Hadoop平台下垃圾邮件过滤技术研究*
2015-09-21刘广钟
李 毅,刘广钟
(上海海事大学 信息工程学院,上海 201306)
0 引言
电子邮件作为网络最基本的服务,已成为人们生活中不可或缺的一部分。截止2014年12月,中国网民规模达到6.49亿,电子邮件用户规模3.9亿,占网民总数的60.1%[1]。在其中充斥着的海量垃圾邮件给人们的生活带来了困扰,如何处理海量垃圾邮件已经成为亟待解决的重要问题。
在目前存在的垃圾邮件过滤技术中,以过滤垃圾邮件时使用的过滤方法作为分类点,可将这些垃圾邮件过滤技术分为以下三种:基于黑白名单的过滤技术[2]、基于规则的过滤技术[3]、基于内容统计的过滤技术。其中,贝叶斯垃圾邮件过滤技术分类能力和准确性较高,但其前期需要对训练样本进行大量的训练学习,对训练样本依赖性较强。海量垃圾邮件的出现使得传统的方法无法满足需要,随着云计算Hadoop的出现和发展,Hadoop MapReduce模型为海量垃圾邮件的过滤提供了新思路。
针对传统贝叶斯垃圾邮件过滤算法的缺点,本文对贝叶斯垃圾邮件过滤算法与MapReduce编程模型的结合进行了研究,提出了垃圾邮件过滤的数学模型,并在此基础上对判定邮件所属类别的决策分类方法给出了一定的改进。
1 研究基础介绍
1.1 贝叶斯定理
贝叶斯定理由条件概率和全概率组成,主要用于在已知事件A发生的条件下,判断A是伴随着{B1,B2,…,Br}中哪个事件发生。E是随机试验,对于E的每一次事件A发生的概率,记为 P(A)。设A,B为两个事件,且 P(A)>0。如果两个事件A和B不是相互独立的,并且已知事件B中的一个事件已经发生,则能得到关于P(A)的信息。这反映为A在B中的条件概率,其计算公式如式(1)所示:

P(A)通常称为先验概率,而条件概率 P(A|B)称为后验概率。
对于一个统计实验,样本空间S是所有可能结果的集合,并且{B1,B2,…,Br}是 S 的一个划分。 令{p(A);A⊆S}表示定义在S中所有事件的一个概率分布。式(2)为贝叶斯定理的表示:

1.2 Hadoop平台下邮件流提取和流重组的实现
电子邮件流重组就是对所有五元组中端口为25和110的TCP流进行重组。通过对TCP流序列号的排序重组即可以重组出原邮件流。在建立TCP连接的三次握手时,发送方和接收方会相互发送TCP头部中的握手报文(即SYN报文,其中SYN=1),而在结束时会互相发送TCP头部中FIN报文(即FIN报文)。通过获取以上两种报文,可以容易地通过FIN报文与SYN报文的seq差值与FIN报文大小的和,求出本条TCP流的长度。用来区别不同的TCP流的标志为五元组[4](即源IP、源端口号、目的IP、目的端口号、传输层协议),其能够对不同的TCP会话进行区分。Hadoop平台下流提取重组的MapReduce[5]过程如图 1所示。

图1 MapReduce流重组方法流程
完成完整的邮件流重组必须从该五元组对应的流中获取带有 SYN=1与 FIN=1(或 RST)的报文。当 TCP出现乱序或者重传覆盖时,对这些流按照seq进行重新排序。对于不完整的TCP流进行丢弃处理。
HDFS进行大规模流量文件的分割,InputFormat将输入的大规模报文文件分割为若干InputSplit,每一个InputSplit将单独作为Map的输入。每条流形成一个键值对<k1,v1>,此处 k1表示报文在文件中的偏移量,v1表示整条报文内容。
(1)Map 阶段: 对每个<k1,v1>键值对进行处理,从报文内容中提取出每条报文的五元组信息,得到<k2,v2>,其中k2为报文的五元组信息,v2是从IP层开始的整个报文。
(2)Combine阶段:Combine相当于对每个 DataNode结点上的数据流进行流重组,此时以Map阶段的输出作为Combine阶段的输入。之后通过指针从报文信息中提取每条报文的 SYN、FIN、TCP 中的序号。以<k3,v3>作为输出,k3为每条报文的五元组信息,v3为每条报文的数组。
(3)Shuffle阶段:在 Shuffle阶段输入为<k3,v3>输出为<k4,v4>,完成局部的流重组整合,也就是对在 Combine阶段未完成的流重组过程继续完成,这样可以有效减少在Reduce的计算压力。
(4)Reduce阶段:接收到 Shuffle的输出后,对每个键值对进行处理,完成在Combine阶段和Shuffle阶段未完成的流重组过程。如果经过以上阶段,发现有的流重组出来是不完整的,则将这条流丢弃。
Reduce阶段完成后,将Reduce处理好的流交给OutputFormat(即 MyOutputFormat)类。 它将重组好的报文写入文件中。按照以上流程即可完成POP3和SMTP邮件的相关流重组。
2 Hadoop平台下贝叶斯垃圾邮件过滤
2.1 改进的贝叶斯垃圾邮件过滤算法
贝叶斯方法包括两个步骤:训练样本和分类,其实质是把邮件判定为垃圾邮件或者正常邮件。假设邮件的特征词集合为d,且d中的各特征词之间相互独立,则构建过滤器的过程如下。
首先收集大量的垃圾邮件和正常邮件,并将其分为垃圾邮件集和正常邮件集两组。之后对过滤器进行训练。假定在训练集中,垃圾邮件有S封,正常邮件有H封,垃圾邮件有 n个特征词{w1,w2,…,wn}。在模型建立时,假设垃圾邮件有 2个特征词,即 d={w1,w2},则当特征词出现时,该封邮件属于垃圾邮件的概率为 P(Spam|w1),而属于正常邮件的概率为 P(Ham|w1);当特征词 w2出现时,该邮件属于垃圾邮件的概率为 P(Spam|w2),而属于正常邮件的概率为P(Ham|w2)。则根据贝叶斯定理有如下推论:

在邮件的特征词 w1,w2出现的情况下,令 P(Spam|w1)=p1,P(Spam|w2)=p2,则邮件属于垃圾邮件的概率如式(5)所示:

若 d={w1,w2,…,wn},则可以进行如下处理:将训练集中的S封垃圾邮件进行训练,查看垃圾邮件中是否存在这些特征词,假设 d={w1,w2,…,wn}对应出现的数量为{f1,f2,…,fn}。则此时,邮件属于垃圾邮件类概率为:
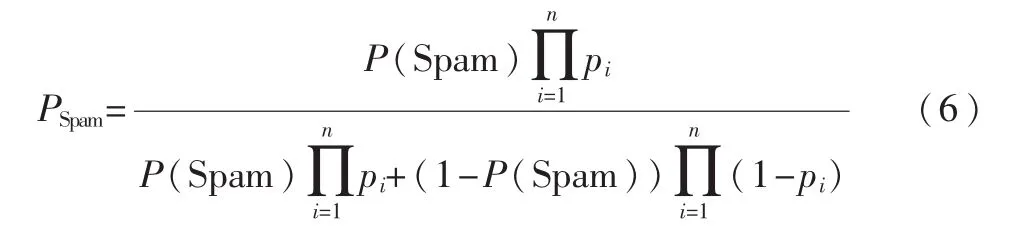
在一般情况下,假设待分类邮件di计算出的PSpam值为 pi,其中 1≤i≤N,N为待分类的邮件总数。此处假设pi是有序递增的,即存在 pi≤pj,其中 1≤i≤j≤N。 假设阈值为 Q,存在 x,1≤x<N,使得 px<Q,而 px+1≥Q,则可判定,前x封邮件归为正常邮件Ham类,后N-x封邮件归为Spam类。
下文对阈值的设定进行改进,在系统判定为正常邮件的前面x封邮件中,错误判定类别的邮件数量和正确判定类别的邮件数量的期望分别如式(7)、式(8)所示:

在判定为垃圾邮件的后面N-x封邮件中正确判定类别和错误判定类别的期望如式(9)、式(10)所示:
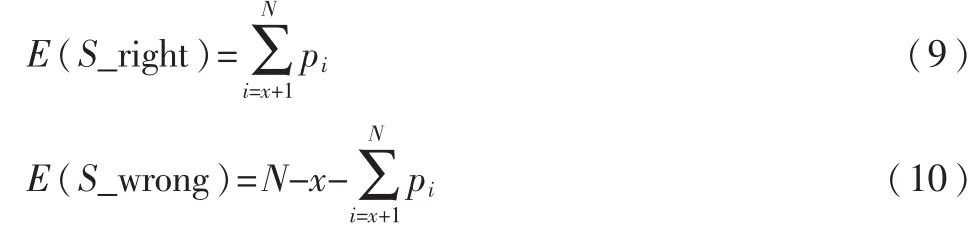
使用上述期望可求出垃圾邮件过滤系统的四个指标[7],如式(11)~式(14)所示:

随着 Q 的增加,P(x)会增大,R(x)会降低;反之,随着 Q 变小,P(x)会降低,R(x)会增大,因此可以求出使F值达到极值的 Q。记 SN为数列{pi}的前 N项和,因为0<T(x)<1,0<P(x)<1,0<R(x)<1,因此,0<F(x)<1。 对于待分类邮件来说,N 和 SN均为常数。 对 F(x)、T(x)求导可得式(15)、式(16),令 F′(x)=0,则可得式(17)。
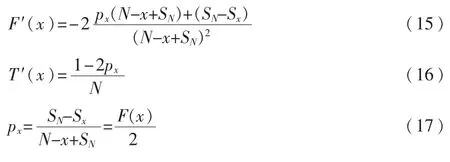
2.2 垃圾邮件过滤技术的MapReduce模型
Hadoop平台下的垃圾邮件过滤技术的MapReduce模型分为两阶段:邮件训练样本阶段和邮件分类阶段。
邮件训练阶段的MapReduce过程如图2所示。第一个MapRecue阶段抽取垃圾邮件的特征,MapReduce输入为已经分好类的垃圾邮件集合,通过Map和Reduce得出垃圾邮件特征词词频。第二个MapReduce过程计算正常邮件类别的特征词词频,以分类的正常邮件集作为MapReduce的输入,输出为每封邮件对应的正常邮件特征词的词频。第三个MapReduce作业计算出垃圾邮件特征词的条件概率,以前面两个MapReduce作业的输出作为输入,通过MapReduce得出每个类别的特征词相应的联合条件概率。结合垃圾邮件和正常邮件类别的先验概率,形成n个特征词的邮件训练库。

图2 邮件训练阶段MapReduce流程图
邮件分类阶段的MapReduce过程如图3所示。总共分为两个过程,第一个MapReduce过程计算待过滤邮件的特征词词汇及其词频,输入为待过滤邮件集合,通过Map和Reduce得出特征词的词频。此过程与训练阶段的第一个MapReduce过程类似。第二个MapReduce过程接收第一个MapReduce过程生成的中间数据及邮件训练结果集,通过MapReduce计算出每个待分类邮件属于垃圾邮件的概率,并且与阈值Q比较,判断邮件所属的类别。

图3 邮件分类阶段MapReduce流程图
3 相关实验
3.1 实验数据和实验环境
为保证实验内容的真实性,本文采用上海海事大学信息工程学院出口网关上截获的40 258封邮件作为本次实验的数据集,其中包含垃圾邮件20 132封,正常邮件20 126封,为了保证实验的可靠性和平均分配,首先将垃圾邮件随机剔除32封,正常邮件随机剔除26封。选取其中5 100封垃圾邮件、5 100封正常邮件作为训练集,将另外的30 000封邮件作为测试集。将测试集中的邮件平均分为10份,对每份测试集进行实验,以10次实验的平均值作为实验结果进行分析。
Hadoop集群具体硬件配置信息如表1所示。

表1 Hadoop集群具体硬件配置信息
3.2 实验评价指标
在对垃圾邮件过滤实验进行评判时,用召回率(Recall)、查准率(Precision)、正确率(T)、F 值四个实验性能评价指标[7]来衡量本文提出的垃圾邮件过滤技术的性能。召回率为垃圾邮件过滤系统识别出的垃圾邮件数量占实际垃圾邮件数量的比例;查准率为实际为垃圾邮件总数占过滤系统判别出的垃圾邮件数量的比例;正确率为垃圾邮件过滤系统正确归类的邮件数量占所有待分类邮件数量的比例;F值为垃圾邮件查准率和召回率的调和平均,它将查准率和召回率综合成为一个新的判定指标。
3.3 实验结果及分析
实验1采用传统的贝叶斯垃圾邮件过滤算法,既未引入Hadoop MapReduce模型,也未进行优化算法,垃圾邮件的概率阈值Q=0.9。
实验2中引入了本文设计的MapReduce模型和算法,使用Hadoop集群,但未对算法做优化处理,垃圾邮件概率阈值取Q=0.9。
实验3中引入了本文设计的MapReduce模型,使用Hadoop集群,并改进了邮件分类时的概率阈值。垃圾邮件分类时的概率阈值根据算法进行设定。
结合三种实验情况,可得出召回率、查准率、F值和正确率如表2所示。
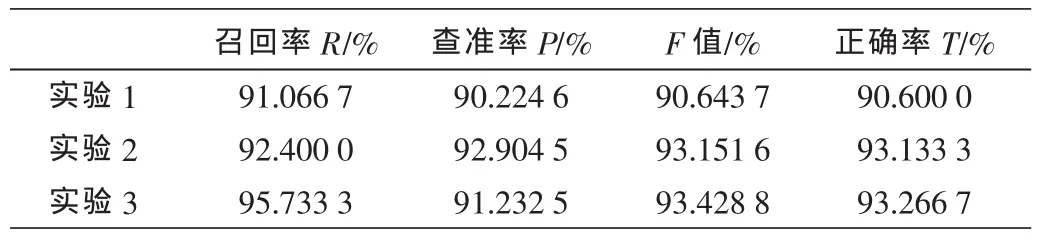
表2 过滤系统性能比较
根据上表可以发现,改进后的Hadoop平台下的垃圾邮件过滤系统在召回率、F值和正确率方面均有所提升,查准率略有下降,垃圾邮件过滤系统的整体性能得到了提升。可以得出结论,改进后的模型较原来的模型在性能上有了一定的提高。
本文针对实验3,分析了不同DataNode数量下基于Hadoop平台的垃圾邮件过滤系统较单机环境下贝叶斯垃圾邮件过滤系统的加速比,实验数据如图4所示。通过分析发现,与单机下的贝叶斯垃圾邮件过滤算法相比,基于Hadoop平台的贝叶斯垃圾邮件过滤技术随着DataNode数量的增加,加速比处于线性上升状态。
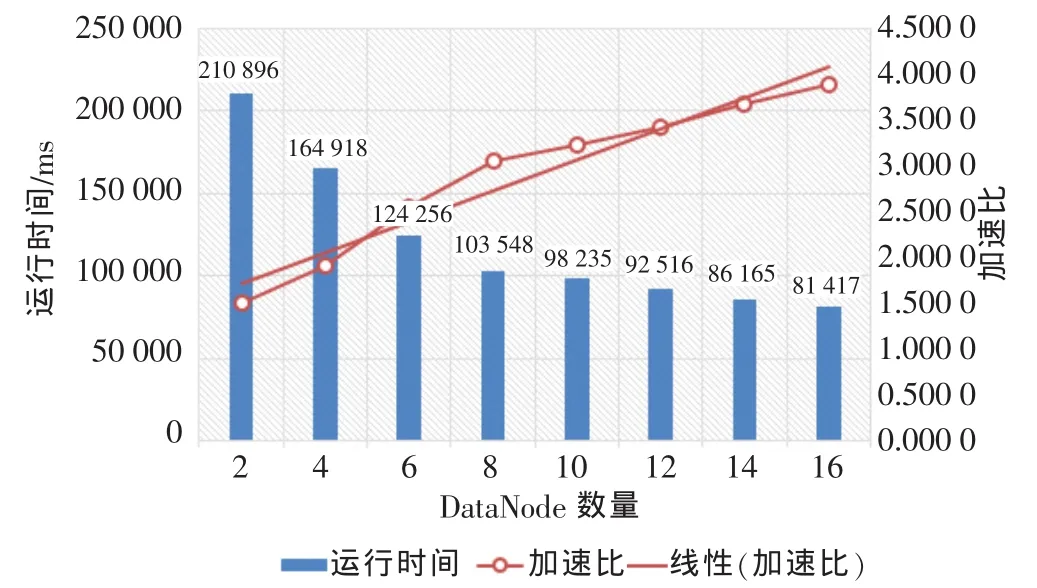
图4 随着DataNode数量变化与单机比较的加速比
4 结束语
本文针对海量垃圾邮件的过滤做出研究,在分析了传统的贝叶斯垃圾邮件过滤算法的缺点后,将贝叶斯垃圾邮件过滤算法与Hadoop MapReduce编程模型结合起来,提出了垃圾邮件过滤的数学模型,并在此基础上对判定邮件所属类别的阈值选择给出了一定的改进。本文提出的垃圾邮件过滤算法在垃圾邮件过滤评价指标上较单机环境下和改进前都有所提升,将算法在Hadoop集群中运行,得到了较好的加速比。
[1]中国互联网络信息中心.第35次中国互联网络发展状况统计报告[R/OL].(2015-02-03)[2015-05-02].http://www.cnnic.net.cn/hlwfzyj/hlwmrtj/.
[2]徐洪伟,方勇,音春.垃圾邮件过滤技术分析[J].通信技术,2003(10):126-128.
[3]向旭宇,姬林,杨岳湘.电子邮件系统过滤技术研究及实现[J].计算机应用研究,2003,20(S1):136-137.
[4]李国元,李双庆,杨铮.一种流序列化的网络流量分类算法[J].电子技术应用,2009,35(6):121-127.
[5]DEAN J,GHEMAWAT S.MapReduce: simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[6]Zhan Chuan,Lu Xianliang,Zhou Xu,et al.An improved Bayesian with application to anti-spam Email[J].Journal of Eelctronic Science and Technology of China,2005,3(1):30-33.
[7]李文斌,陈嶷瑛,刘椿年,等.邮件过滤算法的比较[J].计算机工程与设计,2008,29(17):4433-4436.
