SBHCF:基于奇异值分解的混合协同过滤推荐算法
2016-02-29苏凡军唐启桂
苏凡军,唐启桂
(上海理工大学 光电信息与计算机工程学院,上海 200000)
SBHCF:基于奇异值分解的混合协同过滤推荐算法
苏凡军,唐启桂
(上海理工大学 光电信息与计算机工程学院,上海200000)
摘要针对传统协同过滤中的最近邻查找不够合理导致推荐的准确率较低的困境。提出一个基于矩阵分解的混合相似度算法。该方法融合了基于模型的奇异值矩阵分解算法和基于近邻的协同过滤算法皮尔逊相关系数,并引入阈值和杰卡德系数对相似度进行修正。在公共有效数据集上的实验表明,所提出算法的平均绝对误差比传统的推荐算法至少降低了7.7%,有效提高了推荐准确率。
关键词协同过滤;奇异值矩阵分解;杰卡德系数;皮尔逊系数
SU Fanjun,TANG Qigui
(School of Optical-Electrical and Computer Engineering,University of Shanghai for
Science and Technology,Shanghai 200000,China)
AbstractThe traditional CF recommendation algorithms are poor in accuracy because of its irrational neighbor-retrieve.In this paper,an SVD-based hybrid collaborative filtering algorithm is proposed to solve the challenge.The method combines SVD model-based CF algorithm and PCC memory-based CF algorithm.Several parameters and JACCARD are introduced to revise the similarity.The experiment in the public data set proves that the SBHCF algorithm effectively improves the recommendation accuracy with a reduced MAE by at least 7.7% than the traditional CF algorithm.
Keywordscollaborative filtering;singular value matrix factorization;Jaccard coefficient;Pearson coefficient
大数据时代的用户数目和物品数目增长至高维状态,实际应用过程中用户的评分数据又相当稀疏,这使得单纯从数据集和中度量用户相似性的准确率不高,进而导致推荐的准确率低下和用户体验性差[1-2]。为应对这个挑战,研究者进行了大量研究[3-6]。尽管这些工作有了较大成果,但依然存在不足,文献[3]和文献[4]主要的思想是基于邻域的协同过滤,在数据集中直接寻找相似用户,效率相对低下;文献[5]和文献[6]主要是基于模型的协同过滤,性能和扩展性好,能有效解决评分稀疏性问题,然而基于模型的协同过滤使用低阶矩阵近似原矩阵有一定数据消耗,准确率不高;更重要的是,上述方法没有考虑到有些目标用户其实没有相似用户,若一个用户并没有相似用户,算法也会产生这个目标用户的相似用户,这实际是降低了推荐的准确率。
基于以上分析,提出一个基于奇异值分解的混合协同过滤算法SBHCF(Svd-Based Hybird Collaborative Filiting)。算法主要特点是集成了基于记忆的协同过滤算法(Memory-Based CF)和基于模型的协同过滤算法(Model-Based CF)的优点,大幅缩小了相似用户的查找范围,并引入一系列参数修正用户相似度和物品相似度,考虑了用户评分项相对较少和没有相似用户的情况。当某个缺失值找不到相似用户或相似物品时,并不努力生成一个预测值而是将其置0。相比给用户推荐无需物品而言,这样的策略使得用户体验性会更好。
1SBHCF算法框架和具体实现
SBHCF算法具体可分为3个步骤:第一步是聚类,通过矩阵分解将相关用户聚为同类;第二步通过引入阈值在相关用户子群中度量用户相似度;第三步是聚合相似用户评分,为更好地提高准确率,引入参数混合了相似用户评分和相似物品的评分来预测目标用户缺失值。算法架构如图1所示。

图1 SBHCF算法框架图
1.1 SVD聚类
一个具有m个用户和n个项目的推荐系统可看做一个m×n的矩阵,SVD算法的目的是根据用户的评分数据将高维数据投射从而将兴趣相关的用户聚合在一起[7]。分解的思想为:对于任意矩阵A∈Fm×n,rank(A)=r,可进行如下的矩阵分解,模型如下

(1)
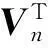
1.2 改进杰卡德的基于用户的协同过滤
通过SVD矩阵分解,文中可将相同兴趣的相关用户置于一个子用户群中,在此群中找相似用户。基于用户(User-based)的协同过滤是当前流行的用户相似度计算方法,公式如下
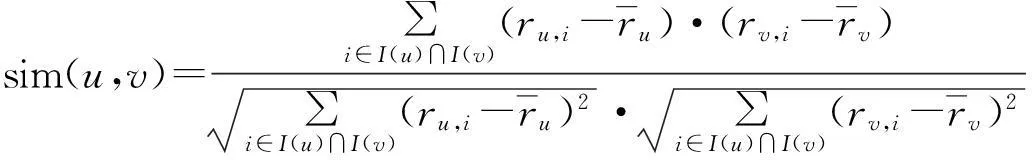
(2)
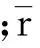
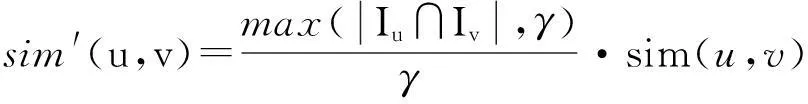
(3)
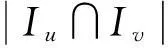
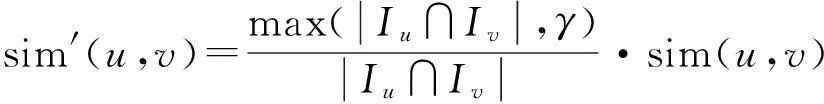
(4)
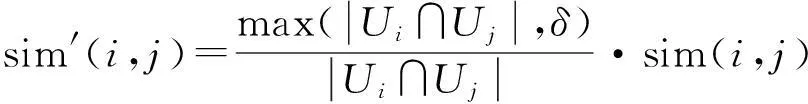
(5)

1.3 混合协同过滤求缺失值
在以上的两个步骤的基础上引入参数来提高平滑预测缺失值的准确率。引入参数η来判断这一相似用户的相似度是否满足要求,若不满足,就认为这一用户不是目标用户的相似用户。引入参数θ来判断是此物品和目标物品是否有足够的相似度,当计算出的相似度低于阈值,则认为此物品和目标物品不相似。
对于缺失评分ru,i,用户u的相似用户应满足

(6)
式中,sim′(ua,u)可通过式(4)计算得出。同样,物品i的相似物品也应满足式(7)才被认为是相似物品

(7)
从实际角度出发,基于用户的协同过滤通过用户的主观打分来预测相似,用户评分的随意性有时会导致出不一致结果,基于物品的协同过滤通过物品的评分来预测相似度,若item是热门物品,其评分基本较高,这些评分较高的物品却不能表达出用户对其的喜爱。因此,预测评分值仅用基于物品的协同过滤或只用基于用户的协同过滤都会忽略一些信息从而导致预测不够准确,综合以上情况合并基于用户的协同过滤和的基于物品的混合协同过滤能有效提高推荐效果。

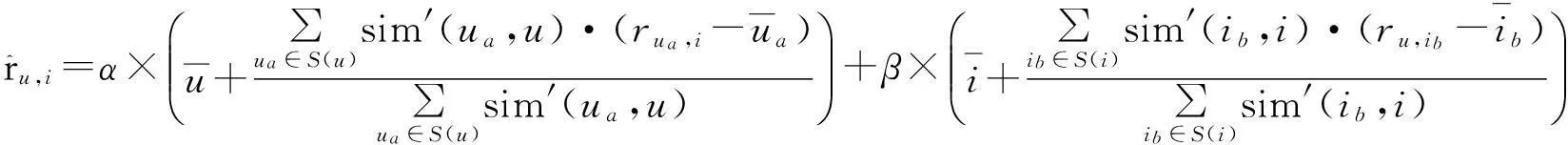
(8)
α和β是两个引入的参数,α+β=1,参数取值范围为[0 1],这两个参数决定了混合算法对基于主观的User-basedCF和基于客观的Item-basedCF有多大程度的依赖。α取值为1时,混合协同过滤算法蜕化为User-basedCF算法;β取1时,混合协同过滤蜕化为Item-basedCF算法。这是因为在实际中,一些用户没有相似用户,即相似度低于规定的阈值,以往算法忽视了这一问题,还是选择了Topn个相似用户,再根据这些相似用户去预测缺失的值,这将大幅削弱预测的精确度。为能更加准确地预测缺失数据,当用户没有相似用户时,文中采用Item-basedCF算法来计算缺失评分值。

(9)
若item找不到与其相似的物品,文中用User-basedCF的算法来计算缺失评分值。
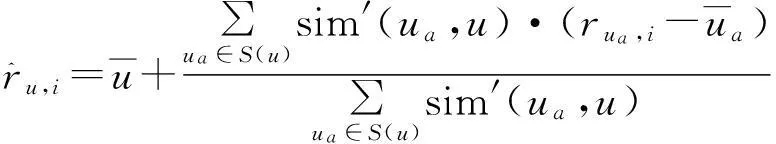
(10)
若相似用户和相似物品均未找到,则对于这样的缺失评分将不予评测,将其置0。
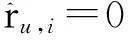
(11)
2阈值和参数讨论
在文中共引入了4个阈值和2个参数,γ和δ是引入的阈值,防止用户和物品在样本较少时出现过拟合,但阈值设置过低,过拟合无法消除,引入过高会导致所有的相似用户或相似物品都要乘以权重系数,所以在不同的数据集里参数的设定要参考实际情况。
η和θ也是重要的阈值,设定过高会导致众多缺失数据不用去预测,设定的太低会造成几乎缺失数据均需要预测,当η为1和θ为1的情况下,这一算法就不用去预测缺失数据,直接是最基本的协同过滤。当η为0和θ为0的情况下,算法预测所有数据,算法收敛为TopN邻域选择算法。在文中,为了不让实验复杂化,将η和θ取相同值。
最终的参数为α和β,其决定算法依靠用户信息或是物品信息的程度。
3实验
3.1 实验数据集
实验的数据集选用MovieLens,这是推荐系统中著名的数据集,数据集合包含了943个用户对1 682部电影评分(分数为1~5级)的情况,评分记录约有100 000,可得出数据集的密度为
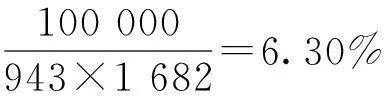
(12)
从数据集中抽取500用户来进行实验,300用户用来训练,200用户来做预测。
3.2 评定准则
文章使用平均绝对差(MeanAbsoluteError,MAE)去度量算法的预测质量。MAE的计算公式如下
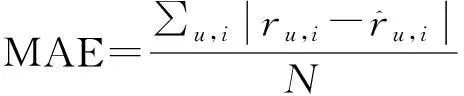
(13)

3.3 实验设置
使用五折交叉验证来对数据集进行实验,在每一折实验中,针对训练集中的评分数据,对测试集中的评分数据进行预测。通过比值,得出每一折的预测精度,而最终的MAE预测精度是五折的平均值。
3.4 参数影响
因为α和β是线性关系,文中只讨论α的情况,将α以步长0.2从0递增到1来计算α对算法预测的影响。在实验中,将阈值取值分别为γ=30,δ=30,η=0.5,θ=0.5,选择相似用户为5、10和15来计算SBHCF的MAE值。
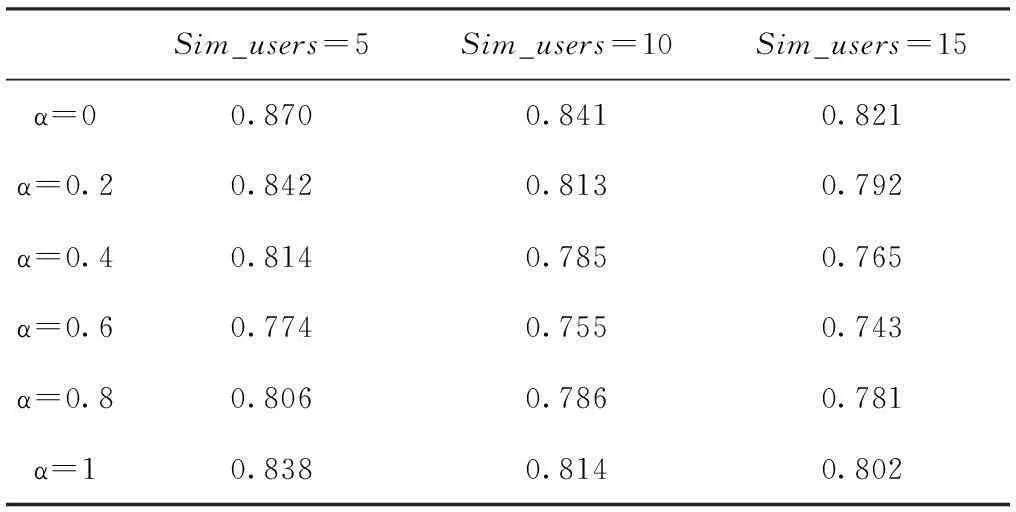
表1 随α取值变化的MAE值
从图2中可看到,随着参数α的逐渐增大,MAE值随之减小,算法的性能类似于线性递增,当大约α=0.6时,算法的性能最佳,此时当参数α再增大时,性能递减。
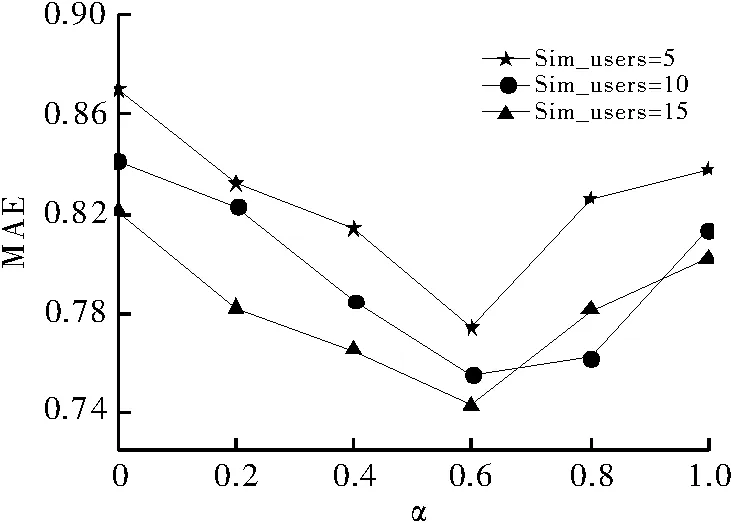
图2 参数α取值对MAE的影响
3.5 阈值设置和性能对比
为验证算法的有效性,将其与传统的协同过滤算法SVD和混合协同过滤HCF以及基于用户的协同过滤UCF进行了对比。在实验中,将阈值设置为γ=30,δ=30,η=0.5,θ=0.5,α=0.6,并分别选择相似用户数分别为5、10、15、20和30来比较这些算法的性能。
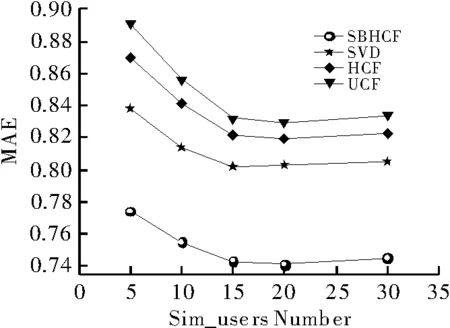
图3 在不同相似用户下算法的MAE值
从图3中可看到,SBHCF算法比传统的相似度算法SVD、HCF和UCF的平均绝对误差低,在相似用户为20时,SBHF和最强竞争力的SVD相比,MAE值比SVD降低了7.7%;同UCF相比,MAE值降低了10.7%。当相似用户递增时,MAE的值是递减的,代表随着相似用户越多预测的数据越和真实数据相符。但不是相似用户越多越好,当相似用户到25以上时,可看到MAE不减反增,证明有不太相似的用户加入了相似用户队列造成预测率降低。
4结束语
文章提出了一个有效的预测缺失数据的推荐算法,使用矩阵分解模型将用户分为不同子群,引入参数找到相似用户集合和相似物品集合,线性加权了基于主观的User-basedCF算法和基于客观的Item-basedCF算法,并将其合并。这样传统的协同过滤算法实际是文中算法的特例,算法根据设定的阈值决定了是否去预测一个缺失记录增强了预测的准确率,通过实验证明,SBHCF算法优于传统的协同过滤算法。
参考文献
[1]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[2]AdomaviciusG,TuzhilinA.Towardthenextgenerationofrecommendersystems:Asurveyofthestate-of-the-artandpossibleextensions[J].IEEETransactionsonKnowledgeandDataEngineering,2005,17(6):734-749.
[3]张光卫,李德毅,李鹏,等.基于云模型的协同过滤推荐算法[J].软件学报,2007,18(10):2403-2411.
[4]黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[5]ChoiK,SuhY.Anewsimilarityfunctionforselectingneighborsforeachtargetitemincollaborativefiltering[J].Knowledge-BasedSystems,2013,37(2):146-153.
[6]XueGR,LinC,YangQ,etal.Scalablecollaborativefilteringusingcluster-basedsmoothing[C].Lanzhou:Proceedingsofthe28thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval,2005.
[7]方耀宁,郭云飞,丁雪涛,等.一种基于局部结构的改进奇异值分解推荐算法[J].电子与信息学报,2013(6):1284-1289.
[8]HerlockerJL,KonstanJA,TerveenLG,etal.Evaluatingcollaborativefilteringrecommendersystems[J].ACMTransactionsonInformationSystems,2004,22(1):5-53.
[9]LiuQ,ChenE,XiongH,etal.Acocktailapproachfortravelpackagerecommendation[J].IEEETransactionsonKnowledgeandDataEngineering,2014,26(2):278-293.
[10]GeY,XiongH,TuzhilinA,etal.Cost-awarecollaborativefilteringfortraveltourrecommendations[J].ACMTransactionsonInformationSystems,2014,32(1):4-10.
[11]HuangZ,ChenH,ZengD.Applyingassociativeretrievaltechniquestoalleviatethesparsityproblemincollaborativefiltering[J].ACMTransactionsonInformationSystems,2004,22(1):116-142.
通信作者:唐启桂(1977—),女,硕士研究生。研究方向:推荐系统和服务计算。
作者简介:苏凡军(1976—),男,博士,讲师。研究方向:网络智能与服务质量。
基金项目:上海智能家居大规模物联共性技术工程中心基金资助项目(GCZX14014);沪江基金研究基地专项基金资助项目(C14001);广西可信软件重点实验室开放课题基金资助项目(KX201415)
收稿日期:2015- 06- 05
中图分类号TP306.1
文献标识码A
文章编号1007-7820(2016)01-044-04
doi:10.16180/j.cnki.issn1007-7820.2016.01.012
SBHCF:An SVD-based Hybrid Collaborative Filtering Recommendation Algorithm
