网络新闻话题演化模式挖掘
2015-12-26赵旭剑张立李波张晖杨春明喻琼
赵旭剑+张立+李波+张晖+杨春明+喻琼+王耀彬


摘要:针对特定主题的新闻话题演化模式挖掘对于话题动态演化研究具有重要的研究意义和应用价值,能帮助人们清晰地梳理话题事件的来龙去脉,直观地展现话题演化轨迹的逻辑结构。针对该需求,本文提出一种面向特定话题的网络新闻话题演化模式挖掘方法,拟从挖掘话题演化逻辑的角度出发,针对特定话题(矿难事件)进行话题演化一般规律的深入分析,对话题演变过程进行阶段化表示,建立话题演化模式。实验结果表明,本文构建的特定话题演化模式具有较强的语义表达能力,符合话题逻辑。
关键词:话题演化;演化模式挖掘;话题聚类;Text Rank
中图分类号:TP391
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.06.001
本文著录格式:赵旭剑,张立,李波,等,网络新闻话题演化模式挖掘[J].软件,2015,36(6): 1-6
Mining of the Topic Evolution Pattern of Network News
ZHAO Xu-jian, ZHANG Li, LI Bo, ZHANG Hui, YANG Chun-ming, YU Qiong, WANG Yao-bin
[Abstract] : Patterns mining for topic evolution of topic-specific news is of great significance and value in the researchon topic dynamic evolution. It can help people clearly sort out topics of the whole story and intuitively show the logicalstructure of the topic evolution track. According to the requirement, this paper proposes a pattern mining method fortopic-specific news evolution. Firstly, this method takes the in-depth analysis to the general rules of the topic evolutionfor the specific topic from the logical point ofview of the topic evolution discovery and then studies the topic evolutionstage representation to establish the topic evolution patterns. Experimental results show that the topic-specific evolutionpattern constructed in this paper has strong semantic expression ability, and accords with the topic logic.
[Key words]: Topic evolution; Evolution patterns mining; Topic cluster; Text rank
0 引言
随着互联网的发展,网络资讯已进入人们生活中的方方面面,而网络新闻更以其独特的魅力在众多传统新闻方式中脱颖而出。网络新闻相比于其他新闻方式具覆盖面广、使用率高、传播效率高与亲和力强等特点,人人可看,人人可说,使得它具有更加深远的影响力。对于新闻话题的发展,从最早话题刚刚兴起时的不成熟,到现在对话题演变研究的不断挖掘,新闻话题目前已经拥有了一定的演化规律,而国内外的研究者们希望通过各种判别分析方式[1-6]再加上大量的同类话题的数据统计分析,总结推导出一套行之有效的新闻话题演化模式,建立一套新闻话题演化的发展模型。新闻话题的演化模式挖掘对于话题动态演化研究具有重要研究意义和应用价值,能帮助人们清晰地梳理话题事件的来龙去脉,直观地展现话题演化轨迹的逻辑结构,对于政府进行舆情监控以及企业进行情报挖掘都有着十分重要的作用。
中文新闻话题演化模式挖掘研究工作大多集中于国内,大致分为两类:基于统计学的模式挖掘[1-3]和基于逻辑分析的模式挖掘[4]。基于统计学的模式挖掘,其优势是与事实契合度高,所有素材源于新闻报道,得出的结论符合分析内容,对于话题的结论可直接使用,针对各个话题得出其特点与热点,比如说2009山西古交煤矿瓦斯爆炸事故,分析之后除了单纯的煤矿事故,还会突出其瓦斯爆炸的事故特点,有着较强的特色分析能力。但其不足的地方是,太过于依赖新闻素材,有时如果报道太过杂乱,会影响其分析结果,容易出现热点重复的问题。基于逻辑分析的模式挖掘,其优势是话题演化形式分析全面,得出结果准确率高,利于分析。但缺点是,分析工作量大,针对比较成熟的话题分析方便,但是对于一个新的专题演化模式的挖掘有着较大难度。
本文结合了两种新闻话题演化模式挖掘的优点,再引入时间模型,在统计的基础上得出初步结论,再结合逻辑分析的方式,添加时间特征,通过多话题演化模式的对比,得出相应话题演化模式模型,增加了分析的准确率,提高了分析的效率。
1 话题演化模型
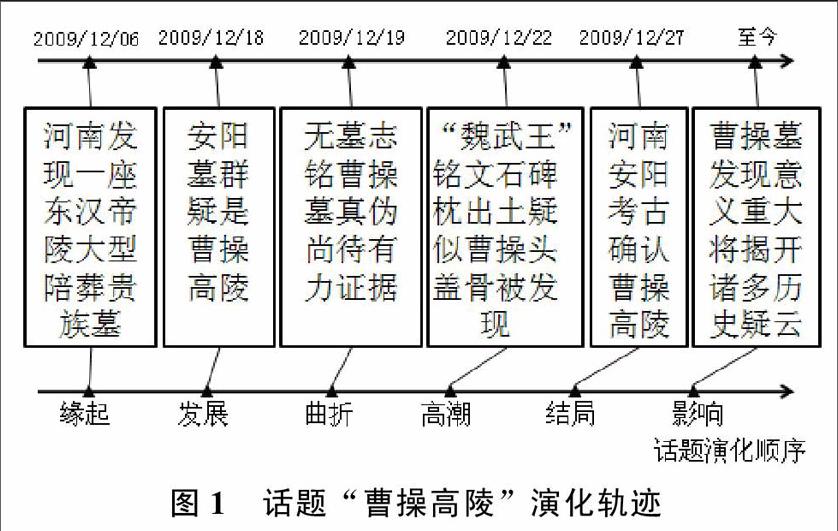
话题演化轨迹可以归纳为不同阶段的话题特征所构成的时间序列,是指一个话题产生后,随着时间的发展,从开始发展到高潮再到衰落,最后直至话题消亡的过程。如图1所示,一个完整的话题演化过程具有与事件发展的时间顺序一致的演化顺序,完全符合人类的逻辑思维方式。因此,针对话题演化模式挖掘问题,我们首先要解决话题演化阶段表示以及话题特征提取两个问题。
1.1 新闻话题聚类
我们采用话题聚类的方法生成话题演化轨迹中的各个阶段,以类簇中的特征来表示当前阶段下话题的内容。对文档进行聚类时,可以根据需要将新闻话题划分成相应数量的类簇。话题演化聚类结束后,将目标新闻话题相关的新闻文档序列组织成一系列类簇,每个类簇代表一个话题演化阶段,而整个新闻文档序列则全面体现了目标新闻话题的演化轨迹。K-means算法是最为经典的基于划分的聚类方法[7,8],K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果[9]。一般都采用均方差作为标准度量函数,如公式1所示。k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开,输出结果是k个类簇的集合。
它假设对象属性来白于空间向量,并且目标是使各个群组内部的均方误差总和最小。假设有k个群组Si,i=1,2,…,k。μt是群组Si内所有元素Xt的重心,或叫中心点。
假设要把样本集分为S个类别,算法描述如下:
(1)适当选择S个类的初始中心;
(2)在第七次迭代中,对任意一个样本,求其到S个中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的S个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
该算法的最大优势在于简洁快速,算法的关键在于初始中心的选择和距离公式,满足本文的文本处理要求。
1.2 话题特征提取
多篇新闻报道聚类后,类簇的核心思想(话题)是由文中的词项来体现。通过词语间的语义关系分析,找出最能代表该类簇核心内容的特征词项。为了弥补传统方法(TF-IDF模型)只计算文中词语词频而没有考虑词项之间语义关系的不足,本文通过构建词项间的Text Rank模型[10],分析多文档间词项的语义关系,抽取出有效关键词。
Text Rank与Google提出的Page Rank非常类似,它本质是在以词汇作为顶点、词之间关联作为带权或无权,有向或无向边的图上进行random walk的过程[11]。Text Rank模型表示为一个带权有向图G=(V,E),由点集合V和边集合E组成,E是VxV的子集,图中两点i,j之间的权重为Wiio。对于一个给定的点Vi,In( Vi)为指向该点的点集合,Out( Vi)为点Vi指向的点集合。点Vi的分数定义为:
其中,d为阻尼因数,取值范围为0到1,代表从图中某一特定点指向其他任一点的概率。在使用TextRank算法计算图中点的分数时,需要给图中的点指定任意的初值并递归计算知道某个词语分数收敛,收敛后每个点都获得一个分数,代表该点在图中的重要性。需要注意,点的最后分数不受给定初值的影响,点的初值只影响该算法达到收敛的迭代次数。根据基于图排序算法的基本理论,可以在具有语义关系的词语之间连线构建Text Rank模型。根据词语之间的相互“投票”,递归计算词语分数,选择分数较大的词语为重要词语,其中不和任何词语有连线的词语为孤立点。例如,“国家养老保险调整”专题新闻文本的词语序列(如下所示),通过Text Rank模型计算得到词项间的关联关系(图2所示)。
保险养老人员单位制度企业事业基金社会保障社保工作参保职工改革退休个人养老金试点管理农民待遇劳动建立农村发放规定机关参加上海推进问题统筹缴纳确保完善实行续保国务院
构建Text Rank模型是根据待选关键词词语之间的语义相似关系大小来决定是否在两个词语之间建立边。因此,Text Rank图是带权无向图,边的权重为两个词语之间的关联度,通过词语间的投票递归计算出权重,关键词的选取按分数序列从高到低选择,选取范围可以根据需要设置。
2话题演化模式构建
构建话题演化模式,我们需要分为两步来进行,第一步,构建同类主题不同话题各白的演化模式;第二步,对各个话题演化模式进行分析与总结,构建统一主题的演化模式。首先,我们对剔除噪声后的关键词提取结果进行分析,看其中是否存在具有代表意义的词语,例如话题“2009黑龙江鹤岗煤矿爆炸”的聚类结果中存在“医院…‘治疗…‘心理…‘巷道…‘弟弟”这几个非常独特的词语,这几个词语在其他聚类结果的关键词提取中不曾出现过,而且在该类簇中的Text Rank值很大,因此,本文定义其为核心词,用以表达该类簇的核心内容。同时,我们结合前期完成的话题时间抽取工作[12],根据文档的话题时间对聚类结果进行二次整合,构建针对单一话题事件的演化模式序列。表1给出了话题“2009黑龙江鹤岗煤矿爆炸”的演化模式生成结果。
将同一主题下不同话题(矿难)的各个专题新闻进行演化模式序列的一致性对比分析,在每个演化阶段提取具有相同或相似语义信息的关键词作为该阶段的“共性词”,然后将这些词组成的集合映射到该话题(矿难)相应的演化阶段,作为该阶段的话题特征,依次处理各个演化阶段,进而构建统一主题的演化模式序列。整个处理流程如图3所示。
3 实验结果及分析
3.1实验环境
本文采用利于分析的典型话题作为实验的原始数据,数据来源于新浪新闻的专题新闻,我们选择矿难专题作为测试话题。数据集包括21个专题、2175篇新闻报道,由于考虑到有些专题报道时间过长、链接失效或是报道相关度较低,本文对数据进行筛选后选用了其中六个篇幅量适中、报道全面的话题(“2009黑龙江鹤岗煤矿爆炸”181篇、“2009山西古交发生煤矿瓦斯爆炸事故”87篇、“2010河南平煤集团平禹四矿矿难”58篇、“2010河南伊川煤矿爆炸”46篇、“2011黑龙江煤矿透水事故”66篇、“2011云南曲靖师宗县煤矿事故”97篇),其他话题的文档作为参考与分析,不参与模型构建。
3.2 实验结果
根据本文的方法,针对六个不同话题事件的矿难专题新闻,我们得到六个话题演化模式挖掘结果,图4、图5分别给出了话题“2009山西古交发生煤矿瓦斯爆炸事故”和话题“2010河南伊川煤矿爆炸”的演化模式序列。
生成了话题演化模式序列后,可以看出并不是每一个话题演化模式的都是一样的,每个矿难话题都有自己的演化特点,但是大致都可以分为事件发生、救援工作展开、家属反映、遇难人数与救援结果以及责任追究这五个方面,同时结合话题时间特征与话题逻辑顺序的分析和理解,我们得到针对矿难话题的基本演化模式:同时,我们以基本演化模式为标准,对六个矿难话题事件的新闻话题演化轨迹进行了实验评测,采用聚类算法的准确率来评测基本演化模式的性能,如表2所示。从实验数据不难发现本文算法得到的基本演化模式具有较好的聚类准确率,对于特定话题的演化轨迹具有较好的语义表达能力,符合话题发展的逻辑顺序。
4结论
本文针对网络新闻话题演化研究的实际需求,提出一种面向特定话题的话题演化模式挖掘方法,从挖掘话题演化逻辑的角度出发,针对特定话题(矿难事件)进行话题演化一般规律的深入分析,对话题演变过程进行阶段化表示,建立统一的话题演化模式。实验结果表明,本文构建的特定话题演化模式具有较强的语义表达能力,符合话题逻辑。
参考文献
[1] 赵华,赵铁军,于浩.面向动态演化的话题检测研究[J].高技术通讯,2006, 16(12): 1230-1235.
[2] Blei D,Lafferty J. Dynamic Topic Models[C]//Proceedings of the International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 2006, 113-120.
[3] Wang X, McCallum A.Topic over Time:A Non-markov Continuous-time Model of Topical Trends[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 2006, 424-433.
[4] 赵旭剑,杨春明,李波,等.一种基于特征演变的新闻话题演化挖掘方法[J].计算机学报,2014, 04: 819-832.
[5] 郑世卓,崔晓燕.基于半监督LDA的文本分类应用研究[J].软件,2014, 35(1): 46-48.
[6] 曾利,李白力,谭跃进.基于动态LDA的科研文献主题演化分析[J].软件,2014, 35(5): 102-109.
[7] 陈磊磊.不同距离测度的K-Means文本聚类研究[J].软件,2015, 36(1): 56-61.
[8] 徐步云,倪禾.白组织神经网络和K-means聚类算法的比较分析[J].新型工业化,2014, 4(7): 63-69.
[9] Yu Bao Liu, Jia-Rong Cai, Jian Yin, Ada Wai-Chee Fu. Clustering Text Data Streams[J]. JCST, 2008, 23(1): 112-128.
[10]陈宏,陈伟.基于突发特征分析的事件检测[J].计算机应用研究,2011, 28(1): 117-120.
[11] Pearson,K.The Problem of the Random Walk[J]. Nature. 1905, 72: 294.
[12]赵旭剑,金培权,岳丽华.TTP: -个面向中文新闻网页的主题时间解析器[J].小型微型计算机系统,2013, 34(5): 1042-1049.
