一种一维可重构计算系统模型的设计
2016-01-04杜高明,张敏,宋宇鲲等
一种一维可重构计算系统模型的设计
杜高明,张敏,宋宇鲲,张多利,倪伟
(合肥工业大学 微电子设计研究所,安徽 合肥230009)
摘要:文章提出了一种PE个数可配置的一维可重构计算系统模型,设计了PE间3种重构模式和PE内3种重构模式,大大简化了系统配置信息。建立C++描述的周期精确级系统模型,映射复数矩阵乘算法,分析比较不同PE内重构模式、同一PE内重构模式不同PE个数下系统的计算性能。实验结果表明,2-PE系统简单、灵活而高效。
关键词:MPSoC;可重构计算;系统建模;可重构模式
收稿日期:2014-01-06;修回日期:2014-03-21
基金项目:国家自然科学基金资助项目(61106020;61006024);高等学校博士学科点专项科研基金(青年教师)资助项目(20100111120009)
作者简介:杜高明(1977-),男,湖南邵阳人,博士,合肥工业大学副研究员,硕士生导师.
doi:10.3969/j.issn.1003-5060.2015.01.013
中图分类号:TN403文献标识码:A
Designofone-dimensionalreconfigurablecomputingsystemmodel
DUGao-ming,ZHANGMin,SONGYu-kun,ZHANGDuo-li,NIWei
(InstituteofVLSIDesign,HefeiUniversityofTechnology,Hefei230009,China)
Abstract:In this paper, a one-dimensional reconfigurable computing system model is proposed, in which the number of PE can be set. Three modes between PEs and three modes for PE are designed to simplify the configuration information. C++ is used to build the cycle-accurate level system model. Mapping complex matrix multiplication algorithm is used to compare the computing performance between different models for PEs, different models in PE within the same models for PEs. The experimental results show that 2-PE system is simple, flexible and highly efficient.
Keywords:multi-processorsystem-on-chip(MPSoC);reconfigurablecomputing;system-levelmodeling;reconfigurablemodel
在当今的多核片上系统(Multi-processorSystem-on-Chip,MPSoC)研究中,如何面向应用设计高效能、高可用的系统体系结构成为多核时代的研究主题[1]。MPSoC允许将多个不同类型、针对特定应用的处理核心集成在一块芯片中,形成异构MPSoC,因而面对不同应用需求,可以提供较高的灵活性和高效的处理机制[2]。
可重构片上多核系统利用不同粒度、不同耦合度的可重构资源,充分开发资源的并行性,兼顾硬件计算的高性能及软件实现的灵活性[3]。可重构计算弥补了MPSoC灵活性不足的特点,MPSoC对作为异构子系统的可重构计算提出了新要求,简要概括为灵活、简单而高效。
可重构计算处理器具有较高的灵活性与高效性,系统设计空间巨大,设计一个优化的系统结构或得到一个优化的实现方案十分复杂[4]。同时,它集成了多核技术、分布式计算技术、可重构技术等重要前沿技术。其中,作为核心技术之一的重构模式研究具有重要的战略意义[5-7]。自从1960年可重构计算的概念诞生以来,很多可重构体系结构在工业界和学术界陆续被提出,如COPACOBANA、Matrix、GRAP、Elixent、PACTXPP、SiliconHive、Montium、Pleiades、Morphosys、PiCoGA[3]。相比于这些成熟的可重构体系结构,目前可重构片上多核系统方面的研究还比较少。
文献[6]提出了一种动态可重构众核处理器,有效降低众核处理器中的网络负载和访存延时,提高大量并行应用在众核处理器上同时运行的性能;文献[5]设计了一款具有2种重构模式(阵列并行模式和流水模式)的动态可重构协处理器DReAC,通过几种典型算法验证了其性能全面超过了同类其他系统;文献[7]给出了一种基于二维mesh片上网络的可重构处理器阵列模型,通过片上网络来实现任意2个处理单元(ProcessingElement,PE)之间的通信。
图1所示为基于NoC的可重构众核系统模型[8]。PE簇作为可重构节点,通过NoC实现PE簇间的通讯,PE簇内通过Crossbar实现互联。以PE簇的方式可以大大减小PE间通讯的时间开销,因而可以提高系统计算性能。同时,簇内PE间采用重构模式的方式,PE内部同样采用重构模式,可以实现系统快速重构,减少配置信息,提高系统计算性能。

图1 基于 NoC的3×3可重构计算簇阵列
本文在这种背景下,提出了一种面向高密度计算的可重构计算系统模型。该系统模型是基于Crossbar互联的一维线性阵列结构,实现了粗粒度局部动态可配置,提出了PE间3种重构模式和PE内3种重构模式,簇内PE个数可配置。
采用C++语言对可重构计算系统进行系统级描述,建立了可重构计算单元的周期精确级模型。可重构计算处理单元可扩展,通过配置信息来加载应用,验证了系统模型正确性。添加了实时监测网络,映射复数矩阵乘算法。实验结果显示,PE内3种模式下系统计算性能不同,同PE内模式不同PE个数下系统的计算性能不同,在2-PE内重构模式2下,资源利用率为100%,同时具有很好的延拓性,符合最初设计简单、灵活而高效的初衷。
1可重构计算系统结构及系统级建模
1.1 RCU系统结构
可重构计算单元(reconfigurablecomputingunit,RCU)的结构如图2所示,主要由存储器、互联网络和PE构成。为了提高计算系统的并行计算能力,存储器采用双口静态缓存器,有2个独立的地址变量;互联网络由2层Crossbar组成,每层Crossbar由多个多路选择器构成,通过配置多路选择器来实现RAM的任一数据传输到PE的任一输入端口。PE是支持流水操作的处理单元,是RCU的核心计算单元。PE间的通信由Crossbar完成,支持任意相邻2个PE间直接通信。对该系统而言,输入双口RAM为只读,输出双口RAM为只写;对于连接该RCU的网络接口,则输入RAM为只写,输出RAM为只读。

图2 2- PE RCU结构示意图
1.2 PE间可重构模式
本文在一维线性结构的基础上,针对高密度计算的特定算法,提出了3种PE间重构模式,如图3所示。
(1) 模式1。每个PE单独工作,计算结果分别输出存储在RAM中。
(2) 模式2。PE依次两两结合,即PE1的计算结果作为PE2的输入,PE2的计算结果输出存储在RAM中,以此类推,PE个数若为奇数个,最后一个PE单独工作,其他的PE依次两两组合。
转眼40年过去了,改革开放让农场人的日子越过越美。三哥小时挨揍最多,长大却最孝顺,和二老住一起,对他们的饮食格外上心。瞧,整洁的灶台上一溜农场自产的绿色健康菜籽油、大豆油特别显眼。我故意逗他:“馋虫,挑一下,想用啥油炸馒头?不会挨揍哦!”
(3) 模式3。PE以链式结合,即PE1的计算结果作为PE2的输入,PE2的计算结果作为PE3的输入,以此类推,最后一个PE的计算结果输出给RAM。

图3 PE内可重构模式示意图
1.3 PE内可重构模式
本文主要面向高密度计算,PE内部由2个加法器和2个乘法器组成。通过配置,乘法器一个输入端口可以输入常数1,加法器一个输入端口可以进行取负操作,另一个输入端口可以输入常数0,同时带有作累加操作的计数器。在该结构之上,提出了3种PE内可重构模式,如图3所示。
(1) 模式1。2个MUL(乘法器)、2个ADD(加法器)中任意选取2个单独计算,计算结果作为PE输出,计算为1级流水。
(2) 模式2。MUL1和MUL2分别作乘法计算,计算结果输入给ADD1做累加计算,累加的结果输入给ADD2做累加计算,累加的结果作为PE输出,计算为3级流水。
(3) 模式3。MUL1和MUL2分别作乘法计算,计算结果分别送到ADD1和ADD2作自加,自加结果作为PE输出,计算为2级流水。
1.4 周期精确级建模
在图2所示系统结构的基础上,建立了PE可任意扩展的周期精确级RCU系统模型。采用基于接口的建模方法,一次完整的数据流包括4个环节:RAM→ConnectNet→PE→RAM。RAM作为输入数据和输出结果的存储单元,双口RAM的RTL级描述:RAM数据类型参数化定义;RAM深度可配置;有2个独立的地址变量,1次可同时读或写2个数;有read和write信号,分别控制RAM的读和写操作,每个周期RAM只读和写1次数据。互联网络可通过配置信息实现自动互联,互联网络的RTL级描述:由2层Crossbar共同完成,对于包含N个PE的RCU而言,第1层由4个N输入的交叉开关组成,第2层由N个4输入的交叉开关组成。PE可通过配置信息实现加法器和乘法器之间互联,互联方式为PE内3种模式。为了验证模型的正确性,并评估不同配置信息对RCU计算性能的影响,设计了系统监测网络。
2实验及分析
本文通过映射复数矩阵乘算法来分析不同配置策略对计算性能的影响。设置寄存器深度为2K,随机产生若干组32×64和64×32的浮点型复数矩阵,分别作了2组仿真实验:一组为3种PE内重构模式映射复数矩阵乘算法;另一组为同一PE内重构模式下不同PE个数映射复数矩阵乘算法。每次实验记录仿真所用的时间ST(SimulationTime)、计算运行周期MC(MachineCycle)、PE资源占用个数RUN(ResourceUtilizationNumber)以及PE资源利用率RUR(ResourceUtilizationRate)。
2.1 算法映射
可知,复数矩阵乘运算得到的结果矩阵仍为复数矩阵,矩阵元素cij的实部(cr)ij、虚部(ci)ij均通过乘加(或减)再累加得到。以2-PE的RCU为例来说明算法的映射过程,图4所示为2-PE内模式2下计算实部cr的RCU内部数据流。4个输入RAM分别存储复数矩阵A和B实部和虚部,2层Crossbar通过配置信息实现PE输入数据依次为ar、br、ai、bi,PE通过配置信息选择合适的PE间模式、PE内模式,同时配置加法器和乘法器的常数输入、加法器用作减法的取负操作以及用于累加的计数器t。通过设置输入RAM的地址,依次取出复数矩阵A实部ar和虚部ai的第i行和复数矩阵B实部br和虚部bi第j列,加法器计数到n时输出累加值即为待求值cr。ci的求值过程与之相似,在此不再赘述。
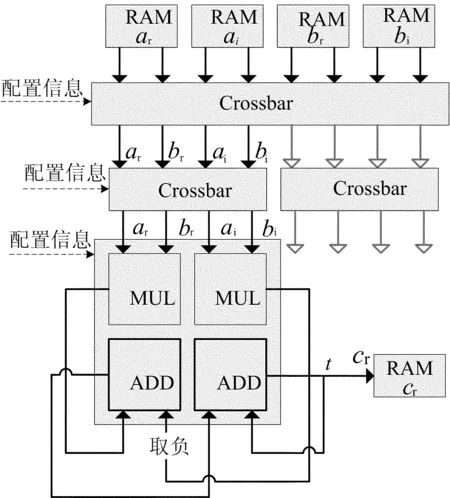
图4 2- PE内模式2下 RCU求解实部c r数据流
2.2 不同 PE内模式下 RCU计算性能分析
通过配置映射复数矩阵乘算法,在3种PE内重构模式下,记录系统计算性能见表1所列。从实验结果可知:模式1的资源占用率最高为50%,以模式1为主要重构模式系统资源不能得到充分利用;模式2拥有最高的资源占用率,处于满负荷工作状态,并且具有最少的仿真时间;模式1的资源占用率为模式2的1/2,计算周期约为模式2的1倍;模式3的资源占用率高于模式1,计算周期与模式1的相当;模式1受工作机制限制,其资源利用率最高为50%;通过增加PE个数,将模式1和模式3组合,以增加50%的资源为代价,提高了资源利用率,计算效率约提高了1倍。由此可知,复数矩阵乘法在该可重构计算系统结构下采用模式2可获得最高的计算效率。
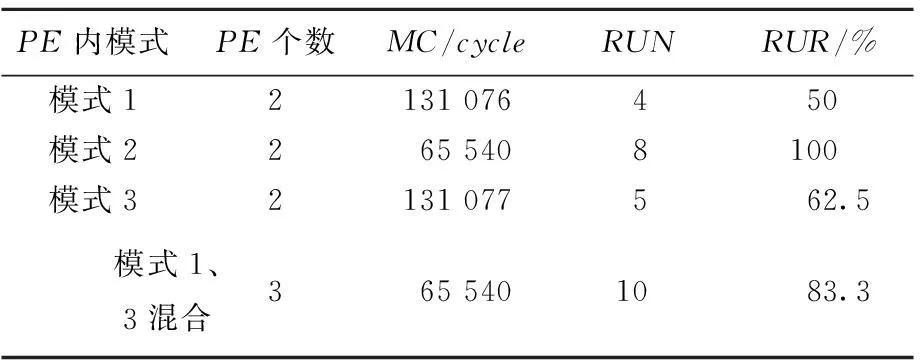
表1 3种 PE内重构模式仿真实验性能
2.3 不同 PE个数下 RCU计算性能分析
通过在不同PE个数、PE内重构模式2下映射复数矩阵乘算法,记录系统计算性能见表2所列。从实验结果可知:系统资源每增加1倍,系统计算效率也成倍增加,系统资源利用率始终为100%。说明针对复数矩阵乘算法,该可重构计算系统在PE内模式2配置策略下具有很好的延拓性。因此,本文提出的可重构计算系统结构在处理复数矩阵乘法运算时,配置策略为PE间重构模式2实现了最高的资源利用率,获得了最高效的计算效率,同时PE处于满负荷工作状态,具有最高的计算性能;在该配置策略下,随着PE资源成倍增加,系统计算性能也成倍增加,因此2-PE可作为最小的RCU系统单元。

表2 不同 PE个数 PE内重构模式2的仿真实验性能
3结束语
本文设计了一种面向高密度计算的可重构计算模型,PE个数可配置,给出了PE间3种重构模式和PE内3种重构模式。通过C++语言对系统进行周期精确级建模,分别对PE内3种重构模式进行复数矩阵乘算法映射,分析比较了不同PE内模式下、同一PE内模式不同PE个数下系统的计算性能。实验结果表明,对于复数矩阵乘法,2-PE系统简单、灵活而高效,满足设计要求。
[参考文献]
[1]严明.面向领域应用的异构多核SoC系统结构设计与优化[D]. 长沙:国防科学技术大学,2011.
[2]杨宏来,黄旻忞.基于SystemGenerator的异构多核片上系统设计[J]. 电子与封装,2012,12(11):27-31.
[3]唐柳,黄樟钦,侯义斌,等.可重构多核片上系统体系结构综述[J]. 计算机工程与应用,2012,48(20):39-45.
[4]孙康.可重构计算相关技术研究[D].杭州:浙江大学,2007.
[5]宋宇鲲.动态可重构协处理器研究[D].合肥:合肥工业大学,2006.
[6]韩兴,蒋江,付宇卓,等.动态可重构众核处理器仿真平台设计[J]. 上海交通大学学报,2013,47(1):44-48.
[7]潘鹏,王鹏,林水生.可重构处理器阵列的系统级建模研究[J]. 微电子学与计算机,2011,28(11):85-89.
[8]侯宁,高明伦,杜高明,等. 二维网格NoC中资源-网络接口设计与实现[J]. 合肥工业大学学报:自然科学版,2008,31(8):1155-1158.
(责任编辑马国锋)
