基于KNN+层次SVM的文本自动分类技术
2016-03-17王金华周向东施伯乐
王金华 喻 辉 产 文 周向东 施伯乐
1(中国电子科技集团公司第三十二研究所 上海 200233)
2(成都军区通信网络技术管理中心 四川 成都 610000)
3(复旦大学计算机学院 上海 200433)
基于KNN+层次SVM的文本自动分类技术
王金华1喻辉2产文3周向东3施伯乐3
1(中国电子科技集团公司第三十二研究所上海 200233)
2(成都军区通信网络技术管理中心四川 成都 610000)
3(复旦大学计算机学院上海 200433)
摘要针对大规模文本的自动层次分类问题,K近邻(KNN)算法分类效率较高,但是对于处于类别边界的样本分类准确度不是很高。而支持向量机(SVM)分类算法准确度比较高,但以前的多类SVM算法很多基于多个独立二值分类器组成,训练过程比较缓慢并且不适合层次类别结构等。提出一种融合KNN与层次SVM的自动分类方法。首先对KNN算法进行改进以迅速得到K个最近邻的类别标签,以此对文档的候选类别进行有效筛选。然后使用一个统一学习的多类稀疏层次SVM分类器对其进行自上而下的类别划分,从而实现对文档的高效准确的分类过程。实验结果表明,该方法在单层和多层的分类数据集上的分类准确度比单独使用其中任何一种要好,同时分类时间上也比较接近其中最快的单个分类器。
关键词自动文本分类KNN层次SVM
INTEGRATING KNN AND HIERARCHICAL SVM FOR AUTOMATIC TEXT CLASSIFICATION
Wang Jinhua1Yu Hui2Chan Wen3Zhou Xiangdong3Shi Bole3
1(The 32nd Institution of China Electronics Technology Group Corporation,Shanghai 200233,China)2(Network Management Center of Chengdu Military Area Command,Chengdu 610000,Sichuan,China)
3(School of Computer Science,Fudan University,Shanghai 200433,China)
AbstractFor automatic hierarchical classification of large-scale text, k-nearest neighbours (KNN) algorithm has higher classification efficiency but is not effective for classifying the samples on the borders of categories. The support vector machine (SVM) classification algorithms have higher accuracy, however a number of previous multi-class SVM algorithms are composed of a number of independent binary classifiers, thus they become slower in training process and are not suitable for hierarchical category structures. This paper presents a new method which integrates both KNN and hierarchical SVM algorithm for automatic text classification. First we modify the KNN algorithm to quickly obtain K class labels of the nearest neighbours, and effectively sift out candidate categories of the documents with them. Then we use a multi-class sparse hierarchical SVM classifier with uniform learning to make top-down categories partition on the sample, so that implement the efficient and accurate classification process on the documents. Experimental results demonstrate that the classification accuracy of this method on classification dataset with single-layer and multi-layer is better than just using either of the methods, meanwhile it is also close to the fastest single classifier in classification time.
KeywordsAutomatic text classificationK-nearest neighbourHierarchical support vector machine
0引言
Web技术和新媒体的发展带来了文本大数据的快速增长,随着人们在互联网上便利地交流,各类电子化的文本文件、资料、档案等已逐步取代了纸质文档。对文档进行语义上的分类管理是传统的文档管理中普遍采用的有效方法,例如图书馆的书别目录检索。然而,面对海量的文本信息资源,传统的人工分类在人力耗费、时间响应等方面已经无法满足实际工作的需要, 因此亟待开发以自动文本分类技术为基础的自动文本管理系统。
当前流行的自动文本分类算法主要有神经网络NN(Neural Net)算法[1]、朴素贝叶斯NB(Naïve Bayes)方法[2]、K近邻KNN(K Nearest Neighbor)算法[3]和支持向量机SVM(Support Vector Machines)算法[4]等。Yang等[5]在数据集Reuters-2l578 上的实验表明,相比于其他方法,KNN和SVM方法无论在召回率还是准确率上都有一定程度的提高。KNN算法原理简单,分类效率较高,但其是一种基于实例的统计学习方法,对于处于类别边界的样本分类准确度不是很高。而SVM分类算法目标在于最大化分类边界之间的距离,因此分类准确度比较高,但训练分类器过程比较缓慢。总之,单独使用这两种方法中的任何一种都很难达到理想的分类效率和效果。
因此,研究者通过对KNN和SVM两种算法进行有机结合,一方面提升分类的准确度,一方面提高分类效率,从使海量文档自动分类达到较好的效果。文献[6]提出一种将KNN与SVM相结合的文本分类算法。首先使用KNN算法找出与文本最接近的K个邻居的类标签,然后在邻居类标签集上使用多个二值SVM分类器对样本进行精分,在减少有效候选类数目的同时,有效提高了分类的准确度。然而,由于这些二值分类器分别由不同的训练样本单独训练得到,可能无法保证学习得到的分类面在分类输出上保持良好的可比性。另一方面,其假设的单层文本类别结构在实际中往往是较少数的。文献[7]则首先使用所有类的SVM分类器对样本进行划分,然后对各类别的输出概率进行比较。只有当最大输出值(预测正确类)与次大输出值(其它最具混淆性的错误类)之间的差大于某个阈值时,才将该结果作为分类器的最终输出结果。如果其差值小于该阈值,则进一步使用KNN分类器来得到最终结果。这样提高了分类输出结果的置信度,然而,在最坏情况下,该方法的分类过程是SVM和KNN方法的线性叠加,分类的效率有所下降。
当文档的类别结构形成一个层次目录时,层次分类算法不但能显著地带来分类效率的提升,甚至能提高分类的准确性[8]。而大多数情况下,由于海量的文档集包含的语义种类丰富,也很难使用扁平的一层类别目录去包含它。在本文中,我们提出一种结合KNN和层次SVM分类的自动文本分类技术。在训练阶段,我们使用多类SVM算法统一对样本的层次目录进行学习,而不是独立地学习多个二值分类器,这样可以更有效地在各个层次分类面的输出上进行比较。在分类阶段,使用KNN对待分类样本的标签进行筛选之后,在分类候选集标签上使用学习到的SVM分类器进行自上而下的划分,有效减少了候选的SVM分类面的数目,加快了分类过程。同时排除了部分不相关的类别分类面的干扰,提高了自动分类的准确性。
1KNN与SVM算法
1.1KNN分类算法
K近邻KNN分类算法是基于实例学习的统计方法。其主要思想是在输入特征空间中计算训练样本里与待测试样例最近的K个邻居,通过这些最近的邻居类别标签来“投票”得出新样本的最终类别标签。
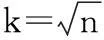
(1)
这样后验概率Pn(wi|x)的估计为:
(2)
也就是说,点x属于类别wi的后验概率就是体积V中标记为wi的样本点的个数与体积中全部样本点个数的比值。这样,为了达到最小的误差率,我们就选择使这个比值最大的那个类别作为最后的分类判别结果。
然而, KNN算法通常需要计算待测样本到所有训练样本的距离并排序,从而选出其最近的K个邻居。假设每个样本的特征维度为d,则上述步骤的时间复杂度为n×d+nlogn。在对海量文本进行分类时,n的值往往很大,特征维度也比较高。因此,为了加快KNN算法的执行效率,一般从两个方面改进算法的分类效率:1) 降低样本的维度,选择最精简的特征来表示文本向量,这种做法往往较为直观,但是当维度过少时分类效果会显著降低;2) 将训练集中的相似文本适当归并,将其作为一个文档来处理,这样将明显减少需要比较的文档数目。这里我们采用文献[6]中的方法,在每个自然类别中再对其进行类别内部文档的聚类,将其聚成j个子类。然后计算每个子类的中心向量,最后将待分类样本与这些子类的中心向量计算距离,从而快速找出最近的K个邻居中心。由于聚类后每个类别包含的文本数量急剧减少,因此KNN分类的算法效率有了明显的提高。
1.2层次SVM分类算法
支持向量机SVM方法具有较为完备的理论基础。在各种不同的实际应用中也表现出了较为优越的分类性能,并具有较高的计算效率,能够高效处理大规模数据。支持向量机利用训练数据来建模最大间隔超平面,然后使用超平面作为决策边界,对未归类的数据进行分类。所谓最大间隔,即训练集样本点到该超平面的最小几何间隔最大,而间隔越大则泛化错误越小,对于新数据的分类判别能力就越强。最终分类超平面的建模实际上只需要用到离超平面最近的少数训练样本,这些样本也就是“支持向量”,其他不是支持向量的训练样本点对分类超平面没有任何影响,因此支持向量机方法具有较高的稳定性。图1给出了支持向量机的示意。

图1 最大化间隔超平面和支持向量示意图
在实际应用中,文档的类别结构通常具有明显的层次分布而非单层扁平的结构。当多类别形成一颗层次树时,研究者发现层次分类模型比其对应的单层分类模型更加快速甚至有时更加准确[8]。因此,我们的分类模型基于层次分类框架。在本文中,我们将统一学习出一个多类的层次SVM分类器,各分类面的目标函数在同一个优化函数中实现,而不是分别训练多个二值分类器[6]。
首先,给出如下标记:令A(i)、C(i)、D(i) 和S(i) 分别表示层次类别中节点i的祖先、孩子、后裔和兄弟节点,且令A+(i) = A(i)∪i。X ⊂ Rd表示含d-维训练文本特征向量组成的集合,Y = {1,2,…,m } 为层次类别目录上的节点类别对应的编号(根节点除外)。层次SVM分类的训练过程如下:给定一组训练文本集D={(x1,y1),…, (xN,yN)},xk∈ X,yk∈ Y,k ∈ {1,…,N},学习m个SVM分类面w = {wi}⊂Rd,i=1,…,m,每个对应层次目录上的一个节点i。我们需要解如下的优化目标:

(3)
subject to

∀i∈A+(yk)∀k∈{1,…,N}
ξk≥0∀k∈{1,…,N}
其中,前两项是混合L1稀疏正则化和L2正则化项,第三项是hinge损失函数。C1、C2和C3是控制正则化项和损失函数平衡的参数。对于某个训练文本k对应的层次类别树上从正确的叶子节点yk到根节点路径上的所有节点,该损失函数将惩罚那些当前层次上的正确标签的分类输出与其他各容易混淆的兄弟节点的分类输出的差距小于1的情况。如果该差距越小,则对应的损失项越大,从而有效增加各层次上相似类别的判别能力。在多类别层次分类的时候,支持向量机中的支持向量往往变得比较稠密[10]。从减少存储开销以及分类时间的角度考虑,我们选择学习一个节俭的模型,其中每个分类面仅仅由若干个稀疏特征的权重组合而成。因此在层次学习框架中我们引入L1稀疏正则化项来对分类面的参数进行惩罚[11]。尽管L1正则化项包含绝对值操作,但不难证明该多类层次SVM分类目标函数对参数w来说仍然是一个凸优化问题。因此,我们可以很容易地使用一些有效的优化方法去解上述优化问题。我们将在下一节中介绍该模型的训练过程。
2KNN+层次SVM分类框架
2.1训练层次SVM分类模型
为了训练层次SVM模型,我们将1.2节的目标函数改写为:
minimizeJ(w)=Ω(w)+H(w)+r(w)
(4)
其中:

由于前两个等式右边可导,我们可以通过计算Ω(w) 和H(w)的子梯度去解决。我们使用一个两阶段的算法[11]来解决不可导项r(w),即正则化项中的稀疏问题。那就是,在每轮迭代t中,我们首先忽略r(w)且使用正则化对偶平均方法RDA(regularized dualaveraging)[12]来更新Ω(w)和H(w)中的参数wt并且得到临时中间变量wt+1/2。然后使用FOBOS更新来解r(w)中的L1正则化项,即,第t+1轮迭代中的新参数如下方式得到:
(5)
2.2KNN+层次SVM算法流程
在算法的训练阶段,两部分单独进行。KNN训练过程主要是对各个类中的子类进行聚类并找到最优的K值;层次SVM分类器的训练如2.1节所示,主要得到层次类别树上各分类面的参数。而在实际分类阶段,算法首先利用KNN分类算法计算其最近的K个邻居中心,然后统计其K个最近邻居中的所有类别,对于每个类别分别调用相应的层次SVM分类器进行分类。“KNN+层次SVM”算法流程如下所示:
算法KNN+层次SVM分类算法
输入样本集和待测样本x的特征向量
输出待测样本x的层次分类标签
步骤:
1) 通过距离函数选择与待测样本x距离最近的k个训练样本中心(子类中心向量);其中k为KNN训练得到的最优参数。
2) 对于这k个样本中心对应的每个类别wi,我们保留其对应的层次路径作为候选集,将待测样本x的特征向量输入该候选集对应的各层次的SVM分类器,计算样本x与路径上各类的相似度。
3) 若与叶子节点wi类的相似度值最大,则将类别wi对应的层次路径类别标签作为样本x的分类结果,算法结束。
“KNN+层次SVM”分类算法结合了KNN算法的时效性和SVM算法的准确性。通过SVM分类器对KNN分类器得到的邻居标签作为候选标签集进一步分类,达到的准确度比较高。该方法尤其对于类别标签比较多时更有效,可以使用KNN过滤掉一些明显不需要调用的类别对应的SVM分类器。
2.3文本预处理和特征选择
从原始的中文文本得到标准长度的文本向量需要一个文本预处理的过程。该过程主要由分词、去停用词和统计词频信息三部分组成。本文采用中科院计算所的开源分词工具ICTCLAS[13]来实现。我们对每篇文档中出现的词统计其词频和出现的文档数量(文档频率),以计算文档特征权重词频-反文档频率(TF-IDF)向量。在获得以上统计信息后,计算特征词典中每个特征词对于每个类别的区分度。这里使用交叉熵和互信息计算特征区分度的方法,将其加权平均来选择有效的特征。
3实验设置和实验结果
为了使文档自动分类系统具备良好的稳定性、扩展性和可用性,更加具备分类的准确行,本系统主要依托成熟的数据库系统来存储、管理分类信息、文本数据及各类算法参数等。由于分类信息的图结构特点,本系统采用Neo4J图数据库对网络数据进行存储。同时对海量文本数据采用Oracle关系数据库进行存储。
3.1实验数据集
• 训练文档数1614,有5个类别,测试文档数806,测试文档中包含与训练文档中相同的5个类别;
• 5个类别分别为:工作计划、军事训练、拉练、突击、武器装备;
• 每篇文档平均大小为1.32 KB;
• 文档特征维度为1000。
3.2实验结果与分析
• KNN与SVM相结合分类准确率与单独使用KNN或SVM的对比如表1所示;
• KNN与SVM相结合分类所需时间与单独使用KNN或SVM的对比如表2所示;
• 在文档维度为1000的条件下,SVM分类器的准确率为90.82% ;
• 在文档维度为10 000的条件下,K-SVM分类器的准确率达到最高,为92.18%。
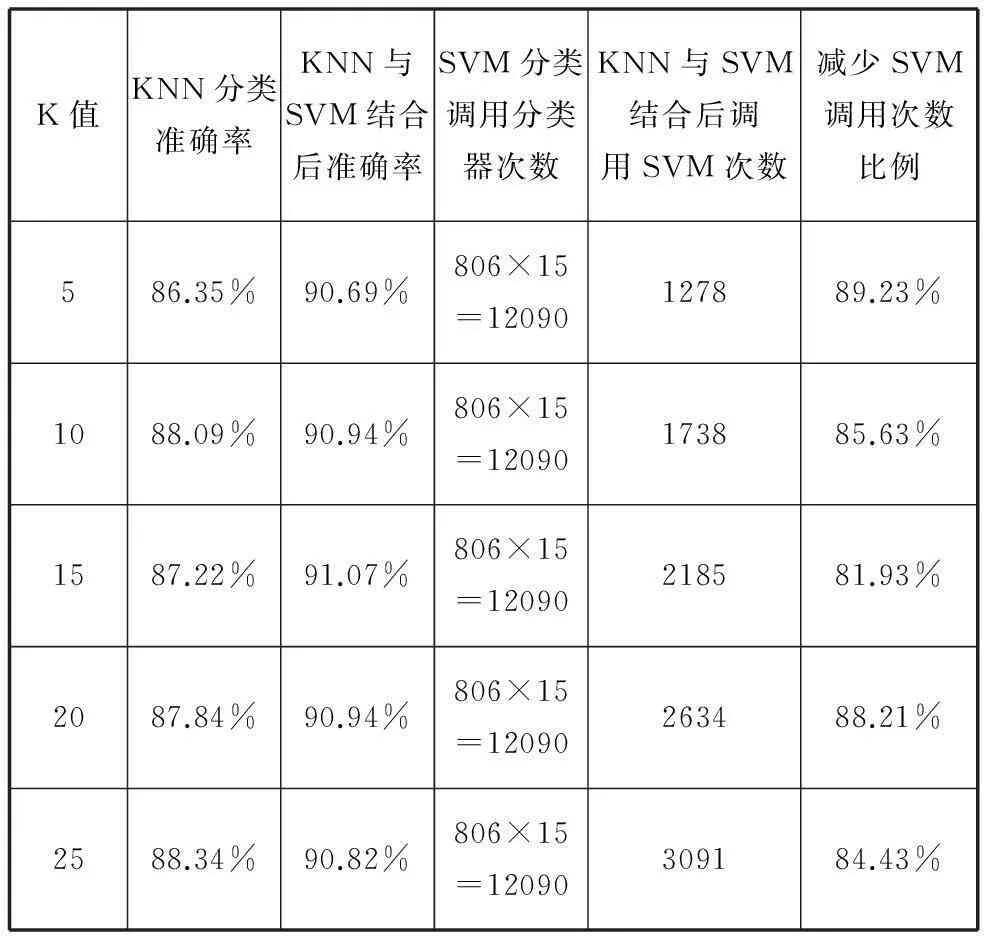
表1 KNN与SVM结合分类效果

表2 KNN与SVM相结合后所需时间
通过表1,我们观察到:
1) 当K值在5~15之间时,KNN与SVM结合后的准确率随K值的增大而增大;
2) 当K值在15~25之间时,改进后的准确率随K值的增大而减小,并最后等于仅有SVM分类器的准确率。
通过表1、表2可见,当K值较大时,KNN和SVM的结合分类器逐渐退化为SVM分类器;当K值合适时,不仅可以提高分类速度,还可以提高分类准确率。
4结语
本文提出了一种混合使用KNN与层次SVM来对文本进行自动分类的方法。使用加速KNN对文档的候选类别集有效筛选后,在较少量的统一学习的稀疏SVM分类器上进行最后的类别划分,实现了对文档的高效、准确的分类机制。在单层和多层的分类数据集上的实验结果表明,该方法的分类准确度比单独使用其中任何一种要好,同时分类时间上也比较接近其中最快的单个分类器。对于实际工程中的海量文本层次分类,该方法是解决大规模文本分类问题的值得参考的一种方法。
参考文献
[1] Ng H T,Goh W B,Low K L.Feature selection,perceptron learning,and a usability case study for text categorization[C]//20th Ann Int ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’97),1997:67-73.
[2] Lewis D D,Ringuette M.Comparison of two learning algorithms for text categorization[C]//Proceedings of the Third Annual Symposium on Document Analysis and Information Retrieval (SDAIR’94),1994:81-93.
[3] Masand B,Lino G,Waltz D.Classifying news stories using memory based reasoning[C]//15th Ann Int ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’92),1992:59-64.
[4] Vapnic V.The Nature of Statistical Learning Theory.Springer[M].New York,1995.
[5] Yang Y,Liu X.A re-examination of text categorization methods[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval.ACM,1999:42-49.
[6] 王强,王晓龙,关毅,等.K-NN与SVM相融合的文本分类技术研究[J].高技术通讯,2005,5(15):19-24.
[7] 匡春临,夏清强.基于SVM-KNN的文本分类算法及其分析[J].计算机时代,2010(8):29-31.
[8] Koller D,Sahami M.Hierarchically classifying documents using very few words[C]//Proceedings of the 14th ICML,1997:170-178.
[9] 张玉芳,万斌候,熊忠阳.文本分类中的特征降维方法研究[J].计算机应用研究,2012,29(7):2541-2543.
[10] Lee Y J,Mangasarian O L.Rsvm: Reduced support vector machines[J].Data Mining Institate Computer Sciences Department University of Wisconsin,2001,2(11):00-07.
[11] Wen Chan,Weidong Yang,Jinhui Tang,et al.Community Question Topic Categorization via Hierarchical Kernelized Classification[C]//Proceedings of CIKM’13,2013:959-968.
[12] Lafferty J D,McCallum A,Pereira F C N.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning,2001:282-289.
[13] ICTCLAS汉语分词系统[J/OL].http://www.ictclas.org/ictclas_files.html.
中图分类号TP302.1
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.009
收稿日期:2014-09-01。王金华,高工,主研领域:数据工程与信息系统。喻辉,工程师。产文,博士。周向东,教授。施伯乐,教授。
