基于MapReduce的出租车停泊点智能推荐算法
2016-03-17蒋鸿玲
蒋鸿玲 张 楠 李 克 田 昊 葛 伟
(中国航天科技集团公司物联网技术应用研究院 北京 100094)
基于MapReduce的出租车停泊点智能推荐算法
蒋鸿玲张楠李克田昊葛伟
(中国航天科技集团公司物联网技术应用研究院北京 100094)
摘要现有解决打车难问题的研究工作大部分是集中式地调度出租车,且大多方法在单一服务器上运行串行算法分析海量出租车GPS数据,计算量大,会遇到计算时间和计算资源的瓶颈。为此提出一种基于MapReduce的出租车停泊点智能推荐算法,为司机或乘客推荐更容易接到乘客或打到车的地点。算法通过挖掘大量出租车GPS轨迹数据,检测出停泊点,并生成停泊点知识库。再利用推荐模型为司机或乘客推荐最佳停泊点。实验分析了北京市真实出租车GPS轨迹数据,结果表明该算法能有效为司机和乘客推荐出停泊点,且在大数据量下具有较高的效率。
关键词出租车GPS聚类MapReduce停泊点推荐
TAXI PARKING POINT RECOMMENDATION ALGORITHM BASED ON MAPREDUCE
Jiang HonglingZhang NanLi KeTian HaoGe Wei
(Internet of Things Technology Application Institute, China Aerospace Science and Technology Corporation, Beijing 100094,China)
AbstractMost researches on solving the problem of hard to take a taxi are for dispatching taxi centrally. The majority of approaches have huge computation and may encounter the bottlenecks of computation time and calculation resources, because they need to analyse a large amount of GPS data on a single server operating the serial algorithm. So the paper proposes a MapReduce-based taxi parking point intelligence recommendation algorithm. It recommends for drivers and passengers the places where the passengers or taxis are more likely to be met or taken. By mining a large amount of taxi GPS trace data, the algorithm detects the parking points and generates the knowledge base of parking points. Then it uses recommendation models to recommend the best parking points for drivers and passengers. The experiments analysed actual taxi GPS trace data in Beijing. Results showed that the algorithm could effectively recommend parking points for drivers and passengers, and had higher efficiency in large amount of data.
KeywordsTaxiGPSClusterMapReduceParking pointRecommendation
0引言
目前打车难成为城市交通的普遍问题。乘客常打不到车,而很多出租车在路上盲目空载行驶,不仅浪费时间给城市交通带来额外的负担,而且浪费能源,影响城市的环境。现有一些研究关注出租车调度系统和出租车GPS数据分析。文献[1]综述了现有出租车GPS数据分析的研究方向,包括分析城市人群流动情况、分析不同地区和时段的交通拥堵情况、为乘客和出租车司机提供服务等。文献[2]调度空车去乘客数期望最高的地点。文献[3]用概率模型分析司机和乘客选择不同策略时的成本及风险,并为司机或乘客推荐停泊点及路径。文献[4]给司机提供时空收益图,提高司机的收入减少巡航时间。
现有研究工作主要是面向司机,通过分析出租车GPS数据为司机提供增加收益的策略。但出租车GPS数据量很大,以每辆车平均一分钟产生一条GPS记录来计算,一天产生上千条记录,上万辆车则有上千万条记录,而传统的单服务器上运行串行算法的分析效率很低。与现有研究不同,本文的停泊点智能推荐模型不仅面向司机也面向乘客,并采用基于MapReduce的并行算法分析GPS数据,提高了分析效率。本文的停泊点是指出租车司机经常停泊的等乘客的地点,通常是最容易接到乘客的地点,如火车站、购物中心、酒店等。一个有经验的司机通常知道什么时间火车到站,什么时间哪个购物中心打车的乘客多。本文对以往北京市出租车GPS轨迹数据进行分析,利用Hadoop[5,6]平台存储大量GPS轨迹数据,并设计了基于MapReduce[7,8]的并行停泊点检测、聚类等算法,得到停泊点知识库。最后利用停泊点知识库进行在线推荐,为司机和乘客分别推荐不同时段的最佳停泊点。
本文主要贡献:(1)提出了基于MapReduce的停泊点检测算法,能够在GPS轨迹数据量较大时快速有效地检测出停泊点;(2)设计了基于MapReduce的DBSCAN聚类模型对停泊点聚类并计算停泊点簇的属性,进而生成停泊点知识库;(3)利用北京市真实出租车GPS轨迹数据验证本文停泊点智能推荐算法的有效性,并实现了停泊点推荐的原型系统。
1停泊点智能推荐模型与算法
图1是出租车停泊点智能推荐模型框架。该模型分为离线挖掘和在线推荐两部分。离线挖掘在Hadoop平台上运行基于MapReduce的并行算法,主要分3步。(1)对原始GPS轨迹数据预处理,删除噪声,保留对挖掘有意义的数据。(2)检测出租车停泊点。(3)对停泊点聚类形成停泊点簇,进而生成停泊点知识库。在线推荐部分则利用停泊点知识库,设计面向司机和面向乘客的推荐模型,分别为司机和乘客进行推荐。
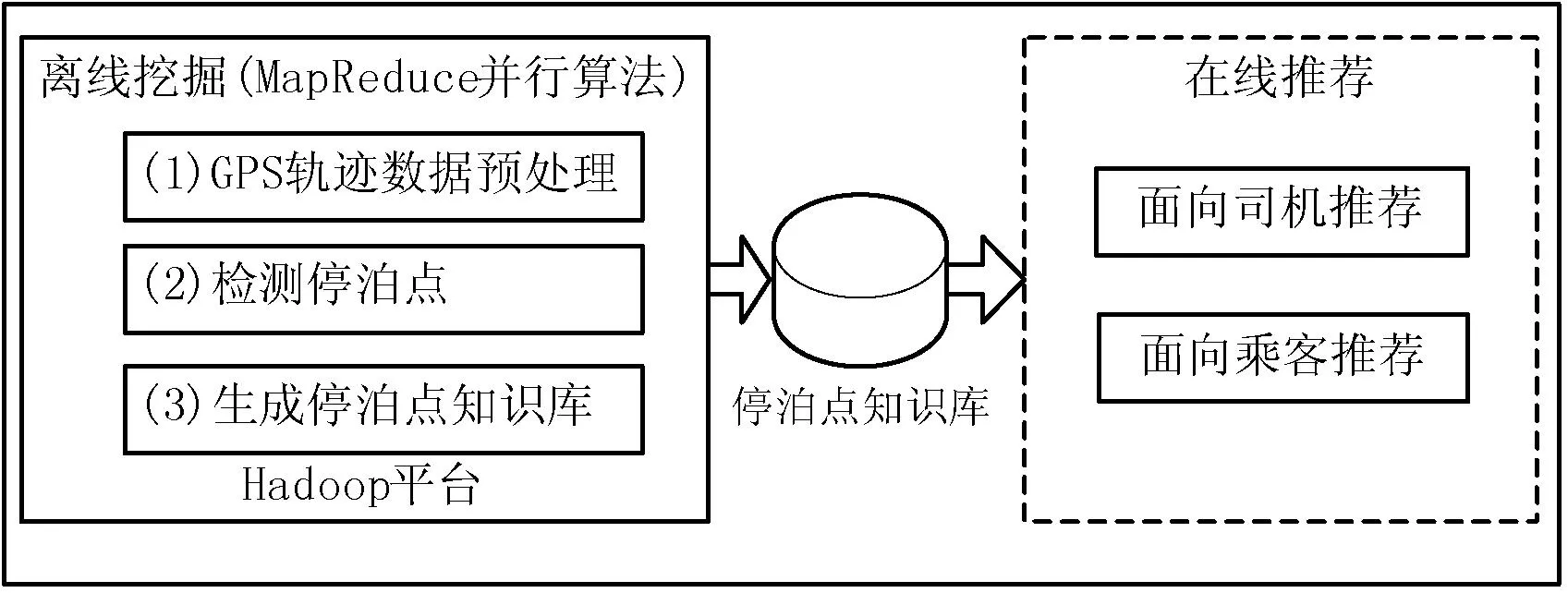
图1 出租车停泊点智能推荐模型框架
2离线挖掘
2.1GPS轨迹数据预处理
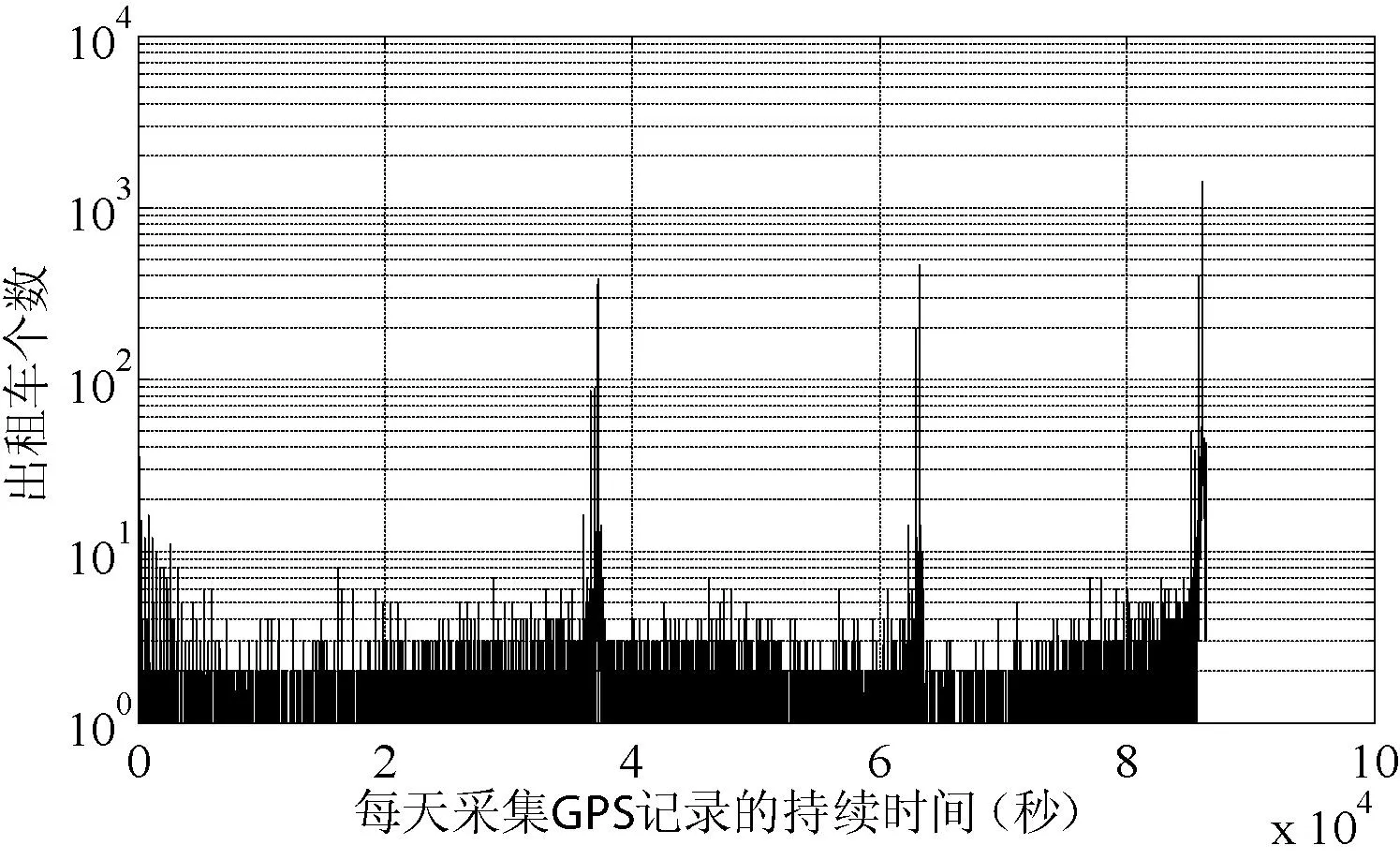
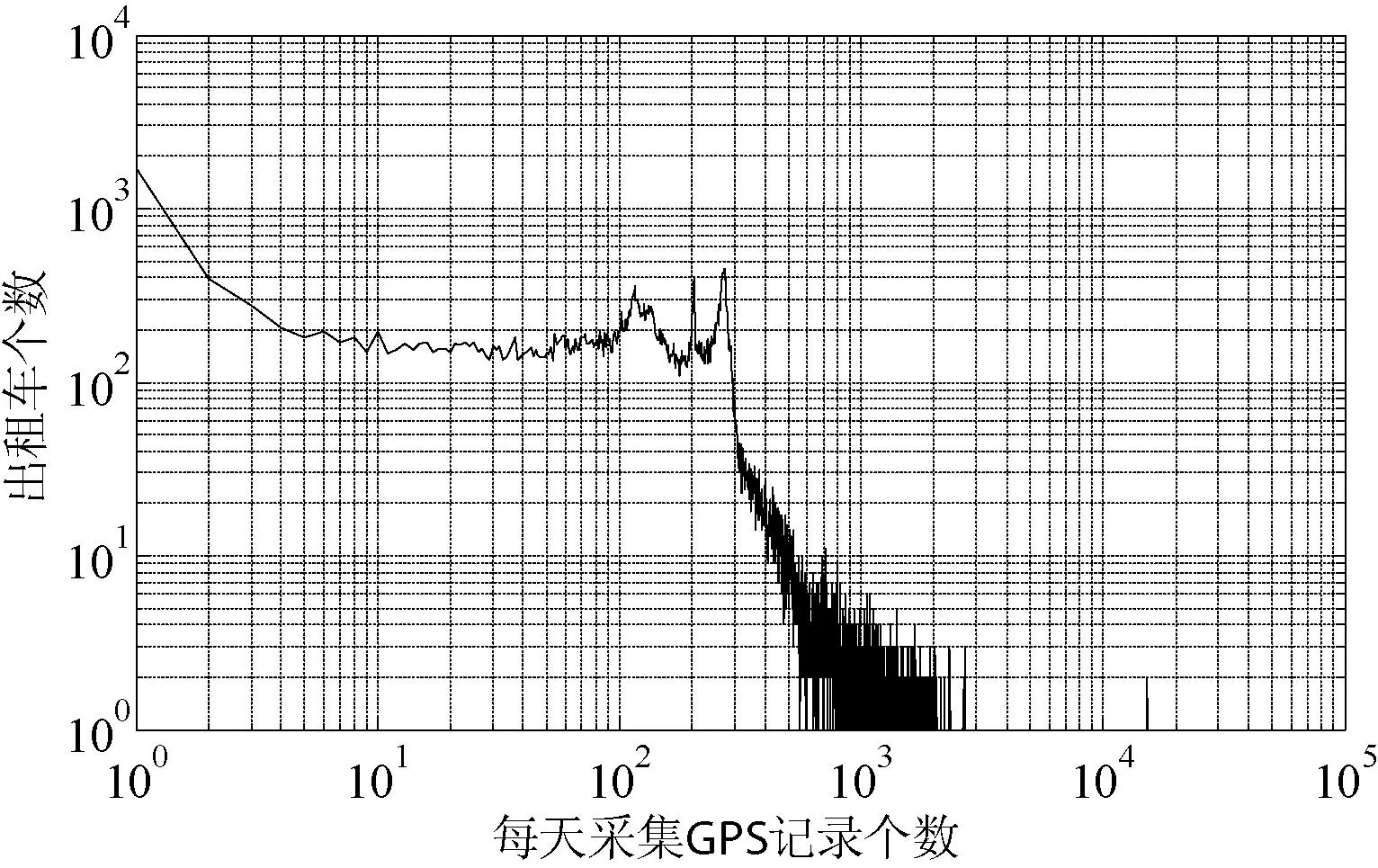
首先删除经纬度异常和完全重复的数据。然后统计每辆出租车每天采集GPS记录的持续时间和记录个数。根据持续时间和GPS记录个数的数据分布情况,对原始GPS轨迹数据进行过滤,保留对挖掘有意义的数据。
2.2检测停泊点
出租车在停泊点等待乘客时,GPS轨迹数据中相邻轨迹点之间的距离很小,且逗留的时间较长。因而停泊点是一组距离较小并且逗留时间较长的GPS点集。本文首先检测候选停泊点,然后对候选停泊点过滤,最后计算停泊点中的所有GPS点集的平均经纬度等,将GPS点集抽象为一个停泊点。
检测候选停泊点的过程即找出一组满足距离和时间阈值的连续GPS点集的过程。给定一个出租车行驶轨迹P1,P2, …,Pn,Pi表示一条GPS记录。依次检测每个点Pi和其后面的点Pi+1,Pi+2,…,Pj的距离是否小于距离阈值Dth,如果小于Dth且时间间隔大于时间阈值Tth,则将点Pi到Pj加入到候选停泊点集合中。然后从下一个点Pi+1开始重复上述过程,直到候选停泊点集合不再加入新的点为止。
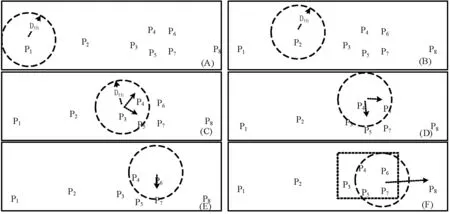
图2是检测候选停泊点示例。GPS轨迹依次为P1,P2,…,P8。检测候选停泊点集合的过程如下:
(1)P1到P2距离dist(P1,P2)>Dth,如图2(A)。
(2) 检测下一个点P2,dist(P2,P3)>Dth,如图2(B)。
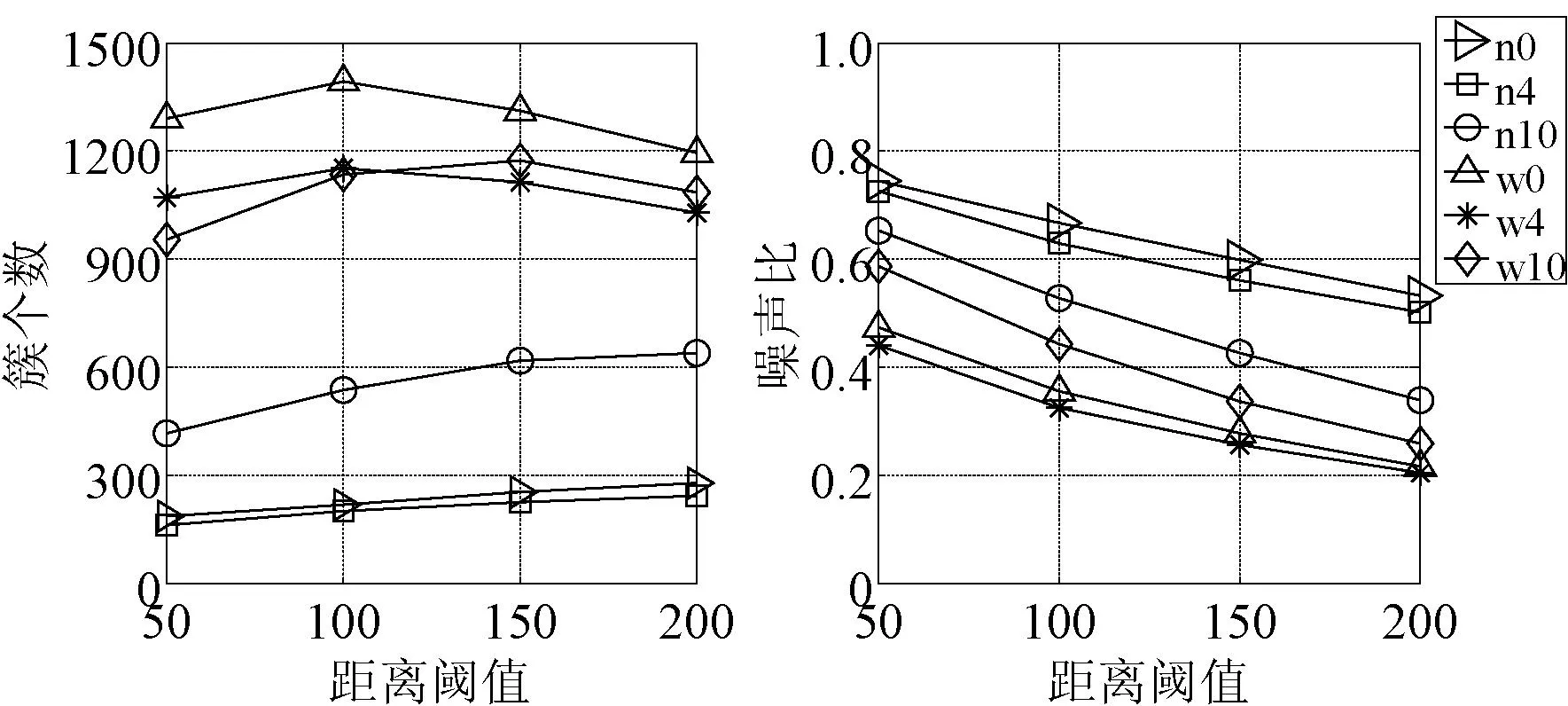
(3) dist(P3,P4) (4) 从P4开始重复上述过程,如图2(D)(E)。 (5) 直到D中不再加入新点,dist(P7,P8)>Dth,如图2(F),则检测出一个候选停泊点D,D是一组GPS点集,包括P3至P7。 图2 检测候选停泊点示例 检测出候选停泊点后,对候选停泊点进行过滤,去掉等待时间过长的点(停泊点对应的GPS点集中第一个点和最后一个点时间间隔大于Tmax的点),如司机在家休息时则会长时间停留。由于停泊点是一组GPS点集,为对停泊点进行高效聚类,需要对停泊点进行处理,用一个点代表一组GPS点集。设停泊点D={P1,P2,…,Pn},其中,P1到Pn是停泊点中的点集,Pi用经度、纬度、日期、时间表示,即(Loni,Lati,Ri,Ti)。停泊点D用集合中所有点的平均经/纬度表示,并记录第一个和最后一个点的日期和时间,则D可表示为(aLon,aLat,sDate,sTime,eDate,eTime)。aLon/aLat表示D中所有点的平均经/纬度,sDate,sTime,eDate,eTime分别是第一个和最后一个点的日期和时间。 2.3生成停泊点知识库 离线挖掘的目的是通过分析挖掘GPS轨迹数据生成停泊点知识库,供在线推荐时使用。停泊点的聚类是将距离相近的停泊点聚到一起。这样做是因为:第一,在同一个热点区域,如地铁站、飞机场等,不同出租车停泊点相近,可以近似为一个大点,以便灵活地对司机和乘客推荐;第二,由于GPS存在误差,不同出租车的停泊点可能在地理位置上是一个点。因此,要对距离相近的停泊点聚类。考虑到距离相近的点形成的簇不一定是球状,可能是任意形状。基于密度的DBSCAN算法生成不规则簇的效果较好,且不需事先确定簇的个数,因而本文采用该算法对停泊点聚类。 由于不同时间段的停泊点不尽相同,因此本文根据时间段对停泊点聚类。将时间从0到23点平均分为12个时间段,第1个时间段的ID为1,从0:00到2:00,第2个时间段的ID为2,从2:00到4:00,以此类推。同时考虑工作日和周末的情况。停泊点数据集按照是否是工作日和时间段被分为24个子集。聚类过程用MapReduce并行算法处理,Map阶段根据时间将数据集划分为24个子集,Reduce阶段用DBSCAN算法对每个子集分别聚类。 停泊点聚类完成后,对聚类结果进行处理,以生成停泊点知识库。该过程主要计算停泊点簇的属性,考虑以下四方面因素:(1)在该簇内停泊的出租车个数。一个司机在此处停泊不一定说明该处打车的乘客多,而多个司机在此处停泊一定程度上说明该处打车的乘客多。(2)等待时间,即出租车在停泊点等待乘客的时间。簇的等待时间为簇中所有停泊点等待时间的平均值。(3)簇中点的紧密程度。如果簇中各停泊点之间的距离越近,说明该簇中的停泊点较紧密,推荐的地点更明确,反之亦然。紧密程度取簇中所有停泊点到簇中心点的距离的平均值。(4)停泊点簇的位置。为司机或者乘客推荐时,要考虑司机或者乘客当前位置到推荐点的距离。用一个点代表停泊点簇,即簇中心点。簇中心点的经纬度为簇中所有点的平均经纬度。据以上分析,停泊点簇的属性包括:出租车的个数、等待时间、到簇中心点距离的平均值、簇中心点的经纬度。 2.4停泊点检测及其知识库生成的MapReduce算法 停泊点检测及其知识库生成的MapReduce过程分4个Job完成,如图3所示。Job1和Job2检测停泊点,Job3和Job4生成停泊点知识库。Hadoop自动将预处理后的GPS轨迹文件分为若干个split块,每个split块大小为64 MB。每个MapReduce任务由Map阶段和Reduce阶段构成,分别用Map函数和Reduce函数实现[9]。 下面分别介绍各MapReduce任务。Job1检测候选停泊点并对其过滤得到停泊点。Job1的输入是预处理后的出租车GPS记录,包括出租车编号(taxiID)、日期(date)、时间(time)、unix时间,即当前时间到1970年1月1日0点的时间之差(unixtime)、经纬度(lon/lat)。Map1输出的key和value中都包含unixtime,这样可利用MapReduce的Shuffle阶段的排序功能,按taxiID分组按unixtime排序,进而提高算法的速度。Reduce1根据2.2节所述过程检测每辆车的停泊点。Reduce1在输出结果前进行过滤,去掉等待时间大于阈值Tmax的停泊点。 图3 停泊点检测及其知识库生成的MapReduce过程 Job2计算停泊点属性,即GPS点集中所有点的平均经纬度、开始/结束时间、时间间隔。Map2的输出按出租车ID(taxiID)和停泊点ID(DID)分组,按停泊点中GPS记录的ID(pIDs)排序。Reduce2计算停泊点的属性并输出。Reduce2输出key是 Job3对不同时间段的停泊点进行DBSCAN聚类。Map3判断每条输入记录是否是工作日并计算时间段ID。Map3输出key中isWorkDay表示是否是工作日,timeID表示时间段ID。value中dur是停泊点的等待时间。Reduce3采用DBSCAN算法对不同时间段的停泊点聚类。Reduce3输出value中cID是聚类后该停泊点所属的簇的ID。 Job4处理聚类结果,输出停泊点知识库。Map4的输出以 3停泊点在线推荐 停泊点在线推荐的目的是为司机和乘客推荐最佳的停泊点。对于司机和乘客,最佳的标准不同,如司机关注是否可以快速接到乘客,即在停泊点等待时间的长短;而乘客关注是否步行较短的路程就可以到达推荐的停泊点。因而,要针对司机和乘客设计不同的推荐模型。 停泊点知识库中存储了停泊点簇的位置及其属性。根据2.3节所述,推荐主要考虑出租车个数、平均等待时间、簇的紧密程度和位置。因此,一个停泊点簇C可以用特征向量表示,如下式所示: C={C1,C2,C3,C4} (1) C1到C4分别表示出租车个数、平均等待时间、簇中停泊点到簇中心点距离的平均值、停泊点距司机或乘客当前点的距离。由于C1到C4的值差别较大,因此要对特征向量归一化处理。将当前每个特征值除以其最大值,使每个特征值的取值范围在[0, 1]内。归一化后的特征向量如式(2),CMaxi(i=1,2,3,4)表示特征Ci的最大值。 (2) 得到归一化的特征向量后,分别针对司机和乘客,计算每个簇C的分数Sc,如式(3),w1到w4是每个特征的权值,取值范围为[-1,1],且w1到w4的和为0。按Sc从大到小对停泊点簇排序,分数越大的停泊点簇越优先推荐给司机或乘客。 (3) 如果是司机,主要考虑在该处停泊的出租车是否较多,多说明该处是一个真正的停泊点,因此w1取大于0的值;司机希望等待较短的时间即可接到乘客,并且簇越紧密,距离越短越好,因此,w2到w4取小于0的值。如果是乘客,该停泊点出租车越多越好,出租车等待时间越长越好,因此,w1和w2取大于0的值;对于乘客簇越紧密并且步行的路程越短越好,因此,w3和w4取小于0的值。 4实验 4.1数据集及预处理 实验数据来自微软亚洲研究院公开的出租车GPS轨迹数据[10,11],是北京地区从2008/2/2到2008/2/8的出租车GPS轨迹数据,共10 357辆车。每辆车的GPS轨迹存储于一个文本文件中,一行表示一条GPS记录,包括出租车ID、时间、经纬度。 分析挖掘前要先对原始GPS轨迹数据预处理。原始GPS记录共17 662 984条,去掉经纬度异常的(如经度或纬度为0的)和各列完全相同的重复数据后,最终记录有15 358 023条。对这些数据做如下统计分析,以删除对挖掘没有意义的数据。 首先统计出租车每天采集GPS记录的持续时间。由图4可见,各出租车采集GPS记录持续时间差别较大。持续时间最小的为0,即只有1条GPS记录,这样的数据将会删除。持续时间最大的为86 399秒,即一天的时间。说明有的车全天24小时都在采集GPS信息,而有的车不是全天采集的。 图4 出租车每天采集GPS记录持续时间统计 然后统计每辆出租车每天采集的GPS记录个数。由图5可见,少量车每天采集的GPS记录个数不到100。大部分是在103数量级,平均1分钟采集一次。最大的每天采集27 306条GPS记录,平均3.16秒采集一次。 图5 每天采集的GPS记录个数统计 根据上述统计分析可以看出,大部分车每天采集上千条GPS记录,有的车一天24小时都在采集,有的一天采集几个小时。在分析GPS数据时,要删除GPS记录个数少的,因为只有一定规模的数据才能挖掘出停泊点知识库。本文实验中删除了每天采集GPS记录个数小于60的出租车GPS轨迹数据,对余下的数据进行分析。删除后共15 078 142条GPS记录,9593辆出租车。 4.2实验及结果分析 数据预处理后,将在Hadoop平台下对预处理后的GPS轨迹数据进行离线挖掘,生成停泊点知识库。实验中Hadoop平台的环境配置如下:4台服务器,其中1个Master节点,3个Slaver节点。Master节点是双核CPU,2.40 GHz,内存32 GB,硬盘1 TB。3个Slaver节点的配置相同,双核CPU,2.13 GHz,内存32 GB,硬盘1 TB。Hadoop平台版本为1.0.3。 为取得较好的推荐效果,实验分析了DBSCAN算法的距离阈值和最小密度变化时停泊点簇个数和噪声比。噪声比即聚类后没有被分到任何簇中的噪声个数和所有停泊点个数的比例。 图6为距离阈值变化时的簇个数和噪声比。实验分别取非工作日和工作日中时间段ID为0、4、10的三组数据进行了比较。n0、n4、n10、w0、w4、w10分别表示非工作日和工作日时间段在0:00-2:00, 8:00-10:00, 20:00-22:00范围内的数据。实验中最小密度固定为3,距离阈值从50增大到200(单位:米)。从图6可见,距离阈值增大时,簇个数有增大的趋势,工作日时距离阈值取100时簇个数最大。工作日时距离阈值大于100时,簇个数有减小趋势。由于工作日的GPS数据量比非工作日大,因而工作日的簇个数较多。距离阈值增大时,噪声比逐渐减小。考虑到距离阈值越大,停泊点簇的范围越大,推荐的范围也会增大,乘客需要步行较长距离。综合上述分析,实验中距离阈值取100。 图6 距离阈值变化时的簇个数和噪声比 图7是最小密度变化时簇个数和噪声比。n0、n4、n10、w0、w4、w10的含义如上所述。实验中距离阈值取100,最小密度分别取2、3、4、5。从图7可见,最小密度越大,簇个数越小,噪声比越大,和预期结果相同。为达到较好的推荐效果,即簇个数越大,噪声比越小越好。综合考虑,实验中最小密度取3。 图7 最小密度变化时的簇个数和噪声比 停泊点检测及其知识库生成的MapReduce算法效率用加速比su评估。加速比是指数据集固定,不断增大计算节点个数时算法并行的性能[12],如式(4)。p是计算节点个数,T1和Tp分别是1个和p个节点时的运行时间。 (4) 图8分析了数据集大小不同时算法的加速比。共4个数据集,分别记为D1、D2、D3、D4,其中出租车个数分别为100、1000、5000和9593。Tp取3次实验的平均值。理想情况下加速比是呈线性的,但实际的加速比要低于理想状态。D1的加速比最小,因为数据量小时Hadoop集群中部分节点处于空闲状态。数据集越大加速比越接近线性。加速比没有达到线性是因为节点通信、任务启动、调度等开销。该实验证实了本文基于MapReduce的停泊点挖掘算法更适用于处理大规模数据集。 图8 加速比 接下来的实验比较了传统串行算法和本文的MapReduce算法检测停泊点并生成停泊点知识库的运行时间。图9为传统算法和MapReduce算法的对比图。当数据量较小时传统算法运行时间略小。当数据量增大时传统算法运行时间上升得很快,而MapReduce算法的运行时间上升较缓,且远低于传统方法。可见本文算法提高了停泊点挖掘效率,数据量较大时效果更明显。 图9 传统算法和MapReduce算法对比 为验证本文出租车停泊点智能推荐算法的有效性,设计并实现了一套原型系统,利用Hadoop平台挖掘出的停泊点知识库和司机乘客的推荐模型实现在线推荐。原型系统中司机/乘客可以输入当前点位置、时间、最远距离(用户能接受距离当前位置最远多少米范围内的停泊点)、最多推荐的停泊点数。当前位置也可在地图上通过点击鼠标选择。系统将根据输入条件推荐出最佳的停泊点。系统推荐的停泊点是一个区域而不是一个点,这样使推荐更加灵活,用户在进入该区域的路上也可能发现乘客或打到车。 5结语 本文提出了基于MapReduce的出租车停泊点智能推荐算法。首先对原始GPS轨迹数据预处理,然后利用MapReduce模型设计并行算法检测停泊点并对其聚类,最终生成停泊点知识库,利用推荐模型实现司机和乘客的在线推荐。通过实验确定了DBSCAN算法的最佳距离阈值和最小密度,以达到更好的推荐效果。实验分析了本文MapReduce算法的加速比,比较了传统算法和MapReduce算法的效率,结果表明本文算法在数据量增大时运行时间上升缓慢,效率明显高于传统算法。实验中利用真实出租车GPS轨迹数据,生成停泊点知识库。设计并实现了停泊点智能推荐的原型系统,验证了本文停泊点推荐算法可以有效推荐出较容易接到乘客或打到车的地点。本文的研究工作为缓解出租车和乘客的供需矛盾奠定了基础。未来工作将进一步细化停泊点检测算法,如GPS轨迹预处理时考虑轨迹和路网匹配问题等。 参考文献 [1] Castro P, Zhang D, Chen C, et al. From taxi GPS traces to social and community dynamics: a survey[J].ACM Computing Surveys,2013,46(2):1-17. [2] Yamamoto K, Uesugi K, Watanabe T. Adaptive routing of cruising taxis by mutual exchange of pathways[C]//Proceedings of Knowledge-Based Intelligent Information and Engineering Systems, Zagreb,Croatia,2010:559-566. [3] Yuan N J, Zheng Y, Zhang L, et al.T-finder: a recommender system for finding passengers and vacant taxis[J].Knowledge and Data Engineering, IEEE Transactions on,2013,25(10):2390-2403. [4] Powell J, Huang Y, Bastani F, et al. Towards reducing taxicab cruising time using spatio-temporal profitability maps[C]//Proceedings of the 12th International Symposium on Advances in Spatial and TemporalDatabases,Minneapolis, MN, United states,2011:242-260. [5] Lei L. Towards a high performance virtual Hadoop cluster[J].Journal of Convergence Information Technology,2012,7(6):292-303. [6] 曹旭, 张云华. Hadoop平台下计算模型中调度策略的研究[J].计算机应用与软件,2013,30(9):208-210,214. [7] 赵辉, 杨树强,陈志坤,等.基于MapReduce模型的范围查询分析优化技术研究[J].计算机研究与发展,2014,51(3):606-617. [8] 林彬, 李姗姗,廖湘科,等.Seadown: 一种异构 MapReduce 集群中面向 SLA 的能耗管理方法[J].计算机学报,2013,36(5):977-987. [9] 慈祥, 马友忠, 孟小峰.一种云环境下的大数据Top-K查询方法[J].软件学报,2014,25(4):813-825. [10] Yuan J, Zheng Y, Xie X, et al. Driving with knowledge from the physical world[C]//Proceedings of SIGKDD. New York, UNITED STATES, 2011:316-324. [11] Yuan J, Zheng Y, Zhang C, et al. T-drive: driving directions based on taxi trajectories[C]//Proceedings of Sigspatial. New York, UNITED STATES, 2010:99-108. [12] 蒋鸿玲, 邵秀丽, 李耀芳.基于MapReduce的僵尸网络在线检测算法[J].电子与信息学报,2013, 35(7):1732-1738. 中图分类号TP391 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.02.059 收稿日期:2014-08-06。河北省科技厅项目(13210707)。蒋鸿玲,博士,主研领域:数据挖掘,大数据。张楠,高工。李克,高工。田昊,工程师。葛伟,工程师。