带有停滞检测的蚁群算法在2D HP格点模型中的应用
2016-03-17熊壬浩
刘 羽 熊壬浩
1(桂林理工大学机械与控制工程学院 广西 桂林 541004)
2(桂林理工大学信息科学与工程学院 广西 桂林 541004)
带有停滞检测的蚁群算法在2D HP格点模型中的应用
刘羽1熊壬浩2
1(桂林理工大学机械与控制工程学院广西 桂林 541004)
2(桂林理工大学信息科学与工程学院广西 桂林 541004)
摘要为了提高蛋白质折叠结构预测的求解效率,针对2D HP格点模型,研究蚁群ACO(Ant Colony Optimization)算法在该问题上的应用。采用四元组表示绝对的折叠方向,并建立构象和解的一一对应关系。通过实验对算法各阶段的常用策略、方法进行比较分析。为了防止搜索陷入停滞,引入位置信息素停滞比和序列信息素停滞比两个参数,使用一种新的停滞检测机制。实验结果表明,改进的算法在保证预测质量的前提下,显著地提升了收敛速度。
关键词HP模型蛋白质折叠蚁群算法停滞检测遗传算法
APPLICATION OF ANT COLONY OPTIMISATION ALGORITHM WITH STAGNATION DETECTION IN 2D HP LATTICE MODEL
Liu Yu1Xiong Renhao2
1(School of Mechanical and Control Engineering,Guilin University of Technology,Guilin 541004,Guangxi,China)2(School of Information Science and Engineering,Guilin University of Technology,Guilin 541004,Guangxi,China)
AbstractAiming at 2D HP lattice model we studied the application of ant colony optimisation algorithm on protein folding structure prediction in order to improve the efficiency of its solution. We used the quadruple to express absolute folding direction, and established the one-to-one correspondence between conformation and solution. Through experiment we made the comparative analyses on common strategies and methods in each stage of the algorithm. To prevent the search from going to stagnation, we introduced two parameters, the position pheromone stagnation ratio and the sequence pheromone stagnation ratio, and applied a new stagnation detection mechanism as well. Experimental results showed that the improved algorithm remarkably accelerated the convergence speed on the premise of ensuring prediction quality.
KeywordsHP modelProtein foldingAnt colony optimisationStagnation detectionGenetic algorithm
0引言
蛋白质是一种复杂的有机化合物,是由氨基酸经脱水缩合反应形成多肽链,然后在空间进行折叠后形成的。蛋白质是细胞的基本构成物质,是生命的物质基础,在生物细胞中起着关键的生物和化学作用。蛋白质折叠问题的研究在医学及生物工程等领域具有重大的科学价值和实用价值,其规律尚未被完全揭示。目前蛋白质折叠结构研究的主要方法包括实验方法以及理论预测两类。X射线晶体学方法等生物化学实验方法对样本的要求高、耗资大、周期长,人们逐渐将注意力转移到理论预测方法上来。最新研究进展表明,一些小型蛋白质的精确折叠结构已使用计算机模拟得出[8]。如何从理论上建立相互作用模型是蛋白质折叠理论的核心问题。1989年Dill等提出的HP格点模型在内的简化模型兼顾了折叠过程的物理机制以及计算机的计算能力,从而受到广泛认可。
HP格点模型上的预测算法主要包括进化算法和蒙特卡罗算法两类。基于蒙特卡罗算法的预测算法应用广泛,但收敛速度较慢。2001年Liang等将遗传算法引入蒙特卡罗算法,取得了一定效果。1996年Dorigo等提出了ACO算法,该算法成功应用于旅行商问题、车辆调度等问题。随后Shmygelska[4,7]等将ACO算法应用于HP格点模型,取得了较好的效果。
目前已有较多文献对HP格点模型上的ACO算法提出了进一步改进。例如,文献[2]用PERM评价构型好坏的标准作为蚁群更新时的迹,同时采用EO算法进行局部搜索;文献[5,7]分别在算法的局部搜索阶段采用了牵引移动的方法和长距离移动的方法;文献[3]提出了一种先用遗传算法生成信息素分布,再利用蚁群算法求优化解的新的混合算法;文献[4]引入了最大-最小蚁群系统中的信息素平滑机制等。这些改进涉及ACO算法的各个阶段,效果不一,但少有文献对相关的策略方法进行衡量,对算法停滞问题的研究也较少。对此,本文通过大量实验比较分析ACO算法中常见的方法策略,在此基础上使用一种新的停滞检测机制,最后与其他ACO算法的效果进行比较。
12D HP格点模型
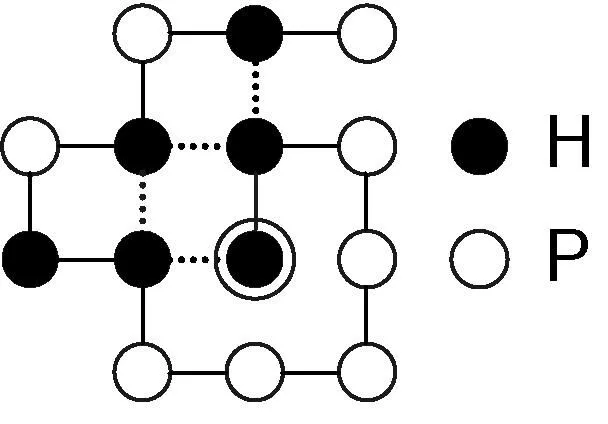
图1 序列H2P5H2PHPHP的一个构象
HP格点模型(Hydrophobic-Polar Square Lattice Model)分为2D HP格点模型和3D HP格点模型,前者应用较为广泛。本文仅针对2D HP格点模,但可扩展为3D HP格点模型。在2D HP格点模型中,氨基酸脱水缩合形成多肽链时被简化为疏水性和亲水性两种,蛋白质则被表示为由疏水性残基H和亲水性残基P组成的序列S。HP模型基于蛋白质折叠的热力学假说,即天然构象的蛋白质处于热力学最低的能量状态。因此蛋白质折叠的过程被表示为序列S在二维网格上盘旋成能量最低的“构象”过程。网格上的一个格点只能被一个残基占据。S中不相邻,构象C中相邻的H-H对称为H-H键。C的能量用H-H键的数目n表示,表达式为EC= -1 × n。例如,图1所示残基序列H2P5H2PHPHP的构象,其自由能为-4。
2蚁群算法
2.1解的表示
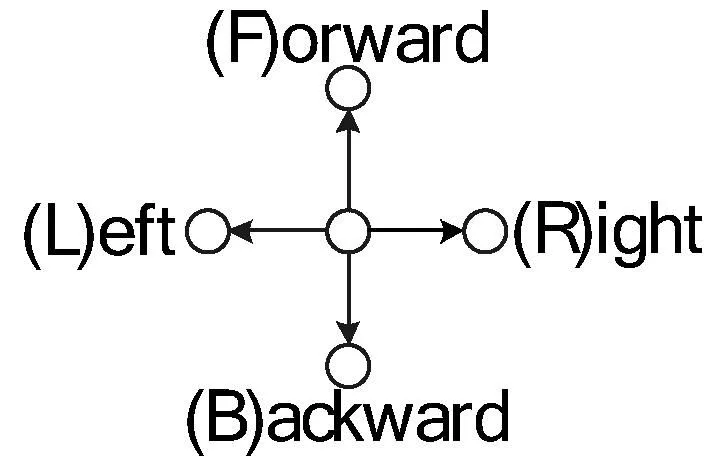
图2 折叠方向的定义
HP模型中的残基序列可表示为S=s1,s2,…,sn,si∈{H,P}。向网格中放置序列中的残基si时,常用相对的方向[2-5,7]表示折叠过程,此时折叠方向序列可表示为D′=d1,d2,…,dm,di∈{S,L,R},其中S、L、R分别代表直行、左转和右转。例如图1中构象的方向序列为D′=RRSRSRLRRRRS。由于方向是相对的,必须至少固定两个残基的位置之后才能确定下个残基的折叠方向,因此方向序列的长度为m=n-2。与此不同,实现采用了与文献[1]所述相似的表示方式。如图2所示,将方向序列定义为D=d1,d2,…,dm,di∈{F,B,L,R},即用4个绝对的折叠方向F、B、L和R表示,此时方向序列的长度m=n-1。使用该定义图1所示构象的方向序列为D=FRBBLLFLFRFRR。绝对的折叠方向更加直观。
残基序列S和方向序列D共同构成一个解。一个解只能表示一个构象,但一个构象可以用多个解表示。指定构象的起始残基(图1中用同心圆圈出)后,建立起解和构象的一一对应关系。考虑到构象在空间经旋转、翻转等操作(或以上操作的组合)后得到的构象实际上为同一构象,此时方向序列可能不唯一。通常2D HP模型不考虑构象的空间变换,但两个不同的方向序列是否表示同一构象是可以判定的。
2.2建立构象
蚁群算法中,该阶段每只蚂蚁进行一次构象。构象的建立从随机选定的位置si(1≤i≤n)开始,每增加一个残基称为“扩展”。从位置i向i+1进行扩展时称为“正向”扩展,i向i-1称为“反向”扩展。以正向扩展为例,从位置i以方向d进行扩展时,以概率Pi,d随机选择扩展方向,公式为:
(1)
信息素τi, d和启发信息ηi, d共同决定扩展方向,其中d∈{F, B, L, R},参数α和β分别反映了信息素和其发信息的重要程度。ηi,d的常见形式有以下两种:
ηi,d=1+hi,d
(2)
(3)
其中,hi,d为从当前位置i以方向d扩展后增加的H-H键数目,T为取值[0.25, 0.35]的常数。下面将式(2)简称为HR1,式(3)简称为HR2。本文采用HR2,实验部分对HR1、HR2两组启发函数进行了进一步讨论。

构建过程中有可能出现网格上四个方向的邻接格点都被占据而无法继续扩展的情况,称为“阻塞”。常见的处理策略有重新构造、回退、淘汰-克隆等策略。初步分析可知重新构造、回退策略耗时较多,但搜索到更多不同构象的可能性较大,而克隆策略耗时少同时易于实现。克隆策略淘汰无效的构象,并以概率Pi随机从有效构象克隆。设有效构象共m个,从构象Ci克隆的概率为:
(4)
本文采用回退策略,实验部分对回退、淘汰-克隆两种策略进行了进一步讨论。
2.3局部搜索
构象构建阶段结束后,选择一定比例具有较小能量的构象,对每个构象进行若干次局部搜索。较好的局部搜索方法包括“长距离移动”[7]、“牵引移动”[5,6]等。长距离移动是相对于“短距离移动”,例如“单点变异”和“多点变异”等来说的,它对于致密的构象依然有效,而牵引移动的优点是只需调整少数顶点即可达到有效构象。本文采用牵引移动方法,实验部分对两种方法进行了进一步讨论。与残基的扩展类似,牵引移动也有正向、反向两个方向。仍以正向为例,随机选择残基序列中的位置i,另设网格中的两个格点e、f,位置i、i+1与e、f构成如图3所示的矩形(不失正确性,假定i、i+1垂直排列),其中i的对角为f。
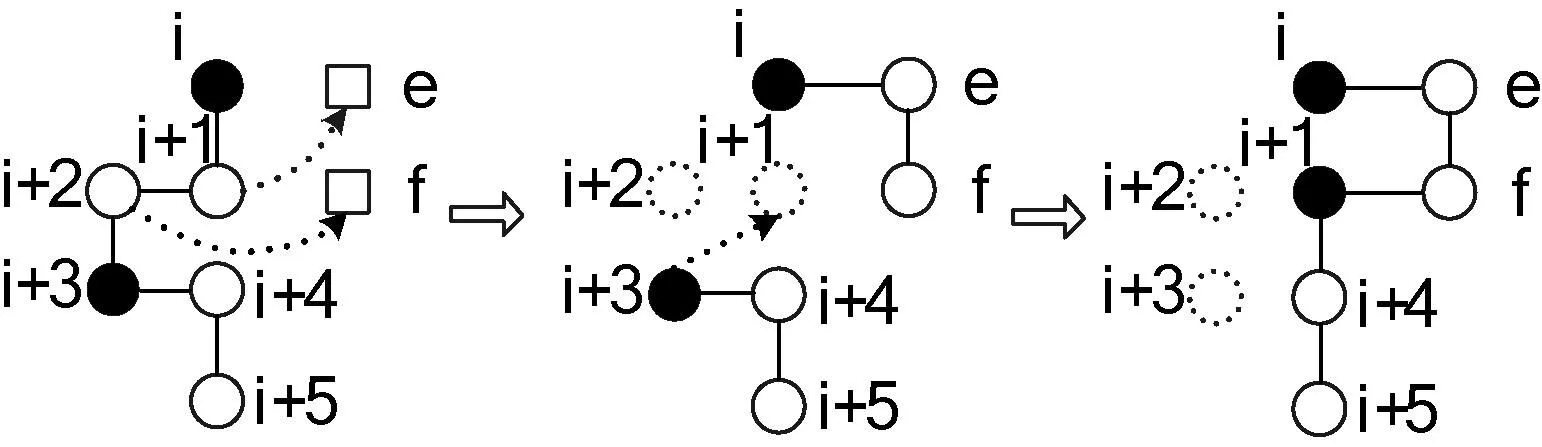
图3 正向牵引移动示例
牵引移动算法描述如下:
Step1若e位置为空,且f为空或i+2,转至Step2,否则移动失败,退出算法;
Step2将i+1移动到e。如果e与i+2相邻,转至Step5,否则转至Step3;
Step3将i+2移动的f。如果f与i+3相邻,转至Step5,否则转至Step4;
Step4将j+3移动到原残基j+1所在位置(i≤j≤n-3),直至形成一个可行的构象,转至Step5;
Step5若新构象具有更小的能量,移动成功,接受该构象,退出算法,否则移动失败,退出算法。
以i、i+1为一条边的矩形有两个,对应的两对e、f分别在边i、i+1的两侧。为了加快收敛速度,牵引移动时使用了贪心策略,对两对e、f先后进行搜索,取较优的结果。反向牵引移动类似,将图3中i+1, i+2,…变为i-1, i-2,…可得到反向牵引移动的一个示例。文献[6]证明了牵引移动并非完全可逆,本文采用了该文献给出的修正版本。
2.4更新信息素
完成构象的构建和局部搜索后,信息素按下式衰减:
τi, d=ρτi, d
(5)
其中,ρ是信息素残留比。然后选择一定比例具有较小能量的构象进行信息素的增强:
τi, d=τi,d+ EC/Em
(6)
其中,Em是序列已知的最小能量值。初始状态下τi,d= 0.25,随着迭代的进行,某些方向上的信息素不断增加,如果这些方向上的信息素远大于其他方向上的信息素,造成选择其他方向的概率非常低,搜索将会陷入停滞状态。为了防止搜索陷入停滞状态,常用类似于最大-最小蚁群系统中的方法对信息素进行调整[4](下面简称为MM)。每次更新信息素后,首先将τi,d标准化,使得∑d∈{F,B,L,R}τi,d=1。设τi, max和τi, min分别为τi, d中最大和最小的信息素,如果τi, min<θ,则令τi, max= τi, max- (θ - τi, min), τi, min=θ。
2.5带有停滞检测的蚁群系统(SD-ACO)
MM在每次更新信息素后进行,可以避免系统陷入停滞状态。MM的缺陷在于,它无法确定对信息素进行调整的时机,具有一定的盲目性。分别针对各个位置i对τi,d进行调整,全局性较差。同时,由于信息素的积累与构象的方向选择是一种正反馈机制,过早的调整信息素必然对收敛速度有所影响。若能通过某种方式对停滞做出检测,将能很好地解决上述问题。为此,引入位置信息素停滞比ε和序列信息素停滞比μ(0.5<ε<1,0<μ<1)两个参数,并定义:
(7)
(8)
通过对大量实验数据的统计分析,发现使用G能够很好表示停滞。使用上述ACO算法进行搜索(参数设置参考实验部分),正常更新信息素,但不进行调整。迭代若干次,统计每次迭代后G的值以及问题的求解比(当前最优能量/Em,见图4中图例Solve),所有迭代完成后取平均。图4给出了实验部分所述序列Ser10的统计结果,其中ε分别取四个不同的值,横轴为迭代次数,纵轴为G值或求解比。可见求解比和G值均在一定次数的迭代后趋于稳定。实验中发现,G趋于稳定后,特定方向上的τi,d持续增大,选择其他方向的可能性减小,而且这种情况随着搜索的继续越来越严重,以至搜索陷入停滞。对其他序列的实验结果也得出相似的特征,这就为文中所述停滞检测方法提供了可行性验证,也为ε和μ两个参数的设置提供了依据。停滞检测的具体方法为,若G>μ则认为搜索已经停滞,随后放弃整个蚁群系统,对τi,d进行重置。本文将这种机制称为SD(Stagnation Detection),将使用这种机制的蚁群系统称为SD-ACO。

图4 迭代次数与求解比、G值的关系
SD基于对τi,d的统计分析,相对于MM,SD先进行停滞检测,再进行进一步处理。它使用了更全面的信息,即所有位置i上τi,d的整体状况作为判断依据,能够更好地反映信息素的全局状况。SD-ACO借鉴了遗传算法的淘汰机制,对陷入停滞的蚁群系统进行淘汰,并用新的系统取而代之。实践证明,SD-ACO更充分地利用了蚁群系统的构象能力,保证了解的质量,同时具有更快的收敛速度。SD还可与其他机制结合,例如与MM结合。即将SD用作单纯的检测机制,同时将MM作为平滑机制。用SD检测到停滞后不重置τi,d,而是按照MM的方式进行调整。文中将这种混合机制称为SD-MM。实验部分对MM、SD和SD-MM进行了比较。
3实验结果及分析
本文几组实验对蚁群算法相关步骤中的一些策略、方法进行了分析,最后比较了带有停滞检测的蚁群算法以及若干其他改进的ACO算法。算法使用C语言实现,编译器为pgcpp 13.6-0,运行环境配置有Intel Core i5 @ 3.2 GHz处理器,操作系统为CentOS。为了更全面地评估算法的性能,实验使用了文献[1]给出的15组基准序列,并将其编号为Ser1到Ser15。如无特别说明,实验参数设置均设置为α=1,β=2,ρ=0.8。蚂蚁数均为200只,用于局部搜索和信息素更新的比例为1%,局部搜索次数500次,迭代次数为10 000次。实验结果中的时间均为CPU时间,单位秒。
3.1HR1与HR2的比较
下面对启发函数HR1和HR2进行实验比较。构象调整的效果依赖于起始构象的能量,较差的起始构象很少能被调整为高质量的解[4]。启发函数对构象的建立有重要的指导作用,较好的构象为局部搜索调整出高质量的解提供了更大的可能性。实验仅关注HR1、HR2的启发能力,即启发函数对构象能量的影响,构象构造完成后不进行局部搜索,也不对信息素进行更新。不限制迭代次数,将运行时间限制在1800 s内,HR2中T取0.25。对于长度不大于36的短序列Ser1-8,分别独立运行100次,对于长序列Ser9-15运行20次。图5给出了Ser10-15的结果,纵轴为平均时间,百分比为达到能量的概率,“+”号后为得到的能量与Em的差值。

图5 Ser9-Ser15两组启发函数的比较
对于短序列,两者均能以100%的概率得到最优解,但HR2所用时间远小于HR1。对于长序列,HR2搜索到的解优于HR1,且时间性能较好。此外,对于短序列,仅使用随机搜索即可在较短时间内得到最优解。对于长序列,随机搜索的求解能力不足,且容易“早熟”。如对于Ser12-15,使用HR2分别早在485、648、1101和945 s已找到最终解。综上,HR2的启发能力明显优于HR1。后续实验中均使用HR2。
3.2阻塞处理与局部搜索
下面对回退、淘汰-克隆两种处理策略和长距离移动、牵引移动两种局部搜索方法进行实验比较。阻塞处理影响算法的收敛速度及解的质量,与局部搜索密切相关。因此实验对上述策略、方法的四种组合,即RB-LRM、RB-PM、CLN-LRM、CLN-PM分别进行了测试。局部搜索后不进行信息素的更新,达到迭代次数后停止,各序列分别使用四种组合各自独立运行100次。RB中回退长度为已折叠序列长度的一半(向下取整),CLN中选择%1的有效构象,LRM中选择与上个残基相同方向的概率为0.5。LRM与PM均使用了贪心策略,每次局部搜索选择正向、反向搜索中较优的构象。为节约篇幅,表1和表2仅给出了Ser12-15的部分运行结果,即100次运行达到相应能量(E)的概率(P)、平均时间(T)及平均迭代次数(R)。空行表示没有达到相应能量。

表1 RB-LRM与RB-PM的结果比较
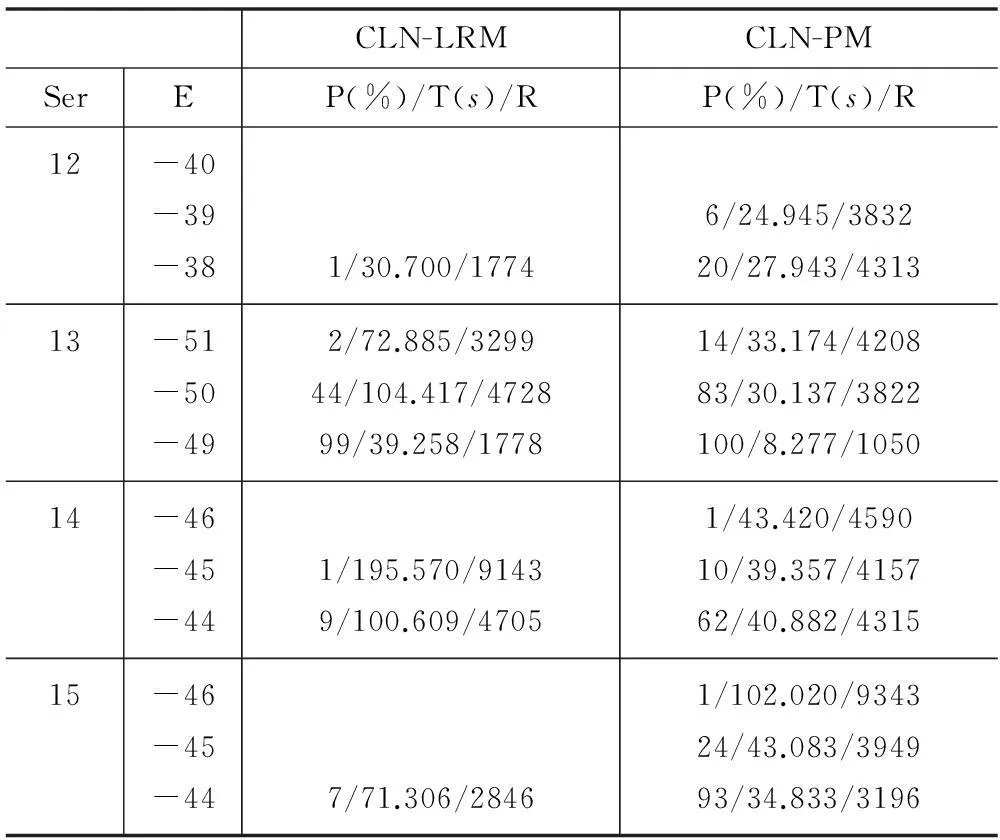
表2 CLN-LRM与CLN-PM的结果比较
将表中数据RB-LRM与RB-PM相比、CLN-LRM与CLN-PM相比,PM的最终解更好,E相同时PM的收敛速度更快、概率更大。将RB-LRM与CLN-LRM相比、RB-PM与CLN-PM相比,E相同时RB的概率更大,但收敛速度慢于CLN。Ser14中CLN-PM的最终解好于RB-PM,但CLN-PM仅以1%的概率得到该解,其他情况下RB的解均较优。Ser1-11的运行结果相似。综上,局部搜索方法采用PM,为了保证解的质量,阻塞处理策略采用RB。后续实验中均采用RB-PM。
3.3MM、SD以及SD-MM的比较
除默认参数外,其他参数θ=0.05,ε=0.75,μ=0.5。对于Ser1-13分别独立运行100次,Ser14-15运行50次。表3仅给出了Ser12-15的部分运行结果,SD-ACO的结果可参见表4所示。其中“*”号标记的能量等于序列已知的最小能量(下同)。

表3 三种停滞处理机制的比较
易见无论是解的质量还是收敛速度SD、SD-MM均优于MM。Ser13中SD-MM的收敛速度远快于SD,但求得最优解及次优解的概率均较低。Ser1-15中,仅对于Ser14,SD-MM的最终解概率高于SD,其他无论在求解质量还是收敛速度上,SD具有明显优势。
3.4SD-ACO与其他ACO算法的比较
SD-ACO的最终版使用HR2及RB-PM,对Ser1-13分别独立运行100次,Ser14-15运行50次。表4给出了Ser1-15的测试结果,同时列出了其他文献报告的结果。除文献中已给出其改进ACO算法的命名外,其他均使用作者姓名首字母命名。表中数据第一行为能量值,“*”号标记的能量等于序列已知的最低能量(下同),第二行为时间,空白行表示文献未给出,若得到解的概率不为1,还给出了求得相应解的概率。

表4 SD-ACO与其他ACO算法的比较
对于Ser1-13,SD-ACO能够保证解的质量,且收敛速度较快。对于Ser14-15,SD-ACO的解质量优于HSZ-ACO和HA,且收敛速度较快。总的来说SD-ACO的效果明显,但Ser14中SD-ACO的解劣于LYPS-ACO,Ser15中SD-ACO的解劣于ACO-HPPFP-3。两者均为运行较长时间后得到的,为进一步研究运行时间对SD-ACO解质量的影响,进行下述实验。取消迭代次数限制,增加运行时间并观察实验结果。表4中,ACO-HPPFP-3以外其他算法列出的运行时间均在7000 s内,除Ser15外SD-ACO均达到了ACO-HPPFP-3所得的最优能量。为验证同等时间条件下SD-ACO的效果,将时限设置为7200 s。此外,为比较不同时限下SD-ACO的运行结果,从而进一步分析运行时间对算法效果的影响,还使用时限3600 s进行了测试。对Ser12-15分别独立运行20次,实验结果如表5所示。

表5 两组时限的测试结果比较
其中Ser12以100%的概率达到最优解,平均时间稳定在90 s内。虽然Ser14在时限3600 s时未找到解-47,但在时限7200 s时找到该解,且概率明显增大。两个时限下Ser13的两组解均优于表4中的其他算法,Ser15求得-48的概率有较大提升。考虑到实际应用,没有使用更大的时限进行测试,但从表5的结果可得出,随着运行时间的增加,达到相应解的概率增大,且有可能得到质量更好的解。
4结语
HP格点模型是学术界广泛接受的蛋白质折叠结构预测模型,将ACO算法应用于2D HP格点模型取得了较好的效果。众多文献对此提出了进一步改进,但效果不一。为衡量常见策略方法的优劣,本文比较分析了两组启发式函数、四对阻塞处理与局部搜索策略方法,并在此基础上使用了一种新的停滞检测机制SD,并进行实验验证,对蚁群算法作出了进一步改进。SD使用全局信息,通过参数化的方式检测停滞,并借鉴遗传算法的淘汰机制进行调整。与最大-最小蚁群系统中的停滞预防机制相比,SD不盲目调整信息素,检测停滞的时机更为精准。实验结果表明,将SD-ACO应用于2D HP模型取得了较好的效果。此外,并行化是提升算法效率的重要手段,这也是后续的研究方向。
参考文献
[1] Mario GarzaFabre,Eduardo RodriguezTello,Gregorio ToscanoPulido.Comparative Analysis of Different Evaluation Functions for Protein Structure Prediction Under the HP Model[J].Journal of Computer Science and Technology,2013,28(5):870-873.
[2] 陆恒云,杨根科,潘常春,等.改进的蚁群算法求解蛋白质折叠问题[J].计算机工程与设计,2010,31(8):1787-1788.
[3] 李晚霞,莫忠息,曾涛.混合遗传算法和蚁群算法在HP模型中的应用[J].计算机工程与应用,2006,42(31):58-59.
[4] Alena Shmygelska,Holger H Hoos.An ant colony optimisation algorithm for the 2D and 3D hydrophobic polar protein folding problem[J].BMC Bioinformatics,2005,6(30):18-21.
[5] 何莲莲,石峰,周怀北.改进的蚁群算法在2D HP模型中的应用[J].武汉大学学报:理学版,2005,51(1):35-37.
[6] Györffy D,Závodszky P,Szilágyi A. ”Pull Moves” for Rectangular Lattice Polymer Models Are Not Fully Reversible[J].IEEE/ACM Transactions on Computational Biology and Bioinformatics,2012,9(6):1847-1848.
[7] Alena Shmygelska,Holger H Hoos.An Improved Ant Colony Optimisation Algorithm for the 2D HP Protein Folding Problem[C]//Lecture Notes in Computer Science,2003,2671:405-417.
[8] Ken A Dill,Justin L MacCallum.The Protein-Folding Problem,50 Years On[J].Science,2012,338(6110):1042-1045.
中图分类号TP18TP301.6
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.053
收稿日期:2014-10-21。国家自然科学基金项目(41264005);广西教育厅科研项目(201102ZD018)。刘羽,教授,主研领域:并行计算,数据挖掘。熊壬浩,硕士。
