基于CUDA的RS纠删码性能优化
2016-03-25戴世航李小勇
戴世航,李小勇
基于CUDA的RS纠删码性能优化
戴世航,李小勇
摘 要:目前分布式存储系统中保证数据可用性的常用方法有多副本技术和纠删码技术。与多副本技术相比,纠删码技术有更高的存储空间利用率,但附加的编码流程不可避免地带来了较高的时间延迟,影响了系统的实时性,限制了纠删码的应用。为了提高纠删码的编码效率,对开源代码库Jerasure提供的RS纠删码进行优化,利用CUDA对其进行加速。实验结果显示,相对于原始算法,该方法将编码速度提高了约20倍,为纠删码技术应用于实时系统提供了可能。
关键词:RS纠删码;CUDA;GPU加速
0 引言
如今,人类社会已经进入了大数据时代。随着各种新兴媒体、数据仓库、社交网络的飞速发展,预计2020年数据总量将达到35万ZB。为存储数量如此巨大的数据,各种分布式存储系统应用而生。
分布式存储系统往往建立在大量廉价机器上,系统中节点故障不可避免,如何才能在这样的环境下保证存储数据的高可用性得到了广泛的研究。实践中最常用的方法是多副本技术,通过将文件以多个副本的形式存入存储系统中以实现冗余容错,只要其中一个副本没有损坏,用户就可以正常访问到文件。但多副本技术存储冗余度高这一缺点也随着数据规模增大而日益突出,而纠删码技术在这一方面则具有明显优势。不过由于纠删码的运算开销较大,实时性差,因此可应用的场景受到限制。
本文针对纠删码技术的这一缺点,在开源纠删码库Jerasure[1]提供的RS纠删码reed_sol_r6_op算法(后文简称为r6算法)的基础上,利用GPU强大的并行计算能力,使用CUDA对其进行加速,获得了很好的加速效果,速度可达原始算法的20倍,为纠删码技术在对实时性要求较高的存储系统中应用提供了可能。
1 RS纠删码
纠删码技术的基本思想是:首先将文件分割成k个数据块,然后依照特定的纠删码算法对这k个数据块进行计算得到m个编码块,这一过程被称为编码。编码完成后,在存储系统中分布式存储这这k+m个文件块。当有任何文件块出现错误时,利用其他文件块来恢复它的信息,这一过程被称为重构或者解码。一般而言,一组文件块最多可以容忍m个文件块出错。
和多副本技术相比,纠删码技术的最大特点是大大降低了数据冗余度,提高了存储空间的利用率,减少了存储成本。举例来说,常用的多副本技术一般为每个文件提供3个副本,数据冗余度为300%,存储空间的利用率仅为三分之一;而常用4+2纠删码(为每4个数据块计算得到2个编码块),将数据冗余度降至150%,存储空间的利用率翻了一倍达到了三分之二。纠删码技术在这方面的优异性能也是它得到越来越多关注的原因。
RS纠删码,全称为Reed-Solomon编码,是目前应用最广的纠删码算法,使用特定的生成矩阵计算得到编码块,过程如图1所示:
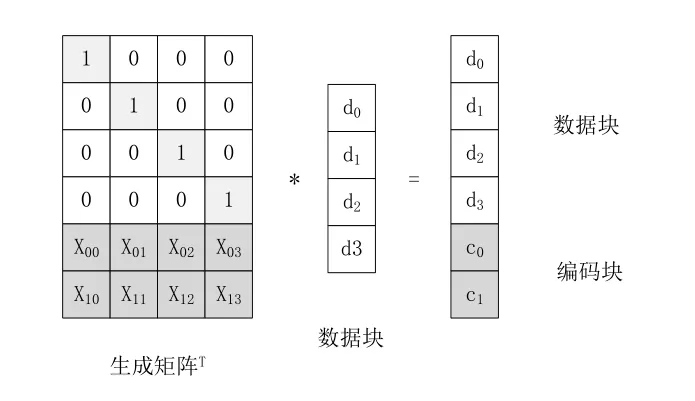
图1 RS纠删码编码过程
RS纠删码最大的特点在于它可以适用于任意k+m的组合。根据生成矩阵的不同RS纠删码被分为两类:一类是范德蒙RS纠删码,另一类是柯西RS纠删码。范德蒙RS纠删码是以范德蒙矩阵为生成矩阵的,而柯西RS纠删码则是以柯西矩阵为生成矩阵的。但无论是哪一种,编码原理都是在有限域上的多项式运算,而有限域上乘法运算极其复杂,这导致其编解码运算速度很慢,时间开销很高。由于这样的原因,RS纠删码在实践中一般用在对实时性要求不高,或者是更新频率较低的云存储系统中[2]。
2 基于CUDA加速的r6算法
2.1 GPU计算优势
GPU最初用于3D图形处理,但经过不断的发展,GPGPU(General Purpose GPU,通用计算GPU)技术得到了不断发展。相对于CPU使用大量晶体管用作复杂的控制单元和缓存以提高少量执行单元的执行效率,GPU将更多的晶体管用作执行单元,因此GPU在处理能力和存储器带宽上有明显优势。同时由于GPU中可以同时运行大量的线程,在并行计算上有着先天的优势。另外,GPU的造价和功耗相对于相同计算能力的CPU要低很多,在一定程度上满足了无法使用高端主机却需要处理海量数据的用户的需求。
2.2 CUDA编程模型
2007年NVDIA公司推出了CUDA(Compute Unified Device Architecture,统一计算设备架构),这是一种将GPU作为数据并行计算设备的软硬件体系,为开发人员有效利用GPU的强大性能提供了条件。
CUDA编程模型采用单指令流多数据流(Single Instruction Multiple Data)执行模式。在这个模型中,CPU 和GPU协同工作,CPU称为主机(Host),负责进行逻辑性强的事务处理和串行计算,GPU作为设备(Device),负责执行高度线程化并行处理任务。运行在GPU上的CUDA计算函数被称为kernel(内核函数),一个完整的CUDA程序时由一系列的设备端kernel并行步骤和主机端的串行步骤共同组成的,如图2所示:

图2 CUDA编程模型
一个CUDA程序中,基本的主机端代码主要完成以下功能:启动CUDA,为数据分配内存和显存空间,将内存中数据拷贝到显存,调用设备端的kernel进行计算,将显存中的结果拷贝到内存中,执行串行代码,释放内存和显存空间,退出CUDA;基本的设备端代码主要完成以下功能:从显存读数据到GPU片中,对数据进行处理,将处理后的数据写回显存[3]。
CUDA通过将计算任务映射成大量的可以并行执行的线程,并由硬件动态调度和执行这些线程来提供给使用者GPU强大的计算能力。为了便于使用和管理这些线程,CUDA将这些线程在2个层次上组织起来,分别是grid中block间的并行和block中thread间的并行,如图3所示:
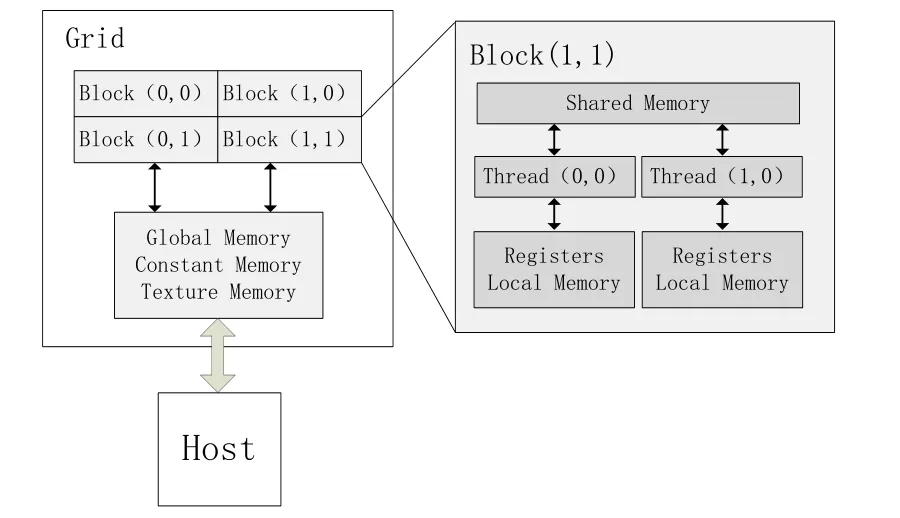
图3 CUDA线程组织形式
kernel实质上是以block为单位执行的,block之间无法通信,也没有执行顺序,但同一block中的thread可以通过共享存储器(shared memory)交换数据,同时每个thread都有独立的register和local memory用于储存计算时所需数据。在kernel运行时,使用者可以通过相应的索引准确定位到grid中的每一个block和block中的每一个thread,进而为每一个线程分配独立的计算任务。从宏观上看,同时可以能有成千上万个线程正在工作,这也是GPU强大计算能力的体现[3]。
2.3 r6算法
传统的RS纠删码能够满足任一k、m的组合,因而有很好的适用性,但正如前文所介绍的,由于在有限域上的乘法复杂度较高,性能不能令人满意,虽然柯西RS纠删码可以可以将有限域上的乘法运算转换成异或运算,但性能提升也比较有限,而且本身的运算依然比较复杂,不易使用GPU运算来进行加速。而r6算法借鉴了阵列纠删码的思想,不再使用矩阵乘法来得到编码块,而是通过对数据块进行异或运算来得到编码块。与阵列纠删码不同的是,r6算法中一个文件的编码块仅由自己的数据块计算得到,而不是跨文件编码。由于不再使用灵活的生成矩阵,r6算法无法应用于任一k、m组合,而是像raid-6一样,将m的值固定为2。算法流程如下:
1)将文件划分成为多个数据块d0、d1、d2、…、dk-1;
2)将d0、d1、d2、…、dk-1通过异或运算得到第一个编码块c0;
3)对每一个数据块进行变换得到d0’、d1’、d2’、…、dk-1’,这里di'= 2i * di,其中0≤i≤k-1;
4)对d0’、d1’、d2’、…、dk-1’通过异或运算得到第二个编码块c1;
本文使用CUDA对步骤2、3、4进行加速,如图4所示:
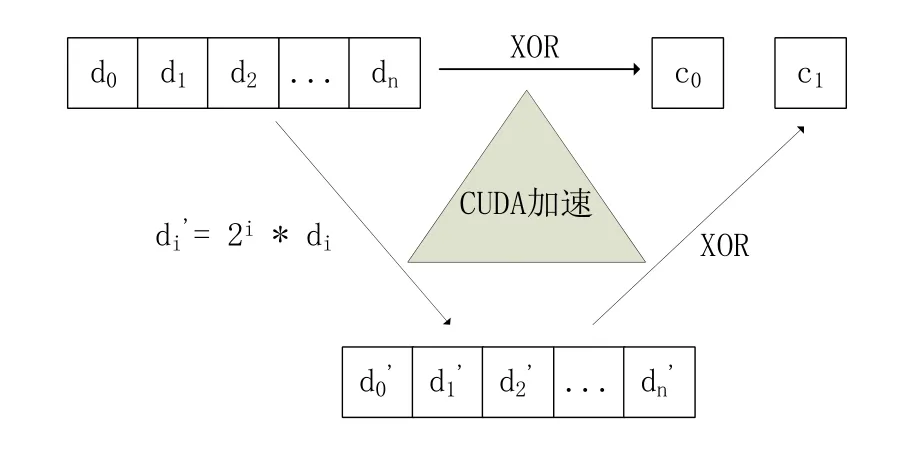
图4 r6算法编码示意图
在r6算法的编码过程中,不再需要生成生成矩阵,也回避了逻辑复杂的有限域上的矩阵乘法,算法实现逻辑简单,大大减少了使用CUDA编程时的工作量。当由于数据丢失需要重构时,该算法与传统k+2 RS纠删码一样,可以在至多两个文件块损坏的情况下恢复出原数据。
虽然在r6算法中,m被指定为2,失去了一定的灵活性。但在实践中依然可以通过调整k值来满足特定的场景需求,比如如果数据比较重要,可以采用4+2的编码方式,而如果存储的是冷数据,可以使用12+2的编码方式,同时还可以通过调整编码时的其他参数来优化编码性能,这些手段也使得该算法在实践中依然具有一定的适用性。
2.4 CUDA加速策略
在编码步骤2、3、4中,需要对待编码的文件块进行规模巨大、但逻辑简单的算术运算,在CPU中,这些无所谓先后顺序运算在循环中串行执行,时间开销巨大,因此对这里使用CUDA进行加速。为充分运用GPU的性能,设定每个block维护1024个线程,这也是一个block最多能够维护的线程数量,然后根据每次处理的数据大小,动态设定grid中维护的block数量。通过这样的修改,将原来由CPU进行的串行运算转换成为由GPU中大量线程同时执行的并行运算,大大减少了时间开销。
在实验过程中,发现虽然单纯的计算过程中使用CUDA加速的代码有着明显的计算优势,但是一旦考虑到申请内存、显存,数据在内存、显存之间传递等操作带来的时间开销,GPU的执行效率便大打折扣。因此如何减少申请内存、显存和数据在内存、显存中传递带来的时间开销成为了优化算法的关键。为此本算法使用了zero-copy技术,使用CUDA提供的API cudaHostAlloc()直接申请不会被换入低速虚拟内存的页锁定内存,并通过cudaHostGetDevicePointer()将页锁定内存映射到设备地址空间,这样GPU便可以直接访问内存中的数据,无须分配显存空间,也不必在内存和显存之间进行数据拷贝,也就是达到了zero-copy的效果,申请空间和数据传输的时间延迟得以回避,使得性能得到了极大的提升。
3 实验与性能分析
实验的环境如下:
CPU:Intel(R) Pentium(R) G630,主频为2.70GHz;
内存:6G;
显卡:GTX 660,显存为2G;
操作系统:Ubuntu 14.04.2。
实验中,使用的纠删码模式为4+2,分别使用大小为154.3MB(文件1)和2.1G(文件2)的文件进行测试,测试结果如图5所示:
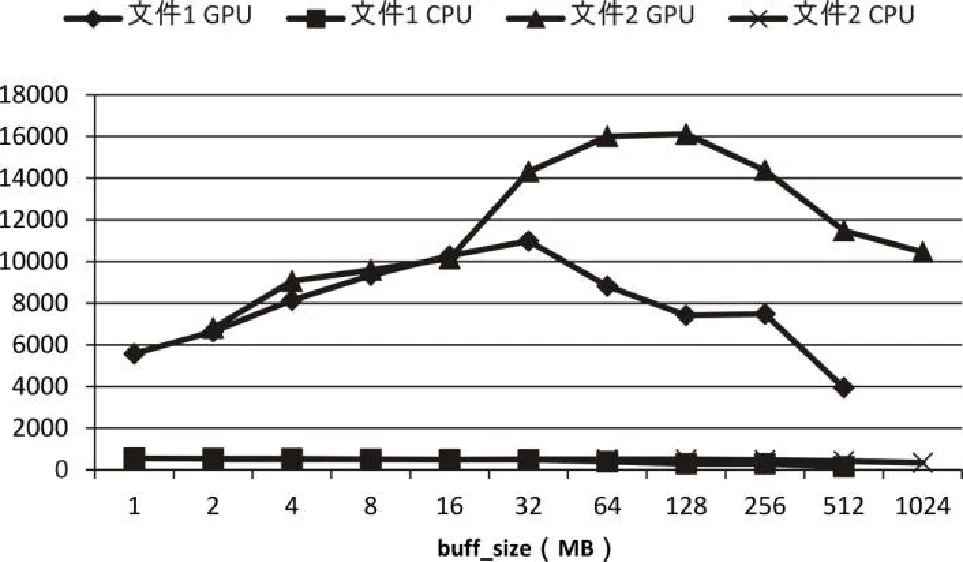
图5 CPU/GPU编码速度测试结果
为排除偶然因素带来的误差,每个数据都是测试10次之后取平均得到的。图中buff_size为每次处理的数据大小。
从实验结果可以看出,无论测试文件大小,使用CUDA加速后的代码编码速度都有大幅度的提升,原r6算法编码速度基本在500MB/s上下,而在CUDA加速后,虽然性能随参数变化有较大波动,但最低也能达到4GB/s,平均速度在10GB/s左右,速度提高了接近20倍。特别是当文件比较大时,如果参数选择合适甚至可以达到16GB/s,达到30倍的加速比。同时从图5中可以看出,随着buff_size的不断增大,编码速度呈现出先增后减的趋势,这是因为虽然在编码时每次并行处理的数据越多,编码越快,但是维护较大内存、显存的开销也会比较大,所以在具体实践中时仍需要根据操作环境的不同,在并行度和内存、显存的维护之间做出适当的折中,选择合适的参数以保证系统有较高的效率。从实验结果可以看出,对于大文件,buff_size选择64MB或者128MB时性能较优。
4 总结
本文以开源纠删码库Jerasure中提供的r6算法为原型,利用CUDA对其代码进行加速,并通过申请、使用页锁定内存,回避了数据在内存和显存中来回拷贝带来的时间开销。经实验测试,经加速后的r6算法编码速度平均可达10GB/s,相当于原r6算法的20倍,为纠删码在实时性要求比较高的分布式存储系统中的应用提供了可能。
参考文献
[9] Plank J S, Simmerman S, Schuman C D. Jerasure: A library in C/C++ facilitating erasure coding for storage applications-Version 1.2[R]. Technical Report CS-08-627, University of Tennessee, 2008.
[10] 罗象宏,舒继武.存储系统中的纠删码研究综述[J].计算机研究与发展,2012,01:1-11.
[11] Nvidia Corporation. NVIDIA CUDA Programming Guide[M]. Santa Clara, USA: Nvidia Corporation, 2011.
CUDA-based Performance Optimization of RS Erasure Coding
Dai Shihang, Li Xiaoyong
(College of Information Security, Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract:At present, the ways used by distributed storage system to ensure the availability of data mainly have multi-replicate and erasure coding technologies. Compared with multi-replicate, erasure coding saves more storage space, however, it takes more time in encoding, which has a bad effect in speed, and limits its application. In order to improve the encoding efficiency of erasure coding, an algorithm provided in the open-source library Jerasure is accelerated by CUDA in this paper. The test result shows that the accelerated algorithm is about 20 times faster than the original one.
Key words:RS Erasure Coding; CUDA; GPU Acceleration
收稿日期:(2015.09.21)
作者简介:戴世航(1991-),男,吉林延边,上海交通大学,信息安全工程学院,硕士研究生,研究方向:云存储、纠删码,上海,200240李小勇(1972-),男,甘肃天水,上海交通大学,信息安全工程学院,副教授,博士,研究方向:海量存储、高性能网络、嵌入式系统、上海,200240
文章编号:1007-757X(2016)01-0070-03
中图分类号:TP311
文献标志码:A
