基于Nutch的搜索引擎的研究
2016-05-14杜旭升
摘 要面对互联网浩如烟海的信息,如何从中挑选出合理、排序公平的搜索结果是当今的一大难题。Nutch拥有开放的结果排序算法,且具有一个大型分布式搜索引擎所需的基本功能,研究Nutch对于我们更加深入的了解搜索引擎具有突出的作用。
【关键词】搜索引擎 Nutch
二十一世纪是互联网的时代,随着科技的发展,互联网已经深入到普罗大众的日常生活中。然而面对如此巨量的信息,我们却显得不知所措。Nutch的诞生为我们从多如牛毛的信息中提取出相对公平客观的信息提供了巨大的帮助。Nutch拥有搜索引擎的一些基本功能,并拥有自身特别的对网页价值评定的算法,努力为使用者提供最合理的搜索结果。
1 Nutch简介
Nutch是一个开源的、java实现的搜索引擎。虽然市场上已经有比较成熟的几款searcher engine,但并不妨碍我们对Nutch的研究,对Nutch的学习主要是因为:
1.1 透明度
Nutch是一款开源软件,因此任何开发者都可以看到它内部的排序算法。因此Nutch比较适合对结果的公平性相对较高信息的查询。
1.2 可以加深对搜索引擎的深入了解
Nutch的研究可以让我们更好的了解到一个大型分布式的搜索引擎是如何工作的很有意义。
2 Nutch的系统结构和工作流程
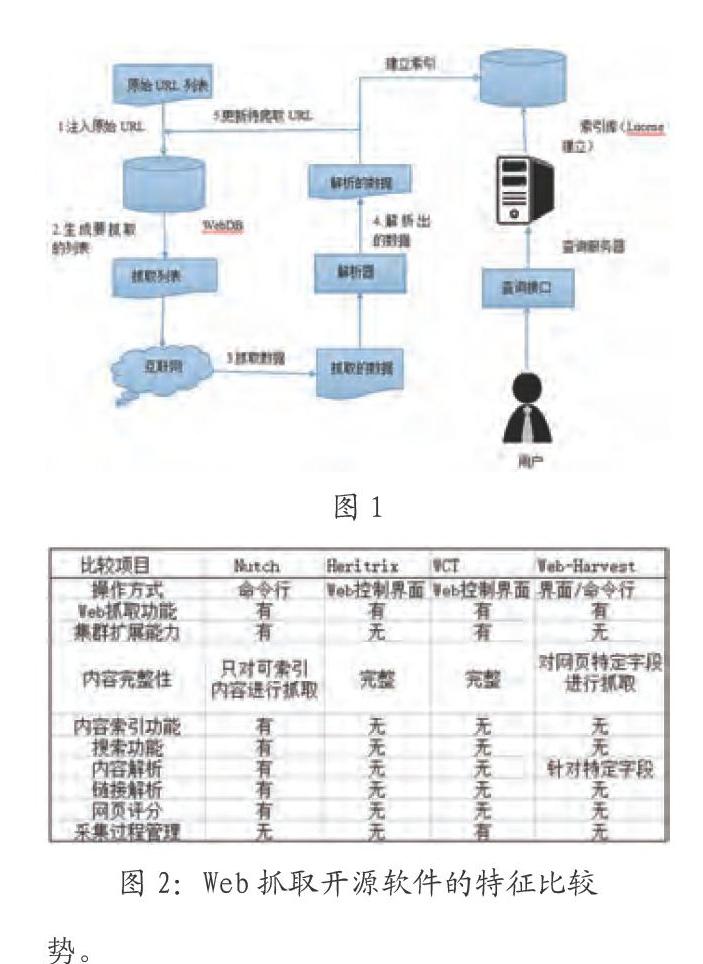
Nutch的基本组成主要包括爬虫,索引,搜索三部分。其体系结构如图1所示。
Nutch由Web-DB、LinkDB、Segements和Index的数据结构提供数据支持,Nutch整个的工作流程可以分为如下几步:
(1)建立种子URL;
(2)将种子URL加入到crawlDB数据库,整个网页抓取过程将会从URL开始抓取,一直到指定的抓取层数;
(3)创建抓取列表;
(4)执行抓取,得到网页内容信息;
(5)更新数据库;
(6)重复进行3~5的步骤,直到预先设定的抓取深度。
(7)对于每一个Segement生成一个索引;
(8)从这些索引中删除冗余的网页和URL;
(9)将小索引合并成大的索引;
(10)用户通过用户端口进行查询操作;
(11)将用户查询转化为Lucene查询;
(12)返回结果。
3 Nutch的技术分析
Nutch主要由Crawler及Searcher组成。Crawler是从互联网上抓取到网页,并且给每个网页建立一个特定的索引。Searcher则是利用crawler建立的索引根据用户查找的关键词来查找出结果。Crawler与Searcher的接口是索引。
3.1 Crawler的研究
Crawler的重点是其运行过程和包含的data file的格式和含义。data file主要包括三类,web database,Segement以及index。Crawler详细工作流程是:在创建一个WebDB之后,“产生/抓取/更新”循环根据一些种子URLs开始启动。当这个循环彻底结束,Crawler根据抓取中生成的Segement创建索引。在进行URLs清除之前,每个Segement的索引都是独立的。最终,各个独立的Segement索引被合并为一个最终的索引index。
3.2 Nutch的网页去噪
网页去噪主要是去除掉广告标签等无用的信息,尽量获取到网页的实质性内容,对于一个网页,去噪过程包括以下步骤:
(1)在
标签中抽取正文题目,根据标志字“by”,“last modified”等来抽取作者,修改日期等信息。
(2)利用HtmlParse去除掉各种脚本、图片等信息,得到只有链接和文本的字符串。
(3)利用网页的一般性特征去除掉导航栏文字,去除所有以“<”和“>”标识的链接文字。
(4)去除版权声明信息。
经过上述四种方法,基本上能够去除掉广告、导航信息、客户端代码等相对没有value的信息,对于获得比较好的网页内容具有极大的帮助。
4 Nutch的对比分析
通过搜索,我们将Nutch与时下比较好的开源搜索引擎进行对比测评,分别有Heritris、WCT、以及Web-Harvest。Nutch提供网页的抓取,分析了解网页、建立连接数据库、对网页进行评分、建立Lucene索引和提供检索界面登陆等。Heritrix提供了丰富的抓取设置选项,完善的、精确的站点内容深度复制。WCT能获得目标站点的深度采集授权、采集调度、资源描述等信息。Web-Harvest能以用户所指定的网页为抓取起始页,通过规则表达语法进行多层抓取,形成XML文档。
从图2可以看出,Nutch具有很强的对比优势。Nutch在抓取过程中,对于需要存储空间较大,但又value不高的信息就有较高的优势。
5 Nutch待改进的方面
经过团队的不断研究与测试,发现Nutch主要存在以下问题,影响了其性能的进一步提高:
5.1 等待时间僵化
Nutch抓取网页上的内容主要是利用protocol-http实现的。N每下载一个页面等待时间都是Nutch-default.xml配置文件预设的固定值:http.max.delays和fetcher.server.delay,这在不同的网络情况下会造成时间的巨大浪费。
5.2 抓取失败的链接网站管理不够
Nutch对于抓取失败的网页链接没有详细的监管。可能某个网站关闭了,或者更换域名,但依然在其他的站点存在链接,如果被Nutch发现而且还一个一个去实验,将会浪费大量的时间和网络资源。
6 结束语
Nutch由于透明的查询算法,其搜索结果对用户而言是比较公平的。然而Nutch离谷歌和百度等这些商业引擎依旧存在较大的差距,希望开发者们一起为Nutch的发展与完善贡献出自己的一份力量。
作者简介
杜旭升(1995-),男,甘肃省庆阳市人。现为新疆大学大学本科在读学生。软件工程专业。
作者单位
新疆大学 新疆维吾尔自治区乌鲁木齐市 830000
