可逆逻辑门进化设计方法的CUDA实现
2015-12-18俞经龙赵曙光
俞经龙,赵曙光,王 祥
(东华大学信息科学与技术学院,上海 201620)
随着可逆电路研究的深入,出现了众多可逆电路的综合方法[1-2],但这些设计方法普遍针对整个逻辑电路进行综合优化设计,对作为其基础构件量子逻辑门的研究甚少,而基础逻辑门的最优化将直接影响量子逻辑电路的整体优化程度。因此,若能对其进行自动进化,获得性能更好、逻辑功能更齐全和量子代价最小的门结构,将对整个电路的优化设计起到重要作用。
本文基于NCV门库[3],利用遗传算法对可逆逻辑门进行优化设计。同时,为了充分发挥遗传算法运用在可逆逻辑门优化设计的优势[4],利用(NVIDIA)CUDA并行计算架构[5],将可逆逻辑门的进化设计方法改编为并行化的算法,令其以“CPU与GPU协同处理”,借助GPU的并行处理能力,在不增加额外成本的情况下大幅提升了程序的运行速度和相应的求解能力。这对于可逆逻辑门的设计优化,新型门的发现及对现有门库的扩充均有着重要意义。
1 可逆逻辑门进化设计方案
1.1 门级器件库选用
Deutsch和Lloyd等人已证明所有的量子门在物理实现上均可有基本的一位和二位量子门的实现[6]。同时,为减少问题的搜索规模和提高求解效率,并考虑量子逻辑门的通用性,本文选择包含以下4种基本量子门的NCV门库。
CNOT门T({c};t):当控制位c为1时,目标位t才翻转。
Controlled-V门V({c};t):若控制位c为1,目标位t根据酉矩阵所描述的操作执行。
Controlled-V+门V+({c};t):当控制位c为1,目标位t根据酉矩阵所描述的操作执行。可看出V+门是V门的共轭转置矩阵。
1.2 编码
利用遗传算法对可逆逻辑门进行优化设计。如对NOT、CNOT、Controlled-V、Controlled -V+,基本门构建通用且完备的门库进行编码,其会随着电路输入的增大,所需的量子门库规模将以指数幂增加,且在功能判定时,随着输入位数的增大,其电路的真值表规模以2的指数幂增大,这也增加了电路功能判定的难度。为此,文中设计了一种新的编码方法,可避免建立量子门库的过程,且通用性较强。
根据信息位传输路径对电路的分级,每级电路需包含一个量子门,且用一组实数位串表示,该位串分为3部分:(1)表示本级电路的功能,用量子门编号表示,设定0表示NOT门,1表示CNOT门,2表示Controlled-V门,3表示Controlled-V+门。(2)表示各量子门的目标位所在连线编号。(3)表示各量子门的所在连接线的具体位置,若直通则用-1表示,否则在其相应的位置上写入所在的连线编号。以图1所示的Toffoli门的NCV实现为例分析其编码为Initial_chromosome={320 -12,1101 -1,32 -112,1101 -1,22 -112}。此染色体包含5个基因,每个基因由5个数字组成:第1位数字表示所选基本门的种类,第2位数字表示目标位所在位置,后3位则表示量子门所在连线的具体位置。

图1 Toffli门的NCV实现
1.3 适应度评估
由于可逆逻辑门进化是典型的多目标优化问题,本文对适应度函数进行了专门设计,利用“加权和”形式,将多目标优化问题转换为单目标进化算法求解问题,其中涉及到以下子目标:功能适应度

量子代价适应度

量子门数适应度

垃圾位适应度

将多目标优化问题转化为单目标进化算法求解的等效问题,其实现形式为
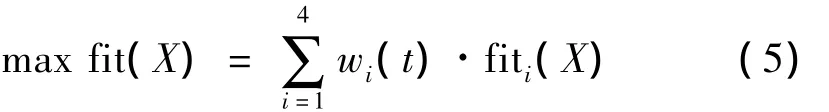
其中,fiti(X)为个体X关于子目标fi(X)的归一化适应度;wi(t)为第t代种群中的非负权重系数,其取值应满足

在此基础上,为兼顾全部子目标,通过借鉴参照人工神经网络中的后向传播(Back-Progagation)学习算法,令权重系数wi随fi(X)的优化程度动态更新,如式(7)所示
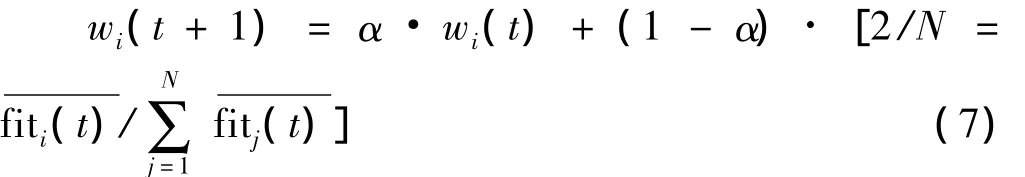
2 算法的CUDA实现
2.1 遗传算法的并行化模型
当种群规模较大时,将其分解为若干个子种群,并为每个子种群分配一个线程块,鉴于线程块之间不能进行数据通信,而遗传算法中的选择、交叉和变异操作均有数据交换。为解决此矛盾,当每个线程块完成子种群进化任务后,让各自线程块的最优染色体迁移到相邻的线程中去,并淘汰其中最差的染色体,但其只能是单方向迁移。对于单个子种群,每一代的最优染色体,将与上一代的最优染色体相比较,若染色体的适应度不如上一代的最优染色体,则上一代的最优染色体将取代当代的最差染色体,以防最优染色体在进化过程中被淘汰[4]。
如种群大小为512×128=65 536,开启128个线程块,每个线程块中有512个线程。一个线程块负责一个子种群的进化任务。当进化完成后,在CPU串行代码中完成最优染色体的迁移。种群结构模型如图2所示。
2.2 遗传算子的并行化实现
(1)选择算子并行化。选用轮盘赌选择法,可将其中的求适应度总和与求个体相对适应度这两个步骤并行化实现。在求适应度的总和步骤上,其求和操作可用归约算法并行实现。如子种群规模为512,串行求和需执行511次加法操作,然并行化求和只需9次循环求解,便可得到适应度总和。理论上,其计算速度是串行求解的511/9倍[7-8]。另外,在求个体的相对适应度时,开启512个线程同时运行,分别将个体的适应度除以适应度总和,子种群512个个体只需一次求解,便可得到个体的相对适应度。理论上,其计算速度是串行计算的512倍,选择操作具体流程如图3所示。
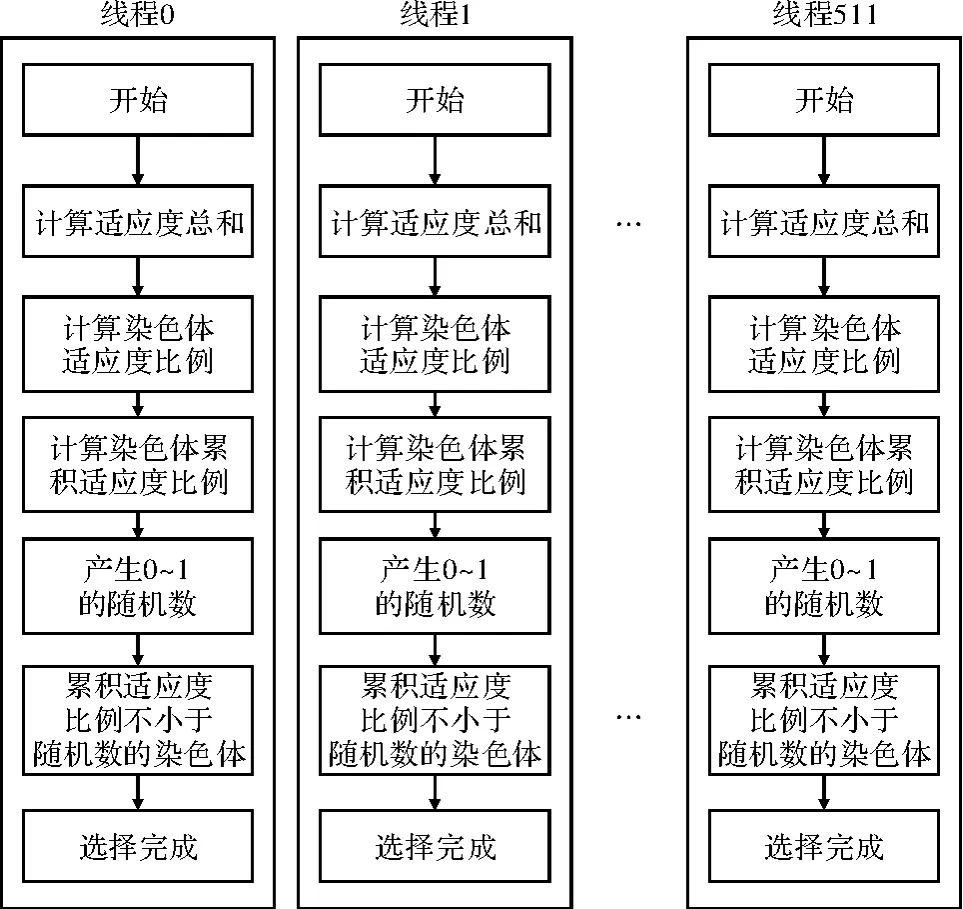
图3 并行化选择操作流程图
(2)交叉算子并行化。交叉操作在CUDA并行化中的具体实现如下:首先将子种群中的512个染色体顺序打乱,为保证交叉的随机性,其顺序的打乱由随机数实现。然后产生随机数表示随机概率,与交叉率Pc进行比较,若随机数小于交叉率,则进行交叉,否则不交叉。
在线程块中开启256个线程分别进行交叉操作。让第个染色体和第256个染色体交叉,第2个染色体和第257个染色体交叉,依次类推,交叉操作一次即可完成。理论上,其交叉执行速度是串行化实现的256倍,其具体操作流程如图4所示。
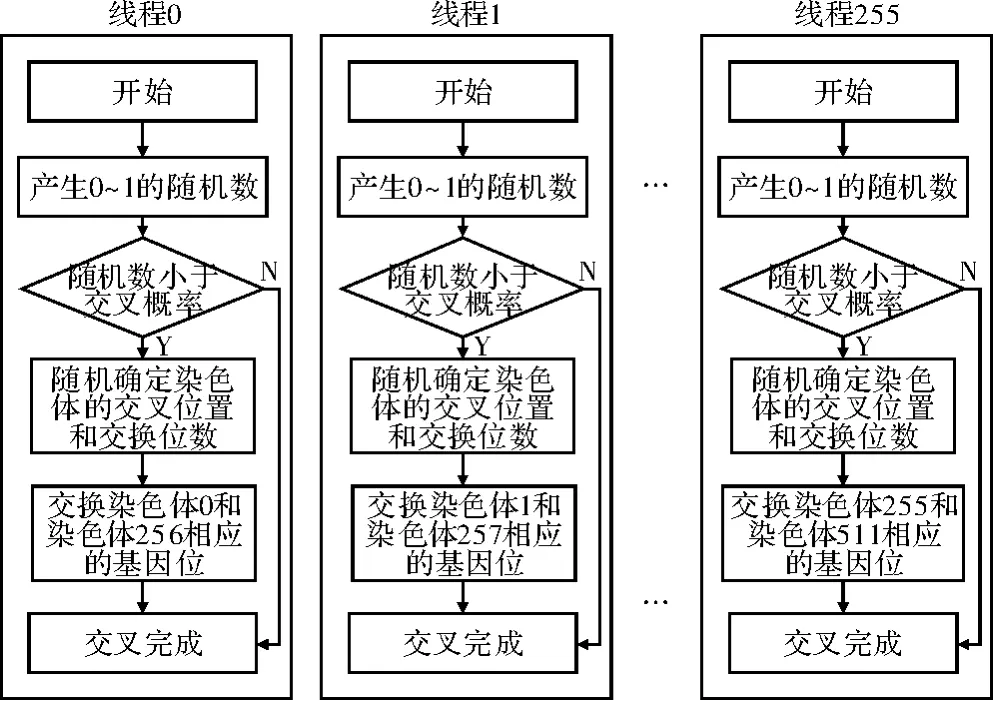
图4 并行化交叉操作流程图
(3)变异算子并行化。针对电路编码的特点,设计了3种染色体变异操作量子门的功能变异、有无量子门变异及量子门的位置变异。其CUDA具体实现如下:首先在每个线程中产生随机数作为随机概率,将其与变异概率Pm相比较,若随机概率小于变异概率Pm,则代表某个基因达到了变异条件,再产生0~2的随机数分别代表上述3种不同方式的变异,并根据此随机数选择相应形式的变异。子种群共有512个个体,开启512个线程同时进行变异操作。理论上,其变异执行速度是串行化实现的512倍。具体流程如图5所示,每个线程执行相同的操作。
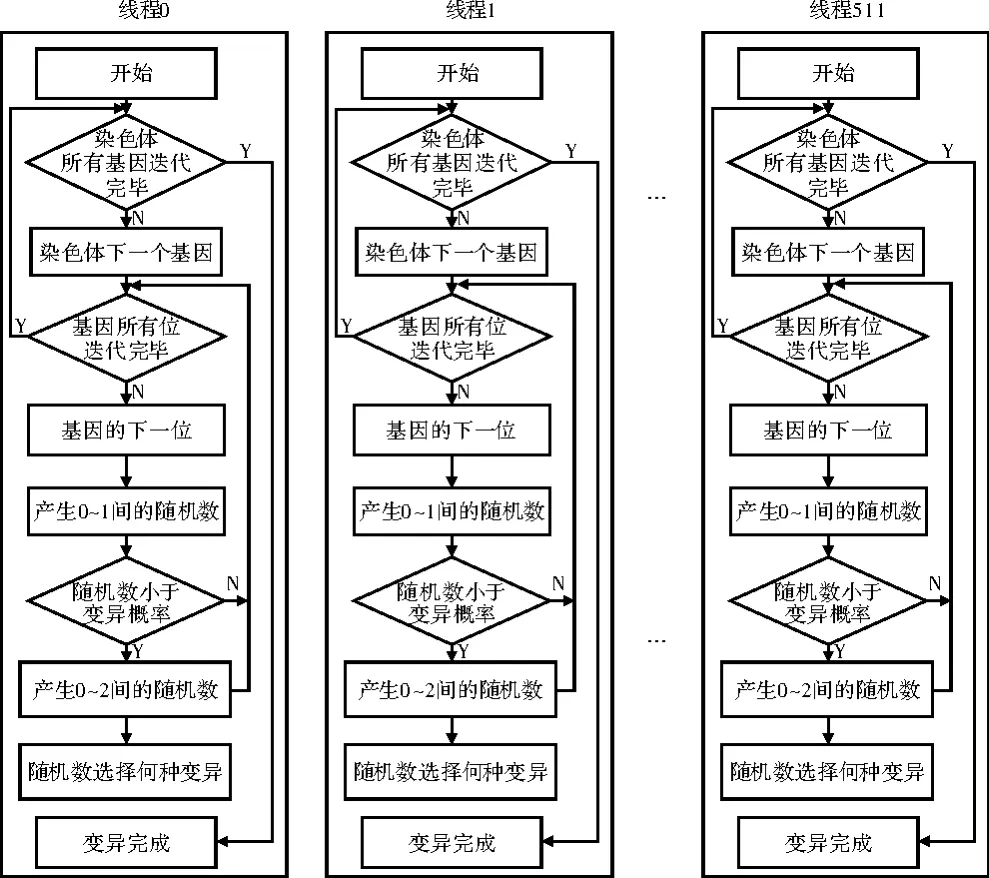
图5 并行化变异操作流程图
3 实验结果与分析
实验在VS2010平台上用CUDA C语言编程实现;所用显卡为Nvidia公司GeForce GT610。
3.1 Toffoli门的NCV实现
参数设置:设置种群大小为128×512=65 536,染色体长度为25,即一个染色体包含5个基因,基因长度为5位,最大进化代数是MaxGeneration=10;遗传操作参数,交叉概率Pc=0.65、变异概率Pm=0.1;适应度函数中各子函数的权重系数初值为w1(0)=0.4,w2(0)=w3(0)=w4(0)=0.2,即满足 α =0.9。
运行结果:320-12,1101-1,32-112,1101-1,22-112。根据上述可逆电路的编解码方案,得到Toffoli门NCV实现的具体电路,如图6所示。
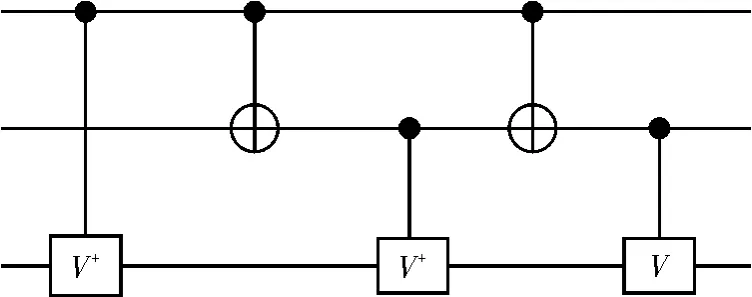
图6 Toffoli门的NCV实现
由于 NOT、CNOT、controlled-V与 Controlled-V+量子代价均为1,可得Toffoli门物理实现的最小量子代价为5。
3.2 可逆基准电路3_17的NCV实现
设置种群大小为128×512=65 536,染色体长度为100,即一个染色体包含10个基因,基因长度为5位,其他参数设置如上。所得结果为:02-1-12,120-12,200 1-1,300 -12,11 -112,2001 -2,22 -112,22 -112,1101-1,32-112。通过解码得到可逆基准电路3_17的NCV实现具体电路,如图7所示。
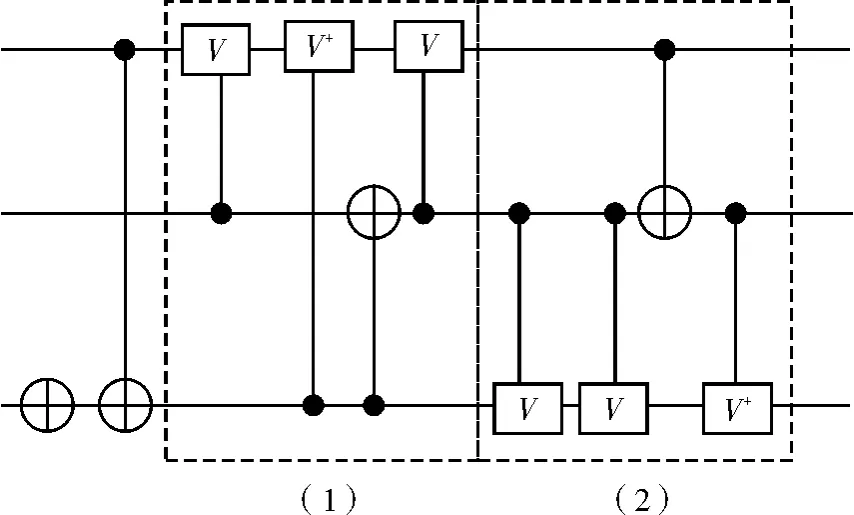
图7 可逆基准电路3_17的NCV实现
可逆基准电路3_17的NCT门库实现如图8所示,其量子代价消耗为14,而本文基于NCV门库的电路进化算法所生成的最优电路的量子代价为10。经细致研究,发现Toffoli门可用Peres门和CNOT门级联得到。同时,可用NCV门库生成3种类似Peres门的新型量子可逆逻辑门,其构造如图9所示。
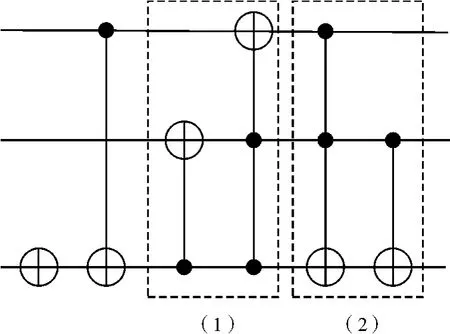
图8 可逆基准电路3_17的NCT实现
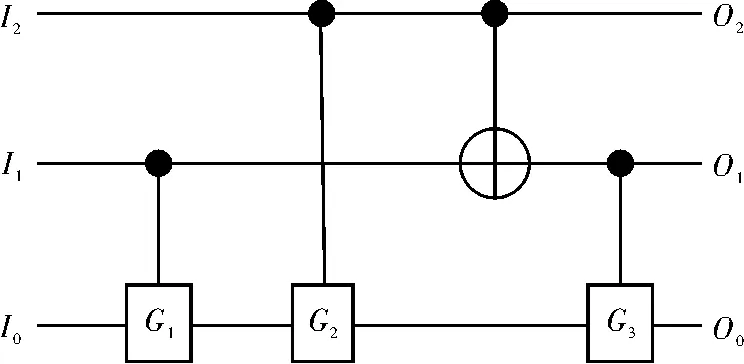
图9 基于NCV的新型量子可逆逻辑门构造图
其中,G1、G2、G3处分别选择 Controlled-V 或 Controlled-V+门,根据 I0、I1、I2的给定值判定选择何种门,实现不同的逻辑功能,如表1所示。
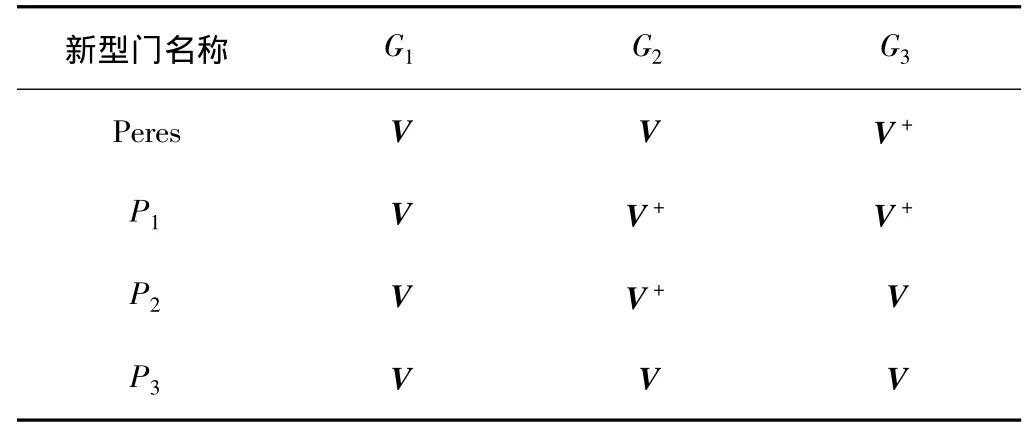
表1 新型量子逻辑门库的构造表
选用易于物理实现的NOT、CNOT、Controlled-V、Controlled-V+基础门构建完备且通用的门库,根据可逆逻辑电路的特点,采用位串的编码方案,并改进了适应度评估方法,使可逆逻辑门优化得到较为全面的评估。鉴于遗传算法本质上具有并行特性,将其改造为CUDA架构下的并行算法应用于可逆逻辑门优化。最后通过两个具体实例,验证了其设计方案的可行性。本文所提出的将遗传算法与CUDA结合应用于可逆逻辑门的优化,不仅可发挥电路进化设计的全局优化能力,且明显提高了电路的搜索速度。进化设计无需依赖先验知识和人工干预的条件下通过进化来获得满足预定目标的电路与系统结构,这对新型门的发现及对现有门库的扩充均具有重要意义。
[1]管致锦.可逆逻辑综合[M].北京:科学出版社,2011.
[2]Lu Hongjun,Guo Junwang,Peng Fei,et al.N - bit quantum gate accomplished by two - bit quantum gates[J].Chinese Journal of Quantum Electronics,2010,27(1):26 -30.
[3]Barenco A,Bennett CH,Cleve R,et al.Elementary gates for quantum computation[J].Elementary Gates for Quantum Computation,1995,52(5):3457 -3466.
[4]Tan Caifeng,Ma Anguo,Xing Zuocheng.Genetic algorithms parallel implementation study based on CUDA platform[J].Computer Engineering and Science,2009,31(A1):68 -72.
[5]张舒,褚艳丽.GPU高性能运算之CUDA[M].北京:北京水利水电出版社,2009.
[6]Miller D M.Lower cost quantum gate realizations of multiple- control Toffoli gates[C].PacRim:IEEE Pacific Rim Conference on Communications,Computers and Signal Processing,2009:308 -313.
[7]高磊,陈则王.基于PPRM表达式的快速可逆逻辑电路综合算法[J].电子科技,2011,24(10):75 -76,80.
[8]董亚清.基于GPU的线性调频信号脉冲压缩算法实现[J].电子科技,2013,26(12):12 -16.
