基于WordNet的中泰文跨语言文本相似度计算
2016-05-03周兰江线岩团余正涛
石 杰,周兰江,线岩团,余正涛
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 智能信息处理重点实验室,云南 昆明 650500)
基于WordNet的中泰文跨语言文本相似度计算
石 杰1,2,周兰江1,2,线岩团1,2,余正涛1,2
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 智能信息处理重点实验室,云南 昆明 650500)
文本相似度在信息检索、文本挖掘、抄袭检测等领域有着广泛的应用。目前,大多数研究都只是针对同一种语言的文本相似度计算,关于跨语言文本相似度计算的研究则很少,不同语言之间的差异使得跨语言文本相似度计算很困难,针对这种情况,该文提出一种基于WordNet的中泰文跨语言文本相似度的计算方法。首先对中泰文本进行预处理和特征选择,然后利用语义词典WordNet将中泰文本转换成中间层语言,最后在中间层上计算中泰文本的相似度。实验结果表明,该方法准确率达到82%。
WordNet;中间层语言;跨语言文本相似度
1 引言
文本相似度在语言学、心理学和信息理论等领域被广泛的讨论,文本相似度计算旨在比较两个文本之间的相关程度。近年来,基于同一种语言的文本相似度计算方法[1-3]日趋成熟,代表算法模型有布尔模型、向量空间模型、概率模型等。但是,对于跨语言文本相似度的研究则很少,跨语言文本相似度是指量化两个不同语言文本之间的相似性,并使量化的结果尽可能符合人工判断的结果。由于汉语和泰语在语法上存在差异,我们无法用现有的计算同一语言文本相似度的方法来计算汉泰双语文本的相似度。目前,关于跨语言文本相似度计算主要有以下几种方法: 1)基于机器翻译的方法[4]。该方法将源语言文本翻译成目标语言文本,在目标语言空间计算相似度,该方法依赖机器翻译的质量,并很难扩展到多种语言;2)基于统计翻译模型的方法[5]。该方法需要两种语言之间的翻译概念词典,但是翻译概念词典需要建立大规模对齐语料库,代价很大,并很难扩展到多种语言;3)基于平行语料的方法[6],该方法以两种语言的平行语料库为基础来计算相似度,该方法的准确性依赖于平行语料库的规模和质量。虽然上述方法取得了不错的效果,但是存在扩展性不足、工作量大等缺点。
Steinberger R[7]等提出一种中间层语言思想,用独立于语言的方式来表示不同语言的文本内容,在多语种词库EUROVOC上计算英文文本和西班牙文文本之间的相似度,该种方法不依赖于机器翻译,且有较高的扩展性和准确性,但Steinberger并没有把某一种具体的自然语言作为中间层语言,由此受到启发: 将中间层语言具体化,将不同语言空间转换成这一具体语言空间来计算文本相似度, WordNet的多语言版本特性使得语言空间的转换成为可能。WordNet[8]是一个使用同义词集表示概念的英文语义词典,有多语言版本,包括中文版、泰文版,中文WordNet的构建原则基本遵守英文WordNet的结构特点,将WordNet中的概念(同义词集合)映射为本国语言同义词集合,保留概念间的关系[9-10],本文使用的中文WordNet是由东南大学开发的中文版WordNet,泰文版WordNet由AsianWordNet提供。不同语言版本之间的WordNet的同义词集合的synset_id是对应的,通过synset_id将中泰文WordNet与英文WordNet对应起来。因此,本文利用多语言版本WordNet的synset_id相对应这一特性,提出了一种基于WordNet的中泰文跨语言文本相似度计算的方法,利用WordNet将中文文本和泰文文本转换成统一的中间层语言,并在中间层上计算相似度。
本文第二节主要介绍中泰文本相似度计算的过程,第三节对本文的算法进行测试与评估。
2 中泰文本相似度计算过程
2.1 文本预处理
尽管原始文本包含所有的文本信息,但是目前的自然语言处理技术无法完全处理这些文本信息,因此,需要对文本进行预处理。传统的文本预处理主要是去掉停用词,如“的”“地”等。由于本文的方法需要对词的语义进行分析,因此需要对一些地名、人名等特殊词进行处理,将这些特殊词统一转换成特定的字符串,在进行特征选择时,将这些特殊词项忽略,避免噪声干扰。
2.2 文本特征选择
经过文本预处理后,需要进行文本特征选择。特征选择的目的是选择对相似度计算真正有贡献的特征项,被选中的特征项应能表征原始文本的主题。本文提取词作为文本的特征,将每个文档看成一个词袋,对于中文文档和泰文文档,通过分词,去掉停用词后,都可以形成一个特征词集。然后通过文本频度的选择方法去掉干扰原始文本主题的无用词。文档频度(Document Frequency, DF)是指整个文本集合中包含特征词t的文本个数,DF大于某一阈值则去掉,DF越高,说明t在越多的文本出现;DF小于某一阈值也去掉,要么是稀有词或噪声。
2.3 中、泰语言空间的转换
考虑到不同语言之间存在很大的差异性,无法在不同语言层完成相似度计算,本文提出一种中间层语言的思想,即将不同语言转换成统一的中间层语言,在中间层上实现中泰文跨语言文本相似度计算。转换模型如图1所示。
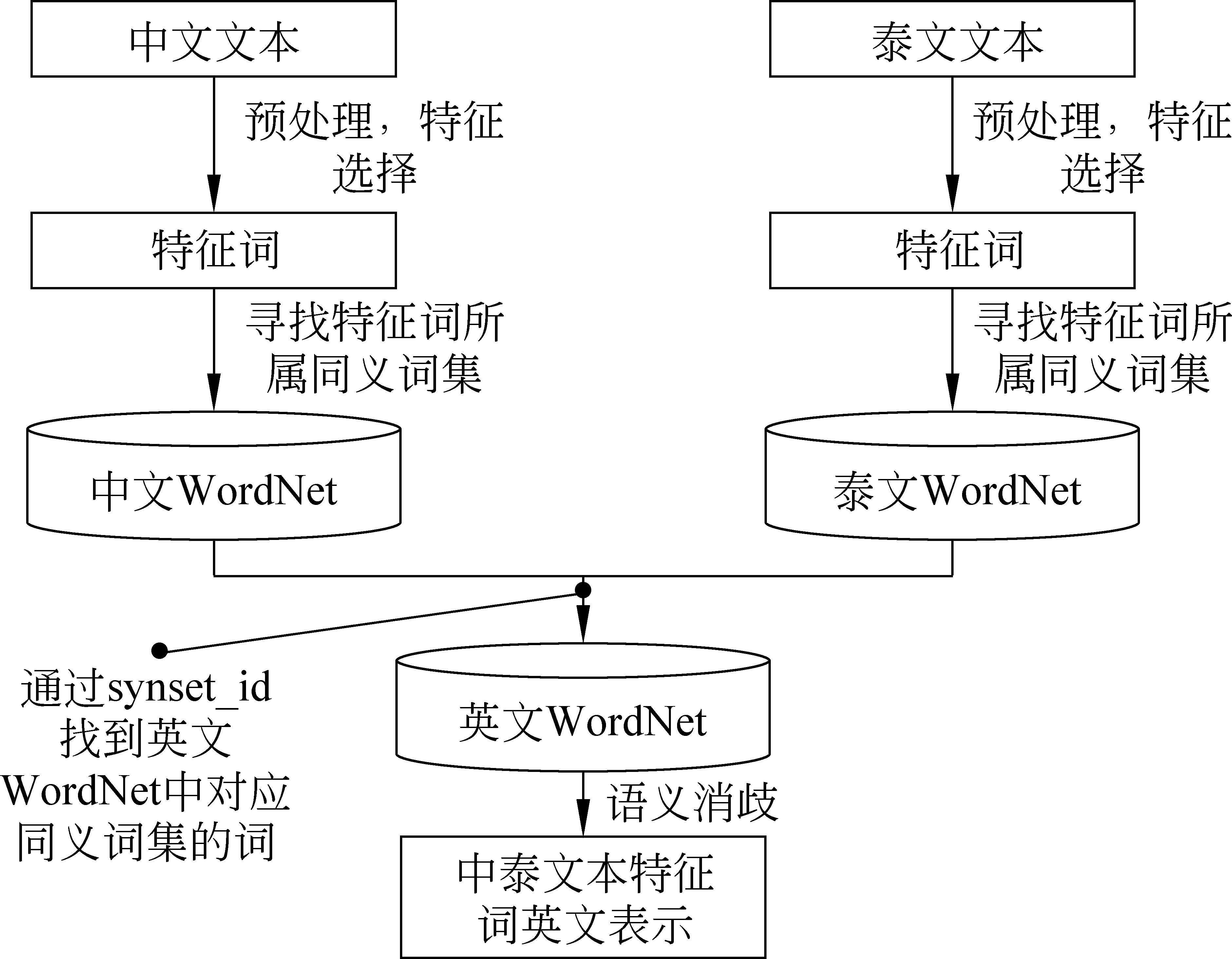
图1 中、泰语言空间转换
通过图1的方式将中文和泰文转换成统一的中间层英语语言空间,我们只需在英语空间上计算中泰文文本的相似度即可。
2.4 语义消歧
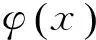
1) 任意x1≠x2,有φ(x1)≠φ(x2);
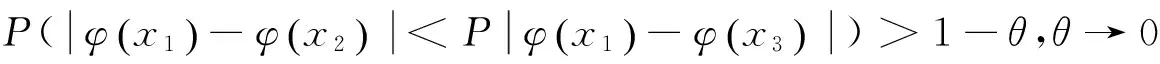
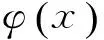
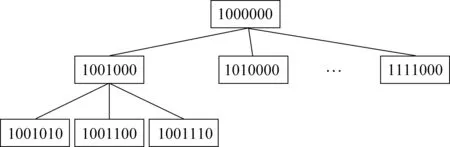
图2 WordNet语义哈希编码示意图
有了语义距离和语义哈希,我们就可以定义语义密度来量化一组词之间的语义相关性。对于一组同义词集w1,w2,…,wn,它们的语义密度density(w1,w2,…,wn)可以由n3与包含所有w1,w2,…,wn的最小子树的“体积”Vmin(w1,w2,…,wn)的商,如式(1)所示。
(1)
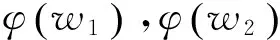
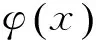
2.5 中、泰文本相似度计算
计算两个文档相似度一般用它们对应向量的夹角余弦值来表示,如式(2)所示。
(2)
其中Wik和Wjk分别表示文本Di和Dj第K个特征词的权值,权值计算采用IDF-TF算法。这种计算相似度的方法的假设前提是: 词与词之间是没有语义关系的。但是现实文本中的词往往都是有关联的,比如同义关系、上下位关系等。因此,本文使用语义词典WordNet来计算中、泰文本特征词之间的相似度。
基于WordNet的词语语义相似度计算,目前有两大类算法: 基于路径、基于信息内容(Information Content,IC)。本文采用基于IC的相似度算法。
基于信息内容的相似度算法是以WordNet中每个概念的IC值作为参数,由Resnik[11]首次提出。IC表示为-lgp(c)(在信息论中,称为自信息)。Resnik认为,两概念的相似度由包含两概念的最深层的公共父节点来决定,只需求出该公共父节点的特征值,就可以得到两概念的相似度值。Resnik的算法模型如式(3)所示。
(3)
lso(c1,c2)表示概念c1,c2在is_a树中最深层的公共父节点,p(c)表示遇到概念c的实例的概率。该类代表算法为Lin算法[12]。Lin的语义相似度算法考虑定义一个通用的计算相似度的方法,算法模型如式(4)所示。
(4)
基于IC的相似度算法的性能优越性主要是由概念IC值的精确性和将IC参数引入算法的合理性来决定。因此,对IC参数模型进行改进,可以提高算法的性能。Nuno[13]对IC模型的改进算法如式(5)所示。
(5)
hypo(c)表示概念c的所有子节点,maxWN表示分类树中所有概念的数目。Nuno的模型只是考虑概念的子节点数是有局限性的,本文给出一种改进过的IC求解模型,将概念在分类树中的深度考虑在内,算法模型如式(6)所示。
(6)
k介于0到1之间,本文取k=0.5。
考虑到Lin算法的通用性,将式(6)带入式(4),得出新的求解相似度模型如式(7)所示。
(7)
式(7)是对WordNet中两个概念求相似度,求解词相似度算法如式(8)所示。
(8)
其中,c1i,c2j为w1,w2的若干概念。
假设中文文本CH的特征词{CW1,CW2,…,CWn},转换成中间层语言,进行语义消歧后得到对应的英语义项{CE_W1,CE_W2, …,CE_Wn};泰文文本T的特征词为{TW1,TW2,…,TWk},用同样的方式得到英语义项{TE_W1,TE_W2,…,TE_Wk},结合式(8),则求解CH和T的相似度的公式如式(9)所示。
(9)
计算结果介于0到1之间,0表示不相似,1表示完全相似,数值越大表示两个文本越相似。
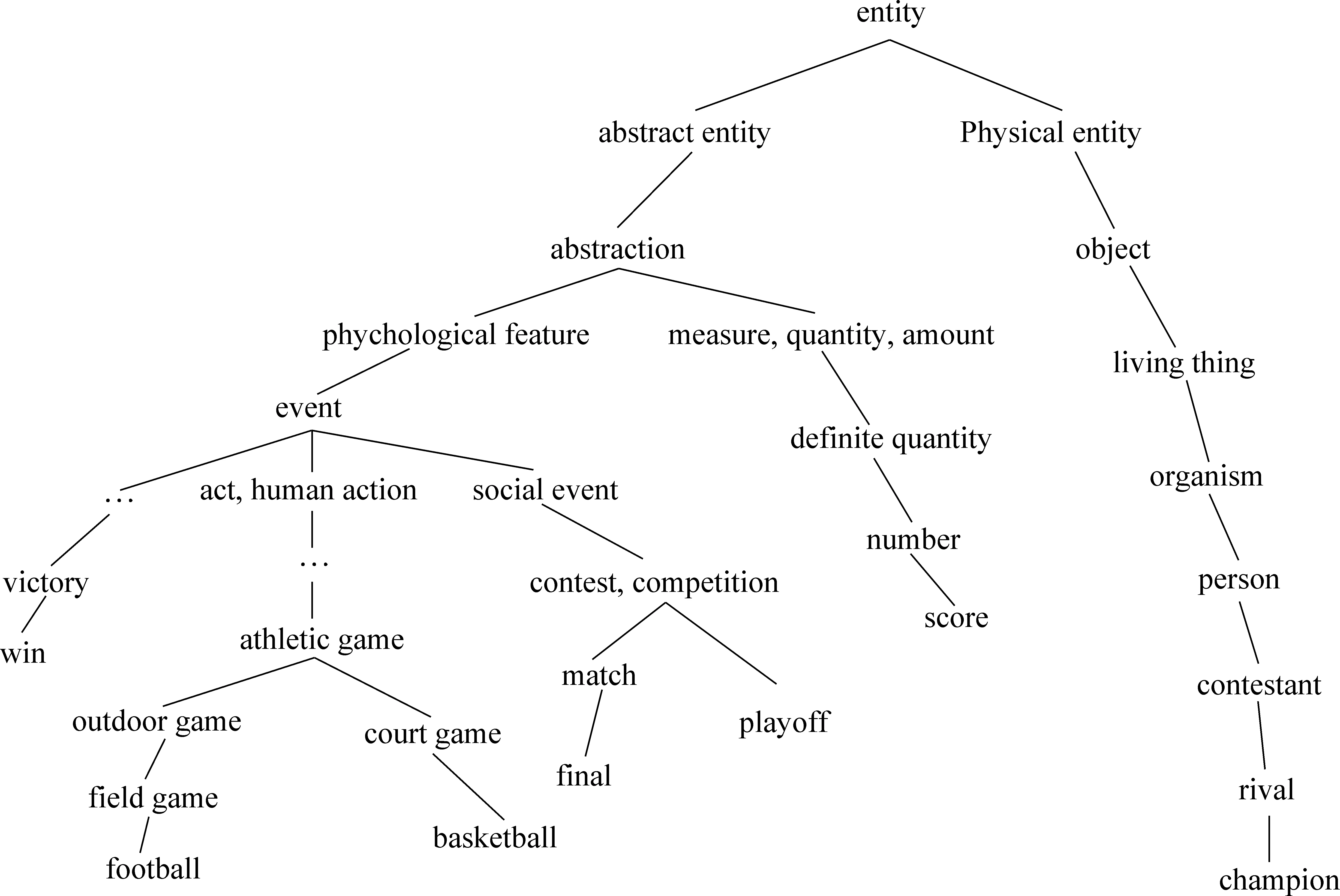
图3 WordNet is_a树

3 实验及分析
首先对本文提出的语义消歧算法进行实验测试,为后文计算中泰文本相似度实验提供更准确的特征词义项。实验选用一个公开的语义标注语料库SemCor,SemCor的单词语义是基于WordNet标注的,用词性标注工具TreeTagger进行POS标注,将标注结果作为消歧算法的输入,将算法的消歧结果与SemCor中人工标注的结果进行对比,得到本文消歧算法的准确率。表1列出了SemCor中前10篇文档的消歧准确率。作为对照,表中基准列表示随机猜测时的消歧准确率。例如,一个词有五个同义词集(即义项),那么随机猜测的准确率为20%,即基准为20%。
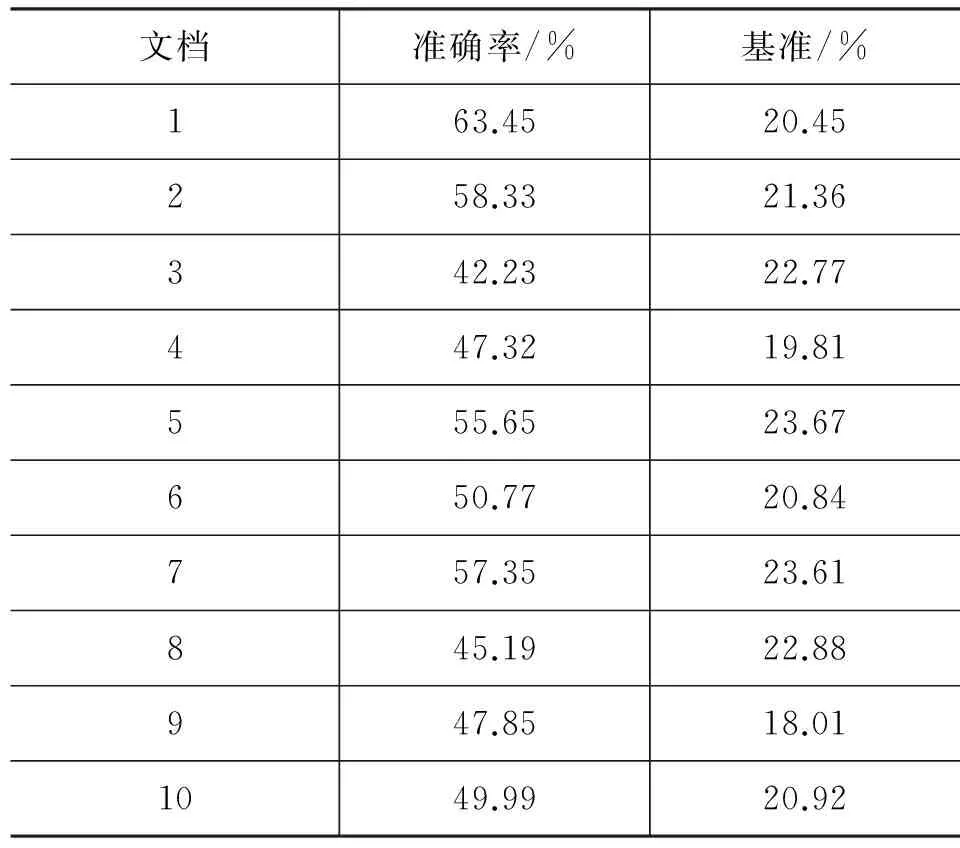
表1 消歧实验结果
消歧算法在SemCor上的平均准确率达到51.8%。
接下来对本文计算中泰文本相似度进行试验。本文实验的文本数为1 000篇文本,中文文本900篇,泰文文本100篇。其中,600篇中文文本为噪音文本,构成噪声集;另外,300篇中文文本和100篇泰文文本构成标准集,并按中文文本和泰文文本两两间的相似度可分为20类,每个类中有13到17篇中文文本不等,也可以这样理解,在标准集中,每篇泰文文本都有13到17篇人为觉得相似的中文文本。将噪声集和标准集混合构成测试集进行试验,如下:
从标准集100篇泰文文本中顺序抽出一篇文本,然后计算这篇泰文文本与测试集中文文本之间的相似度,按照相似度大小排序,输出相似度最大的前17个,然后人为观察输出结果,如果与该篇泰文文本属于同一类的中文文本都被输出,则认为本次计算相似度成功。本文使用空间余弦的相似度算法与本文的算法作比较。
实验结果计算公式如式(10)所示。

(10)
实验数据如表2所示。
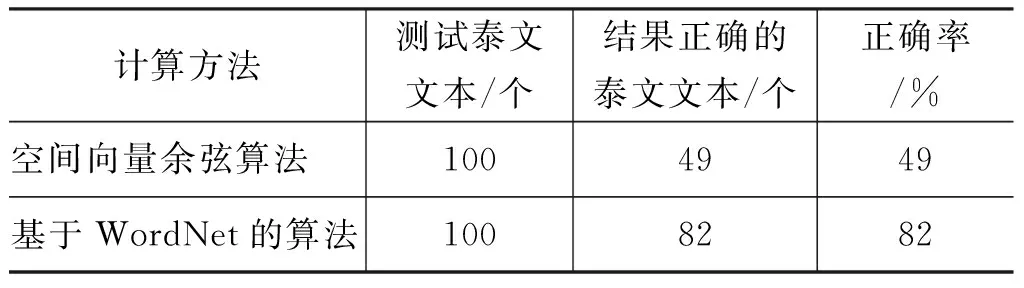
表2 实验结果对比表
实验结果表明: 本文所采用计算中泰文跨语言文本相似度的方法更接近人工评断的结果。
4 结束语
本文提出了一种基于WordNet的中泰文跨语言文本相似度计算方法,通过将中泰文本转换成中间层语言空间,并在中间层计算中泰文本的相似度。实验结果表明本文提出的方法取得了较好的结果。在以后的工作中,考虑进一步改进IC模型,将WordNet中概念的子节点的空间结构加入模型中,这样做的目的是获得一个更加精确的IC值,提高本文算法的精确度。
[1] 李红莲,何伟,袁保宗. 一种文本相似度及其在语音识别中的应用[J]. 中文信息学报,2003,17(01):60-64.
[2] 宋玲,马军,连莉,张志军. 文档相似度综合计算研究[J]. 计算机工程与应用,2006,30:160-163.
[3] 金博,史彦军,滕弘飞. 基于语义理解的文本相似度算法[J]. 大连理工大学学报,2005,02:291-297.
[4] Maike Erdmann, Andrew Finch, et al. Calculating Wikipedia Article Similarity Using Machine Translation Evaluation Metrics[C]//Proceedings of the 2011 IEEE Workshops of International Conference on Advanced Information Networking and Applications (WAINA ′11). IEEE Computer Society, Washington, DC, USA, 2011: 620-625.
[5] Barrón-Cedeno A, Rosso P, Pinto D, et al. On Cross-lingual Plagiarism Analysis using a Statistical Model[C]//Proceedings of the PAN. 2008.
[6] Potthast M, Stein B, Anderka M. A Wikipedia-based multilingual retrieval model[M].Advances in Information Retrieval. Springer Berlin Heidelberg, 2008: 522-530.
[7] Steinberger R, Pouliquen B, Hagman J. Cross-lingual document similarity calculation using the multilingual thesaurus eurovoc[M].Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2002: 415-424.
[8] Miller G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
[9] 王石,曹存根. WNCT:一种WordNet概念自动翻译方法[J].中文信息学报,2009,23(4):63-70.
[10] 张俐,李晶皎,胡明涵,姚天顺. 中文WordNet的研究及实现[J]. 东北大学学报,2003,04:327-329.
[11] Resnik P. Using information content to evaluate semantic similarity in a taxonomy[J]. arXiv preprint cmp-lg/9511007, 1995.
[12] Lin D. An information-theoretic definition of similarity[C]//Proceedings of the ICML. 1998, 98: 296-304.
[13] Seco N, Veale T, Hayes J. An intrinsic information content metric for semantic similarity in WordNet[C]//Proceedings of the ECAI. 2004, 16: 1089.
Chinese-Thai Cross-language Text Similarity Computing Based on WordNet
SHI Jie1,2, ZHOU Lanjiang1,2, XIAN Yantuan1,2, YU Zhengtao1,2
(1. School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming, Yunnan 650500, China;2. Key Laboratory of Intelligent Information Processing,Kunming University of Science and Technology,Kunming, Yunnan 650500, China)
Text similarity calculation is widely used by information retrieval, question answering system, plagiarism detection and so on. At present, most research just aim at text similarity of the same language, and research on cross-language text similarity calculation remains an open issue. This paper propose a WordNet-based method of Chinese-Thai cross-language text similarity calculation. We apply the semantic dictionary WordNet to convert the Chinese text and Thai text into a middle layer language, and compute the text similarity between Chinese and Thai in the middle layer. Experimental results show that, this paper’s method of computing the similarity between Chinese text and Thai text has 82%’s accuracy.
WordNet; middle layer language; cross-language text similarity

石杰(1989—),硕士研究生,主要研究领域为自然语言处理与嵌入式系统研究。E-mail:254089809@qq.com周兰江(1964—),通信作者,硕士生导师,副教授,主要研究领域为自然语言处理与嵌入式系统研究。E-mail:915090822@qq.com线岩团(1981—),讲师,主要研究领域为信息检索、自然语言处理。E-mail:195426286@qq.com
1003-0077(2016)04-0065-06
2014-01-04 定稿日期: 2015-05-04
国家自然科学基金(61363044)
TP391
A
