基于数据挖掘的国内大学生就业信息双向推荐系统
2015-12-09刘玉华陈建国张春燕
刘玉华,陈建国,2,张春燕
(1.福建工程学院软件学院,福建福州 350003;
2.湖南大学信息科学与工程学院,湖南长沙 410082)
基于数据挖掘的国内大学生就业信息双向推荐系统
刘玉华1,陈建国1,2,张春燕1
(1.福建工程学院软件学院,福建福州350003;
2.湖南大学信息科学与工程学院,湖南长沙 410082)
摘要:针对目前国内无法及时、准确地获取高质量的就业招聘信息,企业无法便捷获取符合岗位需求的人才信息等问题,提出一种基于数据挖掘的大学生就业信息双向推荐系统方案,实现毕业生信息与企业招聘信息双向推荐的目的.该系统通过分析某城市若干高校历年毕业生就业管理工作中积累的大量就业数据信息,分别对毕业生信息和企业招聘信息进行聚类分析,同时对各毕业生与其成功就职的企业和岗位信息进行关联分析.根据聚类规则对当前求职的毕业生和招聘企业分别进行分类,向各毕业生自动推荐其同类学生所关联的企业及岗位信息,同时向各企业自动推荐符合其岗位需求的毕业生信息.实验证明,该系统能够有效利用高校之间的就业信息资源共享机制,对各个高校的毕业生及企业岗位招聘信息进行准确聚类,实现毕业生和企业之间的双向推荐.
关键词:双向推荐; 就业信息; 数据挖掘; 聚类分析; 关联分析
伴随着计算机技术和信息技术的迅速发展,各种业务管理系统的应用要求进一步提高,各项业务决策已经越来越依赖于数据的分析和挖掘.目前国内许多高校已经完成毕业生就业工作管理的信息化建设,纷纷建立符合自身学校特色的毕业生就业管理系统[1-3].这些系统经过多年的运行和使用,已经积累了海量的毕业生就业管理业务数据,包括毕业生信息、企业信息、企业招聘信息、毕业生求职过程记录等宝贵的原始数据[4].大数据应用的价值越来越明显.海量数据里面蕴含着大量十分有价值的数据,要处理的数据量越来越大、而且还将更加快速地增长[5].
基于以上背景,本文针对目前高校毕业生在就业过程中存在无法及时、准确地获取高质量的招聘信息,企业无法便捷获取符合岗位需求的人才信息等问题;结合某城市大学城各个高校的毕业生就业管理工作数据,提出一种基于数据挖掘的大学生就业信息双向推荐系统方案,建设一个区域性的高校间毕业生就业推荐系统,实现毕业生信息与企业招聘信息的双向推荐的目的.
1 核心技术研究
1.1数据挖掘
数据挖掘是指从海量数据中采用各种特定算法,经过整合、归纳和评估,提炼出隐含的、有价值的信息,并将信息提炼成知识,为企业决策提供科学依据的过程[6].近年来,工业界各行业领域纷纷对数据挖掘技术开始关注和研究.数据挖掘技术已广泛应用于电子商务、经济金融、科学计算、工业制造等众多领域.
数据挖掘的过程可分为三个阶段:数据准备、挖掘的数据和结果的输出与分析。
1.2K-means聚类算法
K-means算法是一种经典的聚类算法[7],其基本思想是:以随机选取的k(预设类别数)个样本作为起始中心点,将其余样本归入相似度最高中心点所在的簇(cluster),再确立当前簇中样本坐标的均值为新的中心点,依次循环抚今追昔下去,直到所有样本所属类别不再变动[8].K-means算法过程如图1所示.
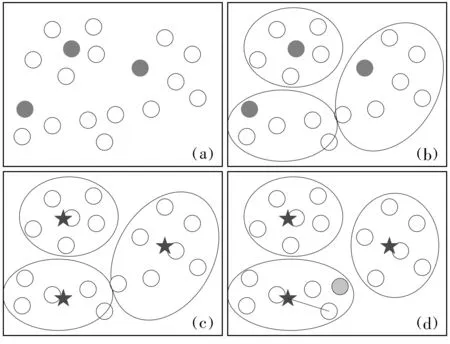
图1 K-means聚类算法演示
本文使用K-means算法对高校历年的毕业生就业数据中的毕业生信息和企业招聘信息分别进行聚类分析.从而对毕业生和企业招聘信息分别进行分类.
1.3Apriori关联规则算法
Apriori算法是一种径典的关联规则挖掘算法,该算法使用迭代的逐层搜索方法挖掘频繁项集[9].其基本思想是:通过读取并计算各个数据项的个数,找出满足最小支持度阈值的数据项并形成1级频繁项集合(含有单个数据项).接着使用1级频繁项集找到2级频繁项集(含有两个数据项).重复该迭代操作,直到找出极大频繁项集(含有最多数据项并满足最小支持度阈值).
2 毕业生与企业信息聚类分析
本系统所使用的毕业生数据、企业数据和就业过程数据来源于某城市5所大学于2008—2013年之间在毕业生就业管理工作过程中产生的部分就业管理工作数据.
2.1毕业生信息聚类分析
(1) 毕业生数据预处理.高校毕业生数据库中包含了许多信息,其中,对就业质量影响很小的其他信息(如:姓名、身份证号等),不作为聚类分析的数据特征.对就业质量可能产生影响的毕业生信息(如:性别、年龄、专业、成绩、籍贯等),这些都影响并决定着其就业的情况,因此,选择这些信息作为聚类分析的数据特征.毕业生聚类分析的数据特征选择情况见表1所示.
确定完要分析的毕业生信息数据源后,需要对这些数据进行数据清洗、规约、变换和集成等预处理操作,具体预处理细节在此不展开阐述.
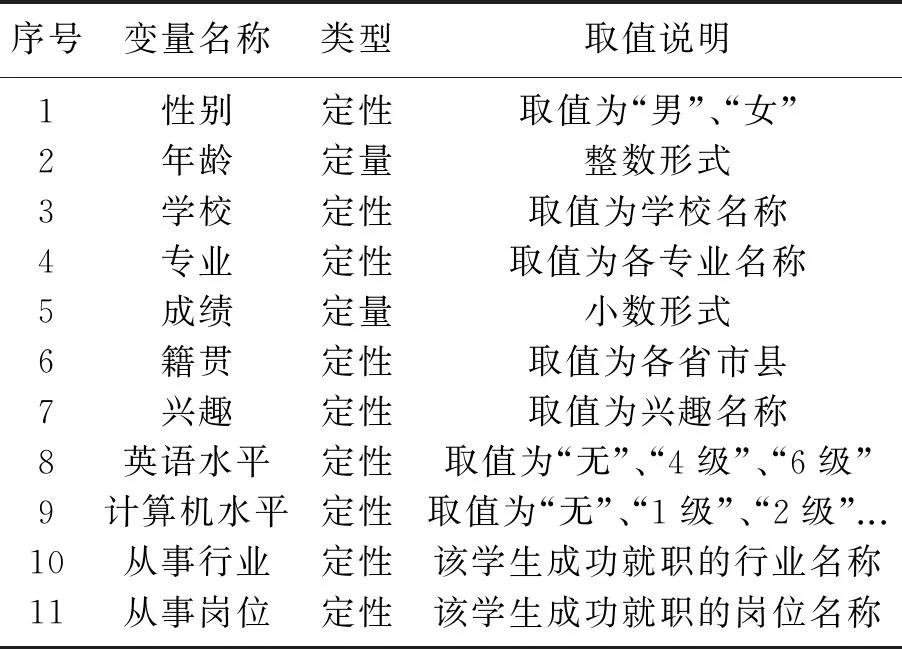
表1 毕业生数据特征选择
(2)K-means聚类分析.本文使用K-means算法对高校历年的毕业生就业数据中的毕业生信息进行聚类分析,根据分析结果对毕业生进行分类.毕业生聚类分析功能示例如图2所示.
图2 毕业生聚类分析功能
使用K-means算法对毕业生信息进行聚类,需要先设定聚类数和所使用的准则函数.
首先,将经过数据清洗、集成等预处理后的毕业生数据集作为选择聚类挖掘的训练样本,设训练样本S:
n为数据集中毕业生的数量.每个样本具有m维特征(本文设为10维:性别、年龄、专业、成绩、籍贯、兴趣、英语水平、计算机水平、从事行业、从事岗位).
其中,si为第i个样本,m为si样本向量的特征维度.
接下来需要设置要进行聚类的个数k,k的取值很关键,不同的k取值将直接影响到聚类的效果,可以通过迭代训练并对比聚类效果的方法修改k的取值,直到聚类收敛.
步骤1从n个毕业生中随机选取k个毕业生信息作为k个聚类质心,形成质心集合μ.
同时形成k个类集合C.
对于每个聚类ci初始化为空,因为目前还没有计算每个毕业生样本具体属于哪个类.
步骤2聚类分析中度量两个样本对象的相似性有两种方法,分别是对所有样本对象作特征投影和距离计算,本文采用距离计算方法.对于每个毕业生样本si,计算其到质心集合μ中每个质心的距离,选择其距离最近的质心所在类.
其中:cj为样本si到k个类中距离最近那个质心所在类;‖si-μj‖2是si到质心μj的距离.由于毕业生样本具有多维特征,因此,本文使用一种多维空间的距离计算方法对各样本到质心距离进行计算.
通过以上步骤,n个毕业生训练样本都找到所属的类.这时每个类中已经包含若干个训练样本数据.
步骤3对于每个类cj,需要重新计算该类的质心μj,得到新的k个质心.
重复迭代步骤2和3,调整各点所属的类,直到质心不变或变化很小,即质心收敛,最终得到k个毕业生信息类,并得到聚类算法模型,能够成功将所有学生正确的划分到所属的类中.同时可以得到m个学生信息的特征对聚类效果的重要性程度.
毕业生信息聚类分析的系统流程如图3所示.
以本文所选的就业管理工作数据源中的5000个毕业生信息为实验数据,得到的毕业生信息聚类挖掘结果如图4所示.
图4中,聚类1的毕业生特征为:性别=“女”,年龄<24,籍贯=“福州、宁德、龙岩”,就读学校所在城市=“福州”,工作地点=“福州”.这类学生共有2110个,占总调查毕业生的42.2%.聚类2的毕业生特征为:性别=“女”,年龄<24,籍贯=“泉州,三明,漳州、厦门”,工作地点=“厦门”.这类学生共有1290个,占总调查毕业生的25.8%.由此可以看出大部分学生的就业工作地点会选择籍贯所在城市或者离家较近的大城市.由此可以进一步看出,影响毕业生就业地点的聚类依据中,毕业生的就读学校所在城市和籍贯有较大影响,其就读高校名称对就业地点影响较少.因此,可以将同一城市各个高校的毕业生就业数据进行统一分析,充分发挥区域性高校就业信息资源的共享功能.这些历史毕业生信息的聚类结果将为当前毕业生的就业推荐提供推荐依据.
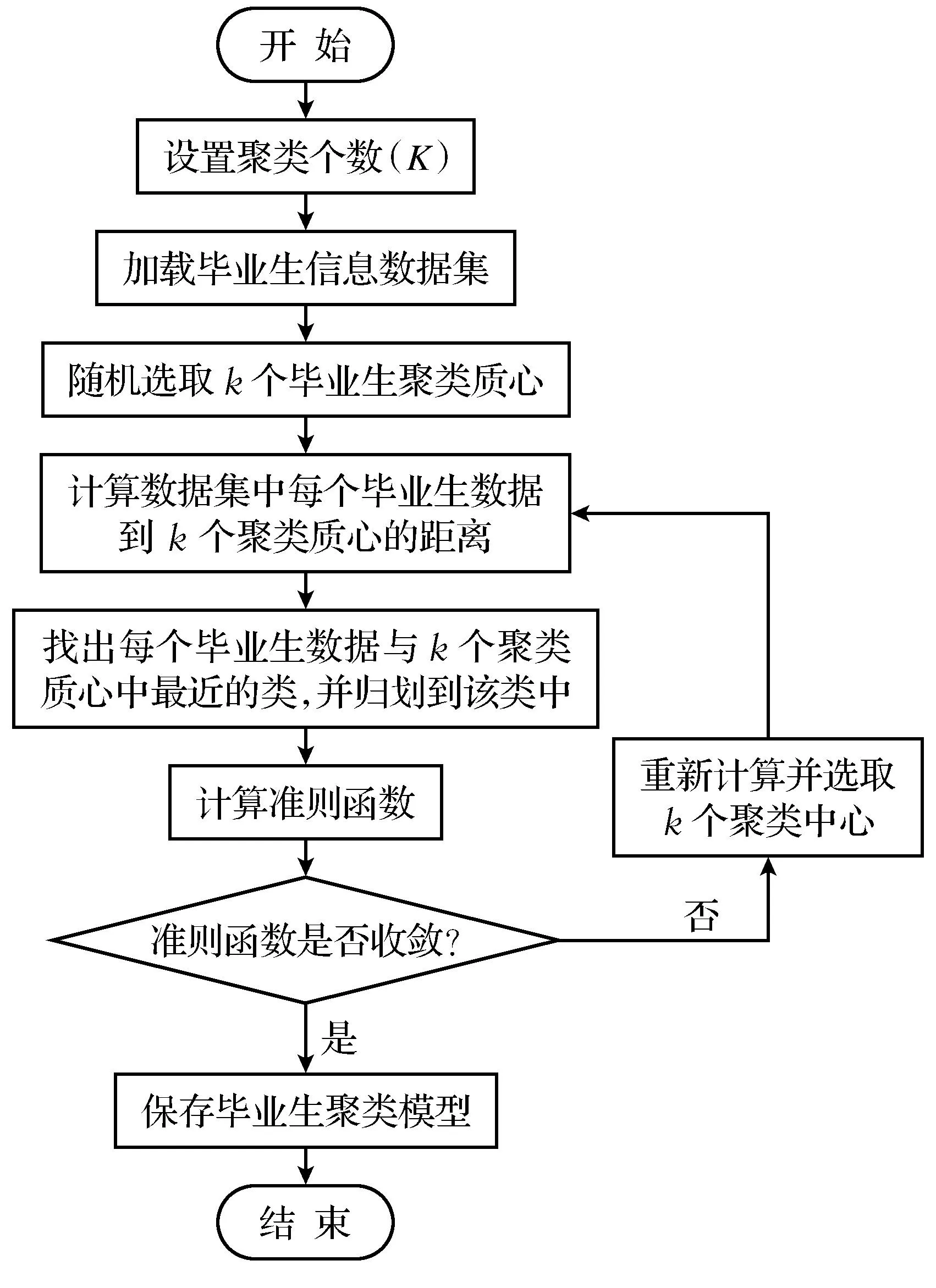
图3 毕业生信息聚类分析的系统流程
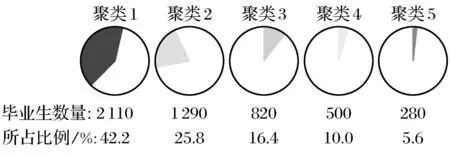
图4 毕业生信息聚类分析结果
2.2企业岗位信息聚类分析
(1) 企业岗位数据预处理.企业岗位信息数据中包含了许多信息,其中,企业自身已经包含了所属行业、企业性质、规模和所在地区等特征.企业所发布的招聘岗位信息也包含了岗位性质、岗位类别、薪资待遇、工作内容、工作要求等.这些都影响并决定着其招聘的情况,因此,选择这些信息作为聚类分析的数据特征.企业岗位信息聚类分析的数据特征选择情况见表2所示.
确定完要分析的企业岗位信息数据源后,需要对这些数据进行数据清洗、规约、变换和集成等预处理操作,具体预处理细节在此不展开阐述.
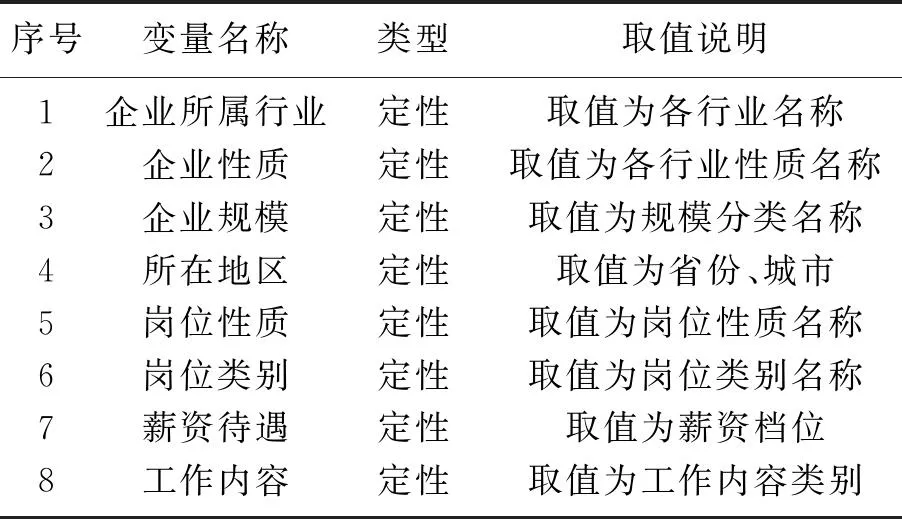
表2 企业岗位信息数据特征选择
(2)K-means聚类分析.本文使用K-means算法对历年来与高校合作开展招聘工作的用人企业及其岗位信息进行聚类分析,根据分析结果对企业和岗位信息进行分类.企业岗位信息聚类分析功能示例如图5所示.
图5 企业岗位信息聚类分析功能
企业岗位信息的聚类分析原理和具体实现过程与毕业生信息聚类分析相似,在此不再阐述.
3 就业信息关联分析
本节通过关联规则分析方法对高校毕业生与其成功就职的企业和岗位信息进行关联分析,结合第3节中毕业生信息聚类分析结果和企业岗位信息聚类分析结果.从而寻找出每个毕业生的成功就职岗位的特点、这些岗位与毕业生各个特征之间的关系、这些岗位与岗位所在聚类结果的关系,为毕业生就业双向推荐提供数据依据.
3.1关联分析流程设计
本文采用Apriori算法对毕业生与企业岗位信息进行关联分析.Apriori关联规则分析最经典的应用就是商品关联销售分析,即对每一次购买订单的多个商品进行分析,找出共同购买可能性最大的商品集合.
和商品关联销售分析不同,毕业生就业数据中,每个毕业生只就职于一个岗位.因此,我们的分析数据对象是毕业生、毕业生所属聚类、毕业生成功就职的企业及岗位、岗位所属的聚类之间的关联关系等,希望找出同类毕业生中每个学生的就业情况之间的关联关系.毕业生与企业岗位之间的就业信息关联规则分析的功能示例如图6所示.
图6 就业信息关联规则分析功能
毕业生与其成功就职的企业岗位之间的关联规则分析的实现过程如图7所示.
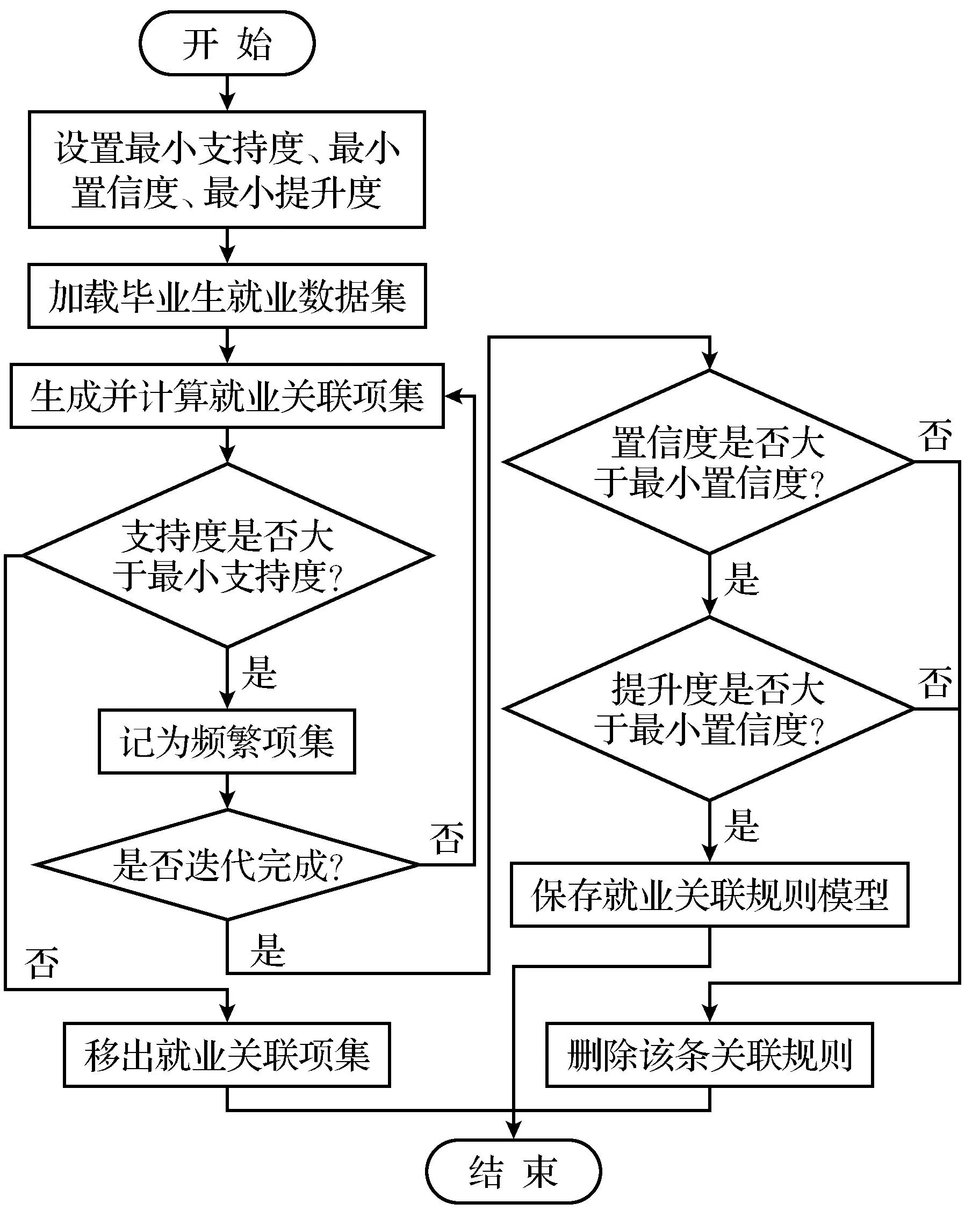
图7 就业信息关联规则分析的系统流程
3.2Apriori关联分析过程
设O={o1, o2,…,om}是毕业生就业信息中全体企业岗位的集合,每个企业岗位称为“数据项”.
记D是整个就业信息数据集(DataSet),即D为所有毕业生就业记录(Employment)E的集合.每个就业记录都由一些数据项构成,并且每个就业记录有一个的标志(EID).
设X是一个O数据项的集合(即是表5中一行就业记录集中的企业岗位集合),如果XE,那么称就业记录E包含X.
(1) 设置最小支持度和最小置信度.设关联规则的格式可表示为XY,其中,X⊂I,Y⊂I,并且X∩Y=∅.
定义1支持度(support):关联规则XY在就业信息数据集D中的支持度是指D中同时包含X和Y的就业记录数量与所有就业记录数量之比,记为support(XY),即
suport(X⟹Y)=
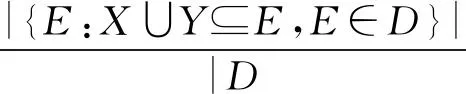
(4)
定义2置信度(confidence):关联规则XY在就业信息数据集D中的置信度是指D中包含X和Y的就业记录数量与包含X的就业记录数量之比,记为confidence(XY),即
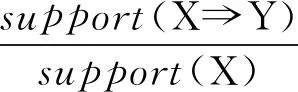
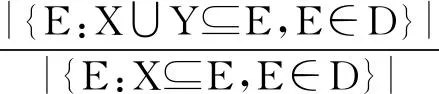
(5)
定义3频繁项集:如果一个就业记录项目集e的支持度大于用户给定的最小支持度,则此就业记录项目称为频繁项目集.
根据前面的毕业生信息和企业岗位信息聚类分析的结果, 对毕业生就业信息和就业情况进行深入分析, 有助于设置最小支持度和最小置信度.
在此,我们设置最小支持度
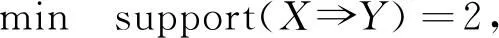
设置最小置信度
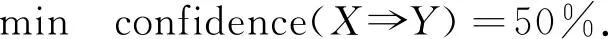
(2) 产生频繁项集.加载上节中整合的就业记录集(关联分析数据源),使用Apriori算法扫描该数据源中的所有项目集,如果某个项目集的支持度大于或等于最小支持度,则该项目集被标记为频繁项集.就业信息频繁项集分析过程如图8所示.
(3) 从频繁集中找出强关联规则.找到最大就业信息频繁项集之后,根据这些频繁项集可以得到候选关联规则.然后计算每条候选关联规则的置信度,筛选出大于最小置信度的关联规则.这些关联规则将在就业信息智能推荐时用于就业岗位信息的关联分析.
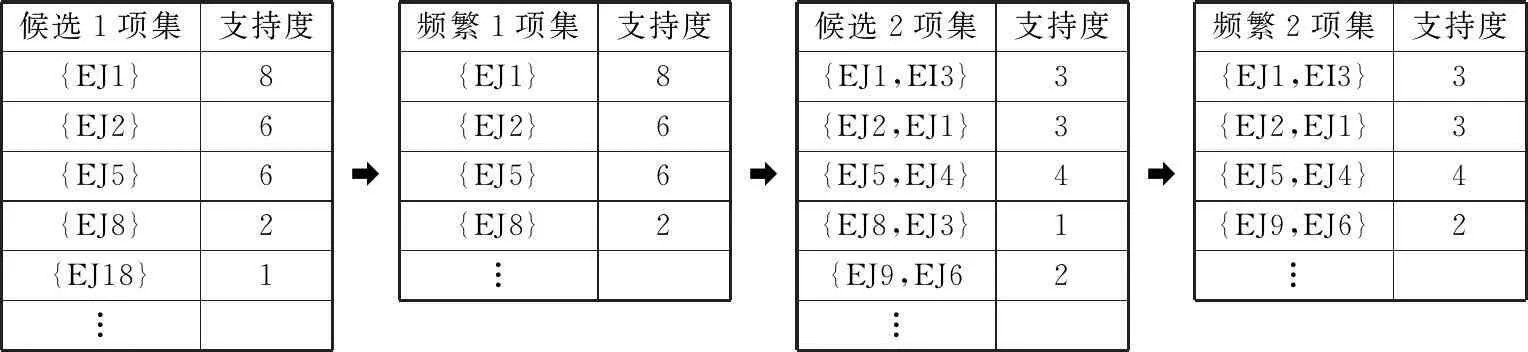
候选1项集支持度{EJ1}8{EJ2}6{EJ5}6{EJ8}2{EJ18}1︙➡频繁1项集支持度{EJ1}8{EJ2}6{EJ5}6{EJ8}2︙➡候选2项集支持度{EJ1,EI3}3{EJ2,EJ1}3{EJ5,EJ4}4{EJ8,EJ3}1{EJ9,EJ62︙➡频繁2项集支持度{EJ1,EI3}3{EJ2,EJ1}3{EJ5,EJ4}4{EJ9,EJ6}2︙
图8就业信息频繁项集分析过程
Fig.8Theprocessoffrequentitemsetanalysisofemploymentinformation
4 就业信息智能推荐
本节根据3中生成的毕业生聚类规则和企业岗位聚类规则,对当前求职的毕业生和招聘企业分别进行分类,向各毕业生自动推荐其同类学生所关联的企业岗位信息,同时将各企业自动推荐符合其岗位需求的毕业生,达到就业信息双向智能推荐的效果.
4.1面向毕业生的就业信息智能推荐
面向毕业生的就业信息智能推荐模块主要是针对当前正在求职的各高校应届毕业生,根据毕业生聚类规则对当前求职的毕业生进行分类,向各毕业生自动推荐其同类学生所关联的企业岗位信息.面向毕业生的就业信息智能推荐流程如图9所示.
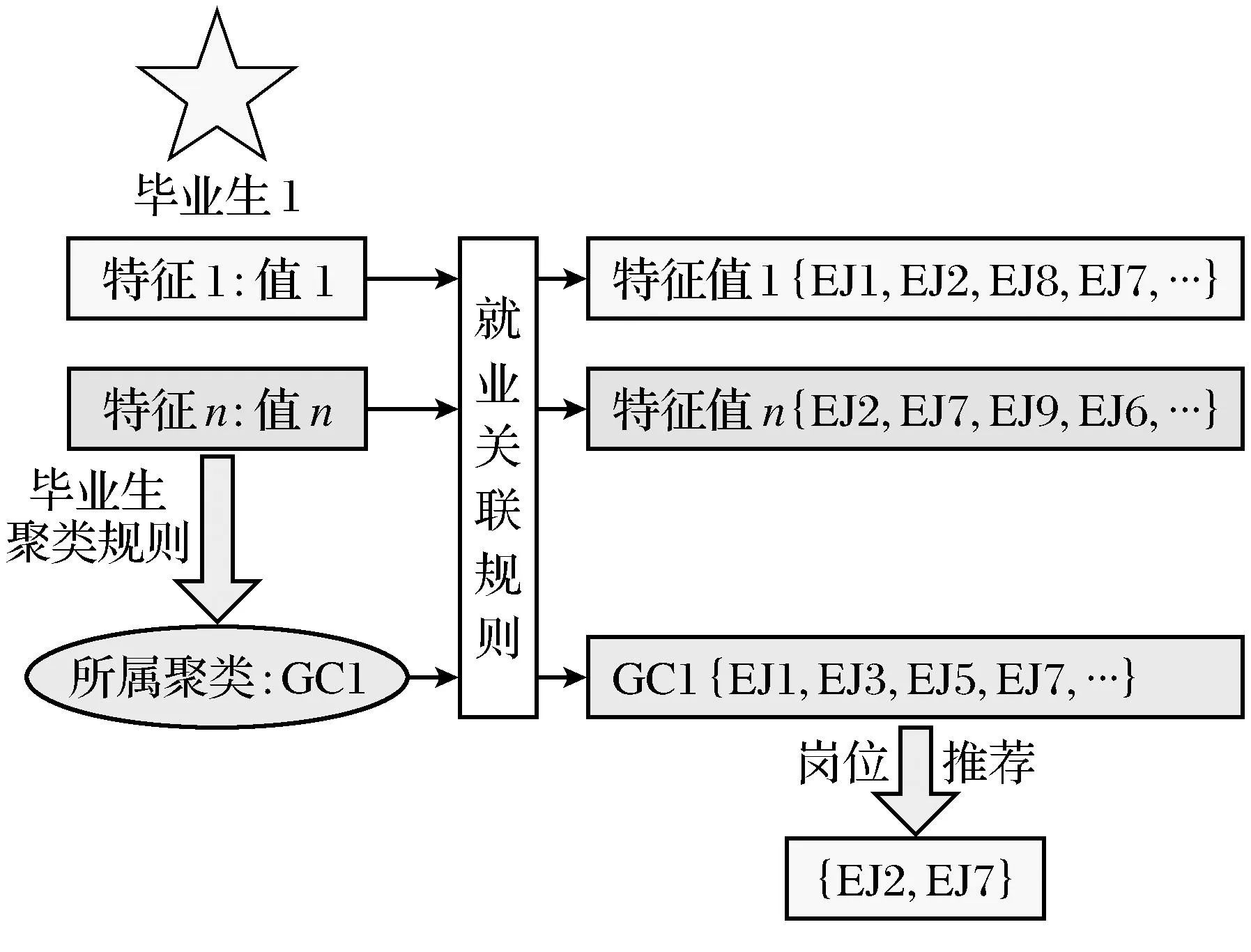
图9 面向毕业生的就业信息智能推荐流程
4.2面向企业的人才信息智能推荐
面向企业的人才信息智能推荐模块主要是针对与各高校合作开展就业工作的各个企事业单位,根据企业岗位聚类规则对当前招聘的岗位信息进行分类,向各个招聘岗位自动推荐其同类岗位所关联的毕业生人才信息.面向企业的人才信息智能推荐流程如图10所示.
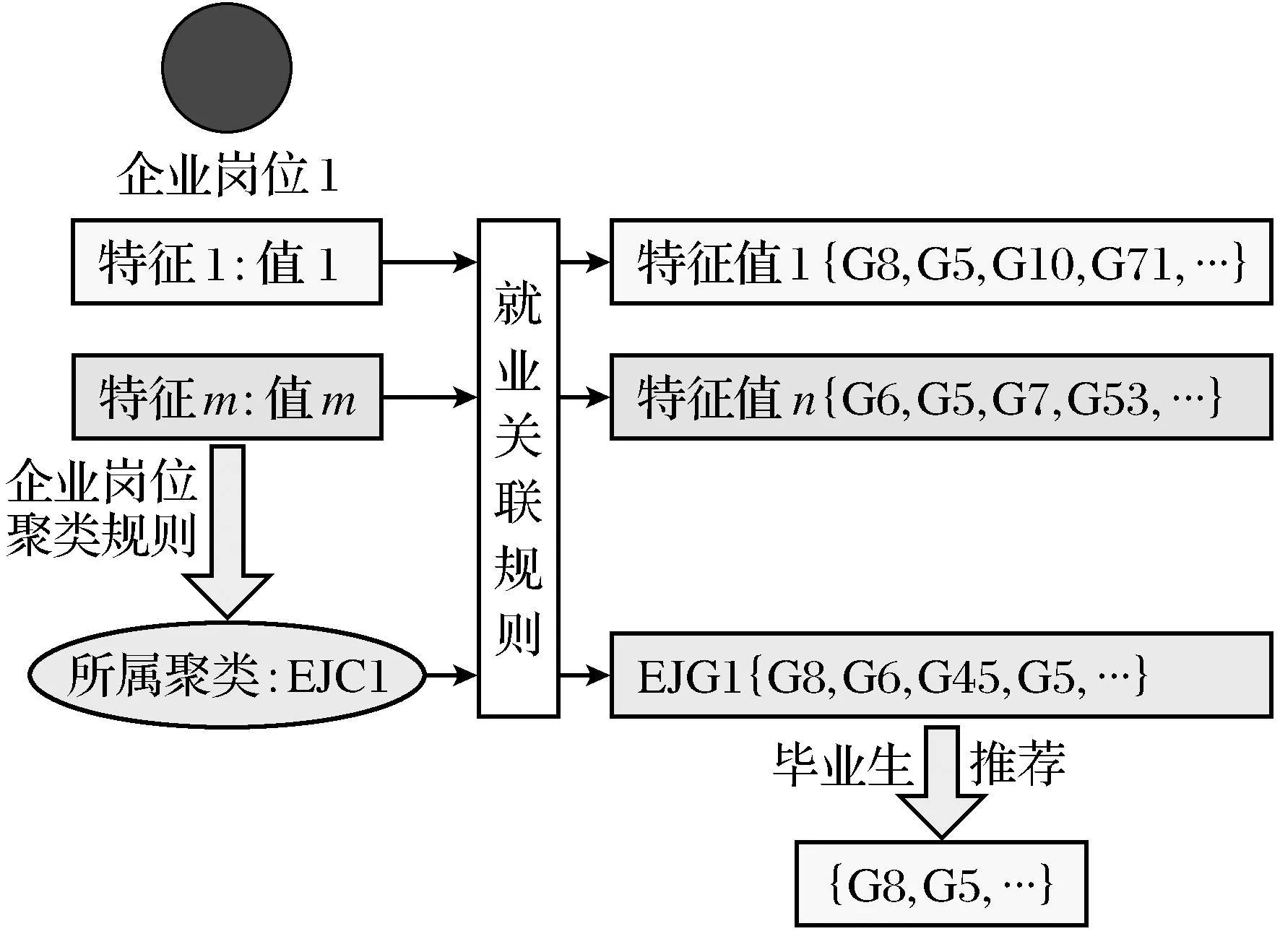
图10 面向企业的人才信息智能推荐流程
最后,本文在提出大学生就业信息智能双向推荐系统模型的基础上,对系统进行实现.系统通过对该城市5所大学于2008—2013年之间在毕业生就业管理工作过程中产生的部分就业管理工作数据进行分析和挖掘,分别提取出毕业生聚类规则及聚类信息库、企业岗位聚类规则及聚类信息库、就业信息关联规则库等.接着以某高校2014年的部分应届毕业生(800人)进行就业信息推荐实验,然后分析这些毕业生及其同专业的上届毕业生在毕业当年1~4月份的就业情况,其分析结果如图11所示.
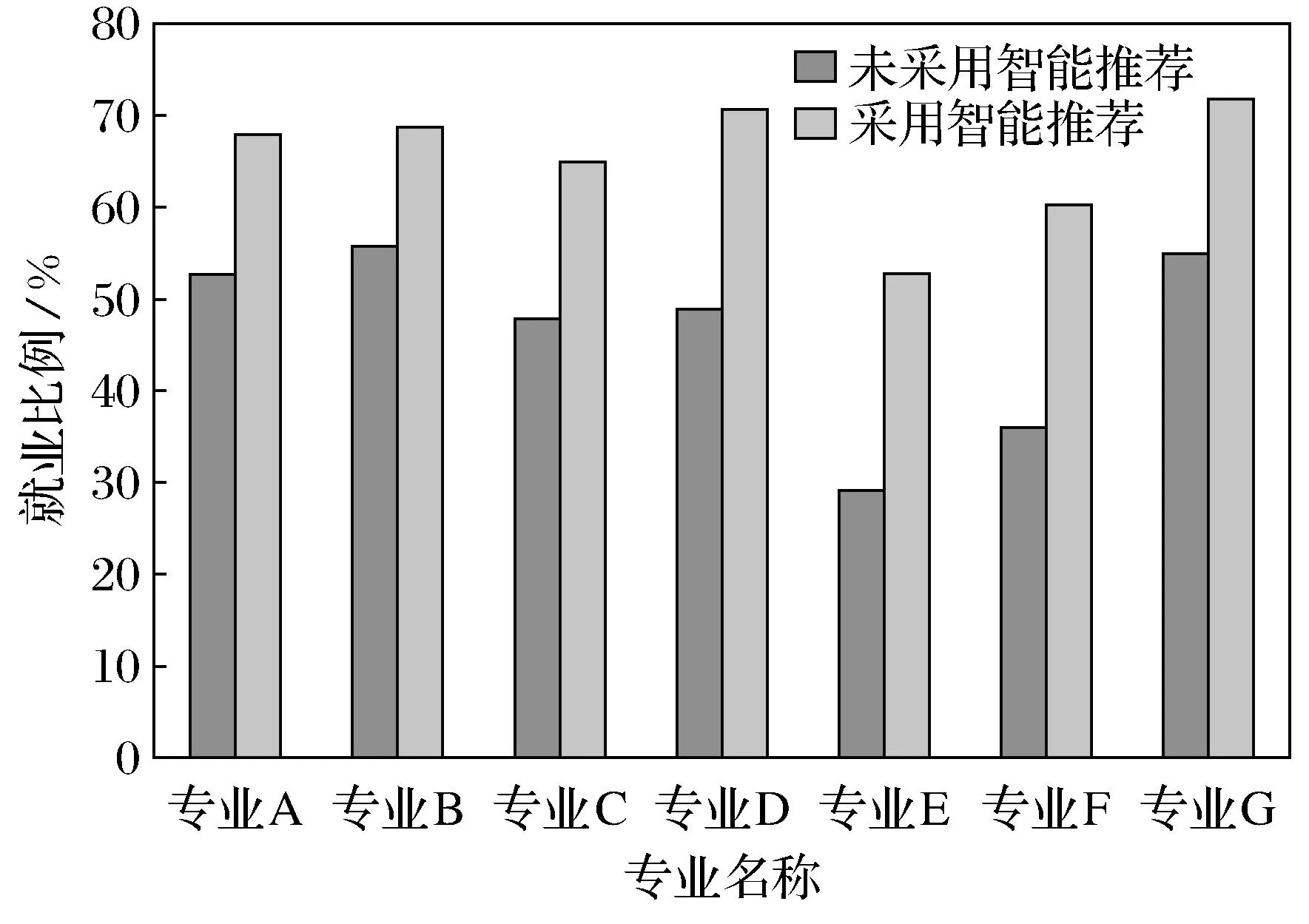
图11 某高校毕业生1~4月份就业情况分析
图11中,专业A~G分别表示计算机科学与技术、软件工程、会计学、广告学、市场营销、翻译和土木工程专业.之所以选择毕业当年1~4月份的就业情况进行对比分析,是因为这段时间是毕业生就业的相对较集中的时间段,在这个阶段进行智能推荐可以取得较好的推荐效果.实验结果表明,使用本智能推荐系统后,该学校各个专业的毕业生在1~4月份的就业比率同比前一年有明显增长.
接着,系统对该城市中到高校开展招聘工作的部分合作企业进行毕业生信息推荐实验,然后分别调查这些企业的具体招聘岗位及该企业同岗位于前一年1~4月份的招聘工作完成情况进行对比,其分析结果如图12所示.
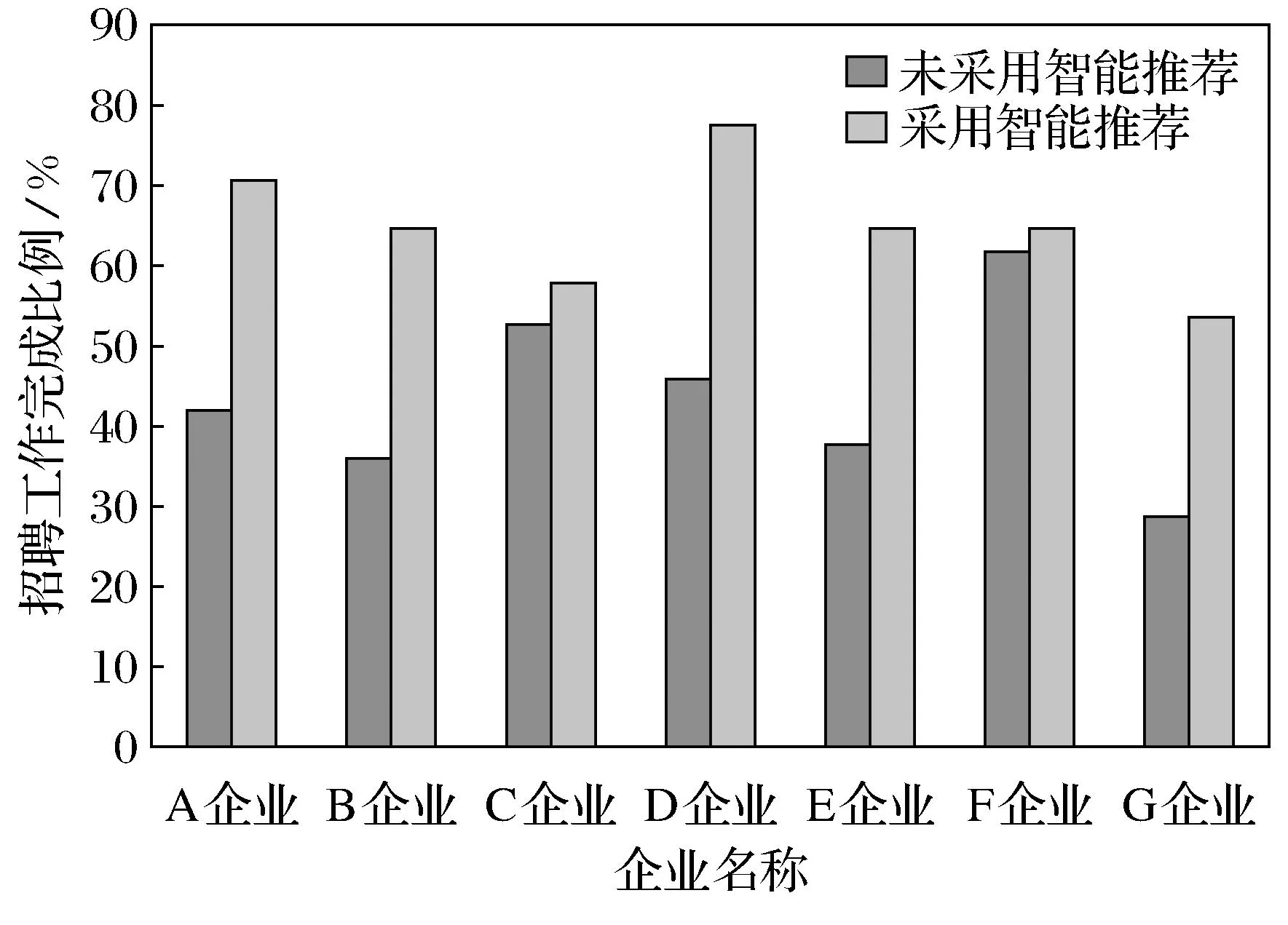
图12 合作企业1~4月份招聘情况分析
实验结果表明,大部分合作企业在使用本智能推荐系统后,1~4月份的招聘工作完成比率同比前一年有明显增长.
5 结 论
文章提出一种基于数据挖掘的大学生就业信息双向推荐系统方案,通过分析某城市各高校历年毕业生就业管理工作中积累的大量就业数据信息,分别对毕业生信息和企业招聘信息进行聚类分析,同时对各毕业生与其成功就职的企业和岗位信息进行关联分析.根据聚类规则对当前求职的毕业生和招聘企业分别进行分类,向各毕业生自动推荐其同类学生所关联的企业及岗位信息,向各企业自动推荐符合其岗位需求的毕业生信息.
系统测试结果表明:本系统运行稳定,能够对毕业生信息和企业信息进行准确聚类,根据毕业生信息分析并推荐最质量的就业岗位信息,同时分析企业岗位招聘要求并推荐相应的毕业生,实现毕业生和企业之间双向推荐功能.系统达到预期设计目标,满足高校就业管理工作的应用要求.
参考文献:
[1]ChenXJ,XuXF,HuangJZ,etal.TW-K-Means:AutomatedTwo-LevelVariableWeightingClusteringAlgorithmforMultiviewData[J].IEEETransactionsonKnowledgeandDataEngineering, 2013,25(4):932-944.
[2]张嘉赢,刘井莲,赵卫绩. 一种基于半布尔矩阵的混合维关联规则算法[J]. 沈阳大学学报, 2008,20(2):19-21.
(ZhangJiaying,LiuJinglian,ZhaoWeiji.Hybrid-DimensionAssociationRulesAlgorithmBasedonHalf-BooleanMatrix[J].JournalofShenyangUniversity, 2008,20(2):19-21.)
[3]原忠虎,李佳,张博. 一种加权的系统聚类方法及应用[J]. 沈阳大学学报:自然科学版, 2014,26(3):201-207.
(YuanZhonghu,LiJia,ZhangBo.AWeightedSystemClusteringMethodanditsApplication[J].JournalofShenyangUniversity:NaturalScience, 2014,26(3):201-207.
[4]PengXS,ZhouCK,HepburnDM.etal.ApplicationofK-MeansMethodtoPatternRecognitioninOn-LineCablePartialDischargeMonitoring[J].IEEETransactionsonDielectricsandElectricalInsulation, 2013,20(3):754-761.
[5]ShiY,TrancheventLC,LiuXH,etal.OptimizedDataFusionforKernelK-MeansClustering[M]∥Kernel-BasedDataFusionforMachineLearning.London:SpringerBerlinHeidelberg, 2011:89-107.
[6]丁静,杨善林,罗贺,等. 云计算环境下的数据挖掘服务模式[J]. 计算机科学. 2012,39(6A):217-237.
(DingJing,YangShanlin,LuoHe,etal.DataMiningServiceModelinCloudComputingEnvironment[J].ComputerScience, 2012,39(6A):217-237.)
[7]BoutsidisC,Magdon-IsmailM.DeterministicFeatureSelectionforK-MeansClustering[J].IEEETransactionsonInformationTheory, 2013,59(9):6099-6110.
[8]XuTT,DongXJ.MiningFrequentPatternswithMultipleMinimumSupportsUsingBasicApriori[C]∥2013NinthInternationalConferenceonNaturalComputation(ICNC),Shenyang, 2013:957-961.
[9]PengY,ZhouT.ResearchontheAprioriAlgorithminExtractingtheKeyFactor[C]∥2012IEEE2ndInternationalConferenceonCloudComputingandIntelligentSystems(CCIS).Hangzhou, 2012:90-93.
[10]PaladinoR,camposJM,PereiraW.StudyoftheGraduatesfromComputerScienceDepartmentoftheCatholicUniversityAndresBellinCaracas[C]∥ComputingConference(CLEI), 2014XLLatinAmerican2014,Montevideo:1-8.
【责任编辑:曹一萍】

BidirectionalRecommendationSystemforUniversityStudentEmploymentInformationBasedonDataMining
Liu Yuhua1,ChenJianguo1,2, Zhang Chunyan1
(1.SoftwareCollege,FujianUniversityofTechnology,Fuzhou350003,China; 2.CollegeofComputerScienceandElectronicEngineering,HunanUniversity,Changsha410082,China)
Abstract:Focusing on the issues in university student employment process that university graduates cannot access high quality recruitment information timely and accurate, and enterprises cannot access talents information accord with the post requirements conveniently, a bidirectional recommendation system for university student employment information based on data mining is proposed. By analyzing the large number of employment data information which is accumulated from the university graduates employment management work for many years, the clustering analysis on the graduates information and enterprise job information is done separately; and the association analysis on the graduates and the enterprises which employed them is made. The current graduates and recruitment enterprises are classified according to the clustering rules trained from above, the enterprises’ job information could be recommended for each student automatically, and the graduates’ information could be commended to related enterprises. The experiment shows that the system uses the university employment information resource sharing mechanism effectively; realizes the clustering of each university’s graduates and enterprise job information accurately; and achieves bidirectional recommendation between graduates and enterprises.
Key words:bidirectional recommended; employment information; data mining; cluster analysis; association analysis
作者简介:刘玉华(1985-),女,福建福州人,福建工程学院助教.
基金项目:福建省教育科学“十二五”规划课题(2014CG1363).
收稿日期:2014-12-23
文章编号:2095-5456(2015)03-0226-07
中图分类号:TP311.13
文献标志码:A
