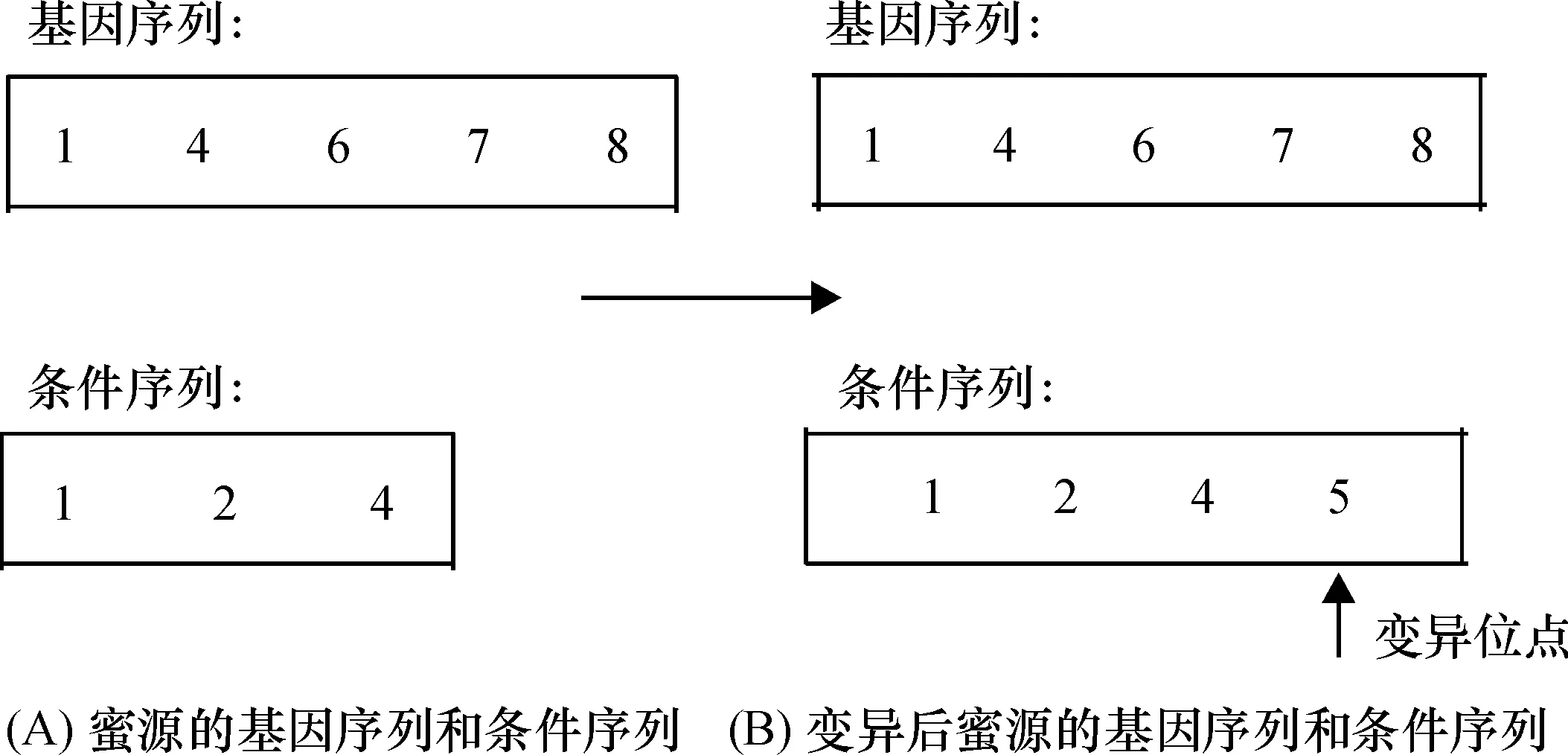
图5 侦查蜂进行全局搜索的例子
2.2.4蜜源替换规则在多目标问题上,不同的决策者目标的侧重程度不一样.对于基因表达数据,当子矩阵控制在一定的均方残差阈值下,子矩阵尺寸大小相对比均方残差重要.因此当2个目标不能兼优时,通过牺牲均方残差这一指标,让双聚类的尺寸达到更优.本文通过改进CI指标[10],定义ObjVal指标,具体表达式如下:
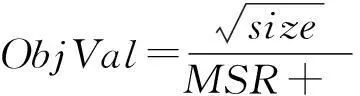
(5)
在蜜源Foodi和蜜源Foodj的替换选择问题上,结合Pareto支配关系[13]建立以下蜜源替换规则来判别两者的优劣,蜜源Foodi优于Foodj须满足以下任一条件:
(1)FoodiPareto支配Foodj,即Foodi≻Foodj;
(2)若2个蜜源间无支配关系,满足:ObjVali>ObjValj.
2.2.5轮盘赌改进策略在多目标人工蜂群算法中,蜜源的质量是由平均平方残差和尺寸共同决定.所以对传统蜂群算法的轮盘赌概率进行改进,确定选取的概率:
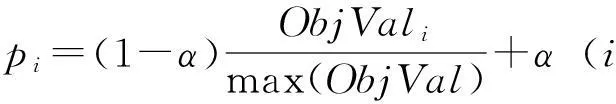
(6)
该指标结合ObjVal指标并引入最小选择概率α,可以保证每个蜜源至少有α的概率被观察蜂选中,这为质量较差的蜜源提供一定的机会,保证了种群的多样性.
2.2.6外部档案的维护本文使用外部档案来维护种群的Pareto最优解集[13],外部档案的大小与蜜源的个数都设定为SN.外部档案具体维护过程如下:首先,外部档案保留了上一代的种群,并把该代进化后的新一代种群也并入外部档案当中;然后,通过NSGA-Ⅱ算法[13]的非劣排序和拥挤距离的方法来维护外部档案,对其进行修剪,使得在下一代开始之前,外部档案始终保留了当前SN个最优蜜源并为下一代提供更优的初始种群.这种外部档案的维护方式能保证种群尽可能收敛于Pareto最优解集,同时也维持了种群内个体的多样性.
2.3多目标人工蜂群双聚类算法的实现
多目标人工蜂群双聚类算法的大致实现描述如下:第一阶段,初始化SN个蜜源并依据2.2节设计的编码规则对每个蜜源进行编码;第二阶段,依据2.2节设计的搜索、选择、更新规则对蜜源进行邻域和全局搜索、选择以及更新;第三阶段,依据2.2节设计的外部档案的维护规则从更新后的蜜源中筛选出SN个蜜源作为下一代蜜源.最后,重复第二、三阶段,直到蜜源进化到规定的代数,输出这SN个蜜源.多目标人工蜂群算法的详细实现可参考其伪代码(算法1).
算法1MOABCB
输入:基因表达数据矩阵,蜜源个数SN,MSR阈值δ,代数n,未更新系数阈值Limit;
输出:双聚类集
step1.随机产生SN个不同蜜源,生成第一代种群P0,设置未更新系数trial(i)=0;
step2.将种群P0置入外部档案;
step3.for种群代数iter=1 tondo
step4.所有采蜜蜂根据邻域搜索方式进行局部搜索,再按照蜜源替换规则进行更新,未更新蜜源的未更新系数加1,即trial(i)=trial(i)+1;
step5.根据式(6)计算概率pi;观察蜂根据概率pi选择蜜源并按其搜索方式进行局部搜索,然后按照蜜源替换规则进行更新,对未更新蜜源的未更新系数加1,即trial(i)=trial(i)+1;
step6.如果trial(i)>Limit,重置未更新系数trial(i),侦查蜂按其搜索方式进行全局搜索;
step7.将更新后的蜜源并入外部档案,对档案中所有蜜源进行非劣排序,计算拥挤距离;
step8.根据非劣排序秩次和拥挤距离大小,保留SN个蜜源在外部档案中,生成下一代种群Pi;
Step9.end for
Step10.return 双聚类集.
3结果与分析
实验使用的数据分别为酵母菌和人类B细胞数据集[4].其中,酵母菌数据收集了2 884个基因在17种不同条件下的表达数据,所有值位于0~600之间,其中34个缺失值用0~800的随机数代替.人类B细胞数据集收集了4 026个基因和96种不同条件下的表达数据,其值位于-750~650之间,其中12.3%的缺失值用-800~800的随机数代替.表1和表2呈现了各算法在2套数据集上的参数设置.
3.1实验结果的统计意义验证
采用CI指标[10]2470对算法所得的双聚类结果进行综合评估:
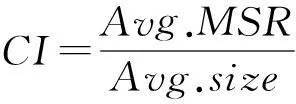
(7)
CI指标越小,说明双聚类的平均尺寸越大,且平均均方残差越小,因此双聚类综合质量越高.
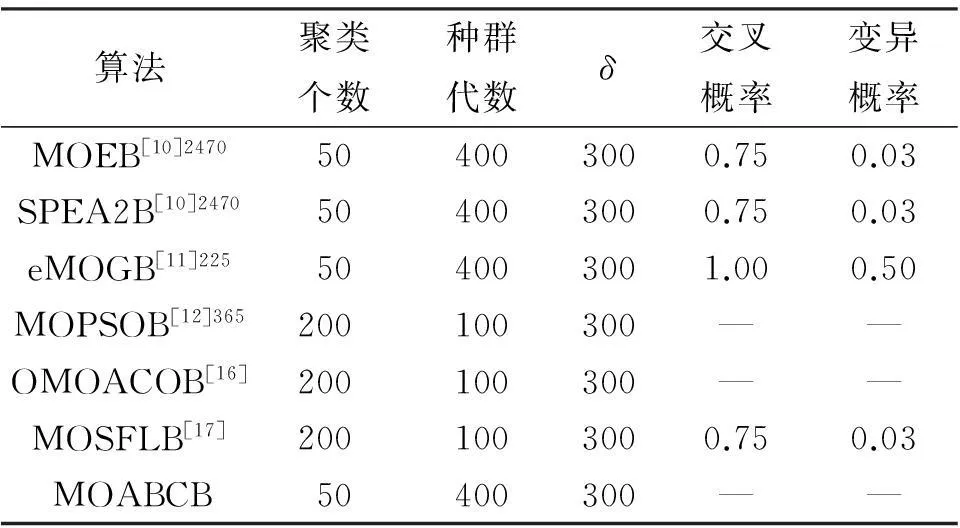
表1 各个算法在酵母菌数据集上的参数设置
从表3看出,多目标人工蜂群双聚类算法所得结果的CI指标为0.018 9,所得双聚类的综合质量优于其他比较算法.另外,获得的双聚类集的平均基因数较多,尺寸相对大.验证了多目标人工蜂群双聚类算法在酵母菌数据集上的测试结果在收敛性和多样性上具有较优的性能.
表2各个算法在人类B细胞数据集上的参数设置
Table 2The parameter settings of each algorithm in Human B cell dataset
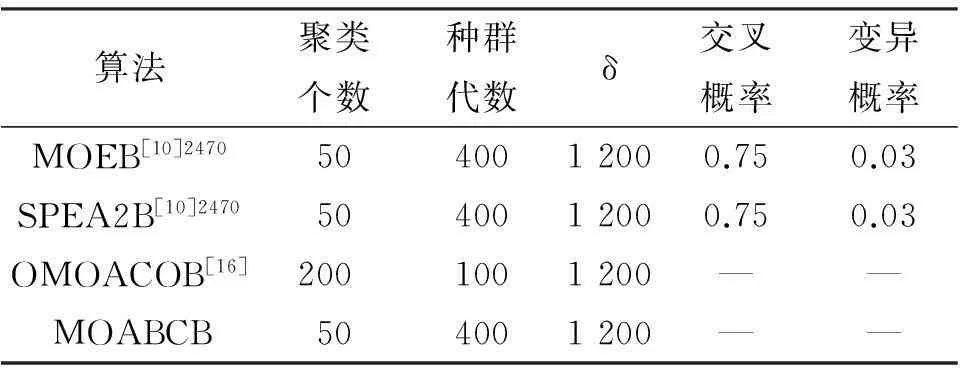
算法聚类个数种群代数δ交叉概率变异概率MOEB[10]24705040012000.750.03SPEA2B[10]24705040012000.750.03OMOACOB[16]2001001200——MOABCB504001200——
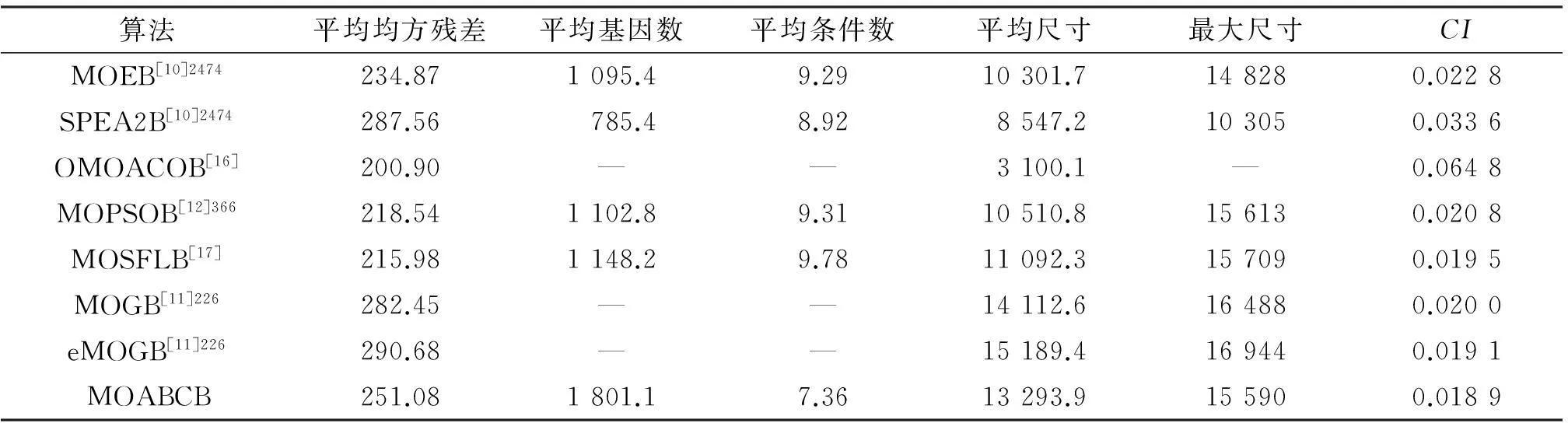
表3 各算法在酵母菌数据集的结果比较
由表4可知,多目标人工蜂群双聚类算法的CI指标为0.029 2,小于其他比较算法,所找到的双聚类综合质量同样优于其他比较算法.另外,对比于其他比较算法,本文算法能获得的双聚类集的平均基因数、平均尺寸、最大尺寸较大.验证本文算法在人类B细胞数据集上的测试结果在收敛性和多样性上具有较优的性能.
3.2研究结果的生物学意义验证
3.2.1GO分析基因本体论(Gene Ontology,GO)数据库[18],是目前应用最广泛的基因注释体系之一.通过对双聚类进行GO分析,可根据P值定位最可能相关的GO Term,从而通过已标注功能的基因来预测未标注基因的功能.本文采用GOTooLBox工具[19]对酵母菌数据集上发现的双聚类进行GO分析.表5列举了3个GO节点具有显著意义的双聚类结果,选择其中一个结果来进行阐释.双聚类C45有11个基因参与繁殖过程, 11个与RNA指导的DNA聚合酶功能相关, 18个与逆转录转座子壳蛋

表4 各算法在人类B细胞数据集的结果比较

表5 3个GO节点具有显著意义的双聚类结果
白的形成有关.由其P值均小于0.05可知,双聚类C45在基因的生物过程、分子功能及细胞组分等3个方面均具有显著的生物意义.这说明了本文算法能挖掘出有显著生物意义的双聚类.
3.2.2KEGG通路分析京都基因与基因组百科全书 (Kyoto Encyclopedia of Genes and Genomes,KEGG)[20]用于将基因及表达信息作为一个整体进行研究.通过KEGG的pathway分析,可根据P值发现较显著的代谢通路.采用基于网络访问的功能注释系统(the Database for Annotation Visualization and Integrated Discovery,DAVID)工具[21]对所发现的双聚类进行通路富集分析.表6列举了2个富集代谢通路具有显著意义的双聚类结果,选择其中一个结果进行阐释.双聚类C24有谷氨酸脱羧酶、精脒合酶等7个基因富集在β-丙氨酸代谢通路中.由其P值为0.016可知,双聚类C24在β-丙氨酸代谢通路出现了显著的富集.这说明了本文算法能挖掘出有显著生物意义的双聚类.

表6 2个富集代谢通路具有显著意义的双聚类结果
4结语
提出了一个应用多目标人工蜂群算法来寻找双聚类问题的框架,并在算法的编码、不同蜂种的搜索方案、蜜源质量评价和外部档案修剪等环节进行了关键的设计,加大了算法的局部和全局搜索能力,使结果更逼近全局最优解.将本文算法在酵母菌和人类B细胞数据集上与多个基于多目标优化的双聚类算法获得的实验结果进行比较,结果表明本文算法能挖掘到更优的双聚类,同时,所得的种群具有较好的多样性和收敛性.最后,利用了GO和KEGG这2个生物数据库验证了本文算法可以挖掘出具有显著生物意义的双聚类结果.然而,随着高通量微阵列技术的继续发展,该算法难免会遇到单机内存不足以及CPU处理能力的瓶颈,如何将算法进行并行优化设计以提高其扩展性将是未来工作的一个重点.
参考文献:
[1]李霞,李亦学,廖飞.生物信息学[M].北京:人民卫生出版社, 2010:188-189.
[2]LUO F, KHAN L, KHAN L. Hierarchical clustering of gene expression data[C]∥Proceedings of the 3rd IEEE Conference on Bioinformatics and Bioengineering.USA:IEEE Computer Society, 2003,67(3):328-335.
[3]SHERLOCK G. Analysis of large-scale gene expression data[J].Brief Bioinform, 2001, 2(4):350-362.
[4]CHENG Y, CHURCH G M. Biclustering of expression data[C]∥Proceeding of the 8th International Conference on Intelligent Systems for Molecular Biology. New York:ACM Press, 2000:93-103.
[5]YANG J, WANG H, WANG W, et al. Enhanced biclustering on expression data[C]∥Proceedings of the 3rd IEEE Conference on Bioinformatics and Bioengineering. Maryland:IEEE Computer Society, 2003:321-327.
[6]BEN-DOR A, CHOR B, KARP R, et al. Discovering local structure in gene expression data: the order-preserving submatrix problem[J].Journal of Computational Biology, 2003, 10(3/4): 373-384.
[7]ZHANG Z, TEO A, OOI B C, et al. Mining deterministic biclusters in gene expression data[C]∥Proceeding of the 4th IEEE Symposium on Bioinformatics and Bioengineering. Taiwan: IEEE Computer Society, 2004: 283-290.
[8]BLEULER S, PRELIC A, ZITZLER E. An EA frame work for biclustering of gene expression data[C]∥Proceedings of the 2004 Congress on Evolutionary Computation. Switzerland:IEEE Computer Society, 2004: 166-173.
[9]BRYAN K, CUNNFNGHAM P, BOLSHAKOVA N. Biclustering of expression data using simulated annealing[C]∥Proceedings of the 18th IEEE Symposium on Computer-Based Medical Systems. Ireland: IEEE Computer Society, 2005:1063-7125.
[10]MITRA S, BANKA H. Multi-objective evolutionary biclustering on gene expression data[J]. Pattern Recognition, 2006, 39(12):2464-2477.
[11]BRIZUELA C A, LUNA-TAYLOR J E, MARTINEZ-PEREZ I, et al. Improving an Evolutionary Multi-objective Algorithm for the Biclustering of Gene Expression Data[C]∥IEEE Congress on Evolutionary Computation. Mexico: IEEE Computer Society, 2013:221-228.
[12]LIU J W, LI Z J, LIU F F, et al. Multi-objective particle swarm optimization biclustering of microarray data[C]∥IEEE International Conference on Bioinformatics and Biomedicine. Philadelphia:IEEE Computer Society, 2008: 363-366.
[13]LIU J W, LI Z J, HU X H. Biclustering of microarray data with MOSPO based on crowding distance[J].BMC Bioinformatics, 2009, 10(4):59.
[14]KARABOGA D. An idea based on honey bee swarm for numerical optimization, Technical Report-TR06[R]. Kayseri: Erciyes University, 2005.
[15]张超群, 郑建国, 王翔. 蜂群算法研究综述[J].计算机应用研究,2011,28(9):3201-3205.
ZHANG C Q, ZHENG J G, WANG X.Overview of research on bee colony algorithms[J]. Application Research of Computers,2011,28(9): 3201-3205.
[16]LIU J W, LI Z J, HU X H, et al. Online MOACO biclustering of microarray data[C]∥IEEE International Conference on Granular Computing. Kaohsiung: IEEE Computer Society, 2011: 431.
[17]LIU J W, LI Z J,HU X H, et al. Multi-objective dynamic population shuffled frogleaping biclustering of microarray data[C]∥IEEE International Conference on Bioinformatics and biomedicine. Atlanta: IEEE Computer Society, 2011: 155.
[18]ASHBURNER M. Gene ontology:tool for the unification of biology[J]. Nature Genetics, 2000, 25(1):25.
[19]MARTIN D, BRUN C, REMY E, et al. GOToolBox:functional analysis of gene datasets based on Gene Ontology[J].Genome Biology,2004,5(12):6.
[20]KANEHISA M,GOTO S.KEGG: Kyoto encyclopedia of genesand genomes[J].Nucleic Acids Research,2000,28(1):27-30.
[21]HUANG D W, SHERMAN B T, TAN Q W E, et al. DAVID bioinformatics resources: expanded annotation database and novel algorithms to better extract biology from large gene lists[J]. Nucleic Acids Research, 2007, 35(S2): 172.
【中文责编:庄晓琼英文责编:肖菁】
Research and Application of Multi-Objective Artificial Bee Colony Biclustering in Gene Expression Data
LIN Qin1, XUE Yun2*, LIN Sida3, HE Mingqing3
(1.School of Information Engineering, Guangdong Medical College, Dongguan 523808, China;2.School of Physics and Telecommunication Engineering, South China Normal University, Guangzhou 510006, China;3. School of Public Health, Guangdong Medical College, Dongguan 523808, China)
Abstract:Biclustering algorithms based on multi-objective optimization, which can optimize several objectives simultaneously in conflict with each other, such as the mean squared residue and the size. In order to mine better biclusters with lower mean squared residue but larger size, a novel algorithm named Multi-objective Artificial Bee Colony Biclustering is proposed. Firstly, the approach adopts a group based representation for the genes-conditions associations to encode foods, then two different crossovers and a mutation operation are used to realize local search and global search respectively. Consequently, the non-dominated sort and crowding distance are applied to prune external archives. Experiments are performed on two real gene expression datasets, and it is found that compared with competing algorithms, the method has better global astringency and diversity of the population. Besides, it can obtain significantly biological biclusters.
Key words:gene expression data; biclustering; multi-objective optimazition; artificial bee colony
中图分类号:TP391
文献标志码:A
文章编号:1000-5463(2016)02-0116-08
*通讯作者:薛云,副教授,Email:xueyun@scnu.edu.cn.
基金项目:国家自然科学基金项目(71272084,71102146);广东省教育部产学研结合项目(2012B091100349);广东医学院面上基金项目(XK1330);广东医学院大学生创新实验重点项目(2014FZDG003)
收稿日期:2015-07-16《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n
