藏语单句相似度计算模型研究
2016-05-14李成龙多拉
李成龙 多拉


【摘 要】句子相似度计算在藏文信言处理的各个领域中都是很重要的。本文从藏语句子的多个角度分析句子的相似性,利用藏语句子的特征结构,结合词形、词序、相似单元夹角和词性来计算藏语句子的相似度,从几个方面最终计算藏语句子的相似度。实验结果表明,该计算方法合理、简便、可行。
【关键词】词性 词序 藏语句子 自然语言处理
1 引言
在自然语言处理领域,尤其在藏文信息处理中,藏语句子相似度的计算是一项基础性较强的研究课题。长期以来一直是人们研究的一个热点和难点,直接决定着藏语信息处理领域的发展。如:基于实例的机器翻译、基于语料库的藏语教学系统、自动问答系统、藏文信息检索等研究中,藏语单句的基本句型研究对计算机语句处理具有重要的理论意义,使计算机对藏语句法分析的重要基础和前提。之前,对藏语句子相似度有些研究,安见才让老师写的《藏语句子相似度算法的研究》提出了采用散列单词倒排索引和基于句长相似度粗选的算法。于洪志老师在《基于藏语句多特征融合的主观题自动评分算法》中提出了一种藏语句多特征融合的主观题自动评分算法,构建了关键词词形相似度计算模型、词序相似度计算模型、句子长度相似度计算模型和句子语义相似度计算模型。
随着藏语语料库语言学的兴起,藏汉语语料库的建立也是一个基础研究项目,给予我们研究藏文信息处理领域的一个好的平台。其基本原理是:当输入一个待翻译的藏语句子时,系统自动从藏汉双语实例库中搜索到最相似的句子,再以该句子的译文为查询对象,查找出与藏语句子相对应的汉语句子。句子相似度的研究是很重要的一个研究项目,其直接影响到信息的检索和翻译的正确性等很多领域。
2 句子相似度模型
2.1 词形相似度
藏语句子的构成是以动词为核心,其语序常态是“ 施事— 受事— 动作” 的格局。词形相似度是比较输入句子和查询句子相似单元的长度。相似单元为输入句子与查询句子中的每个单元相匹配,寻找到相同的匹配单元。即SameWC(A和B)表示句子A和B中相似单元的长度,Len(A),Len(B)为句子A,B的长度,即长度是一个句子中相同的词和标点符号,为了方便于计算也可以忽略标点符号。当相同单元在某个句子中出现的次数较多时,以出现次数少的句子来计算。
例1:
WordSim(A和B)表示句子A和B的词形相似度,由公式(1)来表示:
WordSim(A和B)=2×SameWC(A和B)/len(A)+len(B).(0≤WordSim(A和B)≤1) (1)
该两个句子的相似度值SameWC(A和B)=2×5/(6+7)=0.769。
2.2 词序相似度
词序相似度是两个句子中含有相同词在位置关系上的相似程度。要考虑到一个句子的有序度和无序度。Match(A,B)表示在句子A和B当中都出现并且都只出现过一次的相似单元的集合,用Order(A,B)表示句子A中有序的相似单元,句子B中所确定的相似单元被打乱的程度,就是无序度,用Entropy(A,B)表示。句子A,B的词序相似度有公式(2)来表示:
,在句子A中,各相似单元排列顺序的相邻关系为,2-3,3-4,4-5,5-6,6-7,在这个句子中没有被打乱的相邻关系,即Entropy(A,B)=0,Order(A,B)表示句子B中各相邻最大匹配顶点的有序度。在句子B中有序项为,2<3、3<4、4<5、5<6、6<7,Order(A,B)=5.
2.3 相似单元夹角相似度
计算句子相似度时,有些句子词形、词序、句子长度方面都相同,在输人句子中位置相邻的两个相似单元在实例句子中被非相似单元的匹配单元间隔开来(排列顺序不变),此中间隔成为相似单元夹角。AngleNum(A,B)为相似单元夹角的个数,AngleSize(A,B)为所有夹角中间匹配单元的个数。由公式(3)为:
比较规则:两个藏语句子的词类序列,结合词类的权值信息,对两个句子从词的最左边起始位置开始,依次进行比较,如果词性相同,就匹配,得到最优的匹配结果,即最后的结果使两个待比较句子的词类序列相似度值最大。eword表示词性匹配的总数目,psmatchcount表示两个比较的句子中分词较少的句子的词个数,如果其中有一个句子的所有词都比较完了,则整个比较就结束。
上面2个句子表达的意思完全不同,其中的词汇也相异但是句法结构是一致的。所以这个两个句子结构相似度的值为1.假如两个句子的结构完全不相同,句子相似度的值等于0。
2.5 句子相似度
综合考虑词形、词序、相似单元夹角相似度、词性相似度的计算,给出述下多特征的藏语句子的综合相似度计算模型。
Zsim(A,B)= WordSim(A,B)+ OrderSim(A,B)+ Angle(A,B) pswsim(A,B)其中 分别是各类计算的权重, =1(0≤ ≤1,0≤ ≤1,0≤ ≤1,0≤ ≤1).各区分度的权重是可以调节的,考虑到各区分度对相似度的值得贡献大小,因此取 ,突出了词性在句子中的作用,其权重大。
3 算法流程图
算法流程图1所示:
4 实验结果及分析
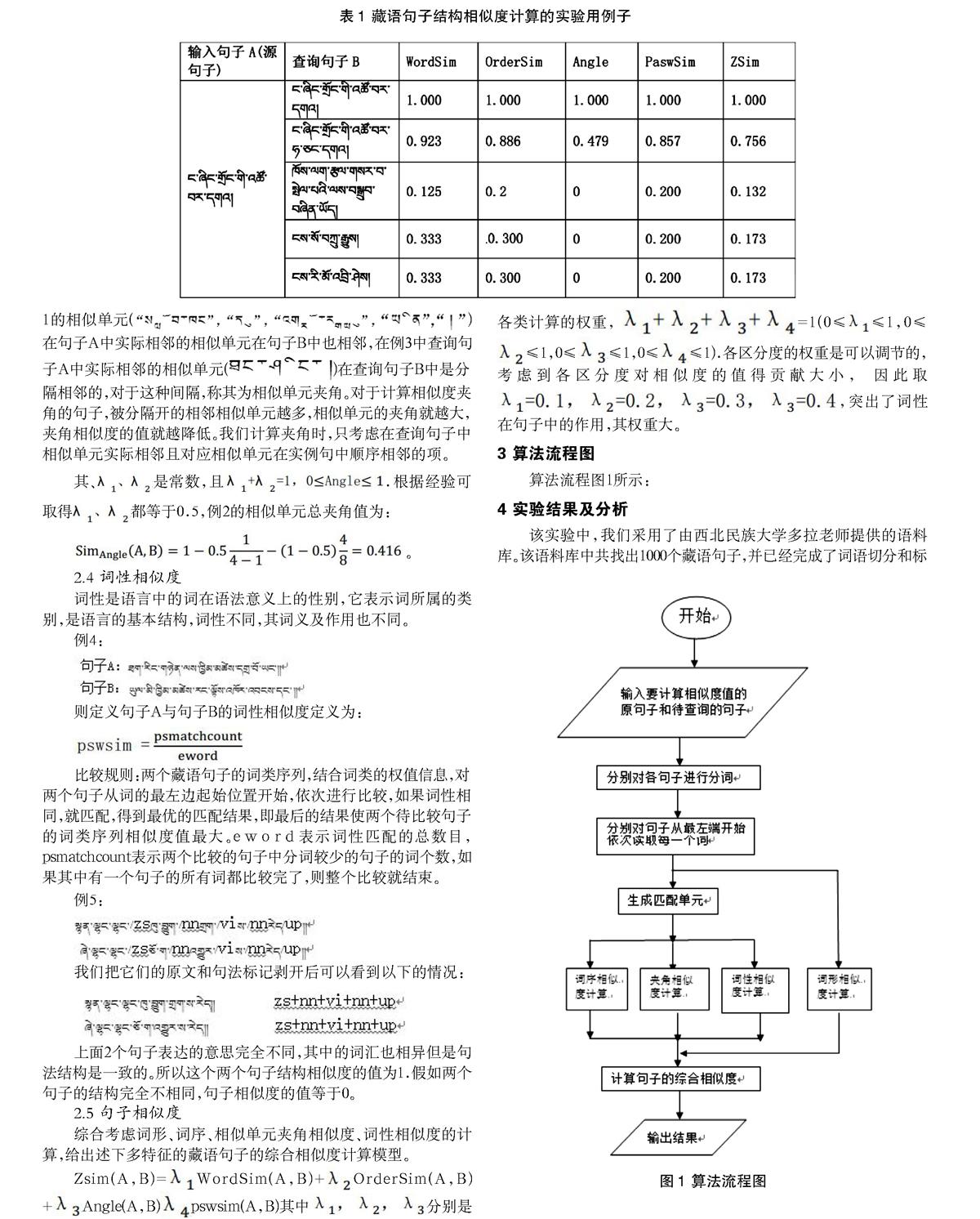
该实验中,我们采用了由西北民族大学多拉老师提供的语料库。该语料库中共找出1000个藏语句子,并已经完成了词语切分和标注。下面列出部分句子实例。
在上面的句子中,nr,vj,nn等是词类标记或者是短语类型标记。在目前的实验中,我们从句子集中选取了一些句子作为输入句子(源句子)。分别在语料库中查找与之结构相似的句子,并且按照相似度从大到小排序。由于篇幅限制,表1列出了部分计算结果。
在表1中可以看出实验结果,做实验的过程中能够把完全相似或整个相似的句子从预料当中找出来,系统会给出一个从0到1之间的一个值。藏语句子相似性的判断,并没有一个标准,只是一个模糊的概念。所以,我们并不能非常准确地用一个确定的数字来表示它们的相似性,只能把上述相似度值,看作是一个相对的概念,反应相似的趋势。
5 结语
藏语句子相似度的计算在基于实例的藏汉机器翻译,信息检索等领域中有着举足轻重的地位。本文从词的角度出发,从相同词的相似度、词序相似度、词性相似度三个方面综合考虑了两个句子相似度,它们所体现的信息都是不一样的,从几个方面考虑计算最终的藏语句子的相似度。实验结果表明,该计算方法合理、简便、可行。
参考文献:
[1] 王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2005(01).
[2] 安见才让.藏语句子相似度算法的研究[J].中文信息学报,2011(4).
[3] 于洪志,夏建华,万福成,陈新一.基于藏语句多特征融合的主观题自动评分算法[J].计算机工程与应用,2014(5).
[4] 吐尔逊阿依·阿不来提.基于词典的维吾尔语句子相似度研究[J].电子制作,2014(13).
[5] 李春梅,徐庆生.基于多特征的汉语句子相似度计算模型的研究[J].计算机技术与发展,2014(6).
[6] 吕学强,任飞亮,黄志丹,姚天顺.句子相似模型和最相似句子查找算法[J].东北大学学报(自然科学版),2003(6).
作者简介:李成龙(1982—),男,藏族,甘肃天祝人,西北民族大学在读硕士,主要从事藏文信息处理研究。多拉(1967—),男,藏族,青海海南人,西北民族大学博士、教授,主要从事语言学及应用语言学、藏文信息处理教学与研究。
