DWSM动态并行计算技术
2015-09-03张岳峰方红卫张红武钟德钰赵慧明王新军
张岳峰,方红卫,张红武,钟德钰,赵慧明,王新军
(1.清华大学水利水电工程系,北京 100084; 2.水沙科学与水利水电工程国家重点实验室,北京 100084; 3.中国水利水电科学研究院泥沙研究所,北京 100048; 4.流域水循环模拟与调控国家重点实验室,北京 100048; 5.宁夏防汛抗旱指挥部办公室,宁夏 银川 750001)
DWSM动态并行计算技术
张岳峰1,2,方红卫1,2,张红武1,2,钟德钰1,2,赵慧明3,4,王新军5
(1.清华大学水利水电工程系,北京 100084; 2.水沙科学与水利水电工程国家重点实验室,北京 100084; 3.中国水利水电科学研究院泥沙研究所,北京 100048; 4.流域水循环模拟与调控国家重点实验室,北京 100048; 5.宁夏防汛抗旱指挥部办公室,宁夏 银川 750001)
针对DWSM计算模式鲁棒性低、计算时间长、无法实现多核计算等局限性,对模型的算法和存储规则进行相应改进。在遵从DWSM计算逻辑顺序的基础上,抛弃原计算单元顺序表模式关于虚拟河道的假设,采用流域分区概念进行河网树结构的模式设计,在基于叶节点并行计算的基础上研究动态分级并行计算技术,以进一步完善计算模式。以黄河宁蒙段流域为实例,计算结果表明,算法的优化极大地提高了DWSM的计算效率,增强了其对大范围、具有复杂河网结构流域水沙规律研究的适用性。
DWSM;水文模型;河网树结构;动态并行计算;叶节点
DWSM (dynamic watershed simulation model)是美国伊利诺伊水资源调查局开发的分布式水文模型,经过美国多个流域资料的验证证明其非常适合模拟不同水文情况下(单次暴雨或短期降雨等)的水沙过程,可用于模拟单次降雨或短期连续降雨引起的地表径流、渗流(土壤浅层侧向流)、洪水波演进、土壤侵蚀、泥沙和源于农业及城市地区的污染物等的迁移扩散情况[1-5]。
DWSM在结构上属于分布式松散耦合型水文模型,按对基本单元的划分可以认为是基于子流域的分布式模型,这类模型有较好的发展前景[6-8]。DWSM计算模式采用了计算单元顺序表的形式,在遇到3条及以上河道并入1条河道的情况时需要进行新建虚拟河道的处理,这使得DWSM在对河网的编码和阅读理解上增加了许多难度,特别是河网很密集、复杂时系统的鲁棒性较低,其单线程的计算方式无法适应大数据时代多核计算机及云计算的运用。
本文针对DWSM计算模式的局限性,对模型的算法和存储规则进行相应改进,在河网树结构的基础上开发叶节点并行计算算法,并对其进行改造和升级,采用并行计算技术对叶节点实施动态分级,以提高DWSM的计算效率,增强其对大范围、具有复杂河网结构流域水沙规律研究的适用性。
1 DWSM计算原理
按计算单元类型划分,DWSM属于基于坡面的分布式水文模型。计算单元划分充分考虑地形、土壤、植被特征的不均匀性,假定每个坡面各处的产汇流特性相同,用代表性参数值统一表示。在模拟某个流域时,首先把计算流域划分成若干个子流域,再进一步概化成一维矩形坡面或河道单元,水库和蓄滞洪区则作为独立的计算节点,置于相应的河道出口位置。坡面部分表示成矩形,坡面产汇流特征用矩形的长度与宽度、坡度、土壤类型、植被种类及糙率来表示;河道则用断面形状、长度、坡度和糙率来表示。坡面的面积、长度、坡度和土壤类型在模拟期间不变,植被种类和糙率在农作物轮种或森林砍伐等特殊情况下才发生相应改变;河道的断面形状、坡度和糙率在模拟期间则假定不变。每个坡面的降雨由各自雨量站控制。经地表覆盖物截留、土壤基质入渗和洼地存储损失后的净雨,由坡面顶部向坡底的河道演进,因此每条河道除了上游来流外,还有河道两边坡面贡献的地表和地下径流[1-4,9-10]。
图1是坡面与河道水流流向及相互关系示意图,图中i1和i2分别为不同坡面各自的降雨强度,mm/h;q1和q2分别为地表径流单宽流量,m3/(s·m);qs1和qs2分别为壤中流单宽流量,m3/(s·m);A为河道断面的断面面积,m2。

图1 坡面和河道水流流动示意图[10]
2 DWSM计算模式
传统的DWSM计算时首先构建一张计算单元顺序表,然后按照顺序表进行坡面和河道的计算。这种计算模式可以有效节约模型计算的存储空间,若河道比较规则,即使计算流域有几万条河道也只需要3个存储空间就能完成整个流域的计算。图2为计算单元顺序表示意图[11],图中,ISEG为河道或陆地块编号,IARY为输入输出向量组:outflows为输出保存位置,lateral inflows为河道左右两坡面陆地块计算输出的位置,upstream inflows为河道两个上游河道计算输出的位置。
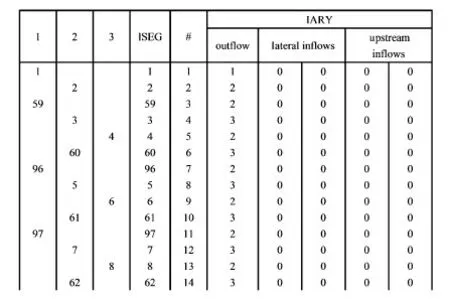
图2 计算单元顺序表示意图
计算单元顺序表具有一定的局限性,它使得模型只能计算2条河道并入1条河道的状态,遇到3条及以上河道并入1条河道的情况时则需要新建1条长度为0的虚拟河道(图3)。这样做有利于计算单元顺序表的生成,可以降低逻辑上的复杂性,但也增加了河网编码和阅读理解的难度,尤其对于密集、复杂的河网,增加虚拟河道会在很大程度上降低系统的鲁棒性。
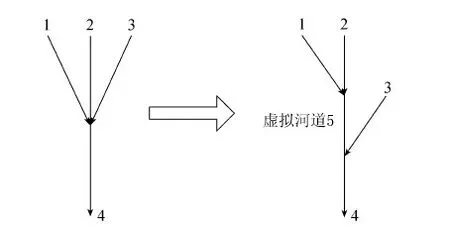
图3 虚拟河道示意图
引入虚拟河道,使得原先的河网编码或编号产生浮动,导致计算单元顺序文件难以自动生成,只能采用人工方式完成,极大地增加了计算单元顺序表的建立时间。例如一个具有500条河道(包括虚拟河道)的流域,一般需要1个月的时间才能建立其计算单元顺序表。除此之外,计算单元顺序表关于所有河道、坡面的计算顺序都只能采用单线程来完成的规定,根本无法适应多核计算机及云计算的运用。而随着存储技术的发展和大数据时代的到来[12-14],存储空间已经不再是模型计算的瓶颈,计算单元顺序表的优势已不复存在。因此,应对DWSM的算法和存储规则进行相应改进,以进一步提高模型的计算效率和适用性。
3 DWSM动态并行计算设计
在DWSM计算顺序逻辑的基础上,拟对其算法和存储规则进行改进和提高。抛弃虚拟河道,河道与坡面为一对一的关系,故计算过程不需要单独规划坡面的计算顺序,只需在计算河道时优先计算其对应的两个坡面。按照Schumn的流域分区概念[15],对于水沙来源区河网的划分及其拓扑的生成,可采用以下假设:①在1个汇流节点,有且仅有1条支流汇入干流;②2个直接相邻的节点间有且仅有1个河段。由此,可以将河网抽象成树结构,每一级待计算的坡面或河道(图1)均可看作河网树结构中的一个节点,上一级节点所表示的坡面或河道的计算完成后,方可进行其相关联的下一级节点的计算。以黄河宁夏段为例可以简要地绘出其河网如图4所示,图中带有标号的圆圈表示某级待计算的坡面或河道,即河网树结构中的一个节点,处于河网树结构中叶子位置(可实现水流计算)的节点即为叶节点。

图4 黄河宁夏段河网树结构
计算单元顺序表模式在设计好各级坡面或河道的计算顺序之后,仅能采用单线程的方式依次计算各个节点。以图4所示河网为例,计算单元顺序表模式每次仅能计算1个节点结构,故共需33步方能完成整个计算过程,其计算效率不高,局限性极大。
3.1 叶节点并行计算
由河网树结构可以看出,河网的所有叶节点没有依赖项,可以独立计算,因此可以设计DWSM的并行计算算法如下:
a. 初始化集合A为空,集合B为所有河网树的节点集合。
b. 搜索B中的所有叶节点,将这些叶节点并入集合A中,移除集合B中相应的叶节点。
c. 集合A中的所有节点并行计算。
d. 若集合B不为空,转步骤b;否则计算结束。
以图4所示河网树结构为例,由上述算法可以得到每一步搜索到的相应步数下可计算叶节点集合,见表1。

表1 叶节点计算过程(理想状态)
由表1可以看出,第一步搜索到的图4中可计算的叶节点数(并行计算CPU核心数要求最多时)一共17个,在理想情况下(CPU核心数足够多,可用于河网计算的核心数大于或等于17个),该河网经过12步并行计算便能完成DWSM的水沙模拟。但计算机CPU是稀缺资源,可以分配的核心也是有限的,特别是当河网分级比较细、流域面积比较大时,程序可以获得的CPU核心数往往远小于其所需要的个数。假设程序可以用2个CPU核心,则计算的过程如表2所示。

表2 叶节点计算过程(2个CPU核心)
由表2可以看出,在可用2个CPU核心时,根据上述算法只需22步就能完成图4的河网计算,较采用计算单元顺序表模式的33步,效率有了一定的提高。但此算法还存在两个问题:①缺乏动态的进程分配,如计算第9步时,未能将河道19提到核心2上进行计算;②未能合理地分配河道计算顺序,如过早地计算了河道2,而其结果需要等到计算河道0时才使用到。
3.2 河道编码
为动态地分配进程,必须实时更新当前的叶节点集合,这需要在每计算完一条河道时,对河网树进行刷新和搜索。但这样做会耗费大量的计算资源,尤其当河网过于复杂时重新搜索一次叶节点可能比计算一条河道的时间还要长。为此,本文重新设计河道编码方式,使节点在变为叶节点时主动加入叶节点集合,同时保持河网的树状结构。
将河网树的每一个节点用向量(S,FS,CN)表示,如图5所示,其中S为河道的编号,FS为下游河道的标号,CN为上游未计算的河道数。由S与FS保持了河网的树状结构,CN初始值为该节点上游河道数,当CN为零时说明该节点为河网树的叶节点。由此,可以修改算法如下:
a. 初始化集合A为空,将河网节点向量中CN为零的节点并入集合A中。
b. 对集合A中的所有节点并行计算。
c. 设a为集合A中刚计算结束的节点,b是a节点指向的下游节点,则节点b的CN分量减1。若此时b的CN分量为零,则将b并入集合A。
d. 将a移出集合A,若此时A为空集,则结束计算;否则转步骤b。

图5 河网树节点向量示意图
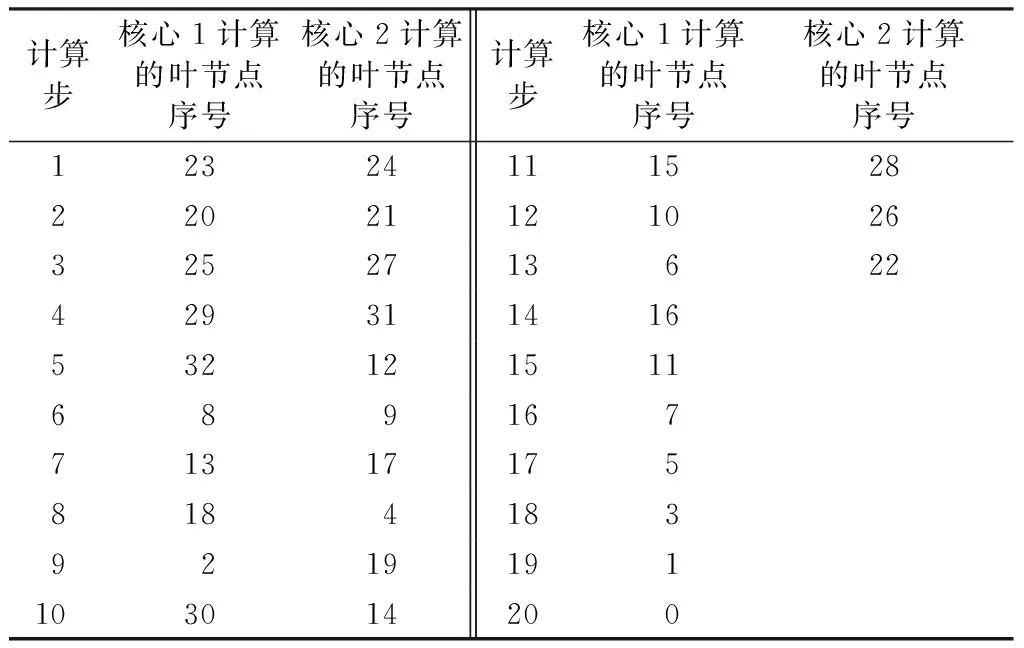
计算步核心1计算的叶节点序号核心2计算的叶节点序号计算步核心1计算的叶节点序号核心2计算的叶节点序号123241115282202112102632527136224293114165321215116891677131717581841839219191103014200
根据修改的算法,节点编码后的计算过程见表3。由表3可见,河网编码可以将原先需要22步完成的河网计算在20步之内完成。当河网非常复杂时,基于河网编码的CPU核心资源分配方式可以使计算步骤大幅度减少。由表3还可见,在计算步骤14及以后,计算过程都是单核运行,因此算法还有提升空间。
3.3 分级优选计算顺序
如前所述,在计算资源受限的情况下,过早地计算河网中的下游叶节点是对资源的一种浪费,因此需要根据河网中河道的上下游关系,对河道的计算顺序进行分级,见图6。

图6 河道计算顺序分级示意图
如图6所示,当可以计算高级别河道时,若利用该计算资源去计算低级别的河道,有可能使计算过程发生阻塞,使得后期计算资源得不到充分利用。如利用2个CPU核心计算图6的清水河段(包括河道16、21、22、25~32)时,如果优先计算了下级河道21和25,则在计算河道22和26时必然只能单核运行,核心2将一直处于空闲状态。为此,需要在河道编码中加入计算等级信息,在上一节的河道编码中加入计算等级分量L,形成新的河道编码向量(S,FS,CN,L)。在此基础上,设计算法如下:
a. 根据河网的计算等级数初始化Lmax+1个叶节点集合A0,A1,A2,…,ALmax(下标表示集合中叶节点的计算等级,Ai(i=0,1,2,…,Lmax)即为每步计算中CN=0且L=i的节点的集合)。
b. 将河网节点向量中CN为零的节点根据分量L并入其相应的集合Al中(Al为Ai中i=L的叶节点集合)。
c. 用∪Ai表示所有Ai的并集,对集合∪Ai中的所有节点并行计算,且优先计算i大的集合中的节点。
d. 设a为集合∪Ai中刚计算结束的节点,b是a节点指向的下游节点,则节点b的CN分量减1。若此时b的CN分量为零,则将b根据其计算等级分量L并入相应的集合Al。
e. 将a移出集合∪Ai,若此时∪Ai为空集,则结束计算;否则转步骤c。
根据该算法,分级优选后的计算过程见表4。由表4可知,分级优选后模型计算速度又有了提高,采用河网分级后图4的河网只需要17步就能完成模拟。这与最原始的计算单元顺序表方式(33步)相比,速度提高了将近1倍,验证了单线程和双核运行速度的区别。由于河网中河道上下游关系的限制,下游河道必须等待上游河道计算完成后才能进行计算,因此河网的计算速度与计算设备的CPU核心数并不呈现线性方式增长,如本例中根据河道的上下游关系,即使CPU核心数足够多,最少也需要12步(表1)方可完成计算。

表4 分级优选后的叶节点计算过程(2个CPU核心)
4 实例验证
以图4所示的黄河宁蒙河段流域为例,验证算法的适用性和有效性。设计计算范围如图7所示,图中河网提取时已尽量简化,共计251条河道。
图7 黄河宁蒙河段流域计算范围示意图
配置CPU为Intel i7的8核处理器,分别采用单元顺序表计算模式、叶节点并行计算模式和动态分级并行计算模式对流域的产流产沙进行模拟计算,所用时间分别为110 s、55 s和30 s。可以看出,算法的优化很大程度减少了计算所耗费的时间,极大地提高了模型的计算效率。算例中改变DWSM原单元顺序表的计算方式,采用叶节点并行计算方式,已经可以将计算时间缩短一半;在此基础上又继续优化算法,采用改进后的动态分级并行计算方式,则计算时间又进一步减少近50%。可见新的计算模式克服了原计算单元顺序表模式对模型在河网编码和阅读理解上的限制,可以使DWSM在大流域中计算时提高运行和分析的速度,增强其计算大范围、具有复杂河网结构流域水沙规律的适用性,使其更适用于大数据时代多核计算机及云计算的运用。
5 结 语
DWSM由于计算单元顺序表的存在和计算模式的限制,使得其计算效率和适用范围具有一定的局限性,特别是河网很密集、复杂时系统的鲁棒性较低,其单线程的计算方式也无法适应大数据时代多核计算机甚至云计算的运用。本文针对上述不足对DWSM进行进一步改进,通过对其计算算法和存储规则的优化来提高模型的计算效率,在基于叶节点并行计算的基础上进行动态分级并行计算技术研究,并以黄河宁蒙河段流域为例,验证了模型新算法的适用性和有效性,表明算法的优化极大地提高了DWSM的计算效率,增强了其对大范围、具有复杂河网结构流域水沙规律研究的适用性。
[ 1 ] BORAH D K,BERA M. Hydrologic modeling of the Court Creek watershed [R].Champaign: Illinois State Water Survey,2000.
[ 2 ] BORAH D K,BERA M.Watershed-scale hydrologic and nonpoint-source pollution models: review of mathematical bases [J].Tran of the ASAE,2003,46(6):1553-1566.
[ 3 ] BORAH D K,BERA M,XIA R J.Storm event flow and sediment simulations in agricultural watersheds using DWSM [J].Transactions of the ASAE,2004,47(5):1539-1559.[ 4 ] 郑毅.北运河流域洪水预报与调度系统研究及应用[D].北京:清华大学,2009.
[ 5 ] 向霄,钟玲盈,王鲁梅.非点源污染模型研究进展[J].上海交通大学学报:农业科学版,2013,31(2):53-60. (XIANG Xiao,ZHONG Lingying,WANG Lumei.Review of non-point source pollution model [J].Journal of Shanghai Jiaotong University:Agricultural Science,2013,31(2):53-60.(in Chinese))
[ 6 ] 徐宗学,程磊.分布式水文模型研究与应用进展[J].水利学报,2010,41(9):1009-1017.(XU Zongxue,CHENG Lei.Progress on studies and application of the distributed hydrological models [J].Journal of Hydraulic Engineering 2010,41(9):1009-1017.(in Chinese))
[ 7 ] 芮孝芳,黄国如.分布式水文模型的现状与未来[J].水利水电科技进展,2004,24(2):55-58.(RUI Xiaofang,HUANG Guoru.The current situation and future of the distributed hydrologic models [J].Advances in Science and Technology of Water Resources 2004,24(2):55-58.(in Chinese))
[ 8 ] 张金存,芮孝芳.分布式水文模型构建理论与方法述评[J].水科学进展,2007,18(2):286-272.(ZHANG Jin-cun,RUI Xiaofang.Discussion of theory and methods for building a distributed hydrologic model [J].Advances in Water Science,2007,18(2):286-272.(in Chinese))
[ 9 ] 郑毅,方红卫,韩冬.DWSM模型产汇流模块的原理及应用[J].南水北调与水利科技,2008,6(3):28-31. (ZHENG Yi,FANG Hongwei,HAN Dong.Principle and application of runoff yield module of dynamic water simulation model (DWSM)[J].South-to-North Water Transfers and Water Science & Technology,2008,6(3):28-31.(in Chinese))
[10] BORAH D K,XIA R J,BERA M.DWSM:a dynamic watershed simulation model [M]//SINGH V P,FREVERT D K.Mathematical Models of Small Watershed Hydrology and Applications. Highlands Ranch: Water Resources Publications,2002:113-166.
[11] 刘通.奥林匹克森林公园暴雨径流及泥沙流失模拟研究[D].北京:清华大学,2008.
[12] 周勇.基于并行计算的数据流处理方法研究[D].大连:大连理工大学,2013.
[13] 王磊.并行计算技术综述[J].信息技术,2012(10):112-115.(WANG Lei.Parallel computing technology review [J].Information Technology,2012(10):112-115.(in Chinese))
[14] 程开明,陈龙.大数据时代的统计挑战与应对[J].中国统计,2013,8:11-13.(CHENG Kaiming,CHEN Long.The statistical challenges and countermeasures in the era of big data [J].China statistics,2013,8:11-13.(In Chinese))
[15] SCHUMMY S A.The fluvial system [M].New York:John Wiley & Sons,1977:1-10.
Research on dynamic parallel computing technology of dynamic watershed simulation model//
ZHANG Yuefeng1, 2,FANG Hongwei1,2,ZHANG Hongwu1,2,ZHONG Deyu1,2,ZHAO Huiming3,4,WANG Xinjun5
(1.DepartmentofHydraulicEngineering,TsinghuaUniversity,Beijing100084,China; 2.StateKeyLaboratoryofHydroScienceandHydraulicEngineering,Beijing100084,China; 3.SedimentResearchInstitute,ChinaInstituteofWaterResourcesandHydropowerResearch,Beijing100048,China; 4.StateKeyLaboratoryofSimulationandRegulationofWaterCycleinRiverBasin,Beijing100048,China; 5.TheOfficeofFloodControlandDroughtReliefHeadquartersofNingxia,Yinchuan750001,China)
The computing model of Dynamic Watershed Simulation Model(DWSM) has some limitations, such as low robustness, long computing time, and inability to realize failure in a multicore computer. Therefore, in this paper, we improved the algorithms and storing rules. Based on the computational logic sequence of DWSM, we suggest to use the concept of basin subarea to design the tree structure model of river network instead of the hypothesis on virtual channel of the original calculation unit sequence table model. Also, we introduce the dynamic hierarchical parallel computing technology according to parallel computation of leaf nodes to improve the calculation model. Taking the Yellow River basin between Ningxia and Neimenggu as an example, the results show that the optimization of algorithm greatly improves the computational efficiency of DWSM as well as increases the applicability of calculation on water and sediment rules in the basins with large scale and complex structure of river network.
dynamic watershed simulation model(DWSM); hydrological model; the tree structure of river network; dynamic parallel computation; leaf nodes
国家自然科学基金(51139003,11372161,51479213)
张岳峰(1983—),男,江苏常州人,博士,主要从事水利信息化、水力学及河流动力学研究。E-mail:zhangyuefeng1983@163.com
10.3880/j.issn.1006-7647.2015.03.010
TV214
A
1006-7647(2015)03-0047-06
2014-06-13 编辑:熊水斌)
