基于BoW模型的油茶害虫图像分类
2015-12-20谢林波余绍军周国英
谢林波,余绍军,周国英,李 虹
(中南林业科技大学,湖南 长沙 410004)
基于BoW模型的油茶害虫图像分类
谢林波,余绍军,周国英,李 虹
(中南林业科技大学,湖南 长沙 410004)
针对目前图像识别在油茶害虫这个领域的应用中存在的问题,提出一种基于BoW模型的油茶害虫图像识别的方法。首先对油茶害虫图像进行SIFT特征提取,然后通过BoW模型来描述各幅图像,针对每类油茶害虫,利用支持向量机(SVM) 训练,进而从图像中识别出油茶害虫的种类。实验结果表明:该方法用在油茶害虫图像模式分类问题上取得了较好的识别率,其平均识别率达到了83.3%,由此表明BoW 模型用于油茶害虫图像分类的有效性。
油茶害虫;图像识别;特征提取;BoW模型;支持向量机;图像分类
油茶作为世界四大木本食用油料植物之一,具有很高的综合利用价值。目前,种植油茶已成为我国南方山区经济和山区农民脱贫致富奔小康的支柱产业之一,同时油茶在我国实施退耕还林和调整种植业结构中发挥着十分重要的作用[1]。我国油茶的种植面积约有300万hm2,但其亩产量并不高,其中油茶害虫是影响其亩产量低的一个很重要的因素。因此开展针对油茶害虫的模式分类问题研究,将有利于油茶林区虫害实施远程监测预报,对推动地方经济发展具有重要的现实意义。
近年来,计算机图形图像、自动检测、人工智能等技术的迅速发展使得图像分类技术得到很大的发展。如何快速、准确地对大量的图像信息进行分类,提取其中有用的信息,逐渐成为了人们研究的热点之一。Bag of words (BoW)模型最开始应用于文档分类领域,由于其简单有效的优点得到了广泛的应用。目前很多的研究者将这样的思想应用到图像分类领域。本研究就是将 BoW 模型应用于油茶害虫图像分类,由于油茶害虫图像分类识别在本质上是一个复杂的多类判别问题,针对每类油茶害虫采集大量的图像样本,但相对于其维数而言,害虫的样本数是一个小样本问题[2]。支持向量机是为解决小样本问题学习和分类提出的具有很强的非线性分类能力[3]。
1 基于油茶害虫图像BoW模型的构造
本研究将BoW模型应用于图像识别,可以先把图像看作为一个文档,而图像中的关键特征被看作为“单词”。对于油茶害虫图像构造BoW的过程主要有4个步骤,如下所示:
(1)特征检测:采用Ostu图像分割[4]的方法对油茶害虫图像进行分割来获取图像的兴趣点,比如图像的边缘、角点、斑块等,获得的图像块在后面图像的识别过程中会起到至关重要的作用。
(2)特征表示:油茶害虫内容通过采用图像的局部特征描述子来表示。在特征检测之后,把获得的局部块状小区域用一个特征向量来表示,提取出的特征向量就称为特征描述子。本研究采用的是SIFT特征描述子。
(3)生成视觉直方图:在特征表示后,将局部特征描述子表示的油茶害虫内容生成虫子视觉单词。然后通过聚类的方法将特征描述子所表示的油茶害虫图像进行聚类,即可获得多个聚类中心,每个聚类中心即为一个视觉词,把全部的中心聚集一起就构成了BoW模型的视觉词典,再通过聚类中心映射得到视觉词直方图。
(4)SIFI特征提取:通过以上几个步骤生成BoW后,再使用K-means聚类算法[5],训练油茶害虫图像集提取的SIFT特征。K-means算法因其收敛速度快成为一种经典的聚类算法得到广泛的应用。K-means算法的思路是把参与聚类的特征数据存入到内存中,然后进行不断的迭代。其迭代过程如下:任意选择K个对象作为初始化的聚类中心,定义的对象为c1,c2,c3,…,ck,然后针对剩下的对象xi(i=1,2,3,…,n),计算各个簇中心与对象的距离,得到其中最小的距离,再把这个对象赋给这个簇。整个赋值过程如下:
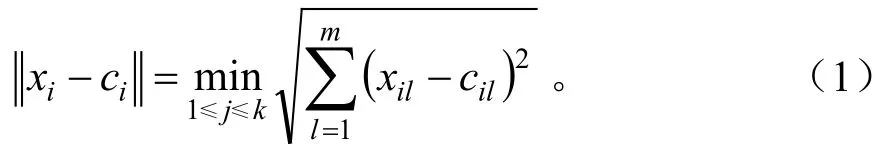
其中1≤l≤m。m是特征向量的维数。
然后把重新计算的每个簇的平均值作为下一次迭代的聚类中心:

其中Ni为第j个簇sj中的对象数目。
K-means 算法全过程包括初始化、分配和更新类中心,其后两个过程需要不断重复,直到所有的聚类中心都不再变化,最终得到的类中心就是 BoW模型所需要的视觉词[6]。然后把每幅油茶害虫图像中的每个 SIFT 描述子都映射到某个视觉词,得到的就是该图像的视觉词直方图。为了生成视觉词直方图,在映射过程中需要计算每个视觉词与每个SIFT特征向量也就是聚类中心的距离,取其中最小的值,并把当前SIFT特征归类到该视觉词下,直到把所有的SIFT描述子都分配完毕后,得到一个直方图,再把直方图表示为数值向量,并进行归一化,就可以用分类器进行训练,进而为后面的图像识别做好准备。
2 基于SIFT算法的油茶害虫特征提取
将 BoW 模型应用于图像分类和识别领域时,首先要对图像进行特征的提取和描述,这就需要合适的选择特征提取方法以及描述子,使提取的特征在对图像能最大限度地进行精确描述,提供它的关键信息,并尽可能地降低其实现的复杂度。本文中采用SIFT (Scale Invariant Feature Transform)描述子来提取油茶害虫特征[7]。下面是SIFT特征提取的四个步骤:
(1)检测在尺度空间的极值点。
(2)生成关键点的描述子,精确定位特征点的位置。
(3)确定每个关键点的主方向。
(4)关键点SIFT描述子的生成。
首先提取油茶害虫图像的SIFT特征作为图像中的视觉词汇,把所有的视觉词汇集合一起,即可用一个特征向量集合描述每幅害虫图像。
然后,采用K-Means聚类算法来构造视觉词汇表[8]。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用算法将词义相近的词汇合并,得到K个聚类中心作为视觉单词,生成单词表中的基础词汇,再由视觉单词构成视觉词汇表,进而利用单词表中的词汇表示害虫图像。
最后,利用SIFT算法,可以从每幅油茶害虫图像中提取多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K维数值向量[9]。对每幅害虫图像中的每个向量计算N个最近邻视觉单词,然后计算第k个的视觉单词的质量:

式(3)中:Mi表示与视觉单词tK第i接近的特征维数;s(fi,tK)表示视觉单词tK与特征向量fi之间的相似度。本文中采用欧氏距离进行度量,对每个视觉单词计算其质量,如果满足

就保留,不然则舍去。式(4)中的h为视觉单词的质量阈值。在满足实时性要求的同时要保证识别率,本文取N=3,h=0.8。
3 SVM分类器的设计
支持向量机(Support Vector Machine)是在1995年由Cortes和Vapnik第一次提出。SVM相比于传统的基于经验风险最小化理论的学习方法,它的泛化能力更强,因为它是一种基于结构风险最小化理论的学习方法[10]。SVM在解决小样本问题上具有比较大的优势,在工、农业等领域的分类和识别问题中得到比较广泛的应用。
SVM方法在采集的样本数目较有限的情况下可以获得较好的分类效果,利用SVM进行油茶害虫图像识别分为两部分——训练和测试。在训练阶段,可以获取油茶害虫图像不同的SIFT特征、不同的视觉词汇本和不同的BoW 模型,将这些不同的BoW 模型可以训练得到不一样的SVM 分类器;在测试阶段,将训练得到的不同分类器分别对测试样本进行分类,进而就可以得到不同的分类结果,即可获得测试训练出来的分类器的识别率。SVM分类器进行识别的流程见图1。

图1 油茶害虫图像识别流程Fig.1 Flow of oil-tea pest image recognition
3.1 核函数选择
对未知数据进行测试时的分类能力是SVM的泛化能力。用支持向量机方法进行模式识别及分类时需选择一个合适的核函数,核函数是SVM模型中很重要的一个参数[8]。选择不同的核函数,关系到识别的准确率。但是如何选择最优的核函数,还仍是一个有待解决的问题,目前大多是通过试验来选择,因此,接下来将对不同核函数下的分类效果进行比较。最常用的核函数主要有三类。
多项式核函数(Poly):

径向基核函数(RBF):
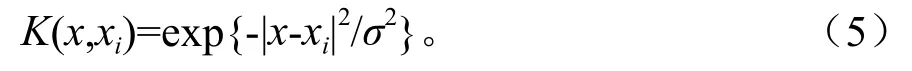
多层感知器核函数(Sigmoid函数):
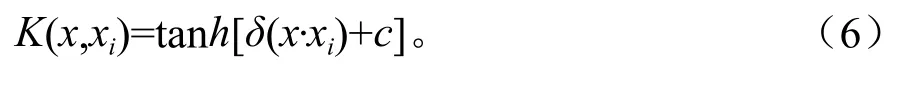
3.2 基于SVM分类方法的步骤
步骤1:将尺度无关特征转变成SIFT提取图像特征;
步骤2:对SIFT特征进行K-means聚类生成所需的视觉词汇本;
步骤3:将所有词汇本和图像的SIFT特征进行比较,统计视觉单词出现的频率,从而构建图像的BoW模型描述;
步骤4:利用油茶害虫图像的BoW模型描述训练得到SVM分类器;
步骤5:利用步骤4得到的SVM分类器对测试样本进行分类,得到不同害虫图像的分类结果。
4 实验结果与分析
本文中基于BoW和SVM分类器的油茶害虫图像分类算法进行了仿真实验。实验的硬件平台是:CPU,Intel Core i5-3450(四核、2.8GHz);内存,4G。采用国立台湾大学林智仁的LibSVM工具箱。从油茶害虫图像样本库选择3种油茶害虫(毒蛾、叶峰、尺蠖),每种虫子40幅图片,每种虫子选取60%的图像作为训练样本,另外40%的图像作为测试样本。用Matlab进行实验。
基于Bow模型的油茶害虫图像分类,主要涉及两个方面的工作。一方面是基于 BoW 模型油茶害虫图像的表达,另一方面则是基于 SVM 的油茶害虫图像分类。基于SVM的分类实验,在已经提取出 BoW 特征之后,主要是参数选择的问题。利用构建的视觉词直方图表示的图像频次,将其归一化后,分别采用多项式核函数(Poly)、径向基核函数(RBF)以及多层感知器核函数(Sigmoid函数)对图像进行训练,得到各类害虫的识别结果(如表1所示)。
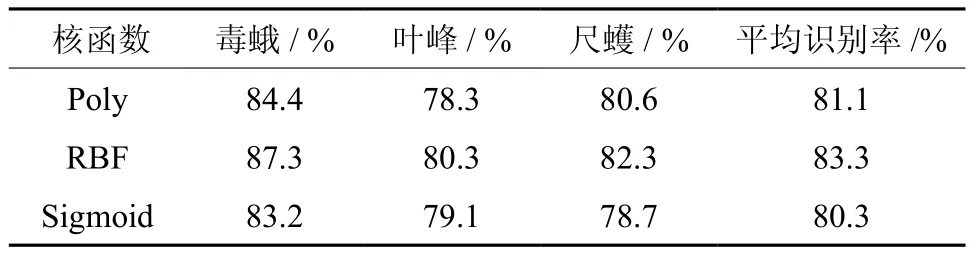
表1 不同核函数的各类害虫的识别结果对比Table 1 Different kernel functions of all kinds of insect pests recognition results
从各类害虫图像的识别率中可以发现,采用不同的核函数分类结果有一定的差别。其中,RBF核函数对油茶害虫图像的分类效果是最好的,它的分类平均正确率最高。
为了验证BoW模型的有效性,在相同实验条件下,将SIFT特征单独作为输入变量,代入支持向量机进行训练和分类,根据上个实验的经验,直接选用RBF核函数进行测试,实验的分类结果如表2所示。

表2 基于不同特征的的油茶害虫图像识别结果Table 2 Based on the different characteristics of camellia pest image recognition results
从实验结果中可以看到,相比于单独使用SIFT特征,由SIFT特征构建的BoW模型在识别率上有了较大的提高,由此表明 BoW 模型用于油茶害虫图像分类的有效性,并取得了较好的分类精度。与此同时,这个结果表明目前这种方法还有待于进一步提高,尤其是在特征提取方面需要继续寻找新的可能性,以提高识别的准确率。
[1]高 超,袁德义,邹 锋.论油茶在南方丘陵区退耕还林工程中的应用[J].中南林业科技大学学报,2011,31(7):205-208.
[2]李 密,邹佳慧,何 振,等.湖南油茶林害虫群落组成及其物种多样性[J].中南林业科技大学报,2013,33(5):11-15.
[3]Chunhui Gu, Lim J J, Arbelaez P,et al. Recognition using regions[M]. IEEE Conference on Computer Vision and Pattern Recognition, 2009: 1030-1037.
[4]刘健庄.灰度图像的二维 Otsu 自动阈值分割法[D].沈阳:东北大学,2011.
[5]张雪凤,张桂珍,刘 鹏.基于聚类准则函数的改进K-means算法[J].计算机工程与应用,2011,47( 11) : 123-124.
[6]陈 凯,肖国强,潘 珍,等.单尺度词袋模型图像分类方法[J].计算机应用研究,2011,28(10):3986-3988.
[7]张秋余,王道东,张墨逸,等.基于特征包支持向量机的手势识别[J].计算机应用,2012,32(12):3392-3396.
[8]astanlar Y, Temizel A, Yardimci Y. Improved SIFT matching for image pairs with scale difference[J]. Electronics Letters, 2010,46(5): 107-108.
[9]Zhang R, Wang W J, Bai X F. SVM color image segmentation based on automatic selection of training samples[J]. Computer Science, 2012,39(11): 967-971.
[10]Chih-Chung Chang, Chih-Jen Lin. LIBSVM3.11: a library for support vectormachines[M]. ACM Transactions on Intelligent Systems and Technology,2011.
Classi fication research of oil-tea pest images based on BoW model
XIE Lin-bo, YU Shao-jun, ZHOU Guo-ying, LI Hong
(Central South University of Forestry and Technology, Changsha 410004, Hunan, China)
For the existing problem of image recognition applying in the field ofCamelliapests, aCamelliapest image recognition method was put forward based on BoW model. Firstly, the SIFT features of oil-tea pest image were extracted, and then by using BoW model the images were described, and last the species of oil-tea pests were identi fied through support vector machine (SVM) training.The experimental results show that the method used in oil-tea pest image pattern classi fication had a better recognition rate, with an average recognition rate of 83.3%.
Camelliapests; image recognition; feature extraction; BoW model; support vector machine (SVM); image classi fication
S781.39
A
1673-923X(2015)05-0070-04
10.14067/j.cnki.1673-923x.2015.05.012
2014-05-10
“十二五”国家科技计划课题(2012BAD19B0803);湖南省科技厅科技计划项目(2014NK3057)
谢林波,硕士研究生
余绍军,教授; E-mail:1071599402@qq.com
谢林波,余绍军,周国英,等. 基于BoW模型的油茶害虫图像分类[J].中南林业科技大学学报,2015,35(5):70-73.
[本文编校:谢荣秀]
