基于LPC和MFCC得分融合的说话人辨认
2016-02-23单燕燕
单燕燕
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
基于LPC和MFCC得分融合的说话人辨认
单燕燕
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
实验室环境下,说话人识别研究已经取得很大进展,但是在实际生活中,说话人识别系统的性能受到环境噪声、健康状况等因素的影响很大。日常生活中,感冒是不可避免的。而感冒往往会诱发鼻腔的炎症,改变鼻腔的容积和形状,引起说话人声音的改变,导致说话人识别性能下降。文中研究测试者感冒时说话人识别系统的性能。为了有效利用不同特征参数得分的互补性,针对基于GMM模型的说话人辨认系统,提出了将特征LPC和MFCC分别应用于该系统,并将二者的得分归一化后进行融合计算。实验结果表明,对正常语音来说,与LPC特征系统相比,该方法能够有效提升辨认性能;对感冒语音来说,当高斯成分为16时,较之LPC特征系统,该方法提升辨认性能12.5%左右,较之MFCC特征系统,该方法也能提升8.5%左右的辨认性能。
感冒语音;说话人辨认;得分融合;得分归一化
语音信号不仅传递了所要表达的语义信息,还传递了说话人的健康状况以及情绪等信息。例如,当说话人身体不舒服或生病时,他说出的语音往往比身体健康时的低沉,给人一种有气无力的感觉,有时甚至是声音沙哑的,所以说话人生病时产生的语音波形也随着而改变,从而降低了说话人识别系统的性能。实际生活中,说话人识别系统的性能受到两方面因素的影响:外部因素和内部因素[1]。外部因素主要指的是环境噪音、编码方式不同以及通道变化。说话人识别的研究目前主要集中在环境噪音和通道失配等外部因素的影响。在这方面已取得了非常大的进展[2]。内部因素,也称自身因素,主要是指说话人的声道特征或者独特的行为特征发生变化,按照时间长短可分为短时和长时两大类。长时变化[3]通常指的是随着说话人年龄的增大发声器官产生的缓慢变化,包括疾病、物理损伤或者发育期变化等带来发声器官的长久性变化。与长时变化不同,短时变化[1]则是由于发声方式的变化、说话人伪装、情绪变化以及短时疾病(如感冒)等因素使得说话人的声音发生暂时性的变化。长时变化通常可利用自适应的方式得到很好地解决,然而短时变化则因其具备复杂性和突变性等特点而成为当前说话人识别中的一个难题。短时疾病一般指感冒、咳嗽、扁桃体发炎等造成发声器官变化的短暂的可康复的疾病。P.Rose[4]指出感冒往往会伴随着鼻腔(nasal cavities)中的炎症和肿大,这会改变鼻腔的容积和形状,从而改变鼻腔对声源激励信号的调制作用,引起说话人声音的改变,从而导致说话人识别性能急剧下降。R.G.Tull等[5]也发现用正常语音训练的说话人识别系统,在说话人感冒时的识别率明显下降。但是对于说话人感冒时引起语音的具体变化以及如何减小感冒时语音的短时变化对说话人识别系统的影响缺乏进一步的研究。
日常生活中,人们总是难以避免地感冒,感冒使得说话人语音发生变化进而影响说话人识别系统的性能,所以,研究测试者感冒时的说话人识别系统具有很大的现实意义。
文中定义说话人未感冒时录制的中性语音作为正常语音,而患有感冒时录制的语音为感冒语音。用正常语音训练说话人GMM模型,而待识别语音分别为正常语音和感冒语音,文中提出了将线性预测系数和梅尔倒谱系数分别应用于基于GMM模型的说话人辨认系统,归一化处理匹配得分,然后进行融合计算,融合得分最高者即为最终的匹配结果。实验结果表明,该方法能显著提高系统的性能。
1 基于GMM模型的说话人辨认系统
说话人辨认分为两个阶段:训练阶段和辨认阶段。在训练阶段,对说话人的语音信号进行一系列的处理,提取其特征参数之后,然后对这些特征参数进行聚类以表征这个特定说话人,即建立说话人模型。而辨认阶段则提取出待辨认说话人的测试语音特征参数,并将其与已建立的说话人模型进行相似性比较,根据相应的评估准则判定说话人身份。
基于GMM[6-8]模型的说话人辨认系统框图如图1所示。
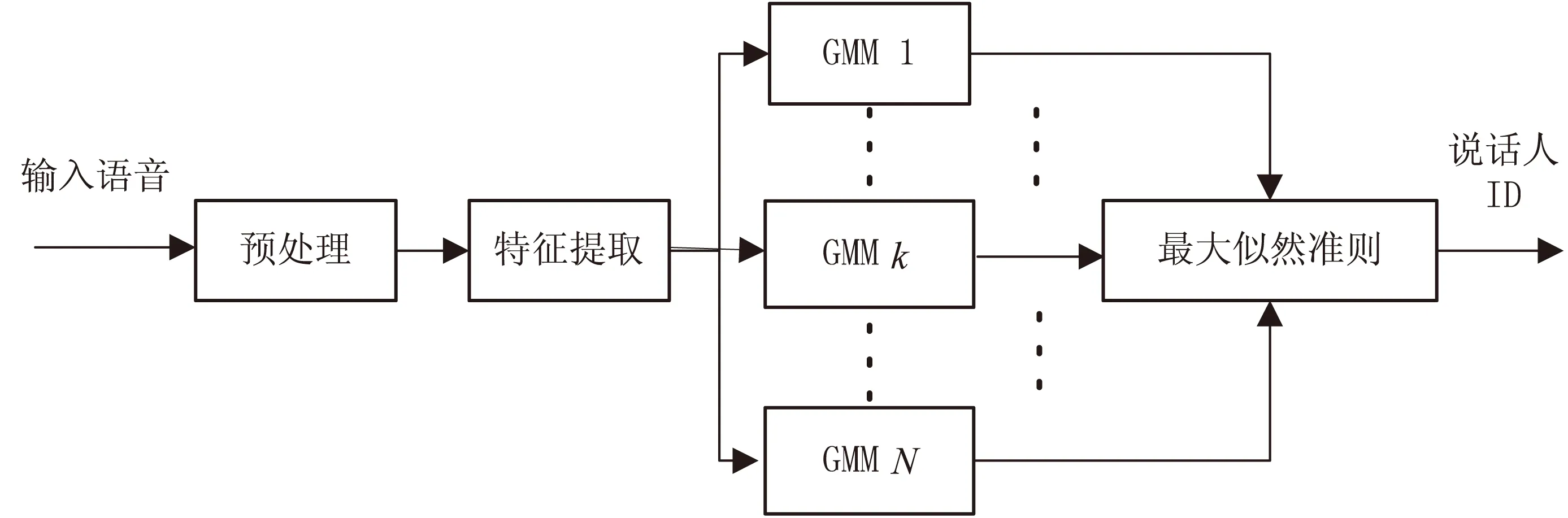
图1 基于GMM模型的说话人辨认系统框图
2 特征提取
2.1 线性预测系数(LPC)
语音信号的线性预测的基本思想是:在特定时间内,语音信号采样点之间具有一定的相关性,因而可以用过去的样点值的线性组合来表示现在或未来的样点值。通过使语音的预测样点值在最小均方误差准则下逼近实际样点值,可以求得唯一的一组预测系数。这组预测系数表征了语音信号的特性。语音信号下一时刻的样点值可以利用该语音信号过去p个时刻的样点值的线性组合来逼近,用过去p个时刻语音采样值的线性组合以最小预测误差预测语音信号下一时刻的采样值,称为对语音信号的p阶线性预测[9]。设语音的采样序列为{x(n)|n=0,1,…,N-1},则x(n)的p阶线性预测值为:
(1)
式中,p为预测系数;ai(i=1,2,…,p)称为线性预测系数。
每一帧语音求解的线性预测系数构成一个p维矢量。线性预测分析就是用这p维矢量来表示每帧语音。若用e(n)来表示预测误差,则

(2)
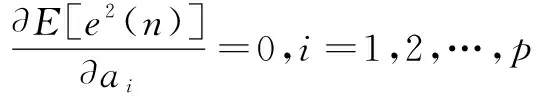
(3)
由上式可得p个方程,其矩阵表示为:
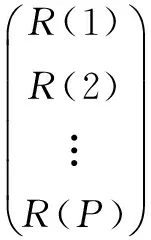
(4)
上述方程的解就是LPC系数。经典的求解方法有两种:自相关法和协方差法[10]。其中Durbin递推算法[11]是目前广泛采用的一种自相关方法。
相比于它的预测功能,线性预测能够提供一个非常好的声道模型和模型参数估计方法,因而被应用于语音信号处理。
线性预测是一种分析语音信号频谱的谱估计方法,之所以是目前最重要的语音特征参数之一,有以下几个原因:
(1)它提供了很好的短时语音信号的声道模型以及求解模型的方法。
(2)基音、共振峰等模型参数数据量小,容易计算,便于实时处理。
(3)LPC参数训练得到的模型参数可以存储起来,在语音识别等应用中减少识别时间。
(4)参数数据量小,传输速率低。
LPC模型阶数p的选择主要从两方面考虑:共振峰个数和对口唇辐射影响的补偿。通常p的取值范围为8至12之间。12阶的LPC模型可以以非常小的误差逼近几乎所有的语音信号产生的声道模型。
2.2 梅尔倒谱系数(MFCC)
噪声环境下及其他变异情况下,人耳仍能分辨出语音内容甚至说话人身份,这是因为耳蜗对输入信号的调制作用。对于不同频率的信号,耳蜗基础膜的振动位置也是不同的。实际的声音频率与人耳所听到的声音高低不是线性关系,它经过了一个非线性的频率变换。即不同的频率信号,人的听觉系统有不同的响应灵敏度。在1 000 Hz以下,实际声音频率与人耳感知到的声音高低成线性关系,而1 000 Hz以上为对数关系。Mel频率反映了实际频率与感知频率的转换关系。其表达式为:
fmel=2 595log10(1+f/700)
(5)
式中,f的单位是Hz。
当两个频率成分的差值超出某个特定值时,这时人耳才能够区分它们。这个特定值被称为临界带宽。根据以上特性,人耳的听觉特性可以用临界频带滤波器来模拟。
一般,采用三角滤波器组[12]来逼近临界频带滤波器组。
MFCC就是基于人耳听觉系统的临界效应提出来的一种倒谱参数。图2即为MFCC参数提取框图。

图2MFCC特征参数提取框图
具体流程为:
(1)将采样后的语音信号进行归一化、端点检测、预加重和分帧加窗预处理后,得到语音信号的矩阵形式,其中每个行向量表示一帧语音。
(2)将预处理后的矩阵形式的语音信号进行离散傅里叶变换,并对语音频谱取模的平方得到能量谱。
(3)通过三角滤波器组对语音信号进行滤波处理。计算出语音信号通过第m(1≤m≤M)个滤波器后的能量和,其中M为滤波器个数。
(4)对每个三角滤波器输出的能量求对数,将得到M个系数。
(5)对这M个系数进行离散余弦变换,即得到MFCC参数。
文中使用的MFCC取其前1~12个,共12阶。
3 基于得分融合的说话人辨认系统
语音信号不仅包含说话人特有的个性信息,还蕴含了语义信息,是二者的综合体。迄今为止学者们仍未找出一个能够将二者分离的语音特征参数。现有的语音特征参数都只是表示了语音信号的某些信息。为了比较充分地表征语音信号,提高说话人识别系统的识别率和鲁棒性,特征参数的融合、不同说话人识别系统的融合以及得分融合已经成为了许多学者考虑的一个重要的研究方向。文中提出用LPC和MFCC分别训练得到的GMM的说话人识别系统,并将这两种特征的测试得分进行融合的说话人识别方法。其系统框图见图3。
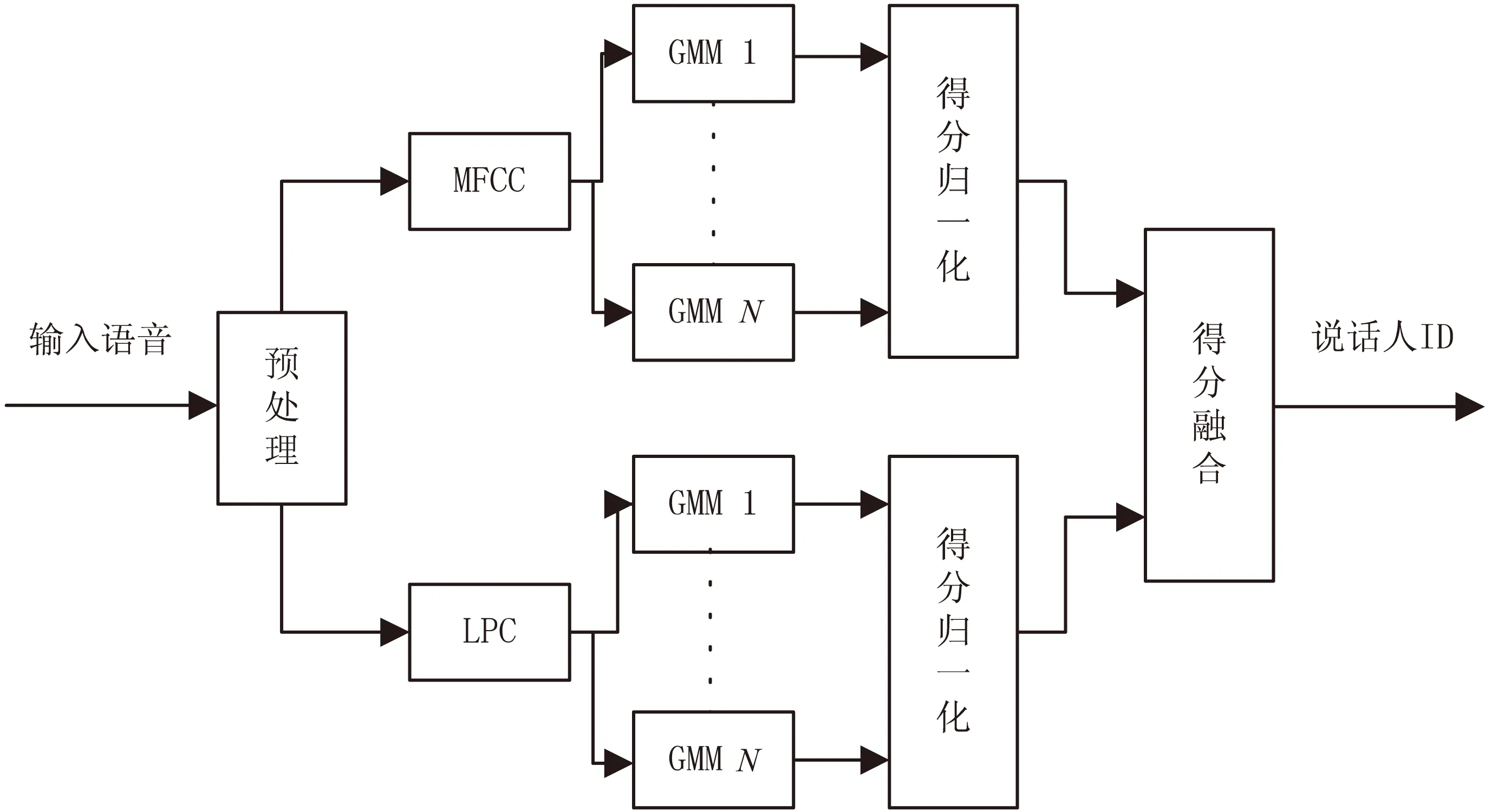
图3 基于LPC和MFCC得分融合的GMM模型说话人辨认系统框图
预处理主要包含预加重、分帧、加窗等操作,预加重技术[13]可以消除口鼻辐射,文中采用预加重滤波器的系数为0.91,其传递函数为:
H(z)=1-αz-1
(6)
建立的说话人模型,考虑了高斯混合成分分别为16、32、64三种情况。
3.1 得分归一化
由于测试语音的特征不同,提取得到的数据之间有很大差异,通过系统的匹配计算部分获得的得分变化幅度较大。如果将不同特征获得的得分直接进行融合,很难获得得分融合的分布规律,故而文中采用数据归一化方法来处理得分。系统获得的得分是一个向量x=(α1,α2,…,αN),归一化处理如下:

(7)
其中,αi表示该测试语音与第i个说话人模型的匹配得分;N为模型库中说话人总数。
3.2 得分融合

s=w1x1+w2x2
(8)
文中使用的加权系数为w1=0.7,w2=0.3。
4 实验结果和分析
4.1 实验设置
文中采用的语音数据库有10名20~30岁说话人,其中7名男性,3名女性。采样频率fs为8 kHz,语音文本包含一段约1分半钟的长语句、10个短句子。每个说话人分别在身体正常和感冒的情况下,朗读以上的长语音和10句短句子。正常情况下朗读的长语音用来训练说话人模型,说话人身体正常和感冒情况下说的10个短句子作为测试语音。说话人身体正常时朗读的长语句作为训练集,共10句,短句子80句作为测试集1;说话人感冒时朗读的80句短句子作为测试集2。
4.2 LPC和MFCC系统性能
表1、表2分别给出了特征参数为LPC的GMM模型说话人辨认系统和特征参数为MFCC的GMM模型说话人辨认系统的识别率,文中采用的是正确识别率作为系统的评价标准。分别是对测试集1和测试集2的识别结果。

表1 基于LPC参数的GMM说话人辨认

表2 基于MFCC参数的GMM说话人辨认
从表1、表2可知,对于同一特征构建的说话人识别系统,感冒语音的识别率比正常语音的识别率低,这说明说话人感冒时发出的语音的个性特征发生了变化,使得说话人识别系统的性能下降。
4.3 得分归一化和融合后性能分析
将测试语音分别提取特征参数LPC和MFCC,并输入相应的系统模型,经匹配计算求得两个得分,将两者线性加权。其中,LPC特征参数获得的得分权重为0.3,MFCC特征参数的得分权重为0.7,其实验结果见表3。

表3 基于LPC和MFCC得分融合的 GMM模型说话人辨认
由表3可得,对于正常语音,与LPC特征系统相比,得分融合系统性能提高的比较显著;对于感冒语音,高斯成分为16、32、64,得分归一化和决策融合系统性能明显优于单一特征系统,其中在16个高斯成分时,与LPC特征系统相比,其性能提高12.5%左右,比MFCC特征系统性能提高8.5%左右。
5 结束语
文中提出将LPC和MFCC两特征分别应用于GMM模型的说话人辨认系统,提取测试语音的LPC和MFCC特征参数,输入相应的说话人识别模型库中进行匹配计算,将这两个特征的得分进行归一化处理后进行线性加权融合,并得出最终的判决结果。实验结果表明,对于正常语音集,文中提出的系统能够较显著地提高说话人辨认系统的性能;对于感冒语音集,说话人辨认系统的性能得到了显著提高,在高斯混合成分M=16时,相对于LPC单特征系统提高了12.5个百分点,相对于MFCC特征系统也提高了8.75个百分点。
[1]FuruiS.Recentadvancesinspeakerrecognition[M]//Audio-andvideo-basedbiometricpersonauthentication.Berlin:Springer-Verlag,1997:237-252.
[2]KinnunenT,LiH.Anoverviewoftext-independentspeakerrecognition:fromfeaturestosupervectors[J].SpeechCommunication,2010,52(1):12-40.
[3]PawlewskiM,JonesJ.URUplus-ascalablecomponent-basedspeaker-verificationsystemforBT’s21stcenturynetwork[J].BTTechnologyJournal,2007,25(3):170-178.
[4]RoseP.Forensicspeakeridentification[M].London:Taylor&Francis,2002.
[5]TullRG,RutledgeJC,LarsonCR.Cepstralanalysisof“cold-speech”forspeakerrecognition:asecondlook[J].JournalofAcousticalSocietyofAmerica,1996,100(4):2760-2760.
[6]ReynoldsDA,RoseRC.Robusttext-independentspeakeridentificationusingGaussianmixturespeakermodels[J].IEEETransonSpeechandAudioProcessing,1995,3(1):72-83.
[7]ReynoldsDA,QuatieriTF,DunnRB.SpeakerverificationusingadaptedGaussianmixturemodels[J].DigitalSignalProcessing,2000,10(1):19-41.
[8]ReynoldsDA.SpeakeridentificationandverificationusingGaussianmixturespeakermodels[J].SpeechCommunication,1995,17(1-2):91-108.
[9]AkhoulM.Linearpredictionofspeakersfromtheirvoice[J].ProcofIEEE,1976,64:460-475.
[10] 张军英.说话人识别的现代方法与技术[M].西安:西北大学出版社,1994:14-16.
[11] 张玲华,郑宝玉.随机信号处理[M].北京:清华大学出版社,2003.
[12]ZhuWeizhong,O’ShaughnessyD.IncorporatingfrequencymaskingfilteringinastandardMFCCfeatureextractionalgorithm[C]//Procof7thinternationalconferenceonsignalprocessing.[s.l.]:IEEE,2004:617-620.
[13] 王 青.基于神经网络的汉语语音情感识别的研究[D].杭州:浙江大学,2008.
[14]YuP,SeideFTB.Ahybridword/phoneme-basedapproachforimprovedvocabulary-independentsearchinspontaneousspeech[C]//ProcofINTERSPEECH2004.JejuIsland,Korea:[s.n.],2004:293-296.
[15]ChenB.VoiceretrievalofMandarinbroadcastnewsspeech[J].InternationalJournalofPatternRecognitionandArtificialIntelligence,2006,20(1):91-109.
Speaker Identification Based on Score Combination of LPC and MFCC
SHAN Yan-yan
(College of Communication and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
At present,speaker recognition technology has made great progress in clean voice.But in daily life,there are various factors,such as environmental noise and healthy condition,impacting recognition rate of speaker recognition system.The cold tends to induce the nasal cavity’s inflammation,and changes the volume and shape of the nasal cavity and then changes the vocal characteristics of the speaker.In order to effectively use the complementarity of scores from different feature parameter,the performance’s change of speaker identification system was studied when the speaker gets the cold.So the method was proposed using linear prediction coefficient and MEL cepstrum coefficient to train the speaker model respectively,and then score normalization method is used to process scores from two feature systems.Finally,two outputs were weighted.The experimental results show that for normal speech,this method can improve the identification performance;for cold speech,the method improves the identification performance by 12.5% when the number of Gaussian components equals to sixteen compared with the system taking MFCC as feature,by 8.5% to the LPC system.
cold speech;speaker identification;score combination;score normalization
2015-01-07
2015-05-08
时间:2016-01-04
国家自然科学基金资助项目(61271335);国家重点基础研究发展计划(2011CB302303)
单燕燕(1988-),女,硕士研究生,研究方向为说话人识别、语音信号处理。
http://www.cnki.net/kcms/detail/61.1450.TP.20160104.1607.064.html
TN912.3
A
1673-629X(2016)01-0039-04
10.3969/j.issn.1673-629X.2016.01.008
