基于ICE的分布式爬虫设计与实现
2015-12-02雷滋和陶宏才
雷滋和, 陶宏才
(西南交通大学信息科学与技术学院,四川成都611756)
0 引言
随着移动智能和互联网信息技术的飞速发展,近年来,Twitter、Facebook、新浪微博为代表的社交网络[1]的出现和快速发展深深地影响了人们的交流方式,成为生活中不可或缺的一部分。社交网络集交友、传媒、电商等多种功能于一体,吸引了不同年龄段、不同性别、不同职业、不同国籍的大量用户。
微博是一种社交网站,不过随着快速发展及用户的需求,已经逐渐演变成一种社会化自媒体。平台中媒体用户利用微博吸引关注,偶像明星利用微博保持和粉丝的交流,商家用户利用微博发布一些促销信息和商品广告。草根用户利用微博关注最新新闻和亲朋好友的最新动态。微博平台由于自身的一些特性,如简洁性、传播性、实时性等,吸引了大量用户。
由于社交网络吸引了大量用户,因此,对社交网络数据的分析管理也有很多研究。通过对微博数据的挖掘,可以分析预测用户的爱好,获取社会热点新闻舆论,挖掘人际关系,预测信息传播趋势等。同时,通过挖掘用户兴趣,也可进行商业推广等。不过,要做到上述这些数据的分析,最重要的一步就是需要进行数据采集。为此,针对新浪微博,采用中间件ICE,设计实现了一个分布式网络爬虫系统,以采集微博数据。
1 技术简介
1.1 爬虫技术
网络爬虫(Crawler)又称为网页蜘蛛,是一种按照某个规则自动从互联网获取信息资源的程序。爬虫从一个或多个初始的页面URL开始,通过分析源文件中的URL,提取出新的URL链接;然后又利用这些链接,继续寻找新的链接。如此不断循环,直至抓取和分析完所有页面。作为搜索引擎和网络数据挖掘的基础组成部分,网络爬虫起着重要的数据采集作用。
早期的Google爬虫由斯坦福大学设计[3]。该爬虫由一个URL服务器将URL分发到若干爬虫节点,各爬虫通过单线程异步I/O方式爬取网页。Mercator[4]爬虫由康柏系统研究中心的 Allan Heydon和MarcNajork开发,采用多线程同步方式以及一些优化策略(如DNS缓冲、延迟存储等)爬取网页。国内也有机构对爬虫进行研究,例如,北大天网[5]开发的分布式网络爬虫,采用两阶段哈希机制实现了亿级数量的网页爬取。
1.2 ICE中间件技术
ICE网络通信引擎[6-7],是一种面向对象的高性能中间件,提供完善的、适合于异构网络环境的分布式系统解决方案,包括库、API和工具。

图1 ICE逻辑结构图
图1展示了ICE客户与服务器内部的逻辑结构图,服务端与客户端是由ICE核心库、Slice接口的生成代码以及应用程序代码组成。ICE核心库包含网络通信、多线程等一些链接库且提供了API接口,应用程序通过ICE API可访问核心库并进行事务管理。代理由Slice接口生成,主要有2个功能:(1)为客户提供访问服务端接口;(2)为数据传输提供整编和解编功能,整编将复杂的数据结构序列化,转换为数据传输的标准形式,解编则将收到的数据反序列化。骨架亦由Slice接口生成,是代理在服务端的等价物,提供向上调用接口及整编和解编功能。对象适配器为ICE API之一,负责创建传给客户的代理,且将客户端的请求转换成服务端对应对象上的特定方法。
2 分布式爬虫的设计实现
2.1 爬虫基本结构
分布式爬虫一般分为主从式和对等式2种结构,文中采用主从式结构进行分布式爬虫的设计,系统分为服务端和客户端。服务端能够进行任务的调度与数据存储,客户端进行数据的爬取。客户端与服务端进行通信时,文中采用ICE中间件技术进行通信。
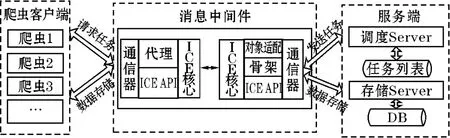
图2 分布式爬虫框架
图2给出整个爬虫的架构图。整个爬虫框架主要分为3部分:
(1)消息中间件。为客户端和服务端提供通信。
(2)爬虫服务端。爬虫服务端包括2个模块:调度服务和存储服务。调度服务端从任务列表中取出任务后,向爬虫客户端分发任务;存储服务端负责将爬虫爬取到的数据存储到DB中。
(3)爬虫客户端。主要分布于各个节点上,爬虫客户端从调度服务器获取任务,然后进行微博数据爬取,将爬取到的数据发送到存储服务器,进行统一存储。
框架通过ICE中间件技术,将各个功能模块分布到各个Server上,各个模块分工明确,并且不相互干扰。如若爬取更多数据,只需要增加爬虫客户端即可。
2.2 ICE中间件设计
作为一个面向对象的中间件平台,ICE提供了一系列的工具、API和库建立面向对象的客户端和服务器的网络通信,ICE适合在异构环境中应用,并且应用的源码都可以移植。
图3给出基于ICE应用程序的开发流程。系统开发时首先需要定制公共接口,其功能在服务端实现。通过接口,爬虫客户端可以向服务端发送请求,服务端根据接口的请求完成相应的操作。ICE通过Slice语言来编写公共的接口文件,它是以一种独立于特定编程语言的方式定义数据、接口、操作等,然后通过ICE内置编译器转换成特定语言的API。在编写ICE应用时,均需进行Slice接口的定义。

图3 开发流程
在爬虫系统中,涉及到服务模块在爬虫系统中担当着不同的任务,因此,这里给定2个Slice。表1给出涉及到的2个服务模块同爬虫客户端的接口。
可以看到,在Slice中,定义爬虫服务端与客户端进行交互的数据类型以及相对应的接口。在Slice定义后,可以根据Slice生成相应的骨架和代理。ICE提供了生成骨架和代理的工具,基于Python语言,生成骨架和代理代码如下:
Ice.loadSlice('scheduler_server.ice')
import weiboCrawler
通过loadSlice,即可将Slice语言转换成骨架(或代理),在形成的骨架(或代理)中,不仅包含所定义的接口,源码同时为客户和服务器提供针对特定类型的运行时支持。在接口确定后,便可以进行爬虫服务端和客户端的开发。服务端实现接口中所定义的功能,客户端通过代理,调用接口中的方法,便可在服务端执行对应的方法,实现与服务端的交互。需要说明的是,图3中最下一层形成的即是图2的分布式爬虫框架。其中,用2个简略的ICE框表示图2中的中间件部分。

表1 调度服务模块和存储服务模块的Slice接口
2.3 爬虫服务端设计
由Slice生成的骨架类是一个抽象的接口类,在服务端进行设计时,需要继承骨架类,并将对应接口的功能实现。爬虫系统包含调度服务和存储服务2个服务端。
2.3.1 调度服务
模块为整个爬虫系统的控制节点,整个爬虫系统需要依赖此节点获取爬取任务。客户端通过接口获取需要爬取的微博用户ID,在爬取完毕后通过接口通知调度服务。因此,服务模块与客户端交互有2个接口:
getUser:爬虫客户端通过该接口获取需要爬取的用户ID。
putUser:爬虫客户端通过该接口通知调度服务某个微博用户爬取完毕。
系统通过任务队列的方式来实现任务的调度。在系统中,爬取一个微博用户微博数据为一条任务,客户端通过从服务端获取所要爬取的微博用户ID即任务ID对微博数据进行爬取。系统采用ICE内置数据库Berkeley DB实现任务队列。系统中涉及2个数据库,一个用来存储未爬取的用户ID,另一个存储已经爬取完毕的用户ID。客户端获取时,都是从未爬取的数据库中获取需要爬取的用户ID,通过2个数据库,起到了任务队列的作用。系统进行任务调度的主要流程为:启动调度服务端,系统读取未爬取的微博用户ID到任务队列;客户端通过接口从服务端获取任务;服务端从任务队列取出任务ID,分发给客户端;客户端执行任务完毕,通知服务端,服务端将完成的任务ID存储到数据库中去。
2.3.2 存储服务
模块为爬虫系统的存储节点,所有爬虫客户端爬取的微博数据都会发送到本模块进行存储。模块为爬虫客户端提供的接口为writeWB,客户端通过调用该接口即可进行数据的存储。
系统采用分布式数据库Hbase[9]对爬取的微博数据存储,HBase是一个分布式的、面向列的开源数据库,适合非结构化数据存储的数据库。文中主要对微博数据的ID、内容、用户ID、发布时间等字段存储。系统中通过Thrift来对Hbase进行访问,存储微博数据。存储微博数据的具体流程为:启动 Hbase并启动Hbase的Thrift服务;通过Thrift与Hbase建立服务;启动爬虫的存储服务,爬虫客户端通过接口将爬取的微博数据发送到服务端;服务端接收到数据后,利用Thrift API将微博数据存储于数据库中去。
在调度服务和存储服务完成对应功能后,均需要建立一个通信器(communicator),完成对ICE运行时服务的初始化。然后,创建一个对象适配器(adapter),并创建代理接口、设置代理标识,用以将客户的请求映射到编程语言对象上的特定方法创建可以传给客户的代理。系统涉及2个标识,分别是调度服务和存储服务,客户端通过这2个标识可以识别对应的代理。设置好后,将代理增加到适配器中去。具体过程如下面代码所示:

服务端在创建完毕后,通过适配器的activate方法将其激活,然后调用waitForShutdown方法启动通信器,以响应和处理客户端发出的连接请求。
2.4 爬虫客户端设计
在进行客户端的功能开发时,客户端需要与服务端取得通信。客户端与服务端的一次通信过程为:创建通信器,初始化ICE运行时服务;通过服务端地址和代理标识,获取服务端在客户端的远程代理;客户端通过代理调用接口中的方法,与服务端进行通信;客户端执行完毕,通信结束,销毁通信器。至此,客户端与服务端就完成一次通信。
爬虫客户端进行初始化的代码如下所示:

每个爬虫节点创建一个通信器,通过初始化服务代理Prx并且调用checkedCast方法,将服务代理转换成服务端在客户端对应的代理,爬虫系统中,包含调度代理和存储代理2个代理。ICE运行时,在库的支持下,每个节点与服务器的通信器就建立了连接。然后,爬虫节点就可以通过代理Prx调用接口中数据和方法。这样,访问远程对象和数据就如同本地访问一样,实际代码运行于服务端。爬虫节点正是利用这个特点,与调度服务及存储服务进行数据的交互。
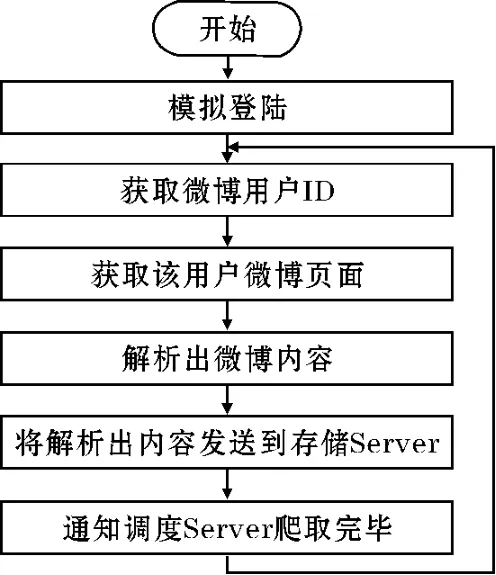
图4 爬取流程
爬虫节点主要负责从网络上爬取数据,具体流程如图4所示。
(1)模拟登录。微博同传统的web网站不同,以前的网站不需要登录,而微博需要进入个人主页需要登录,否则访问将会跳转到登录页面。因此,在进行数据爬取时,需要设计登录模块,只有登录后的用户才可进行微博数据的爬取。文中采用SESSION机制,通过COOKIE和URL重写实现用户登录。
(2)登录成功后,爬虫通过调度服务端代理,与调度服务端进行通信,获取微博用户的ID,利用用户ID和新浪微博url(http://weibo.com/aj/mblog/mbloglist)分段抓取用户的微博数据。此时返回的是JSON数据,需先将JSON解析,然后利用BeautifulSoup解析出用户的每条微博数据。Beautiful Soup提供一些简单的、python式的函数处理导航、搜索、修改分析树等。它是一个工具箱,通过解析文档为用户提供需要抓取的数据。
(3)解析完毕后,爬虫利用存储端代理,访问数据存储方法,将解析的数据发送到存储模块,进行微博数据的存储。
(4)爬虫节点爬取完一个客户的微博数据后,通知调度服务器爬取完毕,同时会重新获取新的用户ID,重新进行爬取。
3 系统部署与运行
实验采用了5台机器,图5为实验网络拓扑图。各机器均为Linux环境,通过无线路由器TL-WR841N(通过100 Mbps WAN口连至Internet)通信。各机器的具体配置如表2所示。

表2 系统部署
实验中,调度模块部署在机器a上,机器b用于存储微博数据,其余3台机器为爬虫节点,用于爬取微博数据。系统在爬虫节点配置了新浪微博账号进行登录验证后,即可对数据进行爬取。尽管新浪微博开放平台提供了访问接口,但基于该接口的爬虫在爬取数据时,需要申请访问授权并受访问次数限制。与这种基于微博开放平台访问接口的爬虫不同,系统勿需授权申请且不受访问次数限制,通过在各个爬虫节点对访问网页频率进行设置,能有效避免因爬取过快而导致的爬取失败。实验了相同时间内不同爬虫节点数下系统的爬取效果,如表3所示。由表3可以看到,随着爬虫节点数的增加,系统爬取的微博数量亦在成倍增加。因此,系统只需增加新的爬虫节点,勿需对已有系统进行变更,就能极大提高系统的爬取能力,具有较强的适应性和可扩展性。

表3 相同时间内不同爬虫节点数下系统的爬取效果
4 结束语
结合消息中间件ICE设计实现一个分布式爬虫系统。文中介绍爬虫及ICE工作原理,讨论基于ICE中间件的分布式爬虫的实现方法。基于ICE,将爬虫的各个模块独立开来,系统具有可扩展性、适应性。实验表明,爬虫系统能够快速地从互联网爬取微博数据。
[1] 李林容.社交网络的特性及其发展趋势[J].新闻界,2010,(5):32-34.
[2] 周德懋,李舟军.高性能网络爬虫:研究综述[J].计算机科学,2009,36(8):26-29.
[3] Brin S,Page L.The anatomy of a large-scale hypertextual Web search engine[J].Computer Networks& Isdn Systems,1998,30(98):107-117.
[4] Heydon A,Najork M.Mercator:A scalable,extensible Web crawler[J].World Wide Web-internet& Web Information Systems,1999,2(4):219-229.
[5] 北京大学天网搜索引擎[EB/OL].http://e.pku.edu.cn,2015-05-06.
[6] 聂彤彤.中间件技术的发展与应用[J].中国信息导报,2005,(7):59-61.
[7] Henning M,Spruiell M.Distributed Programming with Ice[R].Zeroc Inc Revision,2003.
[8] Leader-us.ZeroC Ice权威指南[M].北京:电子工业出版社.
[9] Apache HBase Reference Guide[EB/OL].http://hbase.apache.org/book.html,2015-06-08.
[10] 刘裕,吴坚.中间件技术与ICE[J].微机发展,2004,14(10):37-39.
[11] 张俊军,章旋.ICE中间件技术及其应用研究[J].计算机与现代化,2012(5):192-194.
[12] Boldi P,Codenotti B,Santini M,et al.Ubi-Crawler:a scalable fully distributed Web crawler[J].Software Practice& Experience,2004,34(8):711-726.
[13] 丁云亮,谷利泽,杨榆.基于分布式中间件ICE的应用架构研究[J].计算机应用,2009,29(S2):27-28.
[14] Zhang L,Yun ming Y E,Song H,et al.Design and Implementation of a Distributed High-Performance Web Crawler[J].Journal of Shanghai Jiaotong University,2004,38(1):59-61.
[15] 叶允明,于水,马范援,等.分布式Web Crawler的研究:结构、算法和策略[J].电子学报,2002,30(S1):2008-2011.
[16] 许笑,张伟哲,张宏莉,等.广域网分布式Web爬虫[J].软件学报,2010,21(5):1067-1082.
