基于LSTM的发电机组污染物排放预测研究
2016-02-23杨训政柯余洋梁肖熊焰
杨训政, 柯余洋, 梁肖, 熊焰
(1.中国科学技术大学计算机学院,安徽 合肥 230027; 2.安徽省电力公司调度控制中心,安徽 合肥 230022)
基于LSTM的发电机组污染物排放预测研究
杨训政1, 柯余洋1, 梁肖2, 熊焰1
(1.中国科学技术大学计算机学院,安徽 合肥 230027; 2.安徽省电力公司调度控制中心,安徽 合肥 230022)
为了利用电力公司积累的海量历史污染物排放数据,形成可以减少污染物排放的调度框架。采用递归神经网络,结合发电机组输出功率与污染物排放量之间的关系,并使用批规范化等深度学习技术,对数据和模型进行学习和训练。实验结果表明,可以有效预测发电机组污染物排放量,解决传统回归分析方法无法适用的难以提取有效特征的问题。
机器学习;深度学习;递归神经网络;批规范化;回归分析
0 引 言
近年来,随着社会对电力需求的不断增加,与之相关的污染问题也愈加严重。通过对电力公司积累的海量历史污染物排放数据进行研究,以达到减少污染物排放的目的成为新的研究热点。研究者通过使用传统统计学方法、机器学习方法等手段取得了一定的成果。
本文认为之前基于传统方法的方案,没有考虑到实际条件下数据复杂性产生的难以提取有效特征的问题,而深度学习较传统方法具有不依赖高质量特征的优势[1]。预测或回归分析本质上就是曲线的拟合,很多预测方法都是获得与特征相拟合的曲线,如支持向量机回归(SVR)[2]。回归分析在数据研究与机器学习中一直是核心问题[3],然而当特征的维度非常大或难以有效提取高质量特征时,传统的方法就难以获得良好的效果[4]。
针对以上问题,本文首次采用深度学习技术而非传统方法对发电机组污染物排放量预测问题进行研究。通过基于长短期记忆(LSTM)的模型,结合批规范化(Batch Normalization)等深度学习技术,对电力公司积累的海量历史数据进行建模和训练,达到了预测污染物排放量的目的。实验证明基于LSTM的方法可以克服传统回归方法对于特征质量高度依赖的问题,并且通过对模型进行Batch Normalization、timesteps选取等优化,可以显著提高模型的预测精度和训练速度。
1 RNN
RNN是一种强大的深度神经网络,在学习具有长期依赖性的时序数据上效果显著[5],近些年在语音识别[6]、机器翻译[7-8]等领域获得良好的效果。
1.1 Simple-RNN
简单的递归神经网络(RNN)和一般的深度神经网络(DNN)区别在于神经元直接连接的架构不同:DNN的信息从输出层到隐含层到连接层单向流动; RNN的信息传递存在定向的循环,这也与我们大脑的神经元连接结构相符。

图1 RNN网络结构
如图1所示,RNN的隐含层有一条自循环的边,t时刻节点的输出由t时刻的输入与t-1时刻的输出共同决定。假设一个输入序列为(x1,x2,…,xT),序列(h1,h2,…,hT)为隐藏层状态,Wx代表输入层到隐含层的权重,Wh代表隐含层自循环的权重,φ为激活函数。则t时刻有:
ht=φ(Whht-1+WxXt)
(1)
多个递归神经层组合起来可以构建深度递归神经网络结构[8],设l为隐含层层数,则t时刻有:

(2)
1.2 LSTM
普通RNN(Simple-RNN)相当于在时间序列上展开的多层的DNN,这种模型很容易出现梯度消失或梯度爆炸的问题[9]。

图2 LSTM神经元内部结构
长短期记忆(LSTM)网络是一种特殊的RNN。该模型可以学习长期的依赖信息,同时避免梯度消失问题[10]。LSTM在RNN的隐藏层的神经节点中,增加了一种被称为记忆单元(Memory Cell)的结构用来记忆过去的信息,并增加了三种门(Input、Forget、Output)结构来控制历史信息的使用。
如图2所示,设输入序列为(x1,x2,…,xT), 隐藏层状态为(h1,h2,…,hT),则在t时刻有:
it=sigmoid(Whiht-1+WxiXt)
(3)
ft=sigmoid(Whfht-1+WhfXt)
(4)
ct=ftct-1+ittanh(Whcht-1+WxcXt)
(5)
ot=sigmoid(Whoht-1+WhxXt+Wcoct)
(6)
ht=ottanh (ct)
(7)
其中it、ft、ot代表 input门、forget门和output门,ct代表cell单元,Wh代表递归连接的权重,Wx代表输入层到隐含层的权重,sigmoid与tanh为两种激活函数。
2 Batch Normalization
RNN需要高昂的计算代价,训练时间通常比一般DNN模型高一个数量级[11]。近期有许多利用并行计算减少RNN计算时间的研究[12],但由于RNN训练的是序列数据,增加计算单元并不能获得同比率的计算速度提升。
另一种常见的加速收敛方法是通过受限制的优化方法,如标准化或白化输入数据,然而标准化或白化操作本身就需要大量的计算。针对这个问题,谷歌在2015年提出了批规范化(Batch Norma- lization,BN)对白化进行化简[13],主要的简化方法有两点:(1)对输入数据的每一维多进行规范化(normalize)操作;(2)normalize操作的对象不再是整体训练集,而是当前迭代中的batch集,因此这个方法被叫做Batch Normalization。
2.1 Batch Normalization原理

(8)
(9)

(10)
ε为一个防止分母为0极小的常数。如果简单的将公式(10)得到的分布作为输入,则容易破坏输入原本的分布,因此BN加入了两个可学习的参数,γ和β,得到规范化后的结果为:
(11)
设W为权重矩阵,φ为激活函数,则输出y为:
y=φ(BN(Wxk))
(12)
2.2 BN-RNN
在RNN中,目前Batch Normalization 只能加入在层与层之间,不能在递归连接上加入BN操作[15]。因此BN-RNN推导如下:
由公式(1)与公式(12)可得t时刻有
ht=φ(BN(Whht-1+WxXt))
(13)
由于在递归连接上加入BN会增加训练时间,因此将Whht-1从BN()中拿出,得:
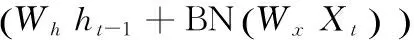
(14)
与Simple-RNN相比,BN-RNN可以使用较高的初始学习速率,加快收敛速度;同时BN-RNN具有较高的泛化能力,因此可以不使用Dropout[16]等带来额外计算开销的抗拟合技术。
3 实验验证与结果分析
3.1 指标选取与数据处理
本文实验的数据来自安徽省电力公司的30台机组,数据内容为t时刻的发电输出功率序列Wt与污染物排放量序列Pt,每台机组数据集大小为8万条。由于前文提到的数据特征难以提取,因此只采用原始数据作为特征,输出功率序列Wt为输入数据(Input),污染物排放量预测值为RNN的输出数据(Output)。如图3所示为合肥一厂数据,由图可以看出,输出功率与污染物排放量之间的对应关系并不明显,难以提取有效特征。

图3 合肥一厂发电机组功率与污染物排放二维散点图
实验结果的评价标准,即目标函数,主要选择均方误差(Mean Squared Error,简称MSE)。这是回归分析中普遍采用的评价标准。在具体分析LSTM的性能指标时,会采用一些深度学习研究中普遍采用的评价标准,如收敛速度等。均方误差,其算数平方根为均方根误差。均方误差公式如下:
(15)

3.2 最小二乘法(LSM)、SVM与LSTM
实验使用Python编程语言,LSTM模型由Keras等深度学习类库实现,包含5个LSTM层,每层128个节点。模型采用随机梯度下降(SGD)优化方法,初始学习率设为千分之一,batch size设为128。最小二乘法拟合的目标函数选择为二次多项式函数。
如图4所示,LSTM-RNN代表基于LSTM的RNN模型,SVR代表支持向量机回归,LSM代表传统的最小二乘法。三种拟合方法在30台机组的测试集数据上的实验结果表明:LSTM模型预测的精度大大高于其他两种方法,在30个测试集上的MSE平均值没有超过0.04,证明该预测方法在实践上具有有效性。如前文所述,基于最小二乘法的拟合方法并不适合不能提取明显特征的数据,而支持向量回归SVR可以将低维度的数据映射到高维度空间,使得数据集的特征变得明显,但是在本次实验中的准确度依然较低。
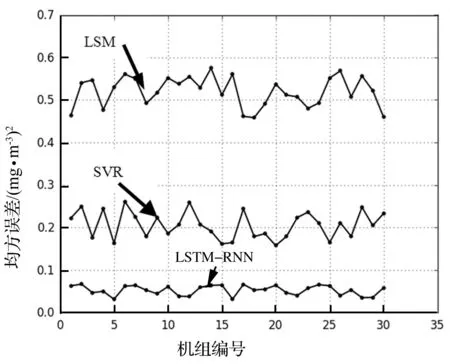
图4 三种拟合方法预测结果对比图
3.3 Simple-RNN与BN-RNN
Simple-RNN的训练时间很长,加上输入数据白化、dropout抗拟合技术等提高模型精度的处理,一个模型的训练时间从数小时到数十小时不等。BN技术可以有效减少训练时间,并提高训练精度。实验采用的Simple-RNN与BN-RNN模型均由5层各128节点的LSTM单元组成,采用SGD优化,BN-RNN中BN处理在层与层之间。Simple-RNN采用 dropout抗拟合技术增加精度。测试集大小为训练集的5%。

图5 simple-RNN与BN-RNN对比图
实验结果如图5所示:加入BN操作的模型在收敛时间取得了显著提升,收敛速度几乎提高了一半。这主要是因为BN-RNN可以使用更高的学习率,BN使得每层输入的分布相同,这样不用使用更小的学习率保证loss下降,因此获得更高的收敛速度。此外因为BN-RNN不需要使用dropout或其他抗拟合技术,减少大量额外计算开销使得迭代时间变短。
在模型精度上BN-RNN也取得了优势,原因可能在于Simple-RNN没有使用白化等手段初始化输入数据。因为白化等方法将增加大量计算时间,使得本来就收敛较慢的模型更难训练,甚至出现无法收敛的情况。
3.4 不同timesteps下的结果比较
RNN与一般深度神经网络(DNN)的不同之处在于,RNN可以训练时间序列上的数据,利用数据在时间上的相关性使得训练结果更加精确。因此在语音识别、语言模型、视频音频分辨[17-18]等上下文时序相关的模型上取得了惊人成果,效果超过了传统的隐马尔可夫模型以及一般的DNN模型。timesteps代表RNN能够利用的时间序列长度。特别的,当timesteps=1时,RNN与一般的DNN没有区别。本文中的实验数据为每隔单位时间从发电机组上采集到的输出功率与污染物排放数据。因为机组的工作状态前后之间具有关联性,因此该数据在时间上具有天然的连续性。具体采用的timesteps的大小应由生产过程中的客观因素决定,当天气、温度、煤的质量、机组工作状态等条件改变时,数据前后之间的关联性便会随之发生变化。

图6 三种timesteps对比图
实验结果如图6所示:当timesteps=1收敛速度最快,收敛速度与timesteps的大小成反比。原因是当timesteps增加时,同样的输出结果(output)对应输入数据(input)增多,增加了大量计算开销。例如time step=1时,时刻t的输入数据为发电功率xt,输出结果为污染物排放量yt;而当timesteps=32时,输出结果还是yt,输入数据为序列(xt-31,xt-30,….,xt),输入数据的改变大大增加了矩阵运算的难度。此外,由于timesteps=1时RNN相当于普通DNN,也证明了前文中所说的“RNN模型训练所需的时间通常比一般的DNN模型高一个数量级”。
同时可以看到,当timesteps=128时,模型精度反而比timesteps=32时降低。这说明timestep是并不是越大越好,过大的timesteps不仅会增加收敛时间、提高模型训练难度,同时有可能降低模型精度。因为当数据在时间序列上的长度过长时,前后之间的关联性可能就逐渐减低甚至失去关联性。因此建议将timesteps设置为可以被学习的参数,当模型的训练精度不再下降甚至反而上升时,便可以进行参数学习更改,取得更优的训练效果。
4 结束语
本文实现了一种基于LSTM的发电机组污染物排放预测方法,解决了传统最小二乘法和机器学习方法难以从发电机组数据中提取有效特征的问题。证明了该预测方法在实践上具有有效性,并可解决传统方法难以解决的问题。同时本文采用BN等深度学习方法,结合RNN 的模型特点对模型的训练方法进行优化,大大缩短了RNN模型的训练时间,深度学习模型的训练时间普遍从数小时到数天都有可能,优化收敛时间对于电力调度等时效性严格的问题具有重要意义。
本文所采用的优化收敛时间的方法Batch Normalization目前在RNN上的使用还局限于每一层之间,无法在RNN的递归连接上加入BN,否则效果大打折扣。学术界正在对这个问题的原因进行研究,目前已有研究者在语音识别的RNN模型上部分解决了这个问题。下一步工作的目标之一便是在本文的模型上解决这个问题,进一步提高模型的收敛速度与精度。
[1] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[2] BASAK D, PAL S, PATRANABIS D C. Support vector regression[J]. Neural Information Processing-Letters and Reviews, 2007, 11(10): 203-224.
[3] HUANG G B, ZHOU H, DING X, et al. Extreme learning machine for regression and multiclass classification[J]. Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on, 2012, 42(2): 513-529.
[4] SMOLA A J, SCHOLKOPF B. A tutorial on support vector regression[J]. Statistics and Computing, 2004, 14(3): 199-222.
[5] GRAVES A, MOHAMED A, HINTON G. Speech recognition with deep recurrent neural networks[C]//Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013: 6645-6649.
[6] LEE T, CHING P C, CHAN L W. Recurrent neural networks for speech modeling and speech recognition[C]//Acoustics, Speech, and Signal Processing, 1995. ICASSP-95., 1995 International Conference on. IEEE, 1995, 5: 3319-3322.
[7] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[8] IRSOY O, CARDIE C. Deep recursive neural networks for compositionality in language[C]//Advances in Neural Information Processing Systems. 2014: 2096-2104.
[9] PASCANU R, MIKOLOV T, BENGIO Y. On the difficulty of training recurrent neural networks[C]//Proceedings of the 30th International Conference on Machine Learning (ICML-13). 2013: 1310-1318.
[10] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[11] WILLIAMS W, PRASAD N, MRVA D, et al. Scaling recurrent neural network language models[C]//Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on. IEEE, 2015: 5391-5395.
[12] YU D, YAO K, ZHANG Y. The computational network toolkit [Best of the Web][J]. Signal Processing Magazine, IEEE, 2015, 32(6): 123-126.
[13] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proceedings of The 32nd International Conference on Machine Learning. 2015: 448-456.
[14] SHIMODAIRA H. Improving predictive inference under covariate shift by weighting the log-likelihood function[J]. Journal of Statistical Planning and Inference, 2000, 90(2): 227-244.
[15] NISHIDA N, NAKAYAMA H. Multimodal gesture recognition using multi-stream recurrent neural network[M]//Image and Video Technology. Springer International Publishing, 2015: 682-694
[16] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[17] XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]//Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 2015: 2048-2057.
[18] YAO L, TORABI A, CHO K, et al. Describing videos by exploiting temporal structure[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 4507-4515.
A Study on the Prediction of Generator Set Pollutant Emissions Based on LSTM
Yang Xunzheng1, Ke Yuyang1, Liang Xiao2, Xiong Yan1
(1.School of Computer Science, University of Science and Technology of China, Hefei 230027, China;2.Anhui Electric Power Company Dispatch Control Center, Hefei Anhui 230022, China)
To take advantage of the massive historical pollutant emission data accumulated by power companies to build up a scheduling framework for reduction of pollutant emission, this paper adopts a recurrent neural network, as well as deep learning technologies like batch normalization, combined with the relationship between the generator set output power and pollutant emissions, to implement learning and training of data and models. Experimental results show that this method can effectively predict pollutant emissions from generator sets to solve the problem of difficult extraction of effective characteristics through traditional regression analysis.
machine learning; deep learning; recurrent neural network; batch normalization; regression analysis
国网安徽省电力公司科技项目(52120015007W)
10.3969/j.issn.1000-3886.2016.05.007
TP391
A
1000-3886(2016)05-0022-04
杨训政(1990-),男,安徽人,硕士,主要研究方向:机器学习、深度学习。
定稿日期: 2016-06-03
