基于主题词的微博热点话题发现
2016-03-17叶成绪刘少鹏
叶成绪 杨 萍 刘少鹏
1(青海师范大学计算机学院 青海 西宁 810008)
2(中山大学信息科学与技术学院 广东 广州 510006)
3(青海师范大学生命与地理科学学院 青海 西宁 810008)
基于主题词的微博热点话题发现
叶成绪1,2杨萍3刘少鹏2
1(青海师范大学计算机学院青海 西宁 810008)
2(中山大学信息科学与技术学院广东 广州 510006)
3(青海师范大学生命与地理科学学院青海 西宁 810008)
摘要近年来,微博网站已成为海量信息的发布平台。微博丰富的信息为用户提供便利的同时,也带来了信息过载的风险。针对热点话题发现能够降低信息过载的风险,改善用户体验。结合最长公共子串和维基百科知识,提出一种基于主题词的中文微博热点话题发现方法。首先,获取微博数据的高频最长公共子串,作为描述话题的候选主题词;其次,利用维基百科知识,对候选主题词进行筛选;最后,对主题词集合聚类以发现话题,并计算每个话题的能量,从中选取热点话题。在真实数据集上的实验表明,该方法能有效发现微博热点话题。
关键词主题词维基百科最长公共子串热点话题发现微博
HOT MICROBLOGGING TOPICS DISCOVERY BASED ON SUBJECT TERMS
Ye Chengxu1,2Yang Ping3Liu Shaopeng2
1(School of Computer Science, Qinghai Normal University,Xining 810008,Qinghai, China)2(School of Information and Technology, Sun Yat-Sen University,Guangzhou 510006,Guangdong, China)3(School of Life and Geography Sciences, Qinghai Normal University, Xining 810008,Qinghai,China)
AbstractIn recent years, microblogging websites have become the publishing platform of massive information. While providing convenience to users, the abundant microblogging information also brings in the risk of information overload. Hot topics discovery can reduce the risk of information overload and improve user experience. Aiming at this, in this paper we present a subject terms-based hot topics discovery method for Chinese microblogging in combination with longest common substrings and Wikipedia knowledge. First, it acquires the high-frequency longest common substring of microblogging as candidate subject terms of description topics. Secondly, it utilises Wikipedia knowledge to screen candidate subject terms. Finally, it collects and clusters the subject terms to discover the topics, and calculates the energy of each topic and then selects the hot topics among them. Experiment conducted on real dataset demonstrate that our method can effectively discover hot microblogging topics.
KeywordsSubject termWikipediaLongest common substringHot topic discoveryMicroblogging
0引言
微博是近年来互联网快速发展的产物,作为一个基于用户关系的信息分享、传播以及获取的平台,它具有内容生产便利、信息传播迅速和数据实时海量等特点。以新浪微博为例,截止到目前,其注册用户数已超过2.5亿,每天有接近1亿条的消息发布,内容从个人日常生活琐事到具有历史性影响的重大新闻,无所不有。这些数据包含丰富的信息,为信息探索提供了机遇,同时也带来了巨大挑战[1]。
微博热点话题,是由大量用户针对具体事件或者观点的讨论而形成,内容多与突发新闻事件相关。热点话题发现能降低信息过载的风险,改善用户信息获取的体验。比如,帮助记者发现有价值的新闻;或者为普通用户推荐感兴趣的话题;或者应用于话题排行榜等服务。
基于向量空间模型的热点话题发现技术[2,3],使用高频关键词描述话题,选取包含微博数目超过一定阈值的话题作为热点话题。该技术存在两个明显的缺陷:第一,关键词难以准确概括相关热点话题。比如在热点话题“天宫一号成功发射”中,多数分词软件没有收录关键词“天宫一号”,导致无法正确分词。ICTCLAS软件(http://ictclas.org/)的切分结果为:天宫/n 、一/m、 号/q,单凭这三个独立无序的关键词无法准确表达热点话题的内容。第二,热点话题选取方法未充分考虑微博平台的特点,不利于用户获取有价值的信息,影响了热点话题发现的效果。微博平台的传播途径和关注结构,决定热点话题的形成因素,不但包括话题本身意义大小,还包括话题传播者的影响力。因此,只根据微博数目来选取热点话题是不够的。
针对上述问题,本文结合最长公共子串和维基百科知识,提出了一种基于主题词的中文微博热点话题发现方法。话题本质上是重复出现内容的高度概括,高频最长公共子串往往是短语,比关键词更能准确描述话题,可作为话题的候选主题词。但是,高频最长公共子串,可能是毫无意义的字符串。考虑到维基百科的知识能够比较准确而全面地反映客观世界的各种现象,有助于改进文本挖掘和自然语言处理等任务[4,5],因此本文使用维基百科知识筛选高频最长公共子串,得到主题词集合。在此基础上,根据主题词共现频率,对其聚类以发现话题,并按照话题能量大小,选取最终的热点话题。
本文的主要贡献包括以下3个方面:
1) 结合最长公共子串和维基百科知识,检测主题词;
2) 对主题词进行聚类以发现话题,并按照话题能量,选取热点话题;
3) 在真实数据集上的实验表明,该方法能有效发现热点话题。
1相关工作
热点话题发现多采用向量空间模型。文献[2]提出了一个Twitter爆炸性新闻发现与跟踪的方法,并设计了Hotstream系统,对Twitter中爆炸性新闻进行收集、分组、排序与跟踪,提供给系统使用者。 TwitterMonitor系统[3]能够实时识别微博的话题趋势,对话题进行分析并提供相关的描述。
借助其他领域模型,结合微博自身特点,是热点话题发现研究的新方向。文献[6]介绍了一种基于时序和社会关系评价的Twitter热点话题检测方法,其思想是:在一个适当的时间段内,如果一个话题可以被广泛地检测且在此之前很少出现,那么该话题在此时间段里是新热点话题。在具体检测过程中,根据Aging理论,为关键词建立生命周期模型,选择相应的高频关键词集合,作为新热点话题。Labeled LDA模型[7],把Twitter内容映射到substance、style、status和social四个维度,利用该模型对用户和tweets按照话题进行区分,缺点是模型复杂,计算量大。文献[8]认为单一主题事件的大量信息发布,与早期的讨论明显不同,可从中发现新话题,采用词典学习解决新话题识别的问题,提出一个基于检测和用户产生内容聚类的两阶段方法。
国内针对微博的研究较少。基于LDA的微博生成模型MB-LDA[9],综合考虑了微博的联系人关联关系和文本关联关系,辅助微博的主题挖掘,采用吉布斯抽样法对模型进行推导,在挖掘出微博主题的同时,还能挖掘出联系人关注的主题。文献[10]提出一种中文微博新闻话题检测的方法,即在线检测微博消息中大量突现的关键词,综合考虑其词频和增长速度,构造复合权值,用以量化关键词作为新闻主题词的合适程度,并将它们进行增量式聚类,从而找到新闻话题。该方法基于ICTCLAS分词软件,只能找到部分主题词;并且检测效果依赖计算参数值的选取,稳定性和自适应性较差。
2基于主题词的微博热点话题发现
热点话题发现依赖主题词的检测以及话题能量的计算。本文的方法包括3个步骤:首先,获取微博数据的高频最长公共子串,作为描述话题的候选词项;其次,利用维基百科知识,对候选主题词进行筛选;最后,对主题词集合进行聚类以发现话题,并按照话题能量大小,从中选取热点话题。
2.1基本概念
表1列出了本文所使用的主要符号及其说明。

表1 符号说明
本文涉及的术语定义如下:
定义1高频最长公共子串。在D中频繁出现,且频率超过设定阈值的最长公共子串。
定义2主题词。在D中用于描述某个话题的关键词或者短语。
主题词必然是高频最长公共子串,但是高频最长公共子串,不一定是主题词。两者紧密联系,但有所区别。
定义3微博流行度。在特定时间段中,微博被转发次数forward(di)和被评论次数comment(di)的累加。
popular(di)=forward(di)+comment(di)
(1)
定义4用户权威度。在特定时间段中,用户粉丝数目fans(ui)与关注用户数目follow(ui)的比值,加上用户被提及次数at(ui)与发表微博数目weibo(ui)的比值。
(2)
定义5话题能量。在D中与该话题相关的所有微博能量累加,其中单条微博能量是微博流行度和用户权威度的乘积。
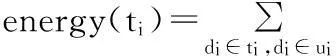
(3)
话题能量反映了其社会影响力,提供了相应的量化评估标准。
定义6热点话题。话题能量超过设定阈值的话题。
热点话题与普通话题相比,参与讨论的用户更多,传播范围更广。具体体现在文本内容上,其微博流行度更高;而从发布行为来看,其用户权威度更大,使得话题的影响力越大。
2.2高频最长公共子串获取
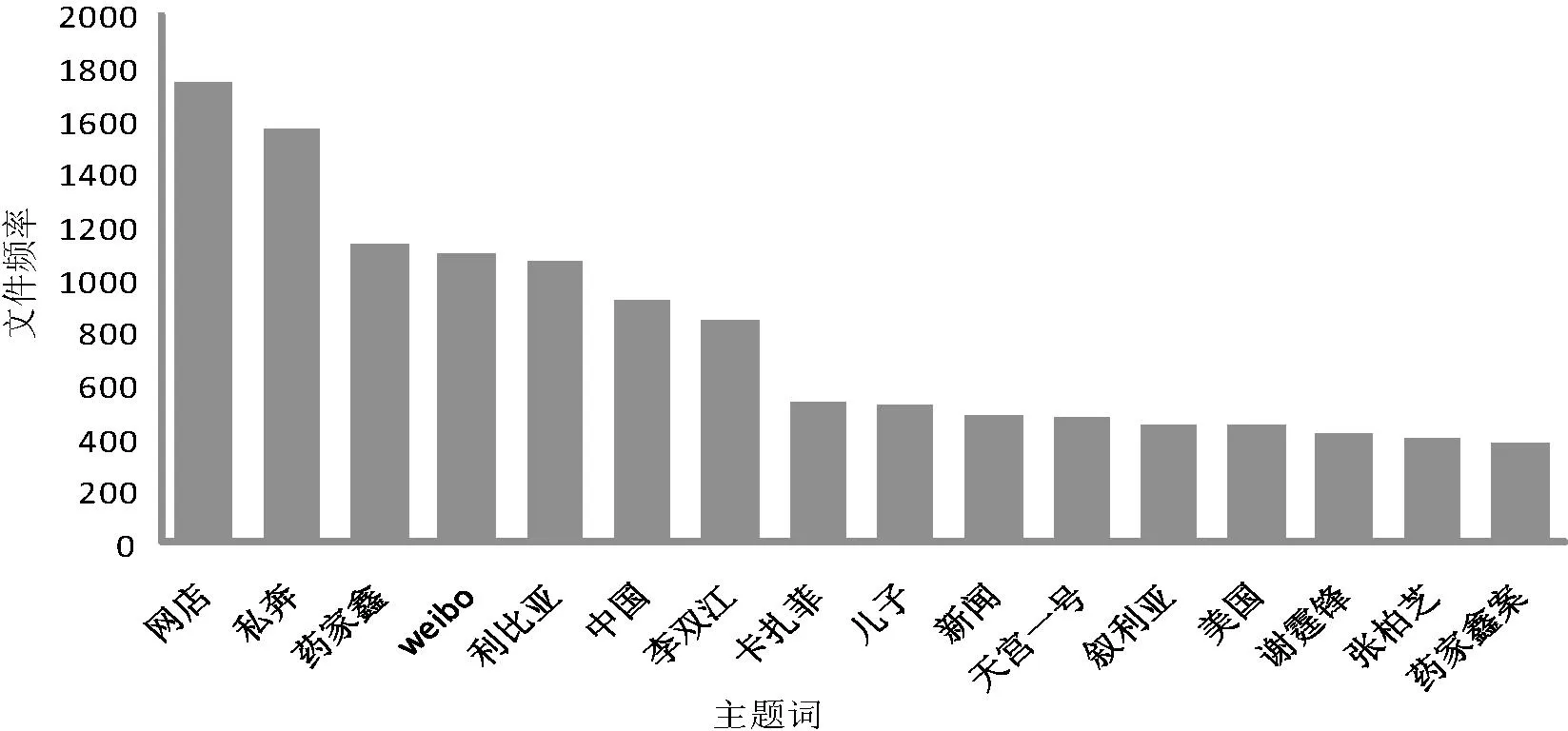
主题词是热点话题发现的关键,高频最长公共子串则是主题词的候选。本文设计FLCS算法,用于获取微博数据集合的高频最长公共子串集合,作为候选的主题词集合。 FLCS算法包括3个步骤:1)设置构建候选的主题词集合E的最大迭代次数MAX_ITERATION。在每次迭代过程中,随机抽取D中任意两条微博di和dj,借助LCS算法得到它们的最长公共子串,对于符合长度范围[MIN_LCS, MAX_LCS]的,统计其文件频率并加入E中。 2)对于E中所有候选的主题词,按照文件频率由大到小重新排序。 3)遍历E中所有候选的主题词ei,如果其文件频率DF(ei)小于设定的阈值FREQ_THRESHOLD,则删除之。
LCS算法是FLCS算法的关键步骤,它利用了最优子结构性质,采用动态规划的思想求解两个字符串的最长公共子串。对于字符串S和P,为其所有可能的前缀组合找到最长的公共后缀:
(4)
从中选择最大的公共后缀:
(5)
最后,根据字符串序列的匹配位置信息,容易获取最长公共子串。
FLCS算法采用随机抽取的方式,而不是简单地对D中所有微博两两求解最长公共子串,算法的时间复杂度为O(|MAX_ITERATION|)。通常MAX_ITERATION设为|D|,因此对于海量的微博数据集合, FLCS算法是简单高效的。FLCS算法完整的伪代码如下:
输入:D,最大迭代次数MAX_ITERATION,频率阈值FREQ_THRESHOLD,最小长度MIN_LCS,最大长度MAX_LCS
输出:候选的主题词集合E
步骤:
1:for k=1 to MAX_ITERATION
2:随机抽取两条微博di和dj
3:获取最长公共子串lcs=LCS(di,dj)
4:if |lcs|≥MIN_LCS && |lcs|≤MAX_LCS
5:统计lcs文件频率
6:lcs加入到E
7:end if
8:end for
9:将E中所有候选的主题词按照文件频率由大到小重新排序
10:for i=1 to |E|
11:if DF(ei)≤FREQ_THRESHOLD
12:删除ei
13:end if
14:end for
2.3主题词筛选
主题词多是高频最长公共子串。判定高频最长公共子串作为主题词合适与否,依赖于丰富的语料背景知识。维基百科作为一部网上百科全书,提供了较为完备的语料知识。基于上述思路, 利用维基百科的条目知识,设计WE算法,筛选出合适的主题词。
算法包括5个步骤:1)遍历E中的每一个候选的主题词ei。 2)检查ei是否为停用词,若是,则删除之。 3)在维基百科中检索候选ei对应的条目。 4)对该维基百科条目进行简繁转换预处理,计算主题词与其相似度。 5)检查相似度是否小于设定的阈值SIM_THRESHOLD,若是,则删除ei。
WE算法采用编辑距离计算主题词与维基百科条目的相似度。编辑距离,又称Levenshtein距离,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符、插入一个字符以及删除一个字符。字符串之间的编辑距离越大,其相似度越小;否则相似度越大。相似度值域∈[0,1],0表示两个字符串完全不同,1表示两个字符串完全相同。
(6)
式(6)考虑了主题词与维基百科条目同义或者近义关系的情况。比如,主题词“小悦悦”和维基百科条目“小悦悦事件”,它们的编辑距离为2,相似度为0.75。若选择合适的相似度阈值,与维基百科条目同义或近义的主题词,将得以保留,而不是简单删除。
WE算法完整的伪代码如下:
输入:候选的主题词集合E,维基百科中文简繁转换方案ZhConversion,停用词文件STOPWORD,相似度阈值SIM_THRESHOLD
输出:主题词集合E
步骤:
1:for i=1 to |E|
2:检查ei是否为停用词,若是,直接删除
3:获取ei对应的维基百科条目w=wiki(ei)
4:w进行中文简繁转换预处理
5:计算ei和w的相似度s=sim(ei,w)
6:if s 7:删除ei 8:end if 9:end for 2.4热点话题发现 话题发现是通过对主题词集合聚类完成的,每个聚簇代表一个话题,簇中的主题词则作为该话题的描述。每个话题可计算其能量值,并按照能量值由高到低排序,超过设定能量值阈值的,则作为热点话题。基于上述思想,采用AP聚类算法,设计了TAP热点话题发现算法。TAP算法的具体实现流程如下所示: 输入:主题词集合E,能量阈值ENERGY_THRESHOLD 输出:热点话题集合T 步骤: 1:初始化主题词相似度集合S={} 2:设定主题词为聚类中心的概率P={pi|pi为常数} 3:for i=1 to |E| 4:for j=i+1 to |E| 5:计算主题词的相似度s=sim(ei,ej) 6:S ← (i,j,s) 7:end for 8:end for 9:AP聚类得到话题集合T=AP(S,P) 10:for i=1 to |T| 11:计算话题的能量值s=energy(ti) 12:if s 13:删除ti 14:end if 15:end for AP算法是TAP算法的关键步骤,影响了热点话题发现的性能和效果。该算法是Brendan J. Frey等人在Science杂志上提出的一种新型聚类算法,它的特点是快速、高效,无需指定聚类数目。算法以数据点之间的相似性矩阵作为输入;数据点视为网络的节点,节点之间通过网络的边,传递吸引度(responsibility)和归属度(availability)消息;每个数据点初始化为聚类中心,随着信息的迭代积累,真正的聚类中心被选中,数据点的聚类标签也随之确定[11]。其中,吸引度和归属度计算分别如式(7)和式(8)所示。 (7) (8) 定义R=(r(ei,ek)),A=(a(ei,ek))分别为吸引度矩阵和归属度矩阵,t代表算法的迭代次数,阻尼因子λ∈[0,1]。则消息矩阵更新公式为: Rt+1=(1-λ)·Rt+λ·Rt-1 (9) At+1=(1-λ)·At+λ·At-1 (10) 主题词之间的相似性度量是影响AP算法聚类效果的关键因素。假设主题词在相同微博共现的次数越多,它们属于同一个话题的概率越大。根据该假设,得到相似性度量公式为: sim(ei,ek)=occur(ei,ek) (11) 完成主题词聚类后,找出话题的所有相关微博,根据式(3)计算每个话题能量,选取热点话题。假设微博包含某个话题的主题词越多,则与该话题相关的概率越大。微博与话题的相似性度量公式为: sim(di,tj)=len(LCS(di,tj)) (12) 3实验结果与分析 3.1数据集 本文抓取了2012年1月13日至2012年2月23日的新浪微博热点大事件的数据。表2给出数据集详细的描述,按照热点话题对微博分类,包含9个话题,12 987条微博。实验平台是Intel Core i3-530M(2.93 GHz)处理器,内存容量为2 GB。实验参数ENERGY_THRESHOLD、FREQ_THRESHOLD、MIN_LCS、MAX_LCS、SIM_THRESHOLD和MAX_ITERATION分别设为: 3000、2、2、5、0.6和|D|。 表2 实验数据 3.2主题词检测 WE算法可以识别数据集的绝大部分主题词。图1是关于前16个主题词的文件频率详细情况,短语“天宫一号”、“校车安全”和“药家鑫案”等均可识别。 图1 WE算法的前16个主题词的文件频率 3.3热点话题发现 TAP算法在主题词集合的基础上,聚类得到话题;然后根据能量大小,有效地发现热点话题。实验结果如表3所示。话题9761交流的是“李双江儿子打人事件”;话题5274是关于“药家鑫杀人案”探讨;话题6564谈论的是“微博私奔”,出现主题词“郭美美”,是因为该话题的很多微博与“郭美美事件”相关;话题5016是关于“利比亚何去何从”的问题,“叙利亚”和“伊拉克”的出现,丰富了该话题的外延;话题7398对“网店征税”进行了讨论,“淘宝网店”揭示了具体征税的对象,但主题词过多,不利于用户准确获取话题的信息;话题6882讲述的是“谢霆锋和张柏芝离婚”;话题11778是关于“甘肃幼儿园校车车祸”的新闻,“校车安全”与其紧密相关;话题10025报道了“天宫一号成功”的信息;话题5351是“Weibo上线”的报道,属于“新浪”的产品新闻等等。 表3 TAP算法发现的热点话题 表3还展示了热点话题的能量值。用户权威度和微博流行度越高,话题的能量值越大,话题排名越靠前。使用能量作为热点话题的选取依据,符合微博平台的特点,真实地反映了话题的社会影响力。其中,“李双江儿子打人事件”的能量值最高,“富二代”折射了当前的社会结构问题:收入差距过大,缺乏公平竞争的环境。“药家鑫杀人案”紧随其后,网民希望看到合理公正的判决结果,保证法律面前人人平等,维护每个人的合法利益。“天宫一号成功”和“Weibo上线”等重大新闻反而没有引起广泛关注,毕竟网民关心的只是与自身利益紧密相关的话题。热点话题的能量值,有助于理解话题的社会影响程度,改善微博服务的质量。 4结语 本文结合最长公共子串和维基百科知识,提出了一种基于主题词的中文微博热点话题发现方法。在真实数据集上的实验表明,该方法能有效发现微博热点话题。相比向量空间模型,本文方法检测的主题词能够更加准确地描述话题;采用话题能量作为热点话题的选取依据,符合微博平台的特点。 如何在海量数据中高效地获取候选主题词,仍然是个挑战,后续的研究工作,将致力于开发高效的搜索算法。另一方面,如何更好地利用维基百科知识,保证主题词的质量,也是今后的研究重点。 参考文献 [1] Lin J, Snow R, Morgan W. Smoothing Techniques for Adaptive Online Language Models: Topic Tracking in Tweet Streams[C]//Proc of the 17th Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2011:422-429. [2] Phuvipadawat S, Murata T. Breaking News Detection and Tracking in Twitter[C]//Proc of 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology. Los Alamitos: IEEE Computer Society, 2010:120-123. [3] Mathioudakis M, Koudas N. TwitterMonitor: trend detection over the twitter stream[C]//Proc of the 29th Int Conf on Management of Data. New York: ACM, 2010:1155-1158. [4] Hu X, Sun N, Zhang C, et al. Exploiting internal and external semantics for the clustering of short texts using world knowledge[C]//Proc of the 18th Int Conf on Information and Knowledge Management. New York: ACM, 2009:919-928. [5] Lau J H, Grieser K, Newman D, et al. Automatic Labeling of Topic Models[C]//Proc of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Pennsylvania: Association for Computational Linguistics, 2011:1536-1545. [6] Cataldi M, Caro L D, Schifanella C. Emerging topic detection on Twitter based on temporal and social terms evaluation[C]//Proc of the 10th IEEE International Workshop on Multimedia Data Mining. New York: ACM,2010: 1-10. [7] Ramage D, Dumais S, Liebling D. Characterizing microblogs with topic models[C]//International AAAI Conference on Weblogs and Social Media. Washington: The AAAI Press, 2010:10-17. [8] Prasad S, Melville P, Banerjee A, et al. Emerging Topic Detection using Dictionary Learning[C]//Proc of the 20th Int Conf on Information and Knowledge Management. New York: ACM, 2011:745-754. [9] 郑斐然,苗夺谦,张志飞,等. 一种中文微博新闻话题检测的方法[J].计算机科学, 2012,39(1):138-141. [10] 张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展, 2011,48(10):1795-1802. [11] Frey B J, Dueck D. Clustering by passing messages between data points [J]. Science, 2007,315(5814):972-976. 中图分类号TP391.3 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.02.011 收稿日期:2014-06-15。国家社会科学基金项目(13BXW037);教育部春晖计划项目(Z2011023)。叶成绪,教授,主研领域:数据挖掘,智能计算,网络安全。杨萍,副教授。刘少鹏,博士。