无监督排序学习算法的一致性比较
2016-01-20李纯果李海峰
李纯果,李海峰
(1.河北大学数学与信息科学学院,河北保定 071002;2.河北大学党委组织部,河北保定 071002)
无监督排序学习算法的一致性比较
李纯果1,李海峰2
(1.河北大学数学与信息科学学院,河北保定071002;2.河北大学党委组织部,河北保定071002)
摘要:对于无监督的排序学习算法来说,排序结果的评价指标是非常具有挑战性的问题.从一致性的角度,比较了4种比较典型的无监督排序学习方法,并在机器学习标准数据库中进行实验比较分析.结果显示,RPC这种非线性的无监督排序融合方法产生的排序结果有最小的Kendall距离和Spearman简捷距离,体现了RPC在无监督排序方法上的优越性.
关键词:启发式排序;学习式排序;排序一致性;RPC
DOI:10.3969/j.issn.1000-1565.2015.02.013
中图分类号:TP181
文献标志码:志码:A
文章编号:编号:1000-1565(2015)02-0182-06
Abstract:Unsupervised ranking has a big challenge that there is no standard metric to measure the ranking results. This paper tries to propose a comparison scheme for unsupervised ranking based on ranking consensus. Some metrics used in supervised ranking can be used here to measure unsupervised ranking consensus. However, these metrics are taken between ranking lists and attributes, rather than ranking lists and ranking labels. Experimental results on UCI datasets show that RPC, which is one kind of unsupervised ranking aggregation method, has the minimum Kendall Distance and Spearman Footrule Distance than the other representative unsupervised ranking methods.
收稿日期:2014-09-12
基金项目:河北省自然科学基金资助项目(F2013201060)
Comparison analysis on ranking consensus
LI Chunguo1, LI Haifeng2
(1. College of Mathematics and Information Science, Hebei University, Baoding 071002, China;
2. Department of Party Committee Organization, Hebei University, Baoding 071002, China)
Key words: heuristic ranking;learning to rank;ranking consensus;RPC
第一作者:李纯果(1981-),女,河北邯郸人,河北大学讲师,主要从事模式识别理论基础与应用、机器学习等研究.
E-mail:lichunguo@cmc.hbu.cn
排序问题是实际应用中的一个很基础的问题,比如说信息检索中的网页搜索问题[1-2].一般地,排序问题分为启发式排序和学习式排序.启发式排序是根据给定排序对象在多个属性上的观测值,基于直观或经验构造一种融合多属性观测值的方法,得到每个排序对象的评分.学习式排序是把机器学习的方法应用到排序中,通过优化一定的规则,得到每个排序对象的排序位置.对于具有连接结构的排序对象来说,基于启发式的排序方法不再适用,而对于当今大数据的局势,更需要学习式的排序方法.
由于机器学习方法是根据一定的学习目标来进行排序,对象的排序顺序根据学习目标不同而不同.对于监督学习来说,NDCG(normalized discount cumulative gain)和MAP(mean average precision)是应用的2种比较多的排序优化目标函数.在文本检索中,NDCG是归一化的累计折扣相关值[3],当NDCG达到最大时,会给出与检索文本排序最相关的网页顺序;而MAP计算的是网页评分对检索文本的平均值[4]. 对于没有真实的排序对象顺序的时候,也就是无监督学习排序,NDCG和MAP都不能用做优化排序目标进行学习.无监督学习排序算法面临很多挑战,由于没有真实排序顺序作为参照,因而最重要的挑战就是“如何保证所得到的排序顺序的合理性”.例如,在大学排名中,根据多个选定指标的统计数据,Times,QS,ARWU,Webometrics的做法基本上都是线性加权和的方式,即给每个指标赋予一定权重值,然后计算把多指标观测数据计算加权算术平均,得到平均分值.然而这种加权算术平均的方式往往会根据权重的不同改变排序对象的排序顺序,权重值是根据不同的专家给定,就会存在权重比较不客观问题.因此,对于无监督的排序方法,需要选择合理适用的排序目标,或者说是如何选择评价无监督排序结果的客观指标.
对于无监督排序结果的评价指标,有些学者提出了用排序一致性的指标来评价,即当没有真实的排序顺序作为参照时,最终得到的排序结果希望与根据各个指标得到的排序结果尽可能的一致.早在最早的排序问题中,例如Borda计数法[5],就是排序结果保持大多数的一致性所提出的.
1一致性衡量方法
假设无监督的排序对象为A={a1,a2,…,an},排序对象在d个属性V={v1,v2,…,vn}上的观测结果记为X={x1,x2,…,xn}.对A中的元素进行排序,转换为对X的n个向量进行排序,即需要根据观测值,给出ai1≤ai2…≤ain,其中i1,i2,…,in是一组{1,2,…,n}的排列,记为τ.无监督排序的任务就是根据排序对象在d个属性上的观测结果,学习到一个最接近于真实存在的排列τ.
无论是监督排序学习方法还是无监督排序学习方法,首先都要确定一个评价排序的量化指标,例如NDCG,MAP,等等.在此指标的指导下,来评价一个排序学习算法的优劣.指标的选取,或者是发现现有指标存在的问题并对其改进,得到新的指标,或者是定义排序指标公理(不证自明的结论)并找到符合所有公理的指标. Kumar曾在2010年就提出了选择排序指标的5条公理[6].
1)简单性:容易理解;
2)广泛的容纳性:不仅支持基于分数的排序融合,还支持基于排序的排序融合;
3)普适性:可以退化到普通的度量指标;
4)满足基本性质:具有尺度不变性,不因标签改变而改变,三角不等式,等等;
5)与其他度量相关联:指导排序的方式相似,可以选择最适合的度量.
并且提出Kendall距离(Kendall tau distance)[7]和Spearman简捷距离(Spearman’s footrule distance)[8]就符合这5条公理.
根据观测结果X对对象进行排序,可以直接采用启发式的排序融合方法,例如基于分值的排序融合,对各属性赋予权重值,每个对象的得分为对象i在各属性上的观测值的加权平均;或者采用基于排序的融合方法,把根据各属性值得到的排序表进行融合.但是这些融合方式都是启发式的,在无监督排序学习中,由于没有排序标签可以参考,没有办法衡量哪一种排序结果的可信度更高一些,所以需要寻求一定的衡量方法.此时可以考虑用一致性的衡量:如果排序的结果与根据属性值排序的结果都一致,则是一种理想的排序结果;如果两者有很大差异,说明排序算法没有遵循一致性的排序宗旨,导致排序结果不具有可信性.
1.1 NDCG
DCG(discounted cumulative gain)[3-4]是一种衡量排序效果的度量,常用来测量网络搜索引擎算法的有效性.对于一个给定的搜索结果,DCG通过搜索结果对输入关键词的相关性的排序,并根据排序位置对相关性打折(Discounted),计算该搜索结果的累积增益,称之为累积折扣增益.给定{1,2,…,n}的一个排列τ,其DCG定义为
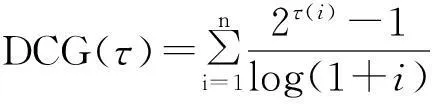
其中,τ(i)是第i个元素在τ中的排列位置.由于有的数据集大小的不同,所以可能导致搜索引擎的DCG有所不同.为了避免由于测试数据集而产生的不同的DCG,定义了NDCG:
其中,Zn是归一化常数.NDCG使得搜索引擎的测试效果不随测试集的大小而改变.
在信息检索中,NDCG把相关分为多个级别,高度相关的文章比部分相关的文档更有价值,其在评价中应该赋予更大的权值[9].文档在序列中的位置越靠后,这个文档的价值越小,从用户的角度考虑,由于时间、精力等原因,用户可能根本不会去看这些文档.NDCG还可以用来衡量排序结果的一致性.例如,按照每个属性值,可以对排序对象做一个排列顺序,而对于每个排序对象的总评分值(score label)得到的排序结果,相对于每个属性值的排序结果,可以得到一个一致性检测.比较2个搜索引擎在同一个搜索集上的NDCG的大小,可以确定哪一个搜索引擎给排序对象的评分值更遵从一致性的原则.
1.2 SRCC
斯皮尔曼相关系数(Spearman rank correlation coefficients, 简称SRCC)是衡量2个变量的依赖性的非参数指标.2个变量x和y的SRCC定义为
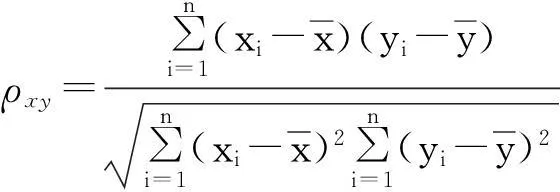
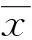

其中,di是第i个元素在x和y的排列中的位置差.SRCC利用单调方程评价2个统计变量的相关性,如果数据没有重复值,并且当2个变量完全单调相关时,SRCC为+1或-1.根据这个特性,SRCC可以用来衡量排序结果是否与属性的排序结果的一致性.如果排序对象根据属性值得到的排序结果与根据属性值排序的结果是完全一样的,说明排序算法可以得到与属性值一致的排序结果,SRCC的绝对值接近于1.排序算法的SRCC越接近于1,说明排序结果与属性值排序结果越一致.
1.3 Kendall距离
Kendall距离(Kendall tau distance)是指2个排序表中2个对象的排序位置不同的对象对的个数[7].如果2个排序表完全一致,Kendall距离达到最小为零;而2个排序表中的对象的位置越混乱,Kendall距离越大.因此,Kendall距离可以用来衡量排序的一致性,作为无监督排序结果评价标准之一.给定2个{1,2,…,n}的排列τ和κ,τ和κ的Kendall距离定义为
K(τ,κ)=|{(i,j):i
其中,τ(i)和κ(i)分别是第i个排序对象在队列τ和κ中的排列位置.
1.4 Spearman简捷距离
Spearman简捷距离(Spearman’s footrule distance)计算了第i个排序对象在2个排列中的位置的绝对距离之和,定义为[8]
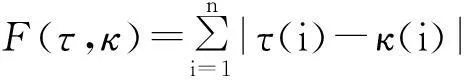
其中,τ(i)和κ(i)分别是第i个排序对象在队列τ和κ中的排列位置.
2排序方法比较
针对综合评价问题,基于一维流形的思想,Li等人[10]基于一维流形综合评价方法,提出了排序主曲线(ranking principal curves,RPC)无监督排序模型.该模型通过非线性融合排序对象在排序观测指标上的观测值,给出每个排序对象一个综合评分结果.一维流形综合评价方法是主成分分析方法(principal component analysis, PCA)的非线性推广(图1),根据研究对象的各评价指标的多属性观测数据,用机器学习的方法确定穿过数据中心的一条曲线,即为面向排序的一维流形.根据研究对象的观测数据在一维流形上的投影点可以确定一个索引值为研究对象的综合评价分值,根据此分值可以确定研究对象的综合排名.RPC的学习排序过程如图2所示.
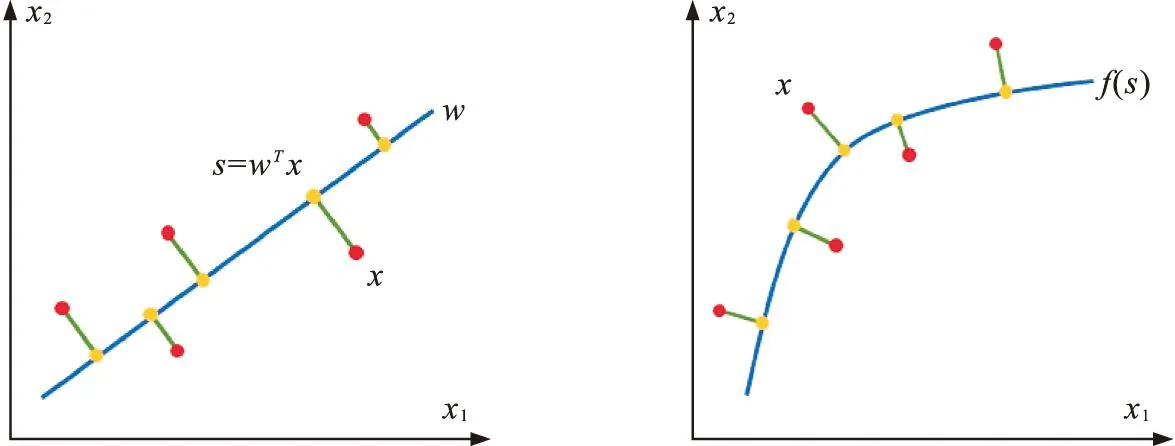
图1 PCA与RPC排序方法Fig.1 Ranking methods of PCA and RPC
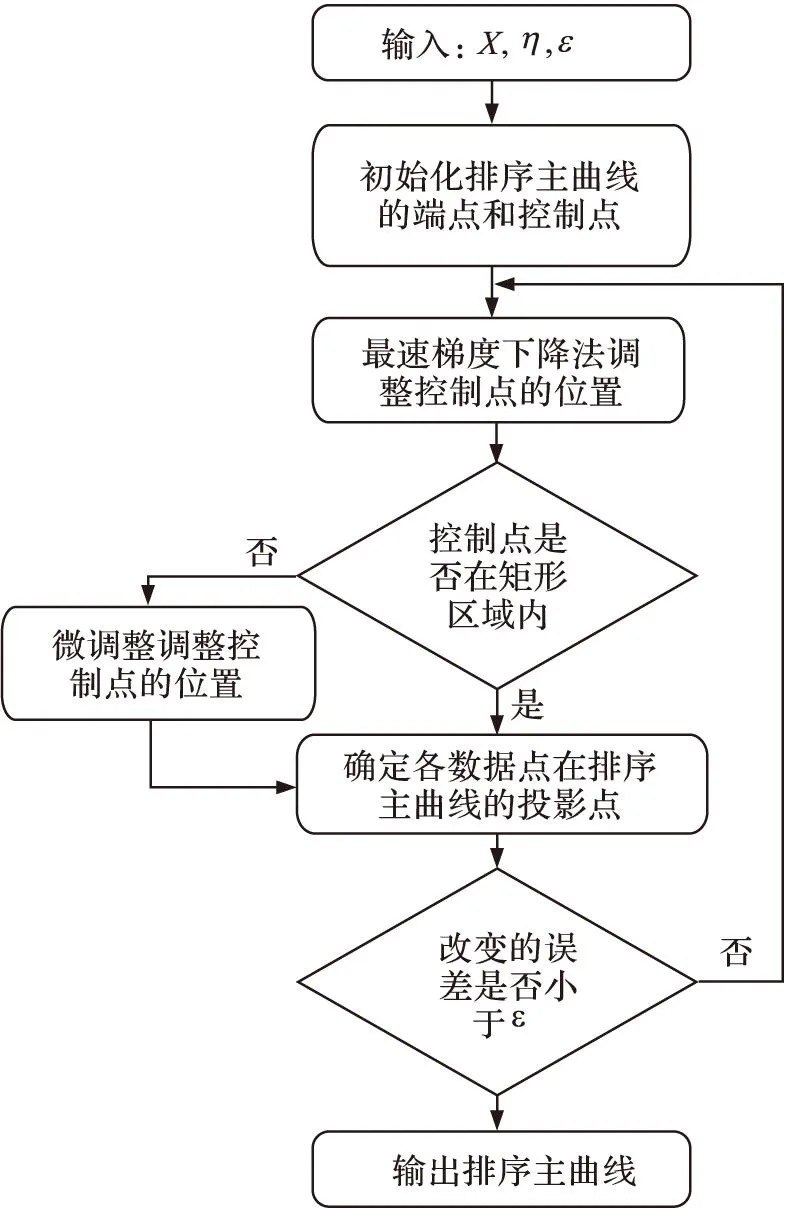
图2 RPC学习流程 Fig.2 Learning scheme of RPC
虽然KPCA(kernel principal curve analysis)也是PCA的非线性推广[11],但KPCA是把原数据点映射到高维数据空间,在高维空间中进行PCA操作,所以KPCA的实质仍是PCA,而主曲线才是真正的从学习动机上非线性推广了PCA,即从线性x=λμ+μ0到非线性x=f(λ)+μ0的推广,其中,μ0是数据的中心点,μ是PCA第一主成分方向,λ是在主成分上的值,f是非线性函数向量.本文把RPC得到的排序结果与KPCA和PCA的排序结果进行了一致性比较.
排序融合是另一种应用很广泛的无监督排序方式[5].通常情况下,这种排序方式都是启发式的融合,例如Borda计数法,Condorcet方法,Kemeny方法.这些方法通常应用在选举中,使得选举结果符合大多数人的排序结果,也是一种一致性的排序融合.本文采用了基于序列的排序融合方法(RankAgg),每个属性都有相同的排序权重,根据每个属性值对排序对象排序,然后取位置的中间值作为排序对象的最终得分,并依据得分进行排名.
3一致性比较
首先,比较了PCA,KPCA,RankAgg和RPC 4种方法的Kendall距离和Spearman简捷距离,实验结果如图3所示.由于无监督排序方法没有排序标签,通过UCI数据库中的回归数据,把回归分值作为每条记录的综合评价分值.将4种方法产生的排序结果与评价分值的结果做对比,来评价RPC方法在无监督排序上的效果.

图3 4种无监督排序方法在Kendall距离和Spearman简捷距离上的比较Fig.3 Comparisons on Kendall Distances and Spearman Footrule Distances of four unsupervised methods
从图3可以看出,在选择的1个人工数据集和4个UCI数据集上,KPCA几乎在所有数据集上的排序结果与目标排序标签的Kendall距离和Spearman距离最大,这也从侧面说明了Kernel技术把观测样本从原数据空间映射到高维空间,映射不具有保序性.虽然KPCA可以实现非线性降维,但是不适用于排序的非线性降维,这是因为低维到高维的映射没有保持数据间的序关系.对于其他的非线性降维,类似于LPP,Isomap,LEE等方法,都存在类似的问题.
PCA与基于MedianAgg的RankAgg方法具有类似的排序融合方式.从排序融合的角度看,PCA是学习融合权重的分值融合方法,而RankAgg是基于序列的融合方法.2类方法都是线性融合方法,对于隐含数据结构为非线性的数据不适用.由于数据本身的数据结构未知,所以不能贸然选择线性或非线性的排序融合方法.如果排序的应用对象是网络搜索和信息检索,排序对象的规模较大,简单的排序融合就比较有效率,因为要求搜索引擎需要在可容忍的时间内搜索结果.而本文讨论的排序对象是静态的,排序对象的个数和排序指标都是确定的,所以,不同于网络搜索和信息检索对排序速度的要求,这里讨论的排序要求尽可能的尊重事实.

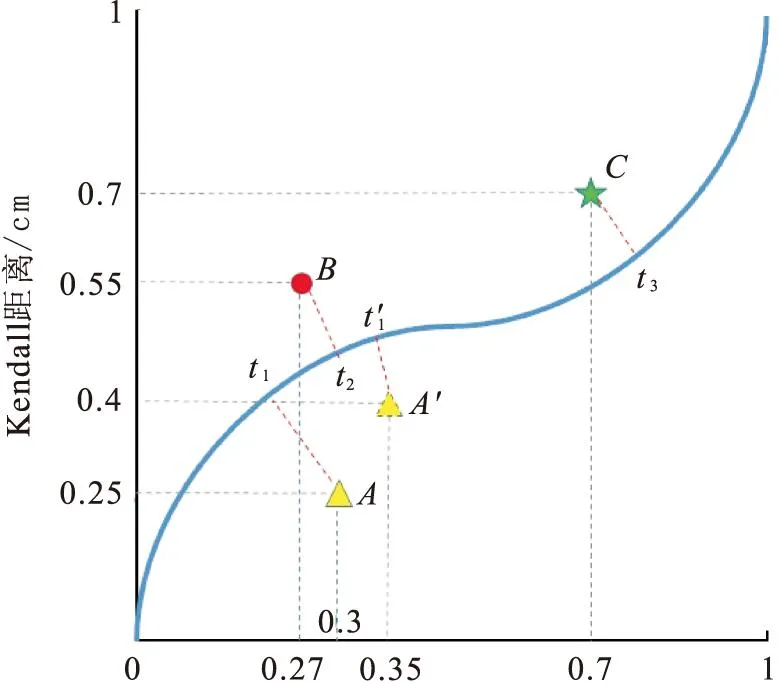
Spearman距离/cm图4 RPC可以反映观测值的微小区别Fig.4 RPC can detect the minor differences in numerical observations
4总结
对于排序学习,监督的学习方法通常用NDCG,MAP等指标来判别算法排序的结果与目标排序标签的是否一致.而对于非监督的排序学习算法的评价,一直是一个很有争议的问题.已经有相关学者提出,可以通过排序融合的方式融合属性值或属性值的排序序列,得到一个综合的排序结果.排序算法在信息检索、网络搜索引擎方面已经有了飞速的发展.
主要针对无监督的排序方法,讨论了4种排序方法对于排序一致性的比较.RPC的非线性排序融合方法不仅能处理线性数据结构问题,也能处理非线性结构问题,从而在Kendall距离和Spearman简捷距离上体现了一定的优势.但是,RPC的排序融合方法潜在的要求是综合评价分值与各属性值成单调关系(单调递增或单调递减),这也是大多数排序问题所满足的条件,RPC正是充分利用了这个排序问题的先验知识而设计的非线性排序融合方法.对于不满足这个先验知识的排序问题,RPC可以做相应的调整,仍然利用RPC的学习架构来进行排序融合,具体的操作是未来的工作之一.未来的工作还包括通过敏感性分析来进行无监督排序学习的属性选择(feature selection)问题.
参考文献:
[1]DWORKC,KUMAR R, NAOR M, et al.Rank aggregation methods for the web[Z]. Proceedings of 10th International Conference on World Wide Web,Hong Kong, 2001.
[2]LI Hang. A short introduction to learning to rank [J].IEICE Transactions on Information Systems, 2011, E94-D(10):1-9.
[3]VOLKOVS M N, ZENEL R S. New learning methods for supervised and unsupervised preference aggregation [J]. Journal of Machine Learning Research, 2014, 15:1135-1176.
[4]PEDRONETTE D C G,TORRES R do S,CALUMBY R T. Using contextual spaces for image re-ranking and rank aggregation[J]. Multimedia Tools and Applications, 2014, 69(3): 689-716.
[5]LIN Shili. Rank aggregation methods [J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(5):555-570.
[6]KUMAR R, VASSILVITSKII S. Generalized distances between rankings [Z]. Proceedings of International Conference on World Wide Web,Raleigh,2010.
[7]KENDALL M. A new measure of rank correlation [J]. Biometrika, 1938, 30:81-89.
[8]CONTRERAS I. Emphasizing the rank positions in a distance-based aggregation procedure[J]. Decision Support Systems, 2011, 51(1): 240-245.
[9]BAEZA-YATES R, RIBEIRO-BETO B.Modern information retrieval [M].New York:ACM Press,1999.
[10]LI Chunguo,MEI Xing,HU Baogang.Unsupervised ranking on multi-attribute objects based on principal curves[J/OL].[2014-02-19].http://arxiv.org/pdf/1402.4542.pdf.
[11]BISHOP C. Pattern recognition and machine learning [M]. New York: Springer, 2006.
(责任编辑:孟素兰)
