孤立词语音识别算法研究与设计
2015-12-20吴佳龙
吴佳龙,李 坤,刘 中
(西安电子科技大学电子工程学院,陕西西安 710071)
在孤立词语音识别中,主要的研究方法有动态时间规整(Dynamic Time Warping,DTW)算法、隐马尔科夫模型(HMM)和人工神经元网络等。但HMM算法复杂,需通过反复计算才能得到模型参数。而DTW算法是语音识别中出现最早、较为经典的一种算法,该算法的训练中无需额外计算,且在孤立词语音识别中,DTW算法与HMM算法在相同环境条件下,识别效果相差较小。另外,MFCC的提出对语音识别做出了重大贡献,该算法模拟人耳处理语音的机制,具有较好的鲁棒性和识别效果,成为语音识别系统中的主要特征参数[1]。文中使用梅尔倒谱系数作为特征参数,采用动态时间规整技术进行模式匹配,是孤立词语音识别的有效解决方法。
1 语音识别系统基本原理
孤立词语音识别的本质为模式识别,其基本算法框架如图1所示[2]。包括对语音信号的预处理单元、端点检测单元、特征参数提取单元、参考模板库建立单元和模式匹配单元等。
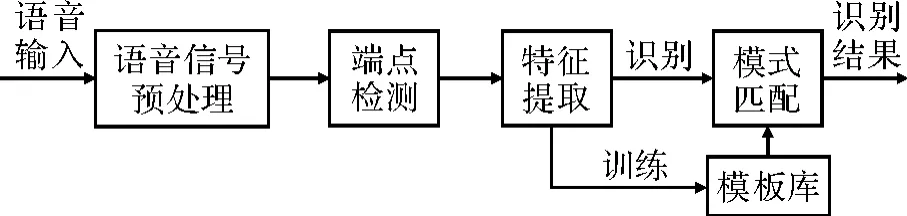
图1 非特定人孤立词语音识别算法框架
图1中,预处理单元对输入语音进行数字化和高通滤波处理;端点检测单元使用短时能零差分法判断语音信号的始末点,获得真实语音信号;特征参数提取单元则采用 Mel倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)提取能代表语音最基本特征的参数;参考模板库建立单元通过基于平均路径长度的训练方法,建立参考特征参数模板库;模式匹配单元,指通过动态时间规整技术(Dynamic Time Warping,DTW)计算测试特征参数与参考特征参数之间的欧式距离,以获得识别结果。
2 孤立词语音识别算法设计
2.1 语音端点检测原理
传统的端点检测算法通过判断语音信号帧的短时能量或短时平均过零率阈值来判定语音帧的起始点和终止点。文中使用一种改进的结合短时能量和短时平均过零率差分阈值的端点检测算法,即短时能零差分法。
用En表示第n帧信号 xn(m)的短时能量,如式(1)所示,En为由信号幅度值平方决定的函数[2]
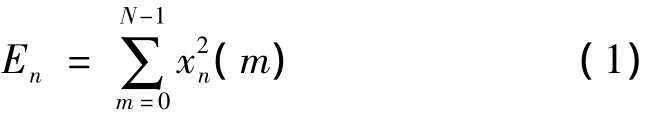
用Mn表示短时平均幅度函数,如式(2)所示,Mn仅由信号幅度值决定,信号中噪声的影响明显减小
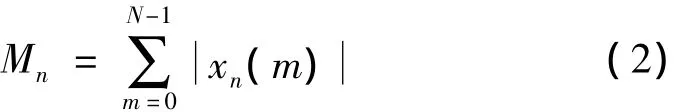
一帧语音信号中波形通过零电平的次数称为短时过零率。过零率在语音信号中表现为,高频段的过零率相比低频段高,因此用短时平均过零率对清音和浊音进行区分。第n帧信号xn(m)的短时过零率Zn如式(3)所示
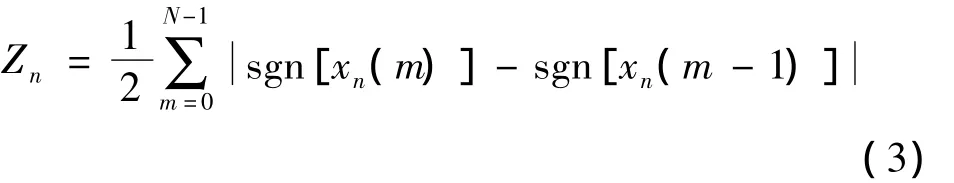
式中,sgn[]是符号函数,即
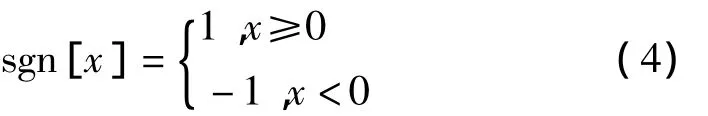
语音信号帧的非语音部分,短时能量Mn和短时平均过零率Zn变化缓慢,而在非语音和语音的过渡部分这两个参数的变化急剧增大,因此通过判断这两个参数便可找到语音信号的起始点和终止点[5]。语音信号有清音和浊音之分,浊音的短时能量和短时过零率特征均较为明显,而清音信号只有短时过零率变化明显。因此,本文采用短时能零差分法进行端点检测,算法的基本框架如图2所示。

图2 短时能零差分法框架
短时能零差分法检测步骤如下:
(1)对输入的语音信号预处理,并根据语音信号的短时平稳性进行分帧,每帧长度为32 ms。
(2)分别计算前5帧语音数据的平均短时能量Pa和平均短时过零率Pb。
(3)假设短时能量差分的高、低阈值分别为ε2、ε1,短时平均过零率差分的阈值为γ1。
寻找边界点:
(4)从语音信号的第6帧数据开始,每5帧组成一组(如第6~10帧为一组,第11~15为一组等),将每组最后1帧(如第10帧,第15帧等)的短时能量与Pa求差分,得差分值m。将m与短时能量差分的低阈值相比较,若m<ε1,则说明还未进入有效语音部分,重复执行第(4)步骤;若差分值m>高阈值ε2,则表明该帧已是有效语音帧,接着执行步骤(5)寻找该组中具体有效语音部分的真正起始点;若ε1≤m≤ε2,则按m<ε1处理,即认定尚未进入有效语音段。
(5)向前搜索。将第(4)步中找到的语音信号起始点所在组的每一帧数据的短时能量均与Pa求差分,得出差分值m,并将m与低阈值ε1相比较,若m>ε1,则认为该帧确定进入语音段。同时,为了防止漏检清音起始点,需向前计算每一帧数据的短时平均过零率与Pb的差分值n,也将n与过零率差分的阈值γ1比较,若n<γ1的帧位置为X,即可认为该帧为本次输入语音的起始点。若该组中每一帧的n值均>γ1,则需继续向前搜索,直至找出语音信号的真正起始点为止。
(6)向后搜索。查找语音信号的结束点。继续向后计算每组数据最后一帧的短时能量与Pa的差分值m,若m<ε1,即可认为该帧数据为语音信号的终止点Y。
判断端点:
(7)根据以上步骤得出的数据计算语音信号的长度L=Y-X,然后与预先设置的语音信号段的最小长度Lmin相比较,若L<Lmin,则认为X到Y是一个脉冲噪音段,重新执行步骤(4),从Y的下一帧组数据开始继续检测语音信号起始点。若检测到的语音信号长度L大于最小长度Lmin,则此时的段就是有效语音段。
将语音数据“救命”通过Matlab进行端点检测算法的仿真,图3所示为其端点检测结果。
如图3所示,语音信号被准确的分为了两个字,除去了无语音信号段,检测出有效语音信号,且频谱前后基本无变化。
2.2 MFCC特征参数提取
孤立词语音信号的特征参数提取是指根据某种算法从语音信号中提取出能表征该语音信号最基本特征的参数。提取特征参数的目的是去掉冗余的、无用的信息及噪声,仅保留能反映语音特征的最基本信息,以实现对孤立词语音信号的识别。
描述语音信号特征时,需考虑人耳的听觉特征。耳蜗是人耳的主要组成部分,其本质类似一个滤波器组,且在对数频率单位上实现其滤波性能。临界频率带宽随着频率的变化而变换,频率在0~1 kHz时,为线性尺度,带宽约为100 Hz;1 kHz以上则为对数尺度。考虑到人的听觉感受,定义新的接近耳蜗特性的梅尔(Mel)频率为单位[3]。Mel频率与线性频率Hz的关系为
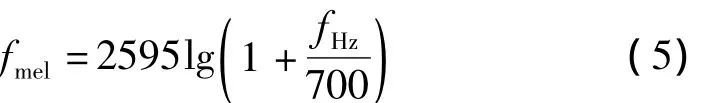
Mel频率和物理频率的坐标图,如图4所示。
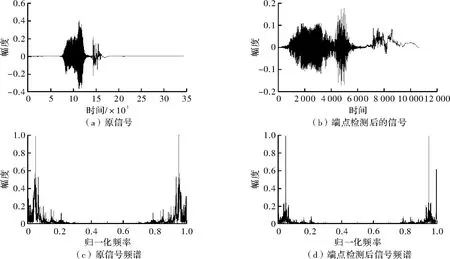
图3 基于短时能零差分法的“救命”端点检测结果

图4 Mel频率与物理频率坐标图
Mel滤波器组,如图5所示。其是语音频谱范围内设置的若干带通滤波器hm(k),m=1,…,M;k=0,…,N/2。其中,M为滤波器的个数,N为一帧语音信号中的采样点数,该滤波器的传递函数如式(6)所示。
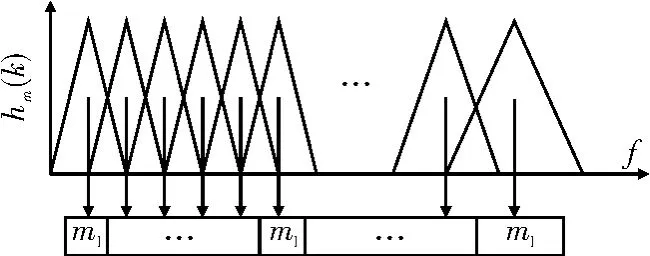
图5 Mel频率滤波器组
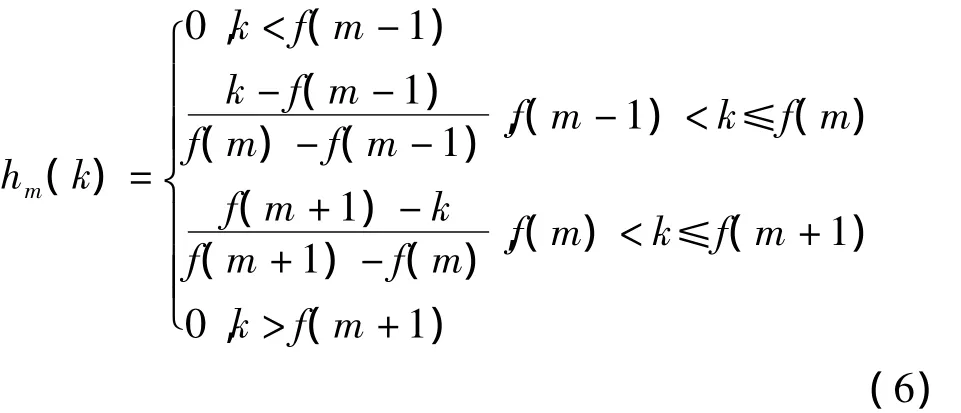
其中,f(m)为中心频率,计算公式如式(7)所示
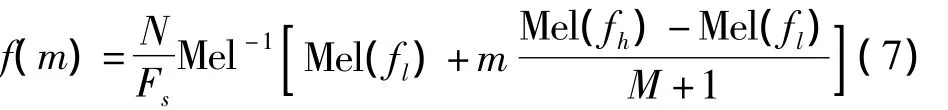
式中,Fs为采样频率;fl和fh为滤波器组的最低频率与最高频率;M为滤波器组的数目。
MFCC参数提取具体计算过程如下:
(1)根据式(5)将实际物理频率转化成Mel频率。
(2)对输入语音帧进行端点检测后作FFT变换得到其频谱,将时域信号转化为频域信号。

(4)对所有三角形带通滤波器的输出求对数,并做DCT变换,得到MFCC
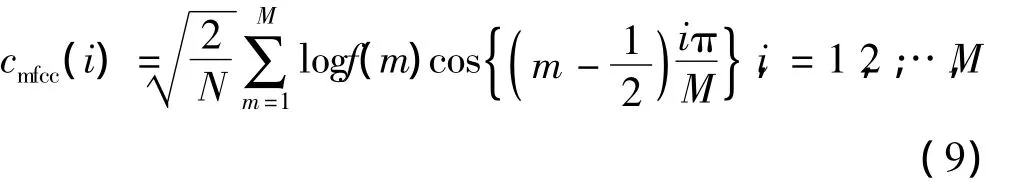
图6所示为孤立词语音信号“救命”所提取的MFCC特征参数。
2.3 DTW 算法的原理与实现
动态时间规整(DTW)技术利用动态规划方式,将繁杂的全局优化问题转换为多个局部优化问题进行解决[7]。对于有M帧数据矢量参考模板R和有N帧数据的矢量测试模板T,各帧号组成一个网格,网格中的任何一个交叉点(n,m)均表示测试模板与参考模板的匹配比较点,且该交叉点语音信号帧的失真度为d(T(n),R(m)),路径通过的所有交叉点组合成测试模板与参考模板的总距离。动态时间规整法的搜索路径,如图7所示。
DTW遵循一定的搜索规则,根据语音信号在时间上的连贯性,认为所有路径均是从第一帧出发,即m=n=1,然后在(N,M)结束。路径中间各点的斜率必须约束为η为0、1/2、1或2。由此可知,若路径通过格点(ni-1,mi-1),则将要通过的下一个格点(ni,mi)为式(10)中3种情况的一种
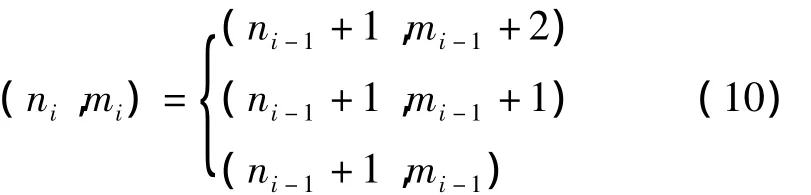
最优路径为在满足约束条件的基础上,计算路径累计距离的最小值,即满足
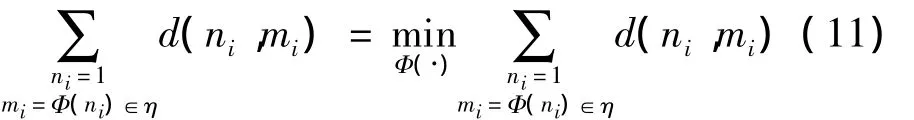
最优路径通过在匹配过程中限定弯折斜率来实现。如图8所示,先作出一个菱形,圈出可能计算的点来节省计算时间,同时也能减少存储空间。

图8 DTW匹配约束条件
DTW算法的实现步骤如下:
(1)假设M<N,将曲线分成三折,拐点分别为(1,X),(X+1,X)及(X+1,N)。其中,X=(2M-aabbaN),X=(2N-m);X、X均四舍五入取整。若测bab试模板与参考模板的帧长不符合(8)所列规则,则可不用计算该模板,即距离不匹配

(2)按式(13)和式(14)计算 Y 轴上[ymin,ymax]
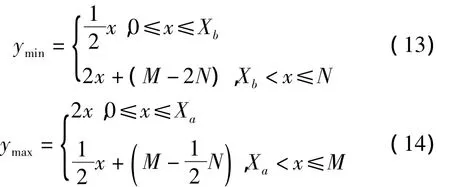
(3)由式(15)计算出当前帧的最小累计距离
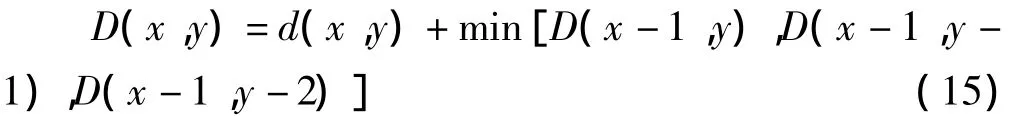
由于在X轴上前进一帧,只用到之前帧的累计距离,因此只需用矢量D保存前列帧的累计距离,用矢量d保存当前列数据的累计距离。每前进一帧数据均需要更新,按照式(15)将前一列数据的累计距离D(x,y)和当前列所有帧数据进行匹配,获得匹配距离d(x,y),即可计算出当前语音帧的累计距离并存于矢量d中。然后将新的累计距离d赋给D,作为新的累计距离,在下一列帧计算累计距离时使用。如图9所示,循环执行到X轴上的最后一列数据,则矢量D的第M个元素便是参考模板与测试模板间动态时间弯折的最小匹配距离。
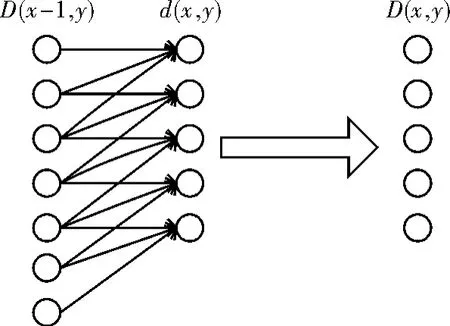
图9 累积距离的动态更新图
2.4 模板训练
文中使用一种基于平均路径长度的训练方法,该方法为每个孤立词筹备N(N≤10)个语音样本,计算这N个语音样本的特征参数矢量沿DTW的平均路径长度。设置初始参考模板,其路径长度最接近平均路径长度;对其余模板在DTW中进行匹配,保证这些矢量模板的路径长度和初始参考模板相同。最后计算每帧中已成功匹配模板的均值,即可获得参考模板。
最终参考模板的计算过程如下:
(1)初始参考模板与第一个模板相匹配,计算出最佳规整函数 w(i),1≤i≤I。
(2)从最后一帧数据开始向前搜索,直至第一帧,在w(i)上寻找每帧信号先前可能通过路径的斜率,有3种可能:1)斜率为1。语音信号帧保持不变。2)斜率为2。重复的语音信号帧,即w(i-1)与w(i)表示相同帧。3)斜率为0.5。计算两个连续语音帧的平均值,即w(i-1)与w(i)的平均值。
(3)对其余的语音参考模板重复步骤(2),得到长度相同的一组模板。
(4)对按以上方法求得的每帧语音信号中的模板计算均值,即可获得最终参考模板。
3 结束语
文中主要对孤立词语音识别系统中各个模块进行研究及Matlab仿真。从断点检测看出,该方法能准确检测出起始点和终止点,为信号的特征参数提取做准备工作;而特征参数提取通过MFCC算法也能较好地提取对信号识别的参数值;研究了DTW算法的原理与实现,通过对一些孤立词语音进行识别验证,证明了该系统在实际应用中具有较好的可行性。
[1]杨熙.基于DSP的非特定人孤立词语音识别系统的研究和设计[D].长沙:湖南大学,2007.
[2]潘夏英.图像边缘检测技术的研究[D].西安:西安科技大学,2011.
[3]丁爱明.作为说话人识别特征参量的MFCC的提取过程[J].信息化研究,2006,32(1):51 -53.
[4]王炳锡,屈丹,彭煊.实用语音识别基础[M].北京:国防工业出版社,2005.
[5]魏峰.特定人孤立词语音识别方法的研究[D].长沙:湖南大学,2007.
[6]孙振超.基于FPGA的说话人识别系统设计与实现[D].武汉:武汉理工大学,2012.
[7]刘长明,任一峰.语音识别中DTW特征匹配的改进算法研究[J].中北大学学报:自然科学版,2006,27(1):37-40.
