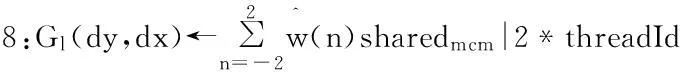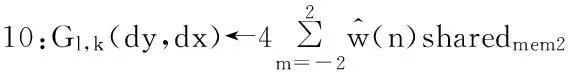基于CUDA的多相机实时高清视频无缝拼接方法
2016-03-17张博凯
王 震 张博凯 王 静 李 圣 郑 宏
(武汉大学电子信息学院 湖北 武汉 430072)
(湖北省视觉感知与智能交通技术研发中心 湖北 武汉 430072)
基于CUDA的多相机实时高清视频无缝拼接方法
王震张博凯王静李圣郑宏
(武汉大学电子信息学院湖北 武汉 430072)
(湖北省视觉感知与智能交通技术研发中心湖北 武汉 430072)
摘要为解决传统CPU或GPU多相机视频拼接方法难以兼顾实时性与视觉效果,提出一种基于统一设备架构GUDA(Compute Unified Device Architecture)的实时无缝拼接方法。结合图割算法预处理的静态接缝掩模和图像空间域融合算法解决了运动物体给拼接中接缝处带来的视觉困扰,同时重点对透视变换、图像融合等拼接步骤在CUDA实现中的优化策略进行研究。实验结果表明,该方法在4路1080p高清网络相机实时拼接获得超宽视野视频的条件下,不仅相对CPU有较高的加速比,而且在不同计算性能和架构的GPU上均满足实时性要求并具备更好的视觉效果。
关键词视频拼接图形处理器统一设备架构
CUDA-BASED SEAMLESS STITCHING METHOD FOR MULTI-CAMERA REAL-TIME HD VIDEO
Wang ZhenZhang BokaiWang JingLi ShengZheng Hong
(School of Electronic Information,Wuhan University,Wuhan 430072,Hubei,China)(Hubei Research Center of Vision Perception and Intelligent Transportation Technology,Wuhan 430072,Hubei,China)
AbstractIn order to overcome the difficulty of traditional multi-camera video stitching method based on CPU or GPU in satisfying both the real-time performance and visual effect, this paper proposes a CUDA-based real-time seamless HD video stitching method. It solves the visual troubles caused by seams in stitching the moving objects by combining the static seam masks of Graphcut pre-treatment and the blending algorithm of image spatial domain, meanwhile puts the emphasis on studying the optimisation strategy of implementation of stitching procedures including perspective transform and image blending in CUDA. Experimental results demonstrate that under the condition of obtaining extra wide filed-of-view video by real-time stitching with four 1080 HD web cameras, the method achieves higher speedup ratio compared with CPU-based algorithm, and satisfies the real-time requirement on GPUs with different computing capability and architecture, and possesses better visual quality as well.
KeywordsVideo stitchingGPUCUDA
0引言
当下视频监控系统中通过部署多个高清网络摄像机来获取更大的监控范围,但是多路视频监控存在信息冗余以及关联性较差等问题,给对场景内同一运动物体进行连续监控带来了一定困难。目前将多路具有重叠区域的视频进行实时视频拼接获取具有超宽视野视频是有效的解决办法之一。近年来许多实时视频拼接算法[1,3,6]应运而生,也有VideoStitch[11]这种离线式视频拼接软件投入商用。但由于过大的计算量,仅仅使用CPU来进行高清视频的实时拼接即使是在较为昂贵的高端CPU上也难以实现。
NVIDIA开发的GPU通用计算技术架构CUDA[7]是一种基于单指令多线程SIMT(Single-Instruction, Multiple-Thread)的大规模并行计算模型。它以多层次网格为基础调度大量GPU线程并行计算的特点与计算密集型的图像处理算法相符,这意味将多路视频拼接算法移植到GPU上是为满足实时性要求的一种有效解决方法。国内外学者针对GPU视频拼接方法的研究也较为普遍,特别是Bagadus研究组针对足球场的特定视频拼接系统展开了一系列深入研究[1,2],并对其视频拼接算法在GPU与CPU上的性能表现进行了详细地分析与对比。
相比图像拼接,视频拼接中运动物体更容易暴露接缝,并且图像融合计算量较大。为保证视觉效果同时兼顾硬件设备的计算能力,文献[2]中使用了基于CUDA的色彩纠正结合动态接缝的方法,文献[3]中使用通用图形处理硬件根据Alpha透明度通道进行融合渲染,在某些场景下这些方法是可行的。但是在运动物体密集,配准存在误差等情况下这些方法都难以解决问题。本文针对多相机监控的大范围场景提出一种基于CUDA高效灵活的实时全高清视频拼接方法。该方法使用图割算法[8]预处理的静态接缝掩模,将多路视频投影到统一坐标轴上,同时结合空间域的图像融合算法,解决了运动物体给接缝处带来的视觉困扰,并提供了根据不同的视觉效果以及硬件计算性能最佳的无缝拼接方法,不仅满足实时性要求而且具备良好的可扩展性。
1实时视频拼接方法框架
1.1方法概观
本文实时视频拼接方法分为两大模块:实时视频采集模块和GPU实时拼接模块。实时视频采集设备由四路带旋转云台的1080p高清网络摄像机和固定设备组成(如图1前端部分所示)。摄像机通过云台安装在位置相对固定的滑轨上,在确保相邻相机有重叠区域的前提下,通过调整相机水平位置和旋转角度来改变相机视野覆盖区域。在2D拼接领域有一个达成共识的假设,即拍摄场景离相机的距离要远大于不同视点之间的距离。对文中设备而言,相机之间的距离远小于覆盖区域到相机安装的距离才能将不同视角捕获的视频才能进行拼接。

图1 多相机视频捕获装置与视频拼接框架
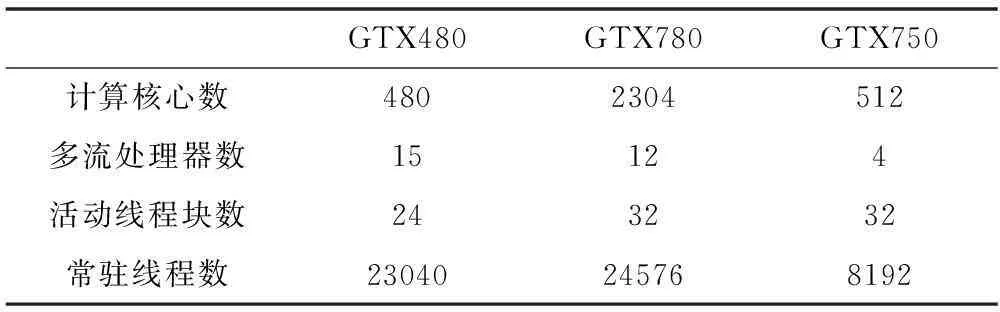
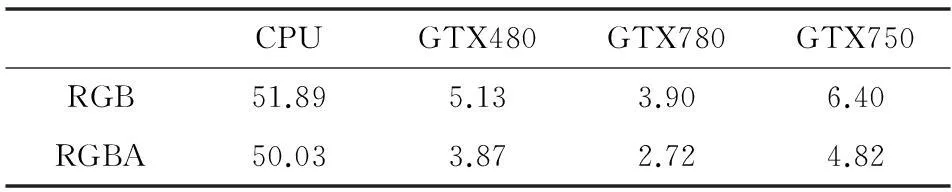
实时拼接所有的工作在一台配备CPU、GPU以及SDI视频采集卡的工作站上运行(如图1所示)。摄像机捕获的高清视频数据通过网路传送到视频采集卡并转换为RGB数据,通过直接内存存储技术DMA以最高带宽速度通过PCI-EXPRESS从CPU传送至GPU的内存。接着根据提前计算的拼接参数(即:单应矩阵H)将视频投影到统一的坐标轴上。然后根据GPU计算能力选择合适的图像融合方法结合对应图像掩模(mask)进行图像融合。最后建立PBO(像素缓冲区对象)作为中间对象,使CUDA与OPENGL交互,将CUDA映射到PBO的超宽视野视频数据高速地复制到OPENGL纹理进行绘制显示。考虑到数据从CPU传输到GPU需要消耗一定时间会影响拼接效率,所以该方法在CPU-GPU异构环境下由POSIX线程调度,利用其多线程和双缓冲技术解决该问题。实时拼接由Pthread1和Pthread2两个线程控制,Pthread1负责实时视频流解码及数据传输,GPU中的实时拼接由Pthread2负责控制,两个线程异步并行执行使数据传输和拼接计算重叠,以发挥最大效率。
1.2图像处理的CUDA加速
许多图像处理算法具有数据计算密集和运算高度独立的特点。如图像加权运算中逐像素进行权值加减,这种运算就完全符合CUDA的编程模型。CUDA将GPU抽象设备成一个巨大网格,并将网格分成若干个线程块,线程块由上千个线程组成,在CUDA函数中可以将每个线程对应一个独立像素进行处理,在SIMT指令模式下这种操作在网格满载线程时可以发挥GPU的最强性能。在对图像处理算法进行CUDA优化时,可对不同的数据类型合理分配GPU内部存储器资源以及使用特定读写策略。如合并访问来减少访问延迟和提高计算效率,如手动控制共享内存读写,特别是图像分块运算(如卷积,直方图)等操作时可以将频繁操作的数据存储于共享内存,从而减少对全局内存的读取次数以提高数据访问效率。同时尽可能多地启动线程将GPU网格充满,充分利用带宽增大并行度。本文结合GPU内存访问和存储器结构等相关优化策略对实时拼接的CUDA实现进行了深入研究。
1.3投影模型与图像配准
(1) 平面投影与自动配准
2D拼接常见的投影模型有:圆柱投影、球面投影、平面投影。不同的投影模型决定了最终视频的显示效果,前两种方法可以获得更大视角范围,但是视频中的直线在柱面或球面投影展开后会投影成曲线。根据文献[9]中的定义,是从一个平面到另一个平面的线性变换关系。直线在该变换的映射(也称透视变换)后仍为直线,为了使视频中直线投影后保持笔直,所以本文实验中采用基于单应矩阵的平面投影方式,通过一组单应矩阵将相机的视频投影到统一的平面坐标系上,设Hi对应第i个相机的单应矩阵,定义如下:
(1)
其中,Hi是一个3×3的矩阵具有八个自由度参数[9],通过改变这几个参数可以实现2D平面上任意平移、旋转、仿射、透视变换。
假设pi=[xiyi1]T,pf=[xfyf1]T分别为第i个相机的图片与拼接投影面在齐次坐标系[9]下的对应点,Pi到Pf的变换关系如下所示:
pf=Hipi
(2)
那么xf,yf分别表示为:
(3)
(4)
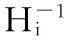
由于使用高清相机位置相对固定无需每帧计算拼接参数,因此实时拼接启动前需根据样本帧进行配准计算出对应各个相机的单应矩阵与拼接掩模。文献[4]提出了根据SIFT特征全自动拼接方法,该方法具有良好的鲁棒性。而通过SIFT特征来进行多幅图像匹配在监控场景有一定弊端,在文献[18]中给出了SIFT、PCA-SIFT、SURF等三种常用特征描述子的比较。在速度和亮度变化上SIFT为三者最差,而监控应用中可能会因为不同摄像机型号或者捕获区域光线照射角度造成相邻两幅图片存在一定亮度差异,SURF在亮度上是三者中表现最好同时具备更快的速度,因此文中图像自动配准中的匹配特征选用SURF。结合视频监控系统特点,图像配准具体步骤如下:
① 输入样本帧,对每幅样本图片计算SURF特征。
② 根据K-D[14]树算法对相邻的两幅图片特征点匹配搜索,接着使用随机抽样一致性算法[15](RANSAC)进行聚类删除错误匹配点获取精匹配点,然后通过精匹配点计算出一组单应矩阵和相机内外参数。
③ 使用绑定调整器[16]对每组相机内外参数进行绑定调整获得一组优化过的单应矩阵,对应每个相机与拼接统一坐标轴的透视变换关系。
④ 根据优化后单应矩阵确定相邻两幅图片的重叠区域,利用图割算法对重叠区域进行分割生成不规则接缝将拼接掩模分为前景区域(拼接区域)与背景区域(非拼接区域)。
(2) 平面投影的CUDA并行设计
算法1RGBA透视变换操作CUDA核函数
cudaBindTextureToArray(tex,RGBA_array)▷将RGBA数据与纹理绑定
dx←blockIdx.x*blockDim.x+threadIdx.x▷拼接目标图像列坐标索引
dy←blockIdx.x*blockDim.y+threadIdx.y▷拼接目标图像行坐标索引
deno=h31*dx+h32*dy+1▷归一化系数(公式(3,4)中分母)
sx=(h11*dx+h12*dy+h13)/deno▷输入视频图像列坐标索引
sy=(h21*dx+h22*dy+h23)/deno▷输入视频图像行坐标索引
dst(dy,dx)=tex2D(tex,float(sx),float(sy))▷将像索值存入拼接目标图像的全局内存
cudaUnbindTexture(tex)▷解绑纹理
1.4无缝融合的CUDA并行设计
前文中提到2D图像拼接中的前提条件,但是实际应用中并不可能完全满足理想情况,必然会产生由视差引起接缝周围的拼接痕迹。除此之外,配准偏差,接缝附近运动物体的鬼影等干扰均普遍存在。特别在视频拼接中运动物体位置频繁变化,拼接痕迹更容易被暴露影响视觉效果。Bagadus[1]使用色彩纠正和动态接缝来处理这些问题,但是如果拼接中重叠区域运动物体情况复杂,更新接缝并不是一个有效可行的办法甚至会导致接缝的不停闪动。而其他的一些实时视频拼接算法为了减少运算量,使用Alpha透明度通道渲染或平均加权法,会导致严重的重影或视觉上的不协调。本文在相邻两个相机配准误差较小的情况下,使用图割法获得接缝生成静态掩模,结合下文所介绍图像的无缝融合技术很大程度上消除了运动物体穿过固定接缝给视觉效果带来的影响。下文深入研究了羽化融合和多波段融合在CUDA上的实现和性能优化。
(1) 羽化融合的CUDA并行设计
羽化是一种基于空间域加权的融合方法,拼接中的加权融合一般使用线性加权函数对相邻两幅图像重合区域像素分别赋予不同权值进行求和获得最后拼接图的对应像素值。本文使用图割法生成接缝,二值图掩模上直观反应只有目标像素(像素值为255)和背景像素(像素值为0),因此不存在像素重合的情况,结合上述情况采用距离变换[10,17]来生成权值图。权值由每个目标像素与其最近的背景像素的欧式距离来确定,即目标像素离接缝边缘的最近距离,使离接缝越近权重越低从而达到模糊的效果。即掩模中像素M(p)的距离权值图可表示为:
(5)

图2 CUDA实现羽化融合的步骤
式中,最近距离min(d(p,p0))表示M(p0)为当M(p)是目标像素时距离最近的背景像素。得到直接由距离变换获得权值wd(p),将其归一化到[0,1]之间获得最终的权值图w(p)。由于使用静态掩模,如图2所示权值图提前在CPU计算再传入GPU,一方面避免重复计算,另一方面距离变换包含大量的判断指令会造成线程束中产生diverge[7](分歧),所以并不适合CUDA实现。最后,在GPU中进行逐像素加权运算对像素每个色彩分量进行求和与归一化操作并将其映射到拼接视频上,该操作可表示为:
(6)
其中,Ii与wi分别对应第i个相机实时图片与权值图,p为图片上单个像素(RGB或RGBA)。式(6)属于逐像素的重复密集型运算与CUDA的编程模型完全相符,可以很容易实现加速。羽化融合在CUDA上的实现步骤如下所示:
算法2羽化中的加权与归一化操作CUDA核函数
sx←blockIdx.x*blockDim.x+threadIdx.x▷图像列坐标索引
sy←blockIdx.y*blockDim.y+threadIdx.y▷图像行坐标索引
对图像中每一点进行加权操作
forallpintheconrespondingpicturedo
Ii(p(sy,sx)R)+=wi(p′(sy,sx));▷对R通道加权
Ii(p(sy,sx)G)+=wi(p′(sy,sx));▷对G通道加权
Ii(p(sy,sx)B)+=wi(p′(sy,sx));▷对B通道加权
end for
对图像中的每一点进行归一化操作
forallpintheconrespondingpicturedo
Ii(p(sy,sx)R)=wi(p(sy,sx));▷对R通道归一化
Ii(p(sy,sx)G)=wi(p(sy,sx));▷对G通道归一化
Ii(p(sy,sx)B)=wi(p(sy,sx));▷对B通道归一化
end for
(2) 多波段融合的CUDA并行设计
在大多数情况下羽化的效果足以满足监控系统基本的视觉要求。但是通过空间权重来模糊接缝远达不到最理想的视觉效果,因为这种方法难以兼顾亮度差异与细节模糊。文献[5]提出基于拉普拉斯金字塔的多波段融合算法有效地解决了此问题,大幅度提高了拼接视频的视觉效果。拉普拉斯金字塔是通过对相邻两层的高斯金字塔差分将原图分解成多层不同分辨率,不同尺度(即不同频带)的子图。这些子图构成了带通滤波金字塔,然后分别对高低频带的子图平滑加权,最后将子图融合(重构金字塔),这样同时兼顾了高频信息(局部细节)和低频信息(光照),最后金字塔的第0层即为融合完成的图像。
图3中高斯金字塔的第0层是已经做过透视变换的视频帧,随后一层的图像分辨率是前一层的四分之一(图像宽高分别缩小一倍)。从高分辨率向低分辨率处理叫作Reduce,相反从低分辨率向高分辨操作叫作Expand,这两个操作复杂度较高并贯穿整个过程,因此是CUDA实现图像金字塔的关键。

图3 CUDA构造拉普拉斯金字塔的步骤
Reduce运算在空间域的表达如下:
(7)
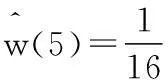
算法3REDUCE操作CUDA核函数
1:sx←blockIdx.x*blockDim.x+threadIdx.x▷进行垂直方向卷积使第l-1层图像列坐标索引
2:sy←2*blockIdx.y▷进行垂直方向卷积第l-1层图像行坐标索引
3:dy←blockIdx.y▷第l层的行坐标索引

5:_syncthreads( )▷线程块内部线程同步确保卷积中间结果全部存入共享内存
6:ifthreadIdx.x 7:dx←(blockIdx.x*blockDim.x+2*threadIdx.x)/2▷第l-1层列坐标索引 9:end if 与Reduce相反,Expand运算在空间域的定义如下: (8) 其中只有当i-m,j-n这两项为偶数才能被2整除作为行列索引。Gl,k是对Gl层做k次Expand操作的结果。Expand操作的CUDA步骤如下所示: 算法4EXPAND操作CUDA核函数 1:dx←blockIdx.x*blockDim.x+threadIdx.x▷第k+1次EXPAND操作结果的图像列坐标索引 2:dy←blockIdx.y*blockDim.y+threakIdx.y▷第k+1次EXPAND操作结果的图像行坐标索引 3:sharedmem1←Gl,k+1(dy/2,dx/2)▷根据坐标关系将第k次EXPAND操作结果图像存入共享以进行卷积运算 4:_syncthreads( )▷线程块内部线程同步确保上述赋值全部完成 5:以下判断确保threadIdx.y为偶数可以被2整除才能使threadIdx.y/2做为图像卷积的坐标索引(参考公式(8)中行列索引定义) 6:ifthreadIdx.y is eventhen 8:endif 9:_syncthreads( )▷线程块内部线程同步确保水平方向卷积的中间结果全部存入共享内存 为尽可能减少计算量,图3中对掩模向下进行高斯卷积(REDUCE)构造高斯金字塔仅在拼接初始帧进行,生成的每一层高斯权重图分别对拉普拉斯金字塔对应层做羽化操作(羽化的CUDA实现见上一小节)。 2实验结果及分析 2.1硬件配置与实验平台 为验证与研究视频拼接性能表现,分别在CPU与GPU上对4路1080p高清视频获得760万像素超宽视野视频的拼接过程进行了性能对比。实验中使用了三块不同架构的NVIDIA GPU(如表1所示)来验证加速效果。为保证GPU的性能不被其他硬件条件影响,它们均在同一台服CPU型号为Intel(R) Xeon(R) CPU E3-1230服务器上运行,同时该CPU作为性能对比计算的CPU。实验运行的软件环境为CUDA6.0[7]。 表1 测试GPU硬件参数一览 续表1 2.2性能测试与分析 (1) 透视变换在CPU与CUDA上实现的性能比较 表2中的实验结果表明透视变换在三种不同架构的GPU上的实现相对于CPU加速了10倍以上。而从RGB与RGBA在GPU上的性能对比可知,使用RGBA进行合并内存访问相对RGB未对齐访问在不同的GPU上减少了25%~30%运算时间。 表2 透视变换在CPU与GPU实现的性能比较(时间单位:ms) (2) 图像融合在CPU 与CUDA 上实现的效果和性能对比 表3给出了羽化与多波段(构造五层拉普拉斯金字塔)在CPU与GPU上实现的性能对比。因为羽化计算对CUDA编程更加友好,其加速比明显高于多波段融合。与透视变换相反,特别在多波段融合的CUDA实现中,使用RGBA的性能较RGB下降度较大,为了提高内存读取效率,使用共享内存存放中间结果。但是每个多流处理器中最多仅包含64 KB的共享内存与一定数量的寄存器,那么共享内存与寄存器容量无法满足当前活动线程的请求。因此一部分线程处于等待状态导致并行度降低,RGBA在内存中比RGB多出三分之一的容量,并行度必然要小于使用RGB存储格式来进行融合。图4中是两组人同时穿过接缝的情况下不同融合方法的接缝处效果,该接缝由一组随机样本帧使用图割法获得。(a)中靠上的黑衣男子头部在经过接缝时中出现明显的错位现象,相对于(a),(c)使用五层拉普拉斯金字塔融合后接缝痕迹与色差几乎消失。(b)中羽化融合对接缝处做了一定的模糊处理,接缝穿过人的不自然效果几乎消失,但两侧依然存在较明显的亮度差异。 表3 图像融合在CPU与GPU上实现的性能对比(时间单位:ms) 图4 相同场景下不同融合方法与无融合接缝视觉效果对比 (3) 与开源拼接软件的性能比较 本文选取OpenCV中Stitching模块进行比较,相比于其他拼接软件,OpenCV开放源码便于修改接口和计算时间,并且包含部分CUDA加速。表4中给出了4路1080p视频拼接分别使用OpenCV、CPU以及CUDA(使用GTX780显卡)实现所用的时间。从直接拼接与羽化拼接可知,文中方法在CPU上的实现就已经接近甚至超过包含部分CUDA加速的OpenCV中的方法,足以证明文中方法的高效性。 表4 文中方法与OpenCV中拼接模块的性能比较 (4) 实时多路高清视频拼接总体性能分析 由于CPU与GPU之间的传输使用双缓冲和多流异步传输技术,因此传输所消耗的时间与GPU计算重叠并不计算在总时间内。表5为在完整拼接流程在CPU上和GPU上实现的性能比较,结果表明GPU相对于CPU有9~15倍以上的加速。 表5 视频拼接在CPU与CUDA上实现的总用时与加速比(时间单位:ms) 表1中可知最新架构的GTX750具备较高的时钟频率,但是多流处理器的数量远少于其他型号使常驻线程数量大量减少。此影响突出体现在直接拼接和羽化融合这两种纯逐像素级别运算的方法,尽管GTX750可以分别达到90 fps和45 fps的拼接速率,但是运算效率大幅度落后其他两块显卡。从整体视觉效果上对比来看,图5(b)中基于距离图的羽化融合大体上并没有出现比较严重的拼接痕迹,在保证拼接速度的情况下,基本符合视频监控的基本要求。而图5(c)中多波段融合保证了良好的视觉效果但表5中的结果表明它过多的牺牲了性能。此时由于GPU片上内存资源有限通过RGBA在保证字节对齐来使用RGB格式时,仅GTX780可以完全满足实时性,GTX480可达到23 fps拼接效率勉强满足实时性。 图5 (a)从4路1080p高清网络相机获取的图片(顺序由左自右)(b)、(c)、(d)分别为直接拼接,羽化,多波段融合输出效果(已剪裁掉部分黑边),明显接缝处在图中用白框表示 图6给出随着分辨率的增长(600到1000万像素)不同方法的性能增长曲线。可知直接拼接与羽化的性能曲线随着分辨率的增长变化非常微弱,即使达到1000万像素,在多流处理器数量较多的GTX780、GTX480上拼接速度仅仅下降了10%左右,GTX750也可以保持35 fps拼接速度。但分辨率的增长意味更多的线程同步以及硬件资源有限带来并行度下降,千万像素输出分辨率的多波段融合仅在性能最强大GTX780上可以达到20 fps的拼接帧率。不过总体来看,实时拼接的总时间的增长率仅为输出视频分辨增长幅度的二分之一或者更小。表明随着相机路数的增加同时获取更高分辨率的宽视野视频,使用文中的实时拼接方法可以大幅度地提高计算效率比。 图6 在三种不同型号GPU上不同分辨率的视频拼接性能比较 3结语 本文提出了一种使用多相机获取多路高清视频进行实时拼接的方法。针对透视变换、图像融合等运算量较大的算法在NVIDIA GPU上的并行优化进行了研究。实验结果表明,该方法可根据GPU性能指标选取最高效的融合方法,同时可选择性地封装对CUDA计算友好的数据存储格式,即保证了视觉效果,又在不同架构和计算性能的GPU上均可满足实时性要求。后续工作将围绕本文方法在多GPU上得移植以满足更多路高清相机拼接获取360度超高清全景视频的要求。 参考文献 [1] Stensland H K,Gaddam V R,Tennφe M,et al.Bagadus:An integrated real-time system for soccer analytics[J].ACM Transactions on Multimedia Computing Communications and Applications,2014,10(1s):7. [2] Stensland H K,Gaddam V R,Tennφe M,et al.Processing Panorama Video in Real-time[J].International Journal of Semantic Computing,2014,8(2):209-227. [3] Tang W K,Wong T T,Heng P A.A system for real-time panorama generation and display in tele-immersive applications[J].Multimedia,IEEE Transactions on,2005,7(2):280-292. [4] Brown M,Lowe D G.Automatic panoramic image stitching using invariant features[J].International journal of computer vision,2007,74(1):59-73. [5] Burt P J,Adelson E H.A multiresolution spline with application to image mosaics[J].ACM Transactions on Graphics,1983,2(4):217-236. [6] Xu W,Mulligan J.Panoramic video stitching from commodity HDTV cameras[J].Multimedia systems,2013,19(5):407-426. [7] Nvidia Corporation.CUDA Programming Guide Version 6.0[EB/OL].2014.http://www.nvidia.com/object/cuda_home_new.html. [8] Kwatra V,Schödl A,Essa I,et al.Graphcut textures:image and video synthesis using graph cuts[J].ACM Transactions on Graphics.ACM,2003,22(3):277-286. [9] Hartley R,Zisserman A.Multiple view geometry in computer vision[M].Cambridge university press,2003. [10] Shih F Y,Wu Y T.Fast Euclidean distance transformation in two scans using a 3×3 neighborhood[J].Computer Vision and Image Understanding,2004,93(2):195-205. [11] The roots of Storymix Media.VideoStitch Studio V2[EB/OL].2014.http://www.videostitch.com/. [12] New House Internet Services B.V.PTGui Pro[EB/OL].2014.http://www.ptgui.com. [13] Andrew M,Bruno P,dangelo,et al.Hugin:Panorama photo stitcher[EB/OL].2014.http://hugin.sourceforge.net. [14] Bentley J L.Multidimensional divide-and-conquer[J].Communications of the ACM,1980,23(4):214-229. [15] Fischler M A,Bolles R C.Random sample consensus:a paradigm for model fitting with applications to image analysis and automated cartography[J].Communications of the ACM,1981,24(6):381-395. [16] Triggs B,McLauchlan P F,Hartley R I,et al.Bundle adjustment—a modern synthesis[M].Vision algorithms: theory and practice.Springer Berlin Heidelberg,2000:298-372. [17] 宋宝森.全景图像拼接方法研究与实现[D].哈尔滨工程大学,2012. [18] Juan L,Gwun O.A comparison of sift,pca-sift and surf[J].International Journal of Image Processing,2009,3(4):143-152. 中图分类号TP3 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.02.030 收稿日期:2015-02-12。国家重点基础研究发展计划专项基金项目(2012CB719905)。王震,硕士生,主研领域:计算机视觉。张博凯,本科生。王静,硕士生。李圣,硕士生。郑宏,教授。