Hadoop技术在移动支付行业的应用
2016-03-10梁明煌吴航
梁明煌 吴航

【摘要】 科学技术及互联网的发展,推动着大数据时代的来临。文章介绍了中国移动集团公司在移动互联网支付系统建设中成功运用Hadoop技术的典型案例。案例采用了Hadoop云计算技术,实现了分布式数据和计算框架,对海量数据进行分布式并发计算,提升了系统并行处理能力,减少了处理等待时间,满足了移动支付多样化及第三方支付平台接入的需要,系统健壮性也得到了极大的提高。
【关键词】 中国移动 Hadoop HDFS MapReduce 移动支付 调度引擎 任务引擎Application of Hadoop technology in mobile payment industry
Liang Minghuang Wu Hang
[Abstract] With the development of science and technology and the Internet, the advent of the era of big data. This article introduces the typical cases of the successful application of Hadoop technology in the construction of the payment system of China Mobile group. In this case the Hadoop cloud computing technology, realize the distributed data and computing framework, distributed & concurrent computing on massive data. Through the mechanism of Hadoop, we are able to enhance the ability of parallel processing, to meet the demand of mobile payment, to diversify the payment platform access need, system robustness has also been greatly improved.
[Key words] China Mobile Hadoop HDFS MapReduce Mobile payment Scheduling engine Task engine
引言
科学技术及互联网的发展,推动着大数据时代的来临。“互联网+”的创新模式使得传统行业与互联网融合发展,形成了更广泛的以互联网为基础设施和实现工具的新经济发展模式,也使得大数据的处理越来越引人注目。
Hadoop技术,在大数据分析以及非结构化数据蔓延的背景下,一出现就受到众多大公司的青睐。迄今为止,Hadoop在互联网领域已经得到了广泛运用,例如,Yahoo 使用4 000个节点的Hadoop集群来支持广告系统和Web 搜索的研究;Facebook 使用1 000 个节点的集群运行Hadoop,存储日志数据,支持其上的数据分析和机器学习;百度用Hadoop处理每周200TB 的数据,从而进行搜索日志分析和网页数据挖掘工作,等等。
本文介绍的是中国移动某子公司在移动互联网支付系统建设中(简称移动支付系统),成功运用Hadoop技术的典型案例。
一、Hadoop是什么
Hadoop是一个由Apache基金会所支持的用Java实现的开源分布式数据和计算框架,在由大量计算机组成的集群中实现了对海量数据进行分布式计算。允许用户在不了解底层细节的情况下,使用分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop框架的核心,是HDFS和MapReduce。HDFS为海量数据提供存储,MapReduce为海量数据提供计算。
1.1 HDFS简介
整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储支持,。
HDFS采用主从(Master/Slave)结构模型,由一个NameNode和若干DataNode组成的。存储在 HDFS 中的文件被分成块,然后将这些块分散到多个DataNode中。NameNode负责管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。
1.2 MapReduce简介
MapReduce框架由一个JobTracker(调度引擎)和多个TaskTracker(任务引擎)共同组成。JobTracker负责调度构成一个作业的所有任务,这些任务被分发到空闲的TaskTracker上执行。当一个作业被提交时,JobTracker接收作业内容和配置信息,然后生成Map和Reduce任务指派给空闲的TaskTracker执行,同时监视它们的执行情况,并重新分派失败的任务。即如果TaskTracker出了故障,JobTracker会把任务转交给另一个空闲的TaskTracker重新运行。
1.3 HDFS与MapReduce的结合
HDFS和MapReduce共同组成Hadoop分布式系统体系结构的核心。HDFS实现了分布式文件系统,MapReduce实现了分布式计算处理。HDFS在MapReduce任务处理过程中提供了存储支持,MapReduce在HDFS的基础上实现了任务的分发、、执行跟踪等工作,二者相互作用,完成分布式集群的不同作业。
二、移动支付业务
移动支付也称为手机支付,就是允许用户使用其移动终端(通常是手机)对所消费的商品或服务进行账务支付的一种服务方式。单位或个人通过移动设备、互联网或者近距离传感直接或间接向银行金融机构发送支付指令产生货币支付与资金转移行为,从而实现移动支付功能。移动支付将终端设备、互联网、应用提供商以及金融机构相融合,为用户提供货币支付、缴费等金融业务。
2.1 中国移动支付业务
本文介绍的移动支付系统是中国移动集团公司为了解决银行缴费分省接入模式下网络成本高、佣金成本高、运营成本高、用户体验不一致等问题,构建的集中运营、全网覆盖的统一支付体系。
移动支付系统通过移动总部系统和银行系统采用一点接入,完成总部(包括31个省公司)与全国性商业银行开展移动总部对银行总部的缴费服务合作,实现了客户缴纳手机话费和营销活动费用的服务。后期,系统持续推进集中充值和支付能力建设,实现了分散向集中转型、费率和能力双统一。增加支持电子渠道缴费业务,支持电子充值营销推广。最大的亮点是对外提供了缴费能力平台,实现了与天猫、移动商城的缴费合作,提供第三方支付能力的接入。系统建设示意图如图1所示。Hadoop技术,正是在此移动支付中实施应用的。
三、Hadoop技术在移动支付中的应用
移动支付系统提供了实时在线缴费和离线对账结算两部分。实时在线缴费负责完成实时缴费交易的处理,主要以HTTP即时请求的方式出现。离线对账结算主要负责完成多方之间各类交易数据的每日对账、定时结算、资金清分等,主要以文件批处理的形式出现。前文所提及的Hadoop应用主要体现在离线对账结算功能中。
3.1 离线对账结算架构方案
1)集群包括HDFS、MapReduce、YARN、Zookeeper和Hive。
2)集群通过JAVA接口访问,包括对HDFS和Hive的基本操作。
3)各方对账的底层就是文件的比对,两方文件比对作为一个业务插件通过公共接口访问操作集群。
4)对账结算流程支持:
a.在HIVE中建立三张按省、日期进行分区的表,分别用于存放源比对数据、目标比对数据和双方的差异数据
b.每次对账开始先将源和目标的比对文件上传到HDFS上
c.对账业务插件将HDFS文件以Hive表的形式加载
d.通过程序调用执行比对的业务逻辑sql,将差异数据形成差异表
e.差异生成组件再读差异表对应的HDFS文件;
f.将数据导出到现有的数据库中以备后续的处理访问。
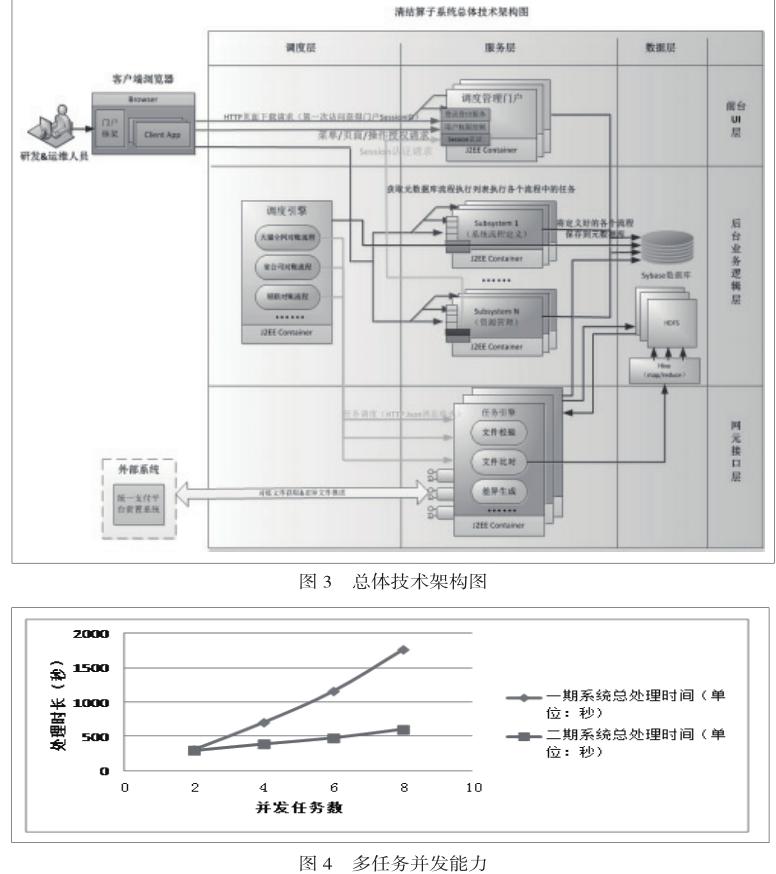
3.2 总体技术图(图3)
总体技术图分为三部分:
1)调度管理子系统:自主研发的管理系统WEBX,提供任务流程的定义,实现调度管理系统功能。
2)调度引擎子系统:实现获取调度管理定义的元数据,并行运行各个任务流程,根据每个任务流程中的任务节点信息,分发给任务引擎执行调度的分发工作。
3)任务引擎子系统:实现对各种原子任务形成组件形成统一管理,对外开放统一接口来获取调度引擎信息,通过key-value方式动态调用实际任务组件,实现任务的执行。
从数据的流向看,划分为调度层、服务层和数据层:
1)调度层:读取元数据信息,启动流程任务调度,分发给任务引擎处理。主要使用调度引擎实现各个流程的调度,核心的消息状态触发以及监听机制采用YARN实现。
2)服务层:调度管理系统来搜集定义以及管理各个任务流程元数据信息,使用任务引擎提供实际任务的执行服务。主要采用任务引擎以及调度管理系统实现,对任务的各个组件采用原子化的方式管理,满足原子任务拼装定义成复杂流程。其核心组件主要有:业务到达、文件备份、文件校验、文件入库、文件比对、差异生成等组件。
3)数据层:主要由Sybase以及HDFS组成,负责业务数据和文件的存储
在功能层次上,划分为前台UI层、后台逻辑层和网元接口层:
1)前台UI层:前台UI层负责向用户展示UI界面,所有的用户请求都通过apache前置机分发给后台逻辑层。
2)后台逻辑层:后台逻辑层物理上由N个子系统组成, apache前置机负责将用户的功能请求分发到不同的子系统上。
3)网元接口层:网元接口层负责获取以及推送对外网元的相关接口数据。
四、性能表现
使用了Hadoop技术以后,相对于未使用hadoop的一期系统,性能有了多方面不同程度的提升。为了方便比对,我们在两个系统上各自运行测试任务,将两个100万记录的文件进行逐行比对,并分别生成相同数据记录与有差异的数据记录。以下是一系列性能测试的结果,我们将其总结为图表。
4.1 任务并发性能显著增强
通过测试,我们发现由于一期系统采用数据库进行任务处理,其处理效率取决于oracle数据库的处理性能。因此,当数据库满负荷的情况下,其任务处理时间基本近似于任务的串行处理时间。且数据库是一个不易于扩展的节点资源,因此暂时认为其不适合处理并发多任务。
而二期系统由于采用多节点的Hadoop组织方式,因此任务分被分配到各个空闲节点上执行,同时,在Hadoop组织方式下,处理节点是一个易于扩展的资源,因此,二期系统的并发处理能力要强 于一期系统。
4.2 具备线性扩展能力
从上表中可以看出,两个系统相比,在少量任务的处理能力上,并没有明显的差距。但使用了Hadoop平台的统一支付二期系统在多任务并发的场景下,其任务处理时间是一条增长更为平缓的曲线。因此,可以认为使用了Hadoop平台,也充分继承了其线性扩展能力的特点。
4.3 具备大文件处理 能力
这也是使用Hadoop平台带来的一个优势。
在一期系统中,正常情况下系统无法处理超大文件,需要 对文件进行分片,即分割为100MB大小的多个记录文件。当内容记录较多时,会产生一大堆从001到999编号的文件,记录 出错概率大,运维管理难度高。Hadoop平台天生对大文件有良好的支持,最新版本的Hadoop平台在存储时自动将大文件以128M大小的分片进行存放。因此,从应用视角,只需要操作一个文件,不必担心其大小超过限制。这也为开发、测试、运维工作带来了诸多多便利。
五、结束语
经过不断调优和持续改进,历时一年的不懈努力,二期系统终于在去年年底顺利上线并投入运营。在该系统中,项目团队首次采用了Hadoop云计算技术,提升了系统并行处理能力,不仅满足了移动支付多样化及第三方支付平台接入的需要,系统吞吐量及健壮性也得到了极大的提高,满足了互联网时代大数据处理需求。
参 考 文 献
[1]中国移动通信集团公司. 中国移动统一支付系统二期工程需求. 2014-03
[2]中国移动通信集团公司. 中国移动统一支付系统技术方案. 2014-04
[3]中国移动通信集团公司. 中国移动统一支付系统二期架构设计. 2014-06
[4]告诉你Hadoop是什么 .中国大数据. 2014-06.http://www.thebigdata.cn/Hadoop/10722.html
[5]详解Hadoop核心架构 .中国大数据. 2014-07.http://www.thebigdata.cn/Hadoop/10973.html
[6]为什么hadoop对你大数据处理的意义重大.中国大数据. 2014-03.http://www.thebigdata.cn/Hadoop/9064.html
[7]移动支付的五种技术.价值中国. 2013-04. http://www.chinavalue.net/BookInfo/Comment.aspx?CommentID=48215
[8]陆嘉恒. Hadoop在百度中的应用. 脚本百事通. http://www.csdn123.com/html/itweb/20130916/120496_120504_120501.htm
