预计算类ECC标量乘算法高速存储控制电路设计
2016-03-17严迎建
李 博 王 威 严迎建 李 伟
(解放军信息工程大学 河南 郑州 450001)
预计算类ECC标量乘算法高速存储控制电路设计
李博王威严迎建李伟
(解放军信息工程大学河南 郑州 450001)
摘要为提升椭圆曲线密码体制中最耗时的标量乘运算的计算速度,解决采用预计算的快速实现算法中数据存储问题,提取分析了NAF窗口算法、固定基窗口算法、固定基comb算法的存储需求和共性特征,设计了适合ECC处理器的统一寻址电路和向量结构的高效访存电路,有效支持目前具有预计算存储需求的典型算法,并使得访存效率和资源利用率大幅提升。在少量资源消耗下,与传统存储结构相比,访问存储性能提升达75%到95%。
关键词椭圆曲线密码标量乘预计算存储结构
DESIGNING HIGH-SPEED STORAGE CONTROL CIRCUIT FOR ECC SCALAR MULTIPLICATION ALGORITHM WITH PRE-COMPUTATION
Li BoWang WeiYan YingjianLi Wei
(PLA Information Engineering University,Zhengzhou 450001,Henan,China)
AbstractIn order to improve computation speed of most time-consuming scalar multiplication operation in ECC and to solve data storage problem of fast implementation algorithm using pre-computation, we extract the common features and analyse the storage requirements in regard to NAF window algorithm, fixed base window algorithm, fixed base comb algorithm, design efficient access and storage circuit suitable for unified addressing and vector structure of ECC processor, which effectively supports for current typical algorithms with pre-computation storage needs, and significantly enhances the efficiency of access and storage and the resource utilisation. While the resource consumption is few, its performance of access and storage improves up to the range of 75% to 95% compared with traditional storage structure.
KeywordsElliptic curve cryptography (ECC)Scalar multiplicationPre-computationStorage structure
0引言
椭圆曲线公钥密码体制ECC以其运算速度快,占用资源少、单比特安全强度高等特点已成为公钥密码的新标准[1]。标量乘是椭圆曲线密码算法的核心运算,决定着椭圆曲线密码体制的运算速度,如何高效实现标量乘是当前研究的一个热点。在众多标量乘算法中,NAF窗口算法、固定基窗口算法、固定基comb算法等通过采用预计算,成为最具速度优势的一类快速实现算法[2]。椭圆曲线密码体制通常采用专用的ECC处理器进行实现。预计算数据带来了额外的存储资源以及数据频繁访问存储的新问题,这也成为此类算法在处理器中适配的难点和瓶颈。
目前,许多研究者关注于算法本身,通过改进算法[3-6],在保证速度的同时尽量降低存储消耗。但是在算法适配中,依然不可回避资源消耗和数据频繁访问存储问题。ECC处理器中通用的存储结构并不适于这类算法的访存需求,可能造成执行单元工作不流畅,将使算法实现效率降低。为解决存储问题所导致的性能瓶颈,本文对上述三种采用预计算的标量乘快速算法进行了分析,提取预计算数据访存的普遍特征,设计并实现了一种适于预计算标量乘算法的统一的寻址电路和向量结构的高效访存电路,有效解决访存效率问题。
1预计算标量乘算法分析
NAF窗口算法、固定基窗口算法、固定基comb算法是三种具代表性的标量乘算法,本节分别对三种算法进行分析,研究其预计算的特点。
1.1NAF窗口算法分析
非相邻表示型NAF通过对密钥k值重新进行NAF编码,减少了k值中非零元素的个数,从而减少了标量乘算法的点加计算次数,提高了标量乘运算的速度[7]。窗口NAF标量乘算法如算法1所示。
算法1窗口NAF标量乘算法
输出:kP。

2.对于i∈{1,3,5,…,2w-1-1},计算Pi=iP。
3.Q=0。
4.对于i从l-1到0,重复执行
4.1.Q=2Q。
4.2.若ki≠0,则
若ki>0,则Q=Q+Pki。
否则,Q=Q- Pki。
5.返回(Q)。
从算法中易知,窗口NAF标量乘算法需要对窗口值内所有可能的奇数倍点进行预计算,如步骤2。预计算点的形式为iP,i∈{1,3,5,…,2w-1-1}。需要的存储点个数为2w-2,这些点在步骤4.2中被调用参与运算,算法的期望运行时间为[1D+(2w-2-1)A]+[mD+(m/(w+1))A],其中A表示点加运算,D表示倍点运算。
1.2固定基窗口算法
基点P固定的情况下,预计算不占用算法实现时间,采用预计算可获得更高的运算速度,固定基窗口算法如算法2所示。
算法2固定基窗口标量乘算法
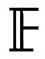
输出:kP。
1.预计算Pi=2wiP,0≤i ≤d-1。
2.A=0,B=0。
3.对于j从2w-1到1,重复执行
3.1. 对于每个使Ki=j的i,执行:B=B+Pi。
3.2. A=A+B。
4.返回(A)。
固定基窗口标量乘算法需要对偶数倍点进行预计算,预计算点的形式为2wiP,0≤i ≤d-1,需要的存储点个数约为d,这些点可能会在步骤3中参与运算,算法的期望运行时间为(2w+d-3)A。
1.3固定基comb算法
固定基comb标量乘算法也是针对基点P固定情况下的快速标量乘运算。comb标量乘算法如算法3所示。
算法3固定基comb标量乘算法
输出:kP。
1.对于所有长度为w的二进制串(aw-1,…,a1,a0),预计算[aw-1,…,a1,a0]P。
2.若需要,则用0填充k的左边,记k=Kw-1//…//K1//K0,其中每个串Kj的长度为d。用Kij表示Kj的第i位。
3.Q=0。
4.对于i从d-1到0,重复执行
4.1. Q=2Q。
4.2. Q=Q+[Kiw-1,…,Ki1, Ki0]P。
5.返回(Q)。
comb算法对于所有可能的位串(aw-1,…,a1,a0)都要进行预计算 [aw-1,…,a1,a0]P,需要的存储点个数为2w-1。这些点将在步骤4.2中参与运算,算法的期望运行时间为(((2w-1)/2w)d-1)A+(d-1)D。
NAF窗口算法、固定基窗口算法、固定基comb算法是三种各具代表性的算法,虽然都采用预计算,但预计算的数据不同,分别为基点的奇数倍点、偶数倍点和连续倍点,且计算量和存储量也各不相同。NAF窗口算法适用于基点未知的情况,后两种算法适于基点固定的情况。其共同特征是预计算的各点将依条件频繁在算法核心步骤中被调用,且选点具有随机性。这涉及到两个问题:一是正确找到点的位置,即统一的寻址电路设计;二是快速存取,即高效读写电路设计。
2预计算标量乘算法存储结构设计
为解决上节提出的问题,本节将对预计算数据的寻址和读写进行分析,并设计统一的寻址电路和向量结构的高效访存电路。
2.1统一的寻址电路设计
统一寻址的理论依据来源于不同算法中的共性特征。分析可知,三种算法都需要根据某个特定值确定取点的位置,对于算法1,该值为步骤4.2中的ki;对于算法2,该值为步骤3.1中的i;对于算法3,该值为步骤4.2中的[Kiw-1,…,Ki1,Ki0]。这里统一用Rk表示。
P的一个坐标x或y占用的存储单元数用VL=L/W表示,其中L为x或y的二进制表示长度,W为存储单元的位宽。VL在寻址中的作用将在后面详细描述。
接下来,将分别对三种算法提取寻址公式:
• NAF窗口算法
对于算法1:奇数倍点的存储,在图1中给出了该情况下的P值存储形式。
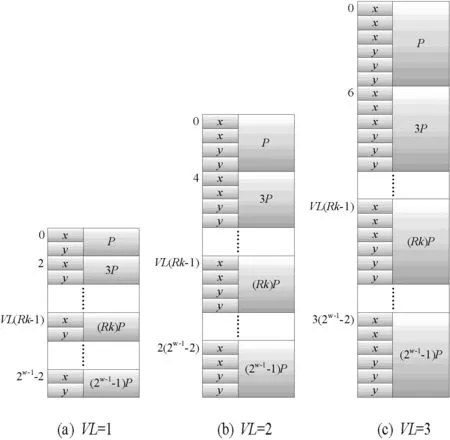
图1 不同VL下P的奇数倍值存储形式
算法1中存储的点为{P,3P,…,(2w-1-1)P},以顺序的方式依次存储。图中(a)、(b)、(c)分别表示VL为1、2、3时的情况,并标出了各点的初始地址。对图1的存储方式,采用数学归纳法,提取出点的初始地址计算公式为VL*(Rk-1),其中Rk∈{1,3,5,…,2w-1-1}。
• 固定基窗口算法
对于算法2:偶数倍点的存储,在图2中给出了该情况下的P值存储形式。
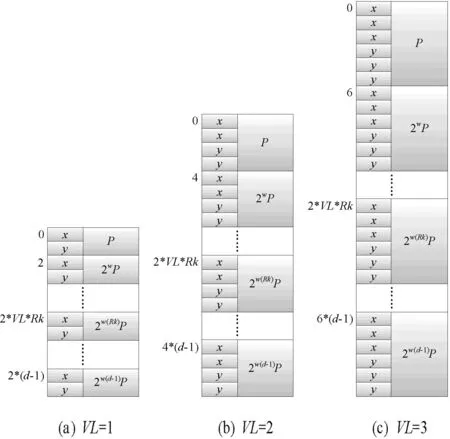
图2 不同VL下P的偶数倍值存储形式
算法2中存储的点为{P,2wP,…,2w(d-1)P},以顺序的方式依次存储。图中(a)、(b)、(c)分别表示VL为1、2、3时的情况,并标出了各点的初始地址。对图2的存储方式,采用数学归纳法,提取出点的初始地址计算公式为2×VL×Rk,其中Rk∈{0,1,…,d-1}。
• 固定基comb算法
对于算法3:连续倍点的存储,在图3中给出了该情况下的P值存储形式。
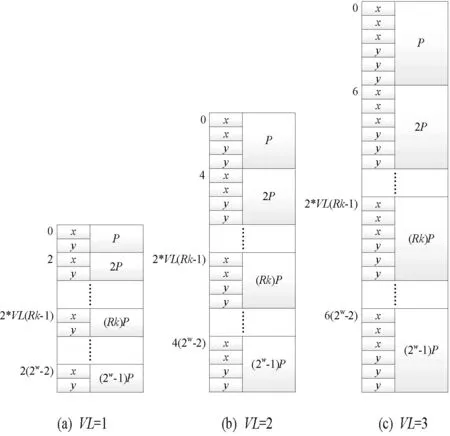
图3 不同VL下P的连续倍值存储形式
算法3中存储的点为{P,2P,…,(2w-1)P},以顺序的方式依次存储。图中(a)、(b)、(c)分别表示VL为1、2、3时的情况,并标出了各点的初始地址。对图3的存储方式,采用数学归纳法,提取出点的初始地址计算公式为2×VL×(Rk-1),其中Rk∈{1,2,…,2w-1}。
综上得到三种算法的初始地址寻址公式如下:
奇数倍点寻址:VL×(Rk-1);
偶数倍点寻址:2×VL×Rk;
连续倍点寻址:2×VL×(Rk-1)。
三个公式形式十分相近,可以采用统一的硬件完成,细微差别可通过设置模式选择信号来确定。
2.2向量读写电路设计
解决寻址后另一个问题就是读写控制,对于普通读写电路,以VL=n为例,取一个点P的坐标x需要n条取数指令,并且要配合地址加一操作,共需要2n条汇编指令,耗费2n个时钟周期。读写操作是频繁的,因此迫切需要提高读写效率。
一个坐标x被分成n个分量 (x1, x2,…,xn)进行存储。这种存储具有向量操作的特点,适于采用向量结构的存储单元[8]。向量操作是单指令多数据流(SIMD)的一种实现,是开发数据级并行性的有效模型[9]。一条向量指令对一组数据指定了相同的操作,相当于完成一个循环操作。向量操作的特点就是单指令多操作,对数据的读取就需要用一条指令读出完整长度的数据。每组数据之间相互独立,不存在相关性,可以实现多个相同操作的并行执行。因此,本文引入向量操作,用一条指令完成存取,以提升取数效率,减少指令数,缩短存取时间。
用一条指令完成一组数据的存取,只需将读写使能信号根据向量长度VL保持n个有效周期,取出一个完整坐标x的n个分量,地址自增加1由硬件配合同步。由此,取点P的一个横坐标x,指令数从2n条降为1条,周期数从2n降为n。
存取时间还存在进一步降低的空间:由于椭圆曲线密码中的参数位宽较大,实现上通常采用小位宽的基本运算单元多次调用或级联拼接来完成,通过流水分割解决数据间的相关性,如图4所示。很多算法理论上支持这样的拼接迭代,实际的算法实现上也通常采用这种策略,即第一组数据分量进入运算模块后即开始运算,相当于存取数据的时间仅为第一个分量存取的时间,其他分量存取与执行时间重叠。因此存取时间进一步缩短至1个时钟周期。
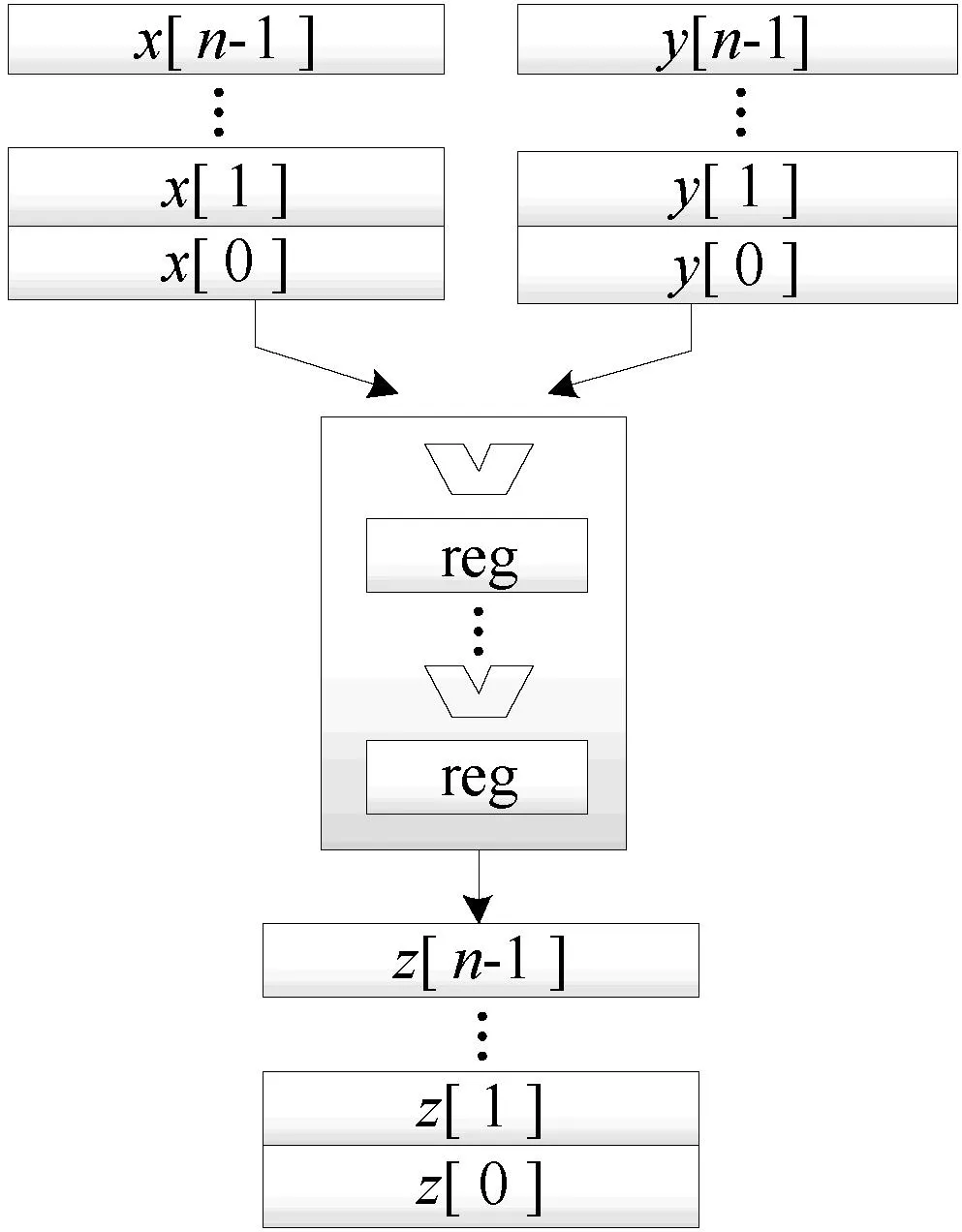
图4 向量指令并行执行模式
2.3设计实现
统一寻址电路和向量读写电路如图5所示。

图5 向量指令并行执行模式
上半部分为向量使能EN_VL产生电路:初始使能信号EN高有效一个周期,表示开始向量操作,经过多级寄存器寄存后的延迟信号,在“*”单元中根据VL的值选择性地进行“或”操作,得到一个保持VL个周期高有效的使能信号EN_VL,即向量使能信号;
下半部分为向量地址产生电路:虚框内为统一寻址电路,通过模式选择信号Mode1和Mode0确定地址生成公式,即分别控制VL是否乘“2”和Rk是否减“1”,以满足三种算法需求。生成的初始地址,在向量使能信号EN_VL高有效的前一个周期存入地址寄存器Addr_reg,向量使能EN_VL高有效的VL个周期中,Addr_reg在各周期内完成自加1操作,产生向量地址信号Addr。
统一的寻址和向量读写电路实现简单,资源占用极少,却可以带来较高的性能提升。
3性能分析
本文的设计在性能提升上体现在两方面:一是该结构支持预计算存储,进而可以适配预计算类快速标量乘算法带来的性能提升;二是向量结构使得指令数减少,访问存储时间缩短带来的性能提升。
3.1支持预计算类算法所带来的性能提升
首先,本文设计的向量存储结构特别适合预计算类标量乘算法,能有效提高标量乘实现效率。三种算法在不同窗口长度w下性能提升程度不同,将其与未采用预计算的原始算法——“从左至右二进制”方法进行对照。在素域上,点加A计算量是倍点D计算量的1.4倍,据此得到各情况下算法期望运算时间与原始算法的百分比如图6所示。
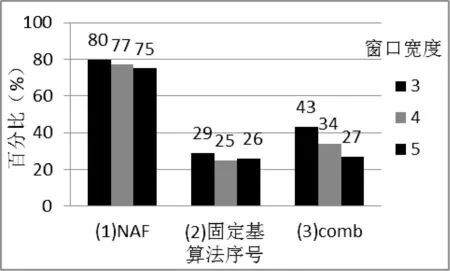
图6 预计算标量乘算法性能提升
从图6可以看出固定基类的算法计算量降低明显,不过其存储点的资源也较大;NAF窗口法计算量降低相对较小,但适用于非固定基的情况,存储需求小。具体选用何种算法需综合考虑性能和资源及应用需求。本文的设计结构对上述类型的算法均能够较好地支持,性能提升范围达20%至75%。
3.2存储结构的性能提升
本文设计的向量结构存储单元,在满足算法需求的必要存储资源基础上,仅增加统一寻址和读写控制电路的少量资源,却带来了访问存储上性能的显著提升。指令条数由2n降为1,间接降低了译码、数据相关等环节的硬件代价,在资源消耗上看,甚至是不增反减的。
访问存储时间的提升十分明显,消耗时钟周期数最大可从2n降为1。以NIST推荐的3种长度椭圆曲线为例,选取长度分别为256、384、521 bit的三类曲线,存储单元基本位宽选用32、64、128 bit,图7中给出了各种情况下的采用向量结构访存时间占普通结构访存时间的百分比。
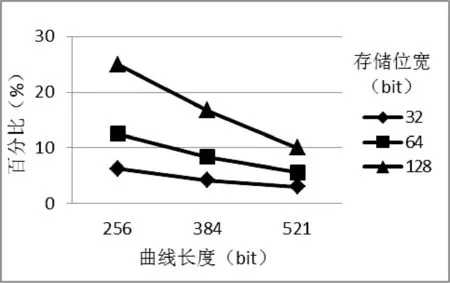
图7 向量结构访存时间占原时间的比率
可以看出,在存储单元位宽相同时,曲线长度越大,访存时间占原时间的比率越小,进而性能提升比率越大;在曲线长度一定时,存储单元位宽越越小,访存时间占原时间的比率越小,进而性能提升比率越大。存储单元位宽的选取应综合考虑各种因素,适合具体应用需求,总体来说,与传统的存储结构相比,节省访问存储时间达75%至95%。
4结语
本文通过对多种预计算类标量乘算法进行分析,提取预计算数据的访存特点,设计了向量结构的存储结构。统一寻址电路和高效的读写电路有效提升了该类算法访存效率,有效减少指令条数,降低译码等硬件代价,减少了循环控制开销,并极大地缩短了存取时间。
参考文献
[1] Hankerson D,Vanstone S,Menezes A J.Guide to elliptic curve cryptography[M].Springer,2004.
[2] 刘斌,瞿新南.椭圆曲线密码体系中标量乘的快速算法研究[J].计算机安全,2013(6):13-16.
[3] Daiyuan B.低存储需求的快速标量乘法算法[J].计算机工程,2012,38(4):137-139.
[4] 刘国柱,祁华欣.优化的低存储NAF标量乘算法[J].科学技术与工程,2013,13(19):5683-5686.
[5] 王玉玺,张串绒,张柄虹.一种改进的固定基点标量乘快速算法[J].计算机科学,2013,40(4):135-138.
[6] 蒋洪波,吴岩,冯新宇,等.基于NAFw的二进制域乘法算法[J].重庆工商大学学报:自然科学版,2012,29(6):47-49.
[7] 赵前进,李西萍,戴紫彬,等.NAF标量乘算法的并行计算研究[J].电子技术应用,2010(7):160-162.
[8] 王永文,陈微,郑倩冰,等.多线程向量处理器中向量数据存储结构的设计与实现[J].计算机研究与发展,2012(1):53-55.
[9] 杨晓辉.椭圆曲线密码专用指令协处理器研究[D].河南:解放军信息工程大学,2011.
中图分类号TP309.7
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.075
收稿日期:2014-05-27。李博,硕士生,主研领域:专用集成电路设计。王威,硕士生。严迎建,副教授。李伟,讲师。
