信息增益对于提取新闻特征向量的优势
2016-05-14钱怡陶
钱怡陶
摘 要 信息增益是当下国内外文本分类热门方法之一,拥有广泛的应有领域。通过对传统基础的新闻推荐算法的模型原理进行详细分析解释,选取各自的优点,指出算法融合改造的优势,将一种基于信息增益的新闻推荐模型,用以达到挑选出最合适的新闻推送给最有兴趣的用户的目的。
关键词 信息增益;新闻推荐;TF-IDF
中图分类号 G2 文献标识码 A 文章编号 2096-0360(2016)05-0019-02
近年来,许多国外购物网站如Amazon采用信息增益的方法来帮助客户做出消费决定,这个方法可以有效缩短客户阅读大量评论的时间,从而达到更好的购物体验感,也加速了每一笔订单的消费时长[1]。而采用信息增益的文本分类方法的应用领域十分广泛,例如网络舆情的挖掘[2],烟丝致香成分分析[3],甚至应用于地震趋势的估计预测中[4]。
1 新闻推荐的原理
新闻阅读与线上购物的原理类似,只不过在这里将所有的商品替代为新闻,用户也在海量的新闻中搜索自己感兴趣的,如同在挑选产品,因此可以借鉴此种方法。在新闻推荐中主要包含的技术步骤包括提取新闻特征向量来简化对原新闻的分析,用户聚类来对不同类群的客户提供个性化的推荐,进行新闻关联将有联系的新闻建立联系,最后再向客户提供因人而异的有兴趣和紧密联系的新闻。
2 一般新闻特征提取方法
提取新闻特征向量最传统和经典的方法之一是TF-IDF法[5]。下面简单介绍一下它的原理。
若采用向量空间模型VSM(Vector Space Model)作为新闻文本表示模型,那么新闻文本就好似在一个矢量空间中的某一点,而其中的特征量能够给予这个点矢量值[6]。那么从中提取特征向量的过程就是对新闻内容进行降维处理,将冗余的信息和不重要的无关信息筛选掉,从而能够使文本在矢量空间中定点。常用的方法是词频法TF(Terms Frequency),通过计算一个词在整个新闻中出现的次数来判断这个词对于文本的重要性和代表性。词频法可以在一定程度上防止同一个词在长文本中出现的频度,很可能大于短文本而带来的干扰。
假设在文本中,词频的计算公式如下:
其中,分子代表某一选定词在整个文本中的计数,而分母则表示文本中所有词的计数和。
但是这样的方法会有很大偏差,如会有很多没有实际意义的词语干扰,如“的”“和”等等。因此需要对特征项进行加权处理,对高价值能够更多提供文本分类信息的特征词给予较高权重[7]。逆向文件频率IDF(Inverse Document Frequency)加权是普遍的一种处理计算,其计算公式如下:
其中,分子表示表示新闻库中新闻的总和,而分母是包含特定特征词的新闻总数,再将商做对数处理。
那么TF-IDF的公式可以整理为
经过IDF加权处理过后的TF法,可以有效降低数据维度,剔除冗余词汇。但是这种方法只能够判断单文本的关键词权重,不能够给出文本类内类外分布对关键词权重的影响。下面将介绍一种可以优化文本类间的权重计算方法。
3 信息增益的优势及改良
信息增益IG(Information Gain)被认为是鉴定机器学习(Machine Learning)效果的良好标准之一[8],也是通过提取特征向量来进行文本分类的常用方法[5]。信息增益的定义为某一特征词选定后在文本中前后的信息熵IE(Information Entropy)之差。而信息熵在信息论中表示一个随机事件出现的概率,而如果在随机事件发生之后计算某一特征词信息熵,则可以从中获得这个特征词的信息价
值[9]。在一个文本类型中,如果一个词的信息熵越大,代表它在文本类中分布得越广,越能够代表这个文本类的普遍特征。信息增益的表达公式
如下[10]:
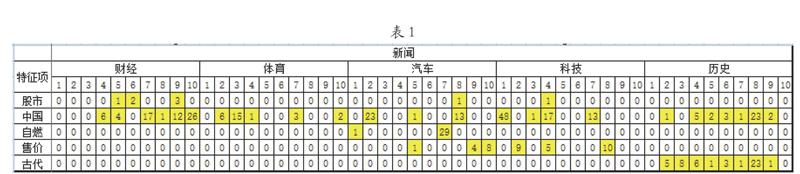
上式中,t为新闻中的特征词,C为新闻类别。特征词的信息增量越大,则说明这个词对新闻分类的贡献越大,越具有代表性。在“今日头条”上挑选50条最新的新闻(2016年1月8日至2016年1月11日期间),财经、体育、汽车、科技、历史五个板块各选取10个文本,挑选“股市”“中国”“自燃”“售价”“古代”为特征项。结果如表1所示。
IG(股市)=-log(0.2,2)+5/50×(3/5×log
(3/5,2)+1/5×log(1/5,2)+1/5×log(1/5,2))+
45/50×(7/45×log(7/45,2)+10/45×log(10/45,
2)×2+9/45×log(9/45,2)×2)=0.105 139
IG(中国)=-log(0.2,2)+25/50×(6/25×log (6/25,2)+1/5×log(1/5,2)+3/25×log(3/25,
2)+4/25×log(4/25,2)+7/25×log(7/25,2))+
25/50×(6/25×log(6/25,2)+1/5×log(1/5,2)+
3/25×log(3/25,2)+4/25×log(4/25,2)+7/25×
log(7/25,2))=0.059 103
IG(自燃)=-log(0.2,2)+24/25×(5/24×log (5/24,2)×4+4/24×log(4/24,2))=0.097 907
IG(售价)=-log (0.2,2)+6/50×(1/2×log (1/2,2)×2)+44/50×(10/44×log(10/44,2)×3+
7/44×log(7/44,2)×2)=0.176 845
IG(古代)=-log(0.2,2)+21/25×(10/42×log (10/42,2)×4+2/42×log(2/42,2))=0.489 924
由数据可以看出IG(古代)>IG(售价)>IG(股市)>IG(自燃)>IG(中国)。“古代”这个特征项只出现在“历史”类别的新闻中,而且占比较大,因此能够很好的代表这类文章,IG值较高;而“中国”这个特征项在五类新闻中都有出现,且分布较为均匀,且此不具有能代表某一类新闻典型特征的特点,IG值较低。
可见特征词的信息增益可以有效提供特征词在文本类间的分布情况,但是不能提供文本内部特征词的情况。因此,可以考虑结合TF-IDF和IG共同考虑来优化特征项的提取,提高其权重的准确性。
中科院鲁松团队从1996—1997年的《人民日报》上选取了6 518篇文本,分别用TF-IDF和TF-IDF-IG两种方法计算召回率(recall)和正确率(precision)进行比较[11]。结果用TF-IDF-IG方法来表示文本从召回率和正确率两个测试结果上都要好于TF-IDF法。
4 结论
可见信息增益的加入相较于传统的TF-IDF法,使新闻推荐更加高效和准确。但其中必须指出的是,该方法的前提是用户的新闻偏好在一段较长的时间内保持不变[12]。对新发布的新闻与用户阅读过的新闻进行对比,当两篇新闻的相似度大于某一阈值,且这个阈值于不同类型的文本各异,我们才能将新录入的新闻推荐给用户。
参考文献
[1]Richong Zhang · Thomas Tran (2011) An information gain-based approach for recommending useful product reviews. Knowl Inf Syst 26.
[2]万源.基于语义统计分析的网络舆情挖掘技术研究[D].武汉:武汉理工大学,2012.
[3]刘孝良,丁香乾,门月.基于信息增益的特征选择在烟丝致香成分中的应用[J].现代电子技术,2012(18):92-94.
[4]齐玉妍,孙丽娜,邱玉荣,等.河北及邻区地震时空概率增益综合预测研究[J].中国地震,2015(1):78-88.
[5]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[6]王博.文本分类中特征选择技术的研究[D].长沙:国防科学技术大学,2009.
[7]陈滢.基于个性化推荐技术的“新闻客户端”的使用与满足研究[D].广州:暨南大学,2015.
[8]Lee C,Lee GG (2006) Information gain and divergence-based feature selection for machine learningbased text categorization. Inform Process Manag 42.
[9]李海瑞.基于信息增益和信息熵的特征词权重计算研究[D].重庆:重庆大学,2012.
[10]YangY,Pedersen JO (1997)Acomparative study on feature selection in text categorization. In:Proceedings of the fourteenth international conference on machine learning:412–420.
[11]鲁松,李晓黎,白硕,等.文档中词语权重计算方法的改进[J].中文信息学报,2000(6):8-13.
[12]付娟妮.基于信息用户的新闻推荐系统特点及构建[J].企业科技与发展,2013(15):39-40.
