搜索引擎指标综合特性的评价
2015-12-22吴胜利谭延之施化吉
吴胜利,谭延之,施化吉
搜索引擎指标综合特性的评价
吴胜利,谭延之,施化吉
(江苏大学计算机科学与通信工程学院,江苏镇江212013)
对搜索引擎的检索性能进行评价是信息检索的一个重要方面,目前已经提出和使用许多各有特色的评价指标.对于如何选择出综合特性最优的评价指标,需要准确、可靠的判断方法.文中提出基于t检验的方法,并使用该方法对5种常用的评价指标进行了试验研究,包括平均查准率(average precision,AP)、前10个文档的查准率(precision at10 document level,P@10)、可查全水平查准率(recall-level precision,RP)、第1位相关文档的倒数(reciprocal ranking,RR)、规范化带折扣的累积收益(normalized discounted cumulative gain,NDCG).结果表明NDCG的综合特性最好,其次是AP,然后是RP和P@10,RR最差.对于任意2个评价指标所提出的方法可以给出定量的比较结果.
搜索引擎;检索性能;评价指标;稳定性;敏感性
对搜索引擎的结果进行性能评价是信息检索的重要组成部分,它用以保证准确地判定不同的检索系统、模型、或者其他组件的有效性,是信息检索技术能够不断发展的必要条件.检索评价是一项有挑战性的工作,一般需要投入很多的人力物力;另一方面要得到比较准确的结果也有相当的难度.为了评价一个或多个搜索引擎的有效性,需要一个参考数据集.参考数据集由文档集合、一组查询和相关性判断组成.其中相关性判断是指对于任一个查询,需通过人工判断文档集合中哪些文档是相关的,哪些文档是不相关的.相关性判断又可分为二分相关和多分相关.二分相关是指将文档分成相关和不相关2种情况,如可用数字0表示不相关,数字1表示相关.多分相关是指文档分成n+1(n+1>2)种情况.除了毫不相关的文档(用数字0表示),对于相关的文档还细分为n种情况,比如用数字n表示最相关的文档,n-1表示第二等相关的文档,等等.
到目前为止,人们已经提出了许多不同的评价指标.明确各个评价指标的优劣以及有关特性有利于用户选择与使用,而且有利于对这些指标本身进行改进.在评价指标的特性中,稳定性和敏感性最为重要.对于这个问题C.Buckley和E.M.Voorhees[1]于2000年在ACM SIGIR会议上发表了一篇代表作“Evaluating evaluation measure stability”,对搜索引擎评价指标的稳定性和敏感性进行了试验研究.他们使用TREC(text rEtreival conference,每年由美国国立标准与技术研究所举办)中用过的一数据集(TREC 8 query track)来评估几个评价指标的稳定性和敏感性.所采用的方法是:对于一个给定的评价指标(比如平均查准率,average precision,AP),计算出所有提交的检索结果在该指标上对50个查询的平均得分值;然后设定一个阈值,比如5%,对于任意2个检索结果的平均得分值之间的差异,检查是否大于或小于所设定的阈值(5%).假设共有a对检索结果,其中b对的平均得分值之间的差异小于所设定的阈值,则平局率定义为a/b.而对于平均得分值之间的差异大于阈值的结果对子,则通过如下方法计算误差率:假设2个结果为A和B,且对于所有s个查询A的平均得分值比B多5%或以上.在其中的s1个查询中,A的得分值比B多5%或以上;但在其中的s2个查询中,B的得分值比A多5%或以上(s≥s1+s2).在此情形下,误差率定义为s2/(s1+s2).这是因为总共有s1次单个查询得出的结论和所有查询的平均得出的结论是一致的,而有s2次单个查询得出的结论和所有查询的平均得出的结论是相反的.
误差率和平局率可用以表示评价指标的特性.如果在相同的数据集中用同样的阈值计算出一组评价指标的误差率和平局率,那么就可以用来比较各个评价指标.通常较低的误差率代表较高的稳定性,而较低的平局率代表较高的敏感性.然而评价指标通常在其中一个特性上表现良好而在另一个特性上表现较差.比如,在C.Buckley和E.M.Voorhees的试验中,他们发现前1 000个文档的查全率(Recall@1000)的误差率最低,但是它的平局率高于P@5(前5个文档的查准率)、RP(recall-level precision,可查全水平查准率)、AP和RP.另一方面,P@5的平局率最低,但是它的误差率却高于P@100,AP,RP,P@1000(前1 000个文档的查准率)和Recall@1 000.
在这种情况下,如果同时考虑稳定性和敏感性,则需要一种合适的方法选出综合特性好的评价指标.C.Buckley和E.M.Voorhees的文章已发表十多年,但对于该问题仍一直延用他们的方法,未有更妥善的方法.在统计学中,t检验是一种成熟的统计检验方法,它已被广泛地应用于各种领域中.主要用于比较2个样本均值的差异性.笔者意识到该方法也可用于评估2种或多种评价指标,它可有机地将稳定性和敏感性糅合在一起.t检验具有理论性和系统性强、计算过程简单、结果可靠的特点.该方法不仅能应用于二分相关的情形,也能应用于多分相关的情形.这是文中主要创新之处.
1 研究背景
在信息检索领域,对搜索引擎的检索结果进行评价是很关键的问题.人们提出了许多评价指标,而其中一些评价指标在研究试验中以及一些信息检索评价活动(比如TREC,CLEF等)中经常被使用到.
为了研究评价指标的特性,C.Voorhees和E. M.Buckley[1]通过对评价指标的稳定性和敏感性的研究来衡量评价指标的优劣.T.Sakai[2]使用同样的试验方法研究了基于多值相关的一组评价指标.Lin Weihao和A.Hauptmann[3]对C.Voorhees和E.M. Buckley的试验方法给出了理论上的意义.
Wu Shengli和Sally McClean[4]通过对多个TREC数据集的试验,研究了非完整相关判断情况对评价指标的评价质量的影响.文中通过对基于多分相关的评价指标的误差率和平局率进行线性组合以得到综合特性最好的评价指标.
t检验、Wilcoxon检验和sign检验均可用于判断2组结果之间的差异是否在统计意义上显著.J.Zobel[5]发现t检验比Wilcoxon检验和sign检验更可靠.因此文中试验中选用了t检验而不是其他的统计方法.
近年来对检索评价的研究一直很活跃.如文献[6]讨论如何评估检索结果的多样性与新颖性,文献[7]和[8]讨论如何评估多样化的检索结果.多样化的检索结果是指结果中不仅有文字信息,也包含声音、图像等.文献[9]探讨了支持交互式信息检索的评估问题,文献[10]讨论了信息检索系统的基于概念和伪相关性反馈的性能评估,文献[11]介绍了一种通过减少性能评估的风险以达到优化信息检索系统的方法.
为便于阅读,下面对5种评价指标的扩充形式进行简单的介绍,使它们能适用于多分相关的情况.对于一给定的查询,一查询结果包含一派序的文档序列<d1,d2,…,dm>.理想结果是指结果中所有文档根据相关度从高向低排列,此时各种评价指数会达到最大值.以下数学式子中的gr(di)是指搜索引擎返回的结果列表中第i个文档di的相关度.

式中:tj为第j个相关文档在结果列表中的位置;为位置ti之前所有文档的相关度之和;为理想结果中位置tj之前所有文档的相关度之和;total-n为文档集合中所有相关文档的数目.且有:

式中n为最大相关度.而且

在一个结果中,如相关度为n的文档第1次出现的位置为tn,相关度为n-1的文档第1次出现的位置为tn-1,…,相关度为1的文档第1次出现的位置为t1,则RR可定义为
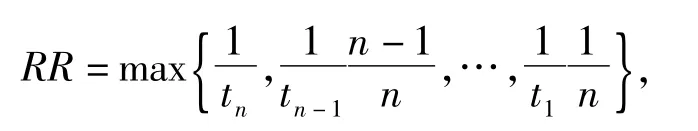
函数max(v1,v2,..,vn)返回集合中最大的值.

式中:m为结果列表中所要考虑的文档数;wi为与位置有关的权值,如i≤2,则wi=1,否则DCG-best则为DCG在所属查询中的最大可能取值,亦即DCG-best是理想结果的DCG值,文中用它来规范化DCG的值.可以验证当相关度为2时,除去NDCG(normalized discounted cumulative gain,规范化带折扣的累积收益)外的4个评价指标即蜕化为原先定义的形式.以上所介绍的AP,P@10和RP在[4]中给出,而NDCG由K.Järvelin和J. Kekäläinen在文献[12]中提出.
2 试验环境和试验方法
t检验是用t分布理论来推论差异发生的概率,从而比较2个样本平均值的差异是否显著.t检验分为单总体检验和双总体检验.双总体t检验是检验2个样本平均值与其各自所代表的总体的差异是否显著.双总体t检验又分为2种情况,独立样本t检验和配对样本t检验.本试验采用配对样本t检验,即为
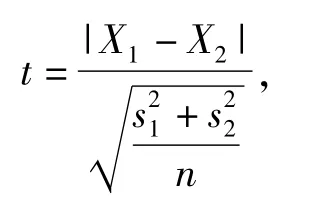
式中:X1和X2为样本平均值;和分别为2个样本方差的无偏估计;n为样本容量.对于一个给定的显著性水平(比如0.05),可以计算出t的值来观察2个样本的平均值之间的差异是否显著.
试验使用TREC中的4个数据集,他们是一些研究组提交到TREC 2000 web track,TREC 2004 robust track,TREC 2008 blog opinion track和TREC 2012 medical track的结果.所有这些数据集来自不同的年份,所用的文档集合不同,所涉及的任务类型不一样,所采用的查询数目也有较大差异.另外,TREC 2000和TREC 2012支持三分相关,文档分为高度相关、低度相关和不相关3种情况;而另2个数据集只支持二分相关.TREC 2008 blog opinion track将相关文档按照意见的观点分成正向、反向、混合等几种情况.这里无需区分,只作二分相关处理.这些数据集的异构特质有利于判别所试验方法的健壮性.在提交的结果中,有一些性能很差,几乎未检索到任何相关文档.这些多是由于在运行一些搜索引擎系统时出现了这样或那样的错误.为避免这些非正常的数据影响试验结果的准确性,除去了一些提交的结果(评价指标AP的平均得分值小于0.05者).此外,在数据集TREC 2012中,有3个查询没有检索出任何相关文档,TREC 2004中,有1个查询没有检索出任何相关文档,在试验中也去掉了.这样最终选择的试验数据集的情况如表1所示.
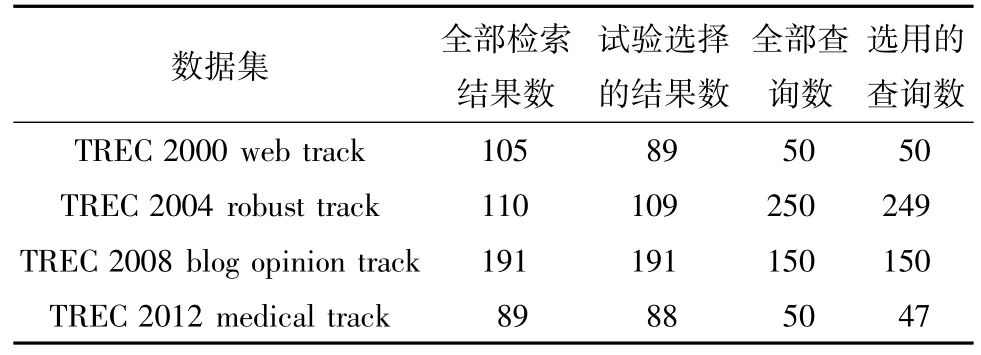
表1 试验中所用的4组数据的信息
文中在二分和三分相关情况下对5种评价指标进行试验,它们是AP,RP,NDCG,P@10和RR.试验方法如下:
1)首先在一个数据集中,对所有的检索结果使用一给定评价指标(比如AP)计算出其在每个查询上的得分值.比如在TREC 2000中,使用评价指标AP计算出结果acsys9mw0在查询1和查询8下的得分值分别为0.569 8和0.135 6.
2)对于数据集中的所有检索结果,两两之间进行配对.比如在数据集TREC 2000中,因为试验用到的检索结果总共有89个,所以总共有89× 88/2=3 916个配对.
3)对于每个配对结果和给定的显著性水平(比如0.05),使用配对样本的t检验进行分析计算,观察2个检索结果用所给定的评价指标评价出的有效性之间的差异是否显著.比如在TREC 2000中,对acsys9mw0和apl9all的2组50个AP得分值之间使用双尾的t检验计算.结果为0.042,小于显著性水平0.05,所以acsys9mw0和apl9all(基于50个查询的AP平均值)之间的差异在0.05水平上是显著的.
4)在得到所有配对结果之间的t检验值后,计算出有显著性差异的检索结果配对所占的比例.比如在TREC 2000中,显著性水平为0.05时,使用评价指标AP得出有显著性差异的检索结果对所占的比例为56.19%,而使用评价指标P@10得出有显著性差异的检索结果对所占的比例为49.68%
5)分别在15个显著性水平下重复以上步骤.它们是0.001,0.002,0.003,0.004,0.005,0.006,0.007,0.008,0.009,0.010,0.015,0.020,0.025,0.050,0.100.
6)分别使用AP,P@10,RP,RR,NDCG这5种评价指标重复以上步骤.
7)分别在4个数据集TREC 2000 web track,TREC 2004 robust track,TREC 2008 blog opinion track和TREC 2012 medical track中重复以上步骤.其中TREC 2000和TREC 2012为二分相关情形,而TREC 2000和TREC 2012采用二分相关和三分相关2种情形.采用二分相关时将高度相关和低度相关均视作相关.
通过以上步骤可以计算出有显著性差异的配对结果所占的比例.一方面有显著性的差异表明该指标可准确地评价检索结果和比较不同的检索结果,即为稳定性的保证;而另一方面,所占的比例高说明了该指标区分检索结果有效性的能力明显,即为高敏感性,因此,通过该试验可以综合考虑这2方面以判断评价指标的好坏.
3 试验结果
第2节中所述试验结果如图1所示.

图1 在6个数据集上5种评价指标的综合特性曲线
在图1的6组数据曲线中,可以观察到在最上面的曲线始终是评价指标NDCG,其次是AP,然后是RP和P@10,RR始终在最下面.只有1处例外.在2000 web track数据集上采用二分相关时,RP和P@10的曲线非常接近.这说明了如果同时考虑评价指标的稳定性和敏感性,那么NDCG是综合特性最好的评价指标,其次是AP,然后是RP和P@10,RR最差.从另一方面说,RR只考虑一个有关的文档,P@10只考虑排在前10位的文档,而其余3个要考虑更多的文档,各指标所需的代价差异很大,所以这样的结果并不意外.
进一步还可以量化出评价指标之间的优劣,比如在数据集TREC 2000 web track数据集上采用二分相关时,当显著性水平为0.05时,使用NDCG和P@10得到的百分比结果分别是68.30和53.68,因此,在这个试验环境下,NDCG的综合特性比RP好27.24%(因为(68.30-53.68)/53.68=27.24%).
另外,笔者也希望知道查询的数量是否对于评价指标的综合性能有影响.一个较为合理的假设是:如果查询数量越多,结果会越可靠.在选择数据集时,笔者就对于此方面有所考虑,所选4个数据集中查询数量不等,从最少的47个到最多的249个(见表1).由于在4个数据集上的结果相似,所以认为结果是比较可靠的.由于TREC 2004数据集上有249个查询,可以进一步在该数据集上进行试验观察.
试验的方法是:对于TREC 2004中的249个查询,笔者将它们分成2,3,5,10等份.如为3等份时,每一个含83个查询.在其他情形,其中一份较其他的等份少一个查询.对于每一份中的查询,按前述方法进行试验.图2显示该试验的采用AP的结果.图中的曲线显示的是所有等份的平均值.对于其他的评价指标,结果相似所以未给出.

图2 在TREC 2004 robust track数据集上AP指标的综合特性曲线
从图2可见,分成的等份越多,查询数越少,则对于给定的显著水平,较少对子之间的差异能达到.这和之前的假设是一致的,因此可认为该假定成立.
4 评价指标的得分困难度
对于同样的结果,每一种评价指标计算得分的方法不同,因此得分能力也就不同,笔者将采用这种评价指标的得分能力定义为该评价指标的得分困难度.当对同样的结果进行评价时,使用困难度较大的评价指标进行评价得到的值较低,而使用困难度较小的评价指标进行评价后得到的值较高.进行这样的研究可有助于在不同的检索评价间的交叉比较,尤其是采用不同的评价指标或采用不同的数据集时.例如,对于数据集C1,一组查询Q1,检索结果集R1,采用评价指标I1在所有查询中的平均得分为S1;对于数据集C2,一组查询Q2,检索结果集R2,采用评价指标I2在所有查询中的平均得分为S2.如要比较R1和R2,则要找到S1和S2可比较的方法.为了计算出各评价指标的困难度指数,笔者仍采用前述4个数据集.试验方法如下:
1)首先在一个数据集中,对检索结果R1中的第1个查询结果r11使用一评价指标(比如RP)计算出其得分值,记为a11;继续对此检索结果的第2个查询的结果r12使用此评价指标计算出其得分值,记为a12;依次类推,可得到此搜索引擎对于所有查询的得分值,即a11,a12,a13,…,a1n,其中n为查询个数.
2)对于此数据集中的每个搜索引擎重复步骤a),这样可以得到基于此评价指标的所有搜索引擎的结果R1,R2,…,Rm在所有查询中的得分值.
3)计算出此数据集中第1个搜索引擎的结果R1应用此评价指标的得分值:,第2个搜索引擎的结果R2应用此评价指标的得分值:,直到最后一个搜索引擎的结果Rm应用此评价指标的得分值:,,其中m是搜索引擎的个数,n是查询个数.
5)分别使用AP,P@10,RP,RR,NDCG这5种评价指标重复以上步骤.
6)分别在不同的数据集中重复以上步骤,试验的最终结果如表2所示.
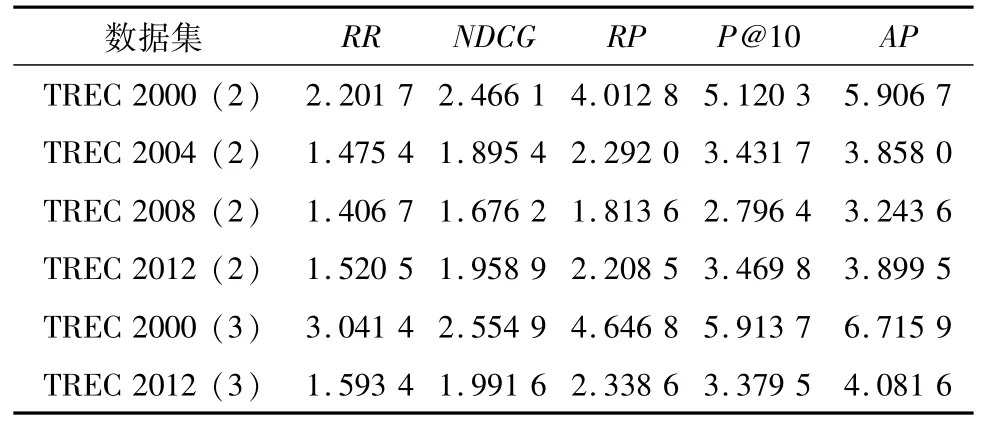
表2 5种评价指标的困难度指数
从表2可见,在所有6个数据集中,RR的困难度最低,其次是NDCG,RP和P@10,困难度最高的是AP.唯一的例外是TREC 2012中采用三分相关的情形.此时NDCG的困难度大于RR.当然,在各个数据集中,同一评价指标的困难度并不相同.这是因为在各个数据集中,文档集合中的文档不同,特别是所用的查询不同,查询的难易程度不同,这会对所有指标的得分值有直接影响.要比较不同数据集中的搜索引擎的性能,需要考虑查询的难易程度.参考文献[13]中给出了一些估计查询复杂度的方法.
5 结 论
2)试验结果表明综合考虑敏感性和稳定性,NDCG是最好的评价指标,其次是AP,然后是RP和P@10,RR最差.同时,也可以量化出各评价指标之间的优劣.
3)文中提出了困难度的新概念,它反映了用一指标做检索评价所需的代价.试验结果表明困难度从低到高的次序是RR,NDCG,RP,P@10,AP.
4)综合考虑敏感性、稳定性和困难度,NDCG是最好的评价指标,它困难度较低,敏感性和稳定性很好.
(
)
[1] Buckley C,Voorhees E M.Evaluating evaluation measure stability[C]∥Proceedings of the23rd International ACM SIGIR Conference on Research and Development in Infornation Retrieval.Athens,Greece:ACM,2000: 33-40.
[2] Sakai T.Evaluating evaluation metrics based on the bootstrap[C]∥Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Seattle:ACM,2006:525-532.
[3] Lin W H,Hauptmann A.Revisiting the effect of topic set size on retrieval error[C]∥Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Salvador,Brazil:ACM,2005:637-638.
[4] Wu Shengli,McClean Sally.Evaluation of system measures for incomplete relevance judgment in IR[C]∥Proceedings of 7th International Conference on Flexible Query Answering Systems.Milan,Italy:Springer Verlag,2006:245-256.
[5] Zobel J.How reliable are the results of large-scale information retrieval experiments?[C]∥Proceedings of the 1998 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Melbourne,Vic.,Aust:ACM,1998:307-314.
●用有机硅功能肥与硅谷农科院培育的“硅谷829”高产小麦新品种,在2017年试验田亩产达到974公斤,创中国小麦历史最高纪录。
[6] Clarke C L A,Craswell N,Soboroff I,et al.A comparative analysis of cascade measures for novelty and diversity[C]∥Proceedings of the 4th ACM International Conference on Web Search and Data Mining.Hong Kong:ACM,2011:75-84.
[7] Zhou K,Lalmas M,Sakai T,et al.On the reliability and intuitiveness of aggregated search metrics[C]∥Proceedings of the 22nd ACM International Conference on Information and Knowledge Management.San Francisco:ACM,2013:689-698.
[8] Chuklin A,Schuth A,Hofmann K,et al.Evaluating aggregated search using interleaving[C]∥Proceedings of the22nd ACM International Conference on Information and Knowledge Management.San Francisco:ACM,2013:669-678.
[9] Belkin N J.Supporting and evaluating whole-session interactive information retrieval[C]∥Proceedings of the MindTheGap′14Workshop,2014.
[10] Abderrahim M A.Concept based vs.pseudo relevance feedback performance evaluation for information retrieval system[J].International Journal of Computational Linguistics Research,2013,4(4):149-158.
[11] Dinçer B T,Ounis I,Macdonald C.Tackling biased baselines in the risk-sensitive evaluation of retrieval systems[C]∥Proceedings of the 36th European Conference on Information Retrieval.Amsterdam,Netherlands:Springer Verlag,2014:26-38.
[12] Järvelin K,Kekäläinen J.Cumulated gain-based evaluation of IR techniques[J].ACM Transactions on Information Systems,2002,20(4):422-446.
[13] Hauff C,Hiemstra D,de Jong F.A survey of pre-retrieval query performance predictors[C]∥Proceedings of the 17th ACM Conference on Information and Knowledge Management.Napa Valley:ACM,2008:1419-1420.
(责任编辑 梁家峰)
Evaluation on metric characteristics of search engines
Wu Shengli,Tan Yanzhi,Shi Huaji
(School of Computer Science and Communication Engineering,Jiangsu University,Zhenjiang,Jiangsu 212013,China)
Performance evaluation of search engines is an important aspect of information retrieval.Many evaluation metrics have been proposed with different characteristics.Accurate and reliable judgment is required to select an optimal metric among many candidates.Based on t test,a method was proposed,and empirical investigation was conducted to compare five commonly used metrics of average precision(AP),precision at 10 document level(P@10),recall-level precision(RP),reciprocal ranking(RR)and normalized discounted cumulative gain(NDCG).The results show that NDCG is the best,which is followed by AP,RP and P@10 with the worst of RR.The proposed method is able to provide quantitative conclusion for the comparison of any two metrics.
search engine;retrieval performance;evaluation metric;stability;sensitivity
TP311.135
A
1671-7775(2015)02-0181-06
吴胜利,谭延之,施化吉.搜索引擎指标综合特性的评价[J].江苏大学学报:自然科学版,2015,36(2):181-186,214.
10.3969/j.issn.1671-7775.2015.02.011
2014-07-16
江苏特聘教授项目;江苏大学特聘教授启动基金资助项目
吴胜利(1963-),男,江苏南京人,教授,博士生导师(swu@ujs.edu.cn),主要从事数据库与信息系统研究.谭延之(1989-),男,安徽合肥人,硕士研究生(1585579087@126.com),主要从事数据库与信息系统研究.
