新疆工业经济预测模型构建——来自克强指数
2016-04-07陈小昆,王静怡
新疆工业经济预测模型构建
——来自克强指数
陈小昆,王静怡
(新疆财经大学 统计与信息学院,新疆 乌鲁木齐830012)
内容提要:本文在借鉴国内外学者己有研究成果的基础上,借助新疆2003年—2013年克强指数相关指标的季度数据,运用非参数回归模型和对数线性回归模型进行建模,预测新疆工业增加值的变化,进而预测新疆工业增加值对新疆宏观经济发展的影响。结果表明,通过克强指数相关指标建立的模型可以及时快速地反映出工业经济变化,且这些模型对工业增加值的预测有很好的效果。
关键词:克强指数;工业增加值;非参数回归;对数回归
一、问题的缘起
2015年3月由国家发展改革委、外交部、商务部联合发布的《推动共建丝绸之路经济带和21世纪海上丝绸之路的愿景与行动》一文中明确将新疆定位为丝绸之路经济带核心区,这势必对新疆经济的发展产生巨大的影响。那么,新疆经济结构将会发生怎样的变化?这一问题值得研究。无论是经济理论还是实践经验都表明,工业化是世界各国经济发展的普遍规律、基本内容和轨迹,没有工业化就没有经济发展。*钱纳里,等.发展的型式:1950—1970[M].李新华等译.北京:经济科学出版社,1988.从这一意义上说,工业的发展变化也预示着整体经济的变化。因此,我们可借助新疆工业的变化来管窥新疆经济的变化。
何川(2006)利用时间序列分析的理论和方法,借助我国2001年—2005年各月工业增加值的历史数据,通过建模对经济变化进行短期预测;叶允最(2013)采用加权最小二乘法与向量自回归方法,建立了广西工业总产值与克强指数间的关系模型,发现克强指数能较准确地预测广西工业经济的变化;祝煦和黄正勇(2014)利用2008年—2011 年的相关指数的月度数据,建立了一元和二元时间序列ARIMAX模型,运用ADF检验对各变量数据的平稳性进行了检验,根据AIC、SBC准则选择最优模型,从而预测经济的变化;陆伟军和宋泽龙(2014)采用普通最小二乘法建立了中国国内生产总值增长率与克强指数相关指标之间的关系模型,发现克强指数对中国经济的预测准确性较高;张潇方和张应应(2014)依据1985年—2013年的GDP和克强指数等基本数据,分别比较GDP和克强指数对城镇居民家庭人均可支配收入的相关性和影响程度并进行回归分析,用2010年—2013年的实际数据加以验证,最终得出克强指数比GDP更能反映中国经济的现实状况;余剑秋(2015)选取我国2000年—2013年克强指数,运用最小二乘法原理,通过计量研究进行多元回归分析,发现运用克强指数对经济的变化进行预测更为有效。
克强指数*克强指数=工业用电量增速×40%+中长期贷款余额增速×35%+铁路货运量增速×25%是英国著名政经杂志《经济学人》创造的用于评估中国GDP增长量的指标,以中国国务院总理李克强的名字命名。克强指数以工业用电量、铁路货运量和银行中长期贷款余额三项指标通过加权平均构造。研究表明,运用克强指数对经济发展进行预测较为有效,因此,本文将借助克强指数,通过非参数回归模型和对数线性回归模型,构建新疆工业经济预测模型,并对其有效性进行验证。
二、预测模型的构建
(一)预测模型构建的依据
工业用电量是经济快速增长的一种证明,我国工业用电量占全社会用电量的70%,被视为能反映经济活跃程度的微观指标;经济增长离不开电力的刚性支撑,工业用电量的多少可以准确地反映我国工业生产的活跃度以及工厂的开工率。而对于间接融资占社会融资总量高达84%的我国而言,中长期贷款的多少既可反映市场对当前经济的信心,又可判断未来经济的风险度;中长期贷款的增长可以有效支持实体经济的发展,从而扩大内需、促进宏观经济发展。铁路作为承担我国货运的最大载体,铁路货运量的多少既能反映经济运行现状,又可反映经济运行效率,其在某种程度上是经济发展的晴雨表,并与企业开工率以及企业生产能力是否充分发挥等都有着密切的联系。在一定环境下,当社会经济在一定时期内发展比较平稳时,铁路货运量就比较饱满;而当经济发展遇到一些问题时,就会出现企业开工不足或者产量不足等问题,就可能导致铁路运输的货运量下降。因此,工业用电量、铁路货运量和银行中长期贷款余额均为国民经济运行的先行指标,即它们是反映未来经济发展变化的重要经济指标。这三项指标的高峰和低谷顺次出现在经济周期的高峰和低谷之前,因而对未来的经济状况有预示的作用。鉴于此,政府和企业可以参考这些指标来分析未来经济发展的状况,从而采取恰当的策略。
综上所述,本文将运用克强指数中的工业用电量、铁路货运量和银行中长期贷款余额三项指标来代表影响新疆经济状况的主要指标,运用工业增加值来代表地区工业发展水平,以此来构建新疆工业经济预测模型。
新疆工业生产与能源消耗密切相关,因此克强指数更能精确地反映新疆经济现状。这不仅是因为上述三个指标更切合新疆经济特征,还因为具体数据易于获得和更加真实。因此,通过耗电量权重占比高达40%的克强指数还可以减少对宏观经济的误判。新疆经济的数字增长很大程度上是由行政主导式的投资刺激所导致,但是,行政主导投资在牵涉铁路货运量和银行贷款发放量两个指标较多的同时,却与权重占比最大的耗电量牵涉不大,故而克强指数对经济状况的反映亦更为客观。另外,将克强指数和新疆工业增加值进行拟合也能证实这一结果(见图1)。

图1:工业增长速度和克强指数的曲线拟合
(二)预测模型的构建
1.构建思想。本文拟通过构造对数线性回归预测模型来预测新疆工业经济的变化,但从理论上说,这一模型可能会存在共线性问题。根据现实情况,学者们运用不同方法解决共线性问题。本文拟运用解决共线性最常用的主成分和岭回归的方法解决这一问题。因此,对新疆工业经济的预测就会产生两个模型,判断这两个模型哪一个更合适,就存在模型精度检验问题。本文拟通过误差项大小来最终确定哪个模型更适合预测新疆工业经济发展情况。
2.构建步骤。首先选择变量,构建模型。根据前文理论分析,本文将工业增加值确定为被解释变量y,将货运量X1、金融机构各项贷款余额X2和发电量X3确定为解释变量,构建如下对数回归模型:
lnyi=B0+B1lnx1+B2lnx2+B3lnx3+ui
其次,解决上述模型是否存在共线性的问题。
第三,计算主成分回归模型和对数岭回归模型的绝对误差和相对误差,以确定最优模型。
三、实证分析
(一)数据来源
本文在分析过程中引用的所有数据均来源于《新疆统计年鉴(2003—2013)》和《中国统计年鉴(2003—2013)》。
(二)实证过程及结果
1.实证过程。首先,对lnyi=B0+B1lnx1+B2lnx2+B3lnx3+ui进行检验,其结果见表1。

表1 货运量、贷款余额、发电量与工业增加值的对数模型
表1显示,lnx1的P值为0.816,大于0.05,说明没有通过系数检验,而lnx2、lnx3的P值分别为0.016和0.000,都小于0.05,说明通过了系数的显著性检验,但是X2和X3的容差(Tolerance)<0.1,而它们的方差膨胀因子VIF>10,这说明贷款余额与发电量存在共线性的情况,由于共线性会使模型估计失真或难以准确估计,因此需要消除共线性再进行模型拟合。
对货运量X1(万吨)、金融机构各项贷款余额X2(亿元)、发电量X3(亿千瓦时)和工业增加值y取对数,分析lnx1、lnx2、lnx3之间的相关程度,lnx1、lnx2、lnx3的相关系数矩阵如下:

从该矩阵中可以看出,lnx1与lnx2、lnx3中度相关,lnx2与lnx3高度相关,故有可能存在多重共线性。
其次,对共线性问题采用主成分法和岭回归法加以解决。
(1)主成分法。主成分法是通过线性变换,将原来的多个指标组合成相互独立的少数几个能充分反映总体信息的指标,从而在不丢失重要信息的前提下避开变量间共线性问题的方法。应用主成分法建立的回归模型见表2:

表2 线性关系检验

表3 拟合优度检验

表4 回归系数的检验


表5 主成分后的模型比较
从表5可以看出,克强指数对新疆工业经济的预测模型为:
lny=-1.84+0.24lnx1+0.45lnx2+0.38lnx3
(1)
模型(1)显示,当货运量每上升1%时,工业增加值平均上升0.24%;同样,在其他变量不变的情况下,当金融机构各项贷款余额每上升1%时,工业增加值平均上升0.45%;在其他变量不变的情况下,当发电量每上升1%时,工业增加值平均上升0.38%。
lny=-1.84+0.24lnx1+0.45lnx2+0.38lnx3
⟹lny=-1.84+lnx10.24+lnx20.45+lnx30.38
⟹lny=-1.84+ln(x10.24x20.45x30.38)
将上式两边取反对数,得到: y=0.159x10.24x20.45x30.38
(2)岭回归法。岭回归法是一种专用于共线性数据分析的有偏估计回归方法,是通过放弃最小二乘法的无偏性,以损失部分信息和降低精度为代价所获得的回归系数更为符合实际和更可靠的回归方法。该方法首先需要确定岭参数,如图2所示:

图2: 岭迹
由图2可知,取对数后的货运量、贷款余额、发电量在岭参数为0.1之前,取对数的发电量的斜率为负增长,这不符合工业增加值与发电量的变化关系,因此要取发电量的对数变化为趋于正值时才能符合正确的工业增加值与发电量的变化关系。当岭参数在0.1~0.2范围内的时候,取对数的发电量的斜率为趋于平缓的变化,而当岭参数取0.2时,取对数的货运量、贷款余额和发电量的变化都趋于平缓,所以本文将岭参数固定为0.2。

表6 岭回归模型
当岭参数固定在0.2的时候,结合以上主成分分析可以得出,对货运量、金融机构各项贷款余额、发电量分别取对数后的对数模型为:
lny=-0.54+0.21lnx1+0.26lnx2+0.48lnx3
(2)
模型(2)显示,当货运量增加一个百分点时,工业增加值平均上升0.21%;在其他变量不变的情况下,当金融机构各项贷款余额增加一个百分点时,工业增加值平均上升0.26%;在其他变量不变的情况下,当发电量增加一个百分点时,工业增加值平均上升0.48%。
lny=-0.54+0.21lnx1+0.26lnx2+0.48lnx3
⟹lny=-0.54+lnx10.21+lnx20.26+lnx30.48
⟹lny=-0.54+ln(x10.21x20.26x30.48)
将上式两边取反对数,得到:y=0.583x10.21x20.26x30.48
2.模型确定。通过模型(1)与模型(2)的误差项对比,最终确定预测模型。将2013年四个季度的克强指数相关指标数据带入主成分回归模型和对数岭回归模型中,得出工业增加值的预测值,并加以计算得到绝对误差和相对误差,其中绝对误差=预测值-实际Y值,相对误差=绝对误差/实际Y值,预测结果及误差比较如表7所示:

表7 预测结果及误差比较
主成分回归模型MAPE=23.08%,对数岭回归模型MAPE=13.64%,结合表7可以看出,对数岭回归模型的预测效果更好。
3.模型预测。首先,对克强指数和新疆经济变量进行描述性统计分析,其结果如表8所示:

表8 描述性统计分析结果
从最大值与最小值来看,货运量最大值达到37136.16万吨,与最小值差别较大,金融机构各项贷款余额、发电量和工业增加值的最大值与最小值相差也比较大,但在这四个变量中货运量的波动范围最大;从均值来看,发电量的均值为158.93亿千瓦时,货运量的均值为14347.76万吨,这反映了变量的整体平均水平;从标准差来看,发电量的标准差最小,说明发电量的离散程度较小,而货运量的标准差最大,也就是说货运量的离散程度最大。

图3:货运量、贷款余额、发电量、工业增加值直方图
从图3直方图可以看出,新疆的货运量在5000~10000万吨的最多,在35000~45000万吨的最少,大部分在5000~20000万吨范围内。由于新疆位于亚欧大陆中部,地处中国西北部,使其物资难以直达内地市场,加之新疆的物流业发展受到基础设施的制约,因而整体货运量不大。贷款余额在2000~3000亿元的最多,在0~2000亿元的最少,大部分在2000~3000亿元范围内,其余的贷款余额分布较均匀,这表明新疆的贷款余额不高。发电量在50~100亿千瓦时的最多,在0~50亿千瓦时的最少,主要集中在50~300亿千瓦时范围内,说明发电量出现较高和较低的频率是很少的;工业增加值在200~400亿元的最多,在800~1000亿元的最少,在800亿元以上的发生频率很小,几近为零,说明新疆工业增加值仍处于较低的水平。
其次,借助模型(2)对2015年第一、二、三季度新疆工业经济进行预测,其结果见表9:

表9 新疆工业增加值的预测
(三)预测模型的补充
任何预测模型的使用都是有条件的,克强指数也不例外。当克强指数在一定范围内时,其对工业经济的预测是有效的,因而需要确定其有效区间,而确定这一区间的方法可使用非参数回归法,其结果如图4和图5所示:

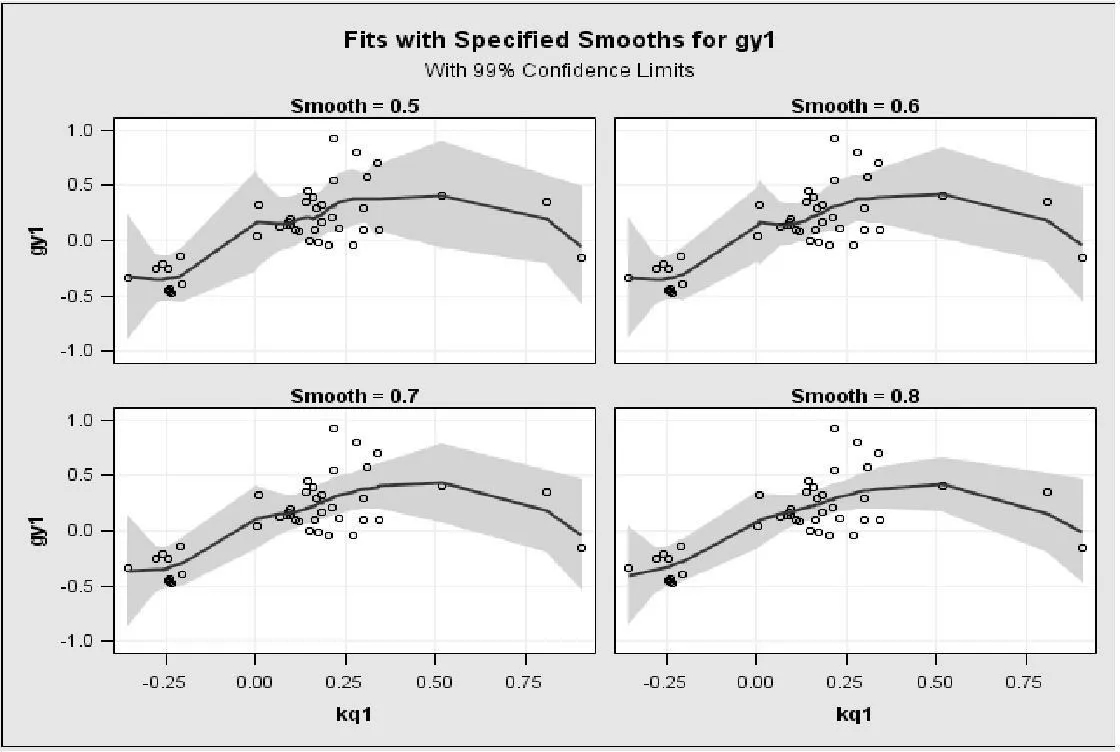
图4:工业增长速度与克强指数的残差图
图5:工业增长速度与克强指数的非参数回归模型
由图4可以看出,残差分布比较均匀,在图5中将平滑系数等于0.5、0.6、0.7、0.8时的图形拟合程度作对比,可以看出平滑系数为0.7时拟合程度较好。当克强指数小于0.5时,随着克强指数的增加,工业增长速度处于不断增加的状态;当克强指数大于0.5时,随着克强指数的增加,工业增速开始下降。因此,当克强指数小于0.5时对工业增长速度的预测较为准确,当克强指数大于0.5时预测失效。
四、模型构建的不足
通过本文可以看出,引入非参数回归模型与对数回归模型能较好地提高预测的精度,使相对误差大大减小,并且这种方法操作简单,再加上采用了克强指数相关指标为研究对象,使得工业增加值的预测更为精确,这为其他经济指标的预测提供了参考,也为政府宏观经济决策提供了科学依据。但同时本文也存在一些不足:首先,用发电量代替了耗电量。这是因为耗电量数据难以获得,若能找到耗电量数据,模型拟合程度会更好;其次,本文用主成分法处理共线性还有一定的问题,且没有考虑数据的季节性和周期性的影响,如果有更好的处理共线性问题的方法并充分考虑相关因素,模型精度会更高;第三,建模过程表明,数据自相关、共线性和异方差问题应同时考虑,否则会降低模型的实践价值。
参考文献:
[1]何川.关于我国工业增加值的统计建模与预测[D].大连:辽宁师范大学,2006.
[2]叶允最.广西工业总产值与克强指数的关系研究[J].中国证券期货,2013,(6):186-187.
[3]张潇方,张应应.克强指数反映中国经济现实状况的优越性研究[J].统计与决策,2014,(22):30-32.
[4]陆伟军,宋泽龙.中国国内生产总值增长率的相关因素分析——基于克强指数的研究[J].经济视野,2014,(13):188-189.
[5]吴喜之,赵博娟.非参数统计[M].北京:中国统计出版社,2013.
[6]何晓群,刘文卿.应用回归分析[M].北京:中国人民大学出版社,2013.
[7]王建军,宋香荣.多元统计理论、实验与案例[M].北京:中国统计出版社,2014.
[8]余剑秋.关于克强指数变量对经济增长贡献程度计量研究[J].合作经济与科技,2015,(11):12-14.
[9]祝煦,黄正勇.修正的克强指数与GDP 增长率时间序列建模分析[J].洛阳师范学院学报,2014,(11):111-115.
[10]陈飞,高铁梅.结构时间序列模型在经济预测方面的应用研究[J].数量经济技术经济研究,2005,(2):95-103.
[11]李闽榕,黄茂兴,李军军.省域经济综合竞争力预测模型的构建与精确度验证[J].管理世界,2009,(2):1-11.
(责任编辑:易正兰)
Xinjiang Industrial Economic Forecast Model——From Keqiang Index
Chen Xiaokun,Wang Jingyi
(Xinjiang University of Finance and Economics, Urumqi 830012, China)
Abstract:Based on the existing research achievements of scholars at home and abroad, this paper, with the quarterly data from 2003—2013 parameters related to Keqiang Index in Xinjiang as the object of study, using the nonparametric regression model and log-linear regression model to model, predicts the change of industrial added value, as well as the influence of industrial added value on macroeconomic development. The result shows that the model built on the basis of relevant parameters of Keqiang Index can reflect industrial economic changes rapidly, and forecast effects towards industrial added value by using these models are pretty good.
Key Words:Keqiang Index; Industrial Added Value; Regression Nonparametric; Regression Logarithm
DOI:10.16716/j.cnki.65-1030/f.2016.01.005
中图分类号:F427
文献标识码:A
文章编号:1007-8576(2016)01-0041-08
作者简介:陈小昆(1963-),女,教授,研究方向:经济统计、市场调查;王静怡(1993-),女,硕士研究生,研究方向:市场调查。
基金项目:新疆维吾尔自治区社会科学基金项目“丝绸之路经济带背景下新疆交通运输系统一体化协调发展研究”(2015BGL101)
收稿日期:2015-09-25
