基于LDA模型和多层聚类的微博话题检测
2016-02-27刘红兵李文坤张仰森
刘红兵,李文坤,张仰森
(1.太原科技大学 电子信息学院,山西 太原 030024;2.北京信息科技大学 智能信息处理研究所,北京 100192)
基于LDA模型和多层聚类的微博话题检测
刘红兵1,李文坤2,张仰森2
(1.太原科技大学 电子信息学院,山西 太原 030024;2.北京信息科技大学 智能信息处理研究所,北京 100192)
随着微博这一新兴社交媒体的广泛应用,以微博为背景的相关研究不断涌现,其中基于微博的话题检测是当前研究的热点之一。结合微博文本的相关特点,文中提出了一种基于LDA模型和多层聚类的微博话题检测方法。首先,通过LDA模型对微博数据建模并提取特征;其次,利用改进的Single-Pass聚类和层次聚类对微博数据进行聚类,从而发现热点话题。通过在大规模微博数据上进行话题检测实验,通过LDA建模比通过TF-IDF进行特征选择和权重计算效果好;改进的Single-Pass聚类能够处理第一遍Single-Pass聚类未处理的微博,提高了初步聚类的精度,并且为下一步层次聚类减少了时间;多层聚类的聚类效果在准确率、召回率和F值三方面均比单一聚类算法的聚类效果好。显然,文中的话题检测方法是可行的,也是有效的。
LDA模型;话题检测;改进的Single-Pass聚类;层次聚类
0 引 言
随着互联网技术的发展及其广泛的应用,包括微博、社交网站、即时通讯等在内的一些新兴社交媒体正在从根本上改变着人们的生活。据中国互联网信息中心(CNNIC)发布的《第34次中国互联网络发展状况统计报告》[1]显示:截至2014年6月底,我国网民规模达6.32亿,较2013年底增加了1 442万人。然而,微博网民规模为2.75亿,占所有网民的43.6%。微博已经成为人们在线交流和传播信息的主要平台,已经成为社会舆情传播的重要载体,一些重要的热点事件或商业信息都首先通过微博进行报道。微博上的热点话题一般来源于突发事件的报道、具有重要新闻价值的信息或者引起讨论、共鸣甚至争论的用户交流,很大程度上反映着当前社会的舆论方向。对这些话题进行实时检测可以帮助用户快速了解目前的热点话题、热门事件,也能够帮助政府及时了解社会动态、知道民众的想法。随着微博的进一步发展和日益普及,开展微博平台上的话题检测技术研究迫在眉睫。
1 研究现状
近年来,有关微博的研究受到了学术界和企业界的广泛关注,针对微博的研究也越来越多。同时,微博话题检测也有了相应的进展。
Peng等[2]总结了热门话题的特征,提出了一种基于用户喜好的热门话题检测方法。Ramage等[3]分析了Twitter数据的特征,利用Labeled LDA模型进行特征提取,并实现了Twitter排序和推荐功能。Du等[4]通过PangRank算法抽取出关键用户,然后结合语义信息提取突发特征,进而发现微博中的突发事件。孙励[5]采用LDA模型发现微博热点话题,并用主题代表话题。此方法虽然能够解决微博数据稀疏问题,但是话题检测性能有待提高。邱洋[6]分析了微博的特点,在计算相似度时融入了语义和时间参数,然后采用Single-Pass算法进行话题检测。路荣等[7]利用隐语义分析解决微博短文本数据稀疏问题,然后选取每个时间窗内最有可能是谈论新闻话题的微博,最后采用K-means和层次聚类进行微博热点话题检测。孙胜平[8]采用SP&HA混合聚类发现微博中的话题,并通过实验验证了该方法的有效性。马雯雯等[9]首先采用隐语义分析(LSA)对微博数据建模,然后利用层次聚类的CURE算法确定K-means的初始类,最后通过K-means算法发现微博话题。蒋洪梅[10]对微博的舆论影响特点进行了具体论述,并对如何更好地利用微博进行舆论引导作了尝试性的探讨。彭泽映等[11]通过观察和分析发现基于微博的大规模短文本所具有的“长尾分布”的特性,提出了一种基于不完全聚类思想用以对这类数据进行聚类分析,一定程度上解决了传统聚类算法难以对大规模短文本进行有效处理的问题。马彬等[12]提出了一种基于线索树双层聚类的微博话题检测方法。首先建立微博线索树,然后在线索树内部进行局部聚类,最后进行全局聚类发现微博话题。史剑虹等[13]通过隐主题分析挖掘微博中的隐含主题信息,然后采用聚类算法和频繁项集挖掘技术进行微博话题检测并提取话题关键词集。
在前人研究的基础上,文中提出了一种新的基于LDA模型和多层聚类的微博话题检测方法。通过LDA模型挖掘微博文本中潜在的主题信息,解决微博数据的数据稀疏问题,同时采用融合改进的Single-Pass聚类算法和层次聚类算法进行微博话题检测。实验结果表明,该方法能够从大规模微博语料中准确地检测出当前的热点话题。
2 关键技术
2.1 LDA模型
LDA模型[14]首先由Blei等于2003年提出,是现今最流行的一种文档主题生成模型。LDA模型适于对文本进行“隐性语义分析”,可以用来识别大规模文档集或语料库中潜藏的主题信息,目的是将文档集或语料库中的每篇文档的主题按照概率分布的形式给出。而且它也是一种无监督的学习算法,不需要任何关于文档的背景知识和已标注的训练语料。
LDA模型也是一个三层贝叶斯概率模型,包含词、主题和文档三层结构。其中,文档到主题服从Dirichlet分布,主题到词服从多项式分布。它采用产生式全概率模型对文档进行建模,对于给定的一个文档集,LDA将每一篇文档用若干主题的概率表示,将每个主题用所有的词的概率表示。每篇文档的主题都服从特定的分布,主题之间也相互独立,并且被所有文档共享。LDA模型生成文档的过程如图1所示。
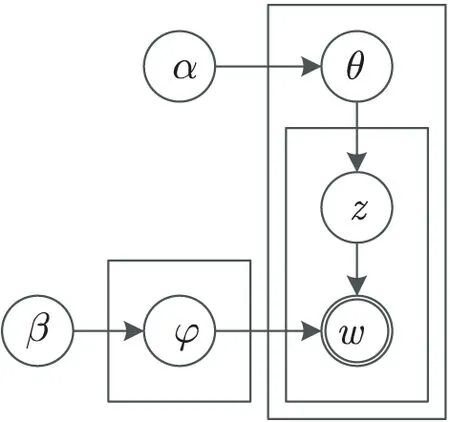
图1 LDA模型
图中,θ,φ,z都是隐藏变量,w是可见变量,方框中的内容表示循环执行。α是每篇文档下主题的多项式分布的Dirichlet先验参数,β是每个主题下词的多项式分布的Dirichlet先验参数,θ表示该文档的主题分布,φ表示该主题的词分布,z表示每篇文档分配在每个词上的主题,w表示每篇文档的词向量。概率生成模型的计算公式如式(1)所示。
LDA模型中隐藏参数的估计也称为LDA的Infernce问题,通常采用EM算法和吉布斯采样(GibbsSampling)进行学习估计。Gibbs采样是由ThomasL.Griffith等人提出的,它是MCMC的一个二维实现方法,比较适合大规模数据的处理,是目前最流行的参数估计算法。这个算法的运行方式是每次选取概率向量的一个维度,给定其他维度的变量值Sample当前维度的值。不断迭代,直到收敛输出待估计的参数。文中也采用Gibbs采样对LDA模型的参数进行估计。LDA模型对文档集建模的最终结果如下:
(1)z文件,它的每一行表示原始文档集中的一个文档。它把所有的词用该词所对应的隐主题替换,然后用这些隐主题表示文档。
(2)phi文件,即文档-主题矩阵M*K。M表示文档集中的文档数,K表示主题数。
(3)theta文件,即主题-词矩阵K*V。K表示主题数,V表示文档集中词的个数。
(4)twords文件,它将所有的主题用概率最高的那些特定的词表示,显示每个主题的具体内容。
传统LDA模型中,V指文档集中所有不相同的词的个数,但是,对于话题检测来说并不是所有的词都有实际的语义。正如副词、介词、连词、助词、叹词和拟声词等,这些词都依附于实词,没有具体的语义,对话题检测没有作用,而且影响系统的性能。文中采用LDA建模时,对传统LDA模型中V的选择进行改进,只保留名词、动词、形容词。这样做不仅能提高LDA模型的性能,而且能降低建模时间。
2.2 多层聚类
2.2.1 Single-Pass聚类
Single-Pass聚类[8]是单遍聚类,属于增量式聚类算法中的一种。Single-Pass聚类算法的基本思想是:按照文档输入的顺序依次处理每个文档,把第一个文档认为是第一个话题,后续输入的每个文档都与之前创建的话题进行相似度计算,并找出与该文档相似度最大的那个话题,如果相似度大于阈值,那么将该文档归入此话题并更新话题簇,否则用该文档创建一个新话题,一直循环此过程,直到所有文档处理完毕,算法结束。
Single-Pass算法的优点是算法逻辑简单,执行效率较高,而且该算法对输入文档的顺序敏感,比较适合微博话题检测。
文中在传统Single-Pass聚类的基础上进行改进,得到一个适合于微博话题检测的聚类算法,具体内容详见第三节。
2.2.2 凝聚式层次聚类
层次聚类也是一种常用的聚类算法,分为分裂式层次聚类和凝聚式层次聚类。分裂式层次聚类是自顶向下的层次聚类,凝聚式层次聚类是自底向上的层次聚类。凝聚式层次聚类非常适合话题检测,其运用到话题检测的思想是:把每一个文档当作初始的类簇,然后计算各个类簇之间的相似度并找出最大相似度和相应的类簇,如果该值大于预定的阈值,那么将这两个类簇合并并更新簇的中心,通过不断的合并与更新得到最终的话题簇。凝聚式层次聚类能够较准确地对微博话题进行检测,但是凝聚式层次聚类每次合并都要计算簇之间的相似度,算法时间复杂度是O(n3),对于大规模数据集凝聚式层次聚类很难在短时间内完成。
3 基于LDA模型和多层聚类的微博话题检测
3.1 微博语料预处理
由于刚抓取的微博含有大量噪声,因此需要对微博语料进行预处理。通过对微博语料的观察分析,发现许多微博文本中含有大量的繁体字和链接。如果对这些繁体字和链接不做处理,那么将会对LDA模型的训练以及聚类产生很大的影响。文中利用现有的繁简体字对照表对微博文本进行处理,消除繁体字,同时删除微博中所有的链接,使微博文本规范化。
此外,语料中含有大量的重复微博和字数过少的微博。例如,“转发微博”,这类微博不仅对话题检测毫无意义,而且会影响系统性能。因此,去掉重复微博和字数过少的微博也是至关重要的。
微博用户在转发互动中形成的微博大都具有语义相关性,通常是对同一个话题的讨论。对于具有转发关系的微博文本,把原创微博与转发微博进行合并,形成一个语义更加丰富的长文本来替换原始微博,解决微博话题检测的数据稀疏问题。
3.2 改进的Single-Pass聚类
传统的Single-Pass聚类只使用一次循环遍历所有微博,完成聚类。事实上,有很多微博虽然属于某一个话题,但是由于它发布时间较早,较早完成遍历,这样可能导致这些微博因为与之前得到的话题的相似度略低于阈值而被重新创建了新的话题,从而影响了聚类效果。
算法1:改进的Single-Pass聚类算法。
输入:按时间顺序排好序的微博集D={d1,d2,…,dn}
输出:话题簇T1,T2,…
Forcountfrom1ton
if(count==1)then
d[count]->T1//创建新话题T1
else
maxSim=0
forifrom1to已经创建的话题数
if(sim(d[count],T[i])>maxSim)then
maxSim=sim(d[count],T[i])
clusterNo=i
endif
endfor
if(maxSim>=阈值)then
d[count]->T[clusterNo] //归入话题
updateandsaveT[clusterNo]
endif
endif
Endfor
Forcountfrom1to没有归入话题的微博数
maxSim=0
forifrom1to已经创建的话题数
if(sim(d[count],T[i])>maxSim)then
maxSim=sim(d[count],T[i])
clusterNo=i
endif
endfor
if(maxSim>=阈值)then
d[count]->T[clusterNo] //归入话题
updateandsaveT[clusterNo]
else
createnewtopic
endif
Endfor
文中提出了一种新的改进的Single-Pass聚类。该算法在传统Single-Pass聚类的基础上,处理了那些漏掉的微博,使聚类更加准确。对于给定的一个微博集D={d1,d2,…,dn},改进的Single-Pass聚类的算法如算法1所示。
3.3 微博话题检测
文中首先通过LDA模型对微博文本进行建模,提取特征,然后采用多层聚类算法对微博文本聚类实现话题检测。多层聚类分两阶段进行,第一步利用改进的Single-Pass聚类进行话题初步检测,第二步利用层次聚类对上一步产生的中间结果再次聚类形成最终的话题。改进的Single-Pass聚类算法逻辑简单,能够快速处理大规模文本,但是聚类精度一般;凝聚式层次聚类的聚类精度高,但是算法的时间复杂度也较大。
文中利用LDA模型有效解决了微博的数据稀疏问题,同时结合改进的Single-Pass聚类和层次聚类的优点,使话题检测系统在准确率和时间上都有很大提高。
系统流程图如图2所示。
3.4 关键字提取
随着信息时代的到来,每天都有成千上万的信息展现在人们面前,如何快速了解海量信息中谈论的热点话题并且找出自己感兴趣的话题,不论对于个人还是企业,都是十分重要的。文中利用多层聚类算法检测出的微博话题都是以微博簇的形式存在的,每个微博簇都是谈论某一个话题的微博文本集。虽然可以把谈论同一话题的微博聚集到一个话题簇中,但是要想确定该话题簇具体谈论的话题内容,仍然需要一条一条地阅读微博。因此,检测出微博话题是不够的,还需要用三到五个关键字概括出微博话题的主要内容。本节主要介绍关键字提取,即从已检测出的微博话题中,抽取主要的关键字表示该话题。

图2 系统流程图
在关键字提取中,用TF-IDF度量每个词语的重要度。经过多次实验后,最终选择TF-IDF排名前三的词语作为话题关键字。提取过程如下:
(1)将每一个话题中的所有微博作为一个整体,分词,去停用词;
(2)计算第一个话题中去掉停用词后剩下的词语在所有语料中的TF-IDF值;
(3)根据TF-IDF值排序,选择TF-IDF值排名前三的词语作为该话题的关键字;
(4)重复步骤(2)和(3),直到所有话题关键字提取完毕为止。
表1展示了各话题中的部分微博和TF-IDF排名前三的词语。话题一主要以央视曝光星巴克咖啡牟取暴利的行为为背景展开的讨论,抽取出来的话题关键字是“星巴克、咖啡、贵”,这与话题内容基本上吻合。话题二是关于高考改革引发的讨论,主要是关于是否取消英语和数学的讨论,然而抽取出的话题关键字是“英语、数学、高考”,这与话题二的内容也是相吻合的。仔细分析话题三和话题四,话题关键字和微博内容也基本上是吻合的,说明采用TF-IDF提取出的话题关键字基本上可以概括出话题的主要内容,而且效果也是不错的。

表1 微博话题和话题关键字
4 实 验
4.1 实验数据及评价指标
目前,在中文微博话题检测方面还没有统一的微博数据。文中通过网络爬虫,抓取了新浪微博2 352个用户发表于2013年6月1号到2013年10月31号之间的所有微博数据。经过语料去重和噪声微博过滤,剩下的微博数据用于实验。
在自然语言处理领域,常用的评价指标有准确率、召回率和F值。文中除了使用传统的这三个评价指标以外,还采用漏检率和错检率评价文中的微博话题检测系统的性能。
具体的计算公式如下所示:
其中,P表示准确率;D表示话题检测系统正确检测出的属于该话题的微博数;U表示话题检测系统实际检测出的属于该话题的微博数。
其中,R表示召回率;D表示话题检测系统正确检测出的属于该话题的微博数;T表示语料中所有属于该话题的微博数。
其中,F表示F值;P和R分别表示准确率和召回率。
其中,PFA表示错检率;FA表示话题检测系统错误检测出的属于该话题的微博数;NT表示语料中所有不属于该话题的微博数。
其中,PMISS表示漏检率;MD表示话题检测系统没有检测出的属于该话题的微博数;T表示语料中所有属于该话题的微博数。
4.2 对比实验及实验结果分析
实验一:为了验证改进的Single-Pass聚类和凝聚式层次聚类对话题检测的影响,文中设置四个系统,四个系统均采用余弦相似度度量微博之间的相似性,具体设置如下:
sys1:只采用Single-Pass聚类。
sys2:在sys1的基础上融入了层次聚类。
sys3:只采用改进的Single-Pass聚类。
sys4:在sys3的基础上融入了层次聚类。
实验中,分别用TF-IDF和LDA模型进行特征选择,由于采用TF-IDF进行特征选择时,一些话题根本无法检测出来,一些评价指标都无法计算,无法进行准确地比较。采用TF-IDF进行特征选择时,各个系统的话题检测的效果比LDA模型的均较差,所以在此不再赘述。
图3显示了在采用LDA模型进行特征选择的条件下,四种不同的聚类策略进行话题检测的实验结果。

图3 不同聚类算法下话题检测的性能比较
从图中可以看出,在五个评价指标中sys1的性能最差,sys2和sys3的性能居中,sys4的性能优于其他三个系统,说明采用文中提出的方法完全能够满足话题检测的要求。sys2和sys3比sys1在各方面都有所提高,说明层次聚类和改进的Single-Pass聚类都能提高话题检测的性能。sys2在召回率方面优于sys3,但在准确率方面不及sys3,说明层次聚类更侧重于召回率的提高,而改进的Single-Pass聚类更侧重于准确率的提高。其主要原因是由于改进的Single-Pass聚类采用层叠Single-Pass聚类方法,其第二次的Single-Pass聚类建立在第一次Single-Pass聚类基础上,可以有效处理第一次Single-Pass聚类未能处理的微博。而且,层次聚类能够把Single-Pass聚类处理完的微博再次整合,提高话题检测效率。其中,sys2就是文献[8]所采用的聚类算法,由图3可以看出,文中方法与文献[8]的话题检测方法相比,各个指标都有提高,F值提高约12%。
实验二:为了评估不同阈值对话题检测结果的影响,该实验设置不同的阈值进行话题检测,得到的结果如图4所示。
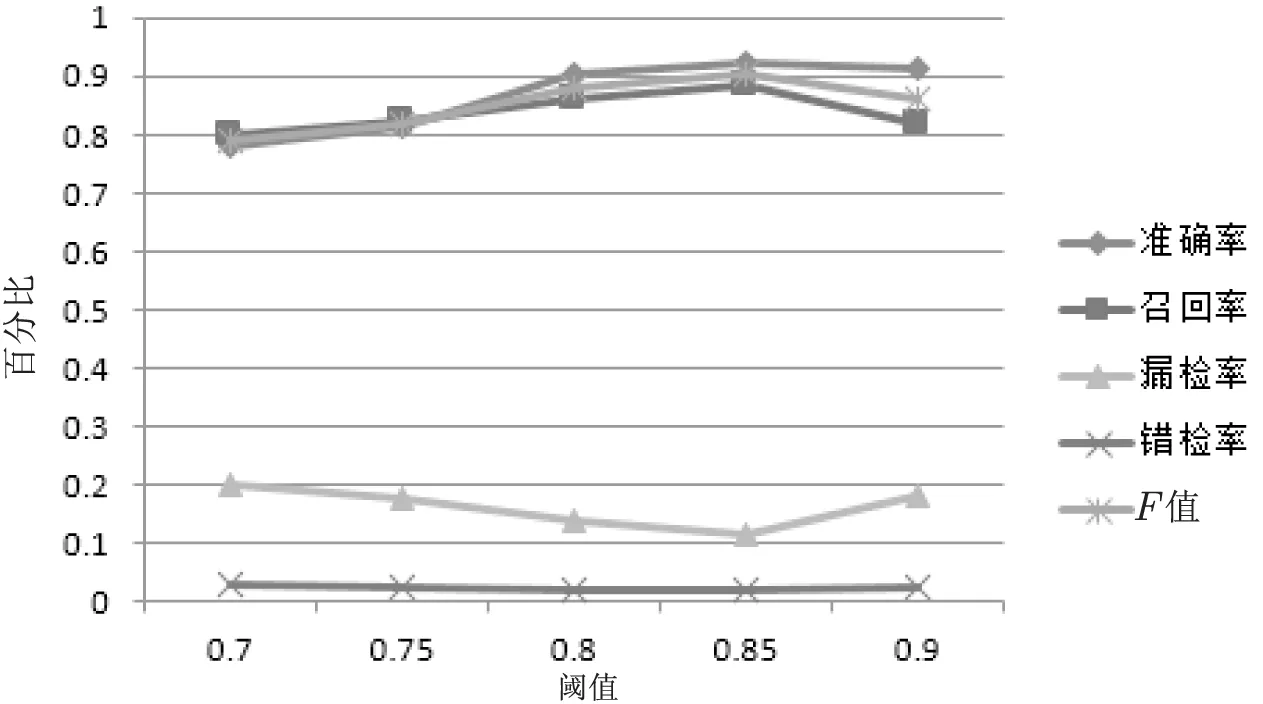
图4 不同阈值话题检测的性能比较
由图4可以看出:随着阈值的不断增大,话题检测的准确率、召回率和F值逐渐增大,话题检测系统的性能持续提高;但是当阈值超过0.85时,这三个指标开始下降,系统性能也开始下降。
5 结束语
文中根据微博内容的简短性、微博话题的时序性以及微博文本之间存在转发关系等特点,提出了一种基于LDA模型和多层聚类的微博话题检测方法。通过合并具有转发关系的微博,以及采用LDA模型选取特征,有效解决了微博短文本的数据稀疏问题。通过融合改进Single-Pass聚类和层次聚类,能够在保证话题检测性能的前提下更大程度地缩短话题检测时间。最后,通过TF-IDF对微博中的词语进行重要度排序,用排名前三的词语作为话题关键字,代表话题的主要内容。
由于微博文本比较随意,口语化较强,网络词语也出现频繁,用现有的分词工具处理微博文本时并不是很理想,导致文中的话题检测性能有所下降。同时,微博文本中会出现大量的同义词,也会影响系统的性能。在下一步的研究中,首先要丰富用户字典,确保分词更加准确;其次要引入同义词字典,处理微博文本中的同义词,进一步提高系统的性能。
[1] 中国互联网络信息中心.中国互联网络发展状况统计报告[R].北京:中国互联网络信息中心,2014.
[2]PengFeifei,QianXu,LiGaoren.Aresearchofhottopicdetectionthroughmicroblogging[C]//Procof4thinternationalconferenceonintelligenthuman-machinesystemsancybernetics.[s.l.]:IEEE,2012.
[3]RamagesD,DumaisS,LieblingD.Characterizingmicroblogswithtopicmodels[C]//ProceedingsofthefourthinternationalAAAIconferenceonweblogsandsocialmedia.Washington,DC:[s.n.],2010.
[4]DuYY,HeYX,TianY.MicroblogBurstytopicdetectionbasedonuserrelationship[C]//Proceedingsofthe2011IEEEjointinternationalinformationtechnologyandartificialintelligenceconference.Piscataway:IEEE,2011:260-263.
[5] 孙 励.基于微博的热点话题发现[D].北京:北京邮电大学,2013.
[6] 邱 洋.微博数据提取及话题检测方法研究[D].大连:大连理工大学,2013.
[7] 路 荣,项 亮,刘明荣,等.基于隐主题分析和文本聚类的微博客中新闻话题的发现[J].模式识别与人工智能,2012,25(3):382-387.
[8] 孙胜平.中文微博客热点话题检测与跟踪技术研究[D].北京:北京交通大学,2011.
[9] 马雯雯,魏文晗,邓一贵.基于隐含语义分析的微博话题发现方法[J].计算机工程与应用,2014,50(1):96-100.
[10] 蒋洪梅.微博客的特点及其舆论影响力[J].新闻爱好者,2011(5):85-86.
[11] 彭泽映,俞晓明,许洪波,等.大规模短文本的不完全聚类[J].中文信息学报,2011,25(1):54-59.
[12] 马 彬,洪 宇,陆剑江,等.基于线索树双层聚类的微博话题检测[J].中文信息学报,2012,26(6):121-128.
[13] 史剑虹,陈兴蜀,王文贤.基于隐主题分析的中文微博话题发现[J].计算机应用研究,2014,31(3):700-704.
[14]BleiM,NgY,JordanI.LatentDirichletallocation[J].JournalofMachineLearningResearch,2003,3(4-5):993-1002.
Microblog Topic Detection Based on LDA Model and Multi-level Clustering
LIU Hong-bing1,LI Wen-kun2,ZHANG Yang-sen2
(1.College of Electronic Information,Taiyuan University of Science and Technology, Taiyuan 030024,China;2.Institute of Intelligence Information Processing,Beijing University of Information Science and Technology,Beijing 100192,China)
With the wide application of microblog,emerging social media,relevant research is being emerged on microblog.The topic detection based on microblog is one of the hotspots in current research.In combination with the relevant characteristics of microblog,a microblog topic detection based on LDA model and hierarchical clustering is proposed.First,LDA model is applied for modeling and feature extraction to microblog data.Then,the improved Single-Pass clustering and hierarchical clustering is used on microblog data clustering and the hot topic is found.Experiment on large-scale corpus shows that it is more effective through the LDA model than by TF-IDF for feature selection and weight calculation;the improved Single-Pass clustering can deal with the untreated microblog by the first Single-Pass clustering,which can improve the accuracy of the initial clustering and reduce the time of hierarchical clustering;it is more effective through the hierarchical clustering than the single clustering in accuracy,recall andF-value.Clearly,itisfeasibleandeffectivebytheLDAmodelandmulti-levelclusteringtodetectthemicroblogtopic.
LDA model;topic detection;improved Single-Pass clustering;hierarchical clustering
2014-11-14
2015-04-08
时间:2016-05-25
国家自然科学基金资助项目(61370139);北京市属高等学校创新团队建设与教师职业发展计划项目(IDHT20130519);北京市教委专项基金(PXM2013_014224_000042,PXM2014_014224_000067)
刘红兵(1968-),男,副教授,研究方向为智能计算机控制。
http://www.cnki.net/kcms/detail/61.1450.TP.20160525.1700.006.html
TP
A
1673-629X(2016)06-0025-06
10.3969/j.issn.1673-629X.2016.06.006
