CoLoRCache:智慧协同网络中一种协作缓存机制
2015-09-01张萌周华春罗洪斌
张萌 周华春 罗洪斌


摘要:介绍一种有效支持缓存协作的未来网络体系架构:智慧协同网络,然后提出了一种高效的协作缓存机制,称为CoLoRCache。CoLoRCache的主要目标是减小缓存冗余和建立缓存共享机制。我们通过仿真结果来验证CoLoRCache。仿真数据表明,相比较于其他缓存机制,CoLoRCache能够产生更高的缓存命中率和有着最小的请求命中距离。
关键词: 智慧协同网络;网络缓存;协作缓存
Abstract: In this paper, we propose a possible future network architecture that supports cache cooperation. We also propose intra-domain cache cooperation, called CoLoRCache, to increase cache efficiency. Our main goals in CoLoRCache are to reduce the caching redundancy significantly and construct a novel cache-sharing mechanism. We use trace-driven simulations to analyze the quantitative benefits. The simulation results show that, compared with other caching mechanisms, CoLoRCache provides a higher cache hit ratio and achieves the minimum hit distance.
Key words: smart and cooperative networks; in-network caching; cache cooperation
对服务内容命名成为了未来网络体系架构研究者们的共识。目前,研究者们提出了诸多未来网络体系架构,例如面向数据的网络结构(DONA)[1]、内容中心网络(CCN)[2](后来被命名为命名数据网络[3](NDN))、4WARD [4] (后来被命名为可扩展和可适应的网络方案(SAIL)[5])、基于发布-订阅的互联网路由模式(PSIRP) [6](后来被命名为基于发布-订阅的互联网技术(PURSUIT)[7]),以及智慧协同网络[8]。不同于传统网络利用网络节点地址,这些未来网络架构依靠与位置分离的内容名字完成服务内容的获取。
尽管这些未来网络体系架构有着不同的设计目标和细节,他们均提出利用网络缓存来提高未来网络的服务质量。
缓存机制要求有限的缓存资源能够响应更多的服务请求,同时产生更小的服务请求命中距离。而传统的网络缓存机制[9]面临着两个需要解决的问题:缓存冗余和缓存内容可用性限制。
这两个问题降低了缓存机制的效率。为了实现高效的缓存机制,研究者们提出了诸多缓存优化机制。这些缓存优化机制都试图减小缓存冗余,或者提高缓存可用性,或者两者兼有。例如,Probcache[10]要求内容路由器概率性地缓存转发的内容数据包,以减小缓存冗余。在Breadcrumbs[11]中,内容路由器建立路由轨迹,以提高缓存内容可用性。而最近研究界提出的缓存优化机制[12-13]均采用了缓存信息通告来实现缓存协作。
需要注意的是,已提出的缓存协作机制都是基于NDN体系架构。考虑一个由V个内容路由器组成的NDN网络,我们假设一段时间内该NDN网络中所有内容路由器的平均缓存命中率为R,每一个内容路由器收到的服务请求数量为N。如果每一个内容路由器在缓存服务数据包的时候,向网络中其他的内容路由器通告缓存信息。那么该NDN网络中每一个内容路由器都需要处理(V-1)×(1-R) ×N个缓存通告消息。由此可见,当网络规模扩大时,协作缓存机制产生的通告开销也相应地增加。所以,NDN网络体系无法兼顾协作缓存机制的效率和可扩展性。
为了解决这个问题,我们在文中首先介绍一种有效支持缓存协作的未来网络体系架构:智慧协同网络。同时,基于智慧协同网络,我们提出了一种高效的缓存协作机制,称为CoLoRCache。
1智慧协同网络
作为研究基础,我们在这一节中简单介绍智慧协同网络,更多的细节请参考文献[8], [14-15]。智慧协同网络是一种全新的未来网络体系架构,其核心思想是通过动态感知网络状态并智能匹配服务需求,进而选择合理的网络族群及其内部组件来提供智慧化的服务,并通过引入行为匹配、行为聚类、网络复杂行为博弈决策等机制来实现资源的动态适配以及协同调度。
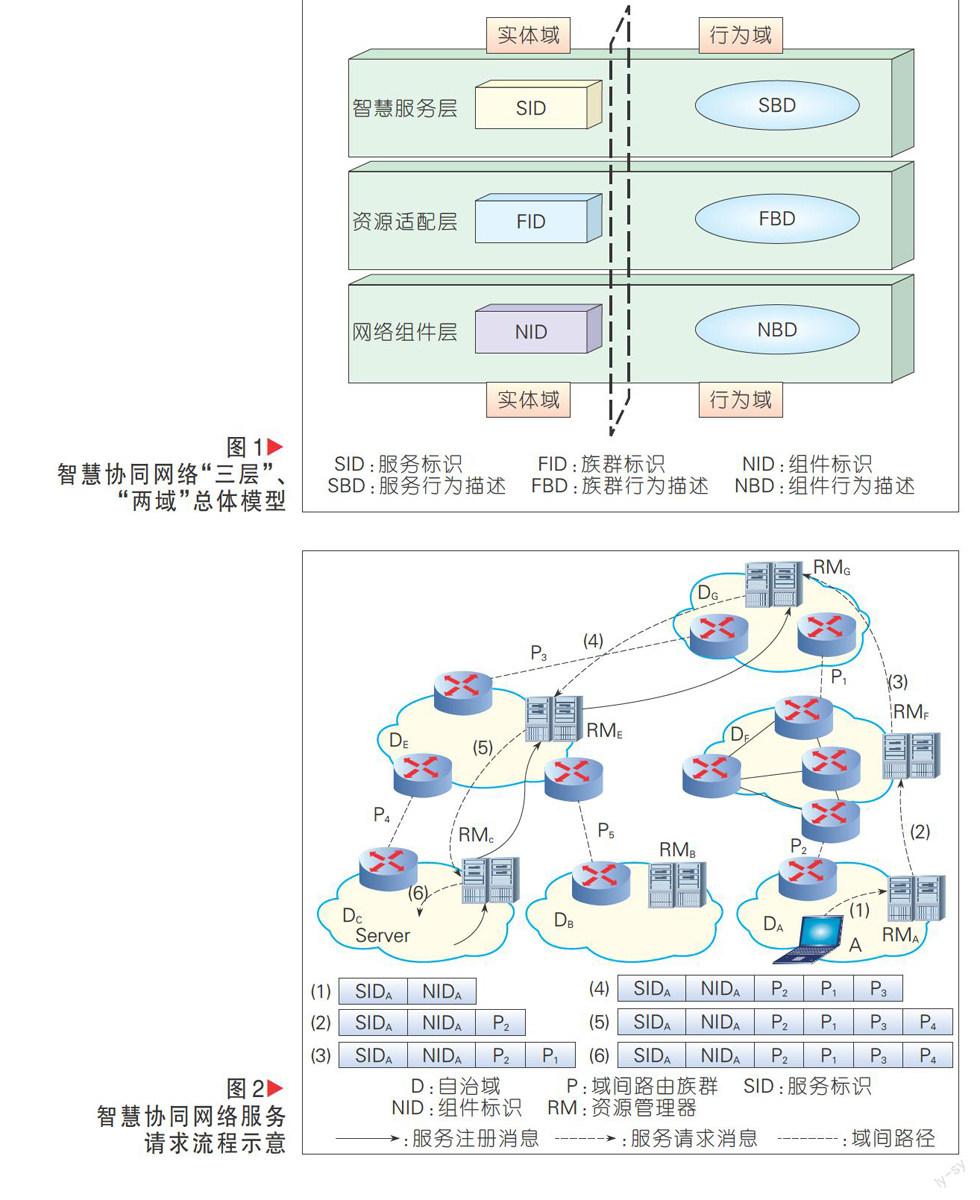
智慧协同网络的“三层”、“两域”总体系架构模型,如图1所示。三层即智慧服务层、资源适配层和网络组件层;两域即实体域和行为域。在三层、两域新体系结构模型中,智慧服务层主要负责服务的标识与描述,以及服务的智慧查找与动态匹配等;资源适配层通过感知服务需求与网络状态,动态地适配网络资源并构建网络族群,以充分满足服务需求进而提升用户体验,并提高网络资源利用率;网络组件层主要负责数据的存储与传输,以及网络组件的行为感知与聚类等。使用服务标识(SID)来标记一次智慧服务,实现服务的资源和位置分离;使用族群标识(FID)来标记一个族群功能模块;使用组件标识(NID)来标记一个网络组件设备,实现网络的控制和数据分离及身份与位置分离。
在智慧协同网络中每个自治域维护一个资源管理器(RM),并用来管理网络资源和服务资源。如图2中实线所示,当某个网络组件(例如位于自治域Dc的用户A)需要获取某个服务内容时(例如SIDA,由网络组件Server发布),用户A向其本地RM(例如RMA)发送服务请求消息。该服务请求消息包含该网络组件的组件身份标识、所需服务的服务标识等信息,如图2中(1)所示。RMA收到该服务请求后,如果本地有其他网络组件(例如某个内容路由器)能够提供所需服务,则直接将该请求转发给该内容路由器。否则,将该请求发送给其某个邻域(如provider)的RM(即RMF)。此时,自治域DA和DF之间的域间路径P2为一个域间路由族群。RMA在请求包头中添加对应的路径信息,并将服务请求转发给RMF,如图2中(2)所示。类似地,RMF将服务请求转发给RMG,如图2中(3)所示。此时,RMG可以在其服务注册表中查到该服务标识的条目,因此向RME转发该服务请求,如图2中(4)所示。RME收到该服务请求后,根据其本地策略决定将该服务请求并转发给RMC,如图2中(5)所示。此时,RMC知道网络组件Server提供所需服务,于是将服务请求转发给Server,如图2中(6)所示。当每个RM向其邻域转发服务请求的时候,该RM根据其本地策略,选择一条该域与其邻域的域间路由族群,并附加在服务请求后面,发送给其邻域的RM,从而完成服务标识到族群标识的映射。
数据包转发流程示意如图3[8]所示。网络组件Server收到服务请求后,知道去往服务请求者A的域间路由族群。此时,它将收到的域间路由族群、所需服务的服务标识、服务请求者的组件身份标识等放在分组头部。然后,它将服务数据包发送至本地RM。RM收到数据包后,查找其本地域间路由表,发现路由族群P4在该域的端点为R1。假定域DC利用IP做域内路由,则RM为数据包封装一个IP报头,报头的目的地址为R1的IP地址(IP1)。然后RM将数据包发送给R1。R1收到数据包后,剥去IP报头,知道数据包应该沿着路由族群P4转发出去,于是将数据包向路由族群P4转发。当数据包到达路由族群P4的另一个端点R2时,R2剥去数据包头部的路由族群P4,并将数据包发送至RME。RME收到数据包后,知道数据包应该沿着路由族群P3转发。于是,RME查找其域间路由表,了解到路由族群P3在该域的端点为R5,并采用该域的路由机制(图3中假设该域采用多协议标签交换MPLS)将分组转发给R5。同理,R5将该分组向路径P3转发。如此继续,服务数据包将被发送给服务请求者A。
由此可见,智慧协同网络能够解决现有互联网中存在的服务的“资源和位置绑定”、网络的“控制和数据绑定”及“ 身份与位置绑定”等问题。这种全新的网络体系与机制的设计,能够在有效解决网络可扩展性、移动性、安全性等问题的基础上,大幅度提高网络资源利用率,降低网络能耗,显著提升用户体验。同时,智慧协同网络能够有效支持协作缓存机制,提高缓存效率。
2 CoLoRCache
2.1 CoLoRCache缓存协作机制设计
在智慧协同网络中,由RM负责管理本域的缓存资源。每个RM均建立缓存摘要表,表中每一条条目记录了域内的某个内容路由器的信息,包括:该内容路由器的组件标识、缓存命中次数、偏心度(Ec)、被该内容路由器缓存的数据包的服务标识。其中,内容路由器(例如Rn)的偏心度由公式(1)计算得到:
[EcRn= max?Ri\Rnc(Rn,Ri)] (1)
其中,Ri是域内的某个内容路由器,而c(Rn, Ri)是Rn到Ri之间最短路径的代价。
以图4中的RMA为例,说明服务内容的检索过程。在RMA的缓存摘要表中一条条目包含了域内的一个内容路由器的组件标识(标记为Rn)、命中次数、偏心度和已缓存数据包的服务标识。图4为一个资源管理器RMA在收到来自客户端的服务请求包完整的处理流程,主要可以分为4个步骤。
步骤1:服务请求者Client发送针对一个服务内容的服务请求,如图4中(1)所示;
步骤2:RMA收到该服务请求时,首先查询缓存摘要表,如图4中(2)所示。如果缓存摘要表中有该服务标识对应的条目,则进入步骤3;如果没有,则进入步骤4;
步骤3:根据缓存摘要表中对应条目记录的组件标识,RMA将服务请求发送至该组件标识对应的内容路由器处,同时将对应条目的缓存命中次数加1,如图4中(3)所示;
步骤4:RMA查询注册表,并根据注册表将服务请求发送至下一跳RM,如图4中(4)所示。
当收到服务数据包时,RM将决定是否在域内缓存该数据包的副本。如果需要缓存,CoLoRCache在域内对相同的服务数据包只保留一份副本。RM则使用内容放置算法在域内选择内容路由器作为该副本的缓存位置,并向该内容路由器发送数据包的副本。资源管理器在缓存摘要表中记录该缓存信息。内容路由器将发送至本地的数据包副本缓存在本地。
2.2 CoLoRCache内容放置算法
我们用Go= (Vo, Eo)代表某个自治域的网络拓扑,其中包含了|Vo|个内容路由器,|Eo|条链路。V是网络中命中次数最低的内容路由器的集合,当资源管理器收到数据包时,调用下述的内容放置算法在域内选择某个特定的内容路由器来缓存该数据包的副本,如算法1所示。
算法1包含4个步骤。
步骤1:根据缓存摘要表,选出集合Vo中当前命中数量最小的内容路由器放入集合V中;
步骤2:根据|V|值,进行判定,如果|V|>1,进入步骤3;如果|V|=1,进入步骤4;
步骤3:选择集合V中的元素,结束算法;
步骤4:选择集合V中的偏心度最小的元素,结束算法。
CoLoRCache内容放置算法的增益效果是将数据包优先缓存在缓存命中次数最低的内容路由器,以提高缓存效率。当多个内容路由器缓存命中次数相同时,该算法能够将数据包优先缓存在更加位于拓扑中心的内容路由器处,以降低获取该数据包的成本。
3仿真实验
为了验证缓存性能,我们在OMNeT++上对CoLoRCache进行了仿真实现,基于一个实际的拓扑和一个生成的拓扑。实际的拓扑为AS-3967,其拓扑信息来自Rocketfuel [16]。同时,我们利用Tier [17]生成一个分层的拓扑,由1个骨干网和3个接入网组成。我们在表1中列出了详细的拓扑参数。
我们在OMNeT++中部署了目前已提出的其他缓存优化机制:
·All-Cache。All-Cache是传统的缓存机制,它要求每一个内容路由器在转发数据包的同时,都在本地缓存保留一份数据包的副本。
·Prob-Cache。Prob-Cache是概率性缓存机制,主要分为Prob(p)[18]和Probcache。在Prob(p)中,内容路由器以某个固定的概率缓存转发的数据包。在仿真中Prob(p)要求内容路由器缓存一个转发的数据包的概率为0.75,只转发该数据包的概率为0.25。而在Probcache,内容路由器根据其在下载路径上的位置计算缓存概率。同样的,在Prob-Cache中,每一个内容路由器都只知道本地的缓存状态。
·Ran-Cache。Ran-Cache的原型是CATT。两者不同的地方在于,我们将Ran-Cache部署在了智慧协同网络中,目的在于验证内容放置算法。除了不同的内容检索和转发方法,与CATT相比,Ran-Cache中每一个域的资源管理器能感知本域的缓存状态。
·Cop-Cache。Cop-Cache的原型是CPHR[19]。两者不同的地方在于Cop-Cache被部署在了智慧协同网络,因此每一个域的资源管理器能够感知本域的缓存状态。
在仿真中我们验证了多个缓存性能参数,包括缓存命中率和平均命中距离。同时,在仿真中服务内容的访问频率模型符合Zipf分布,并将Zipf参数设定为0.73。
3.1缓存命中率优化
一次缓存命中意味着服务请求包被缓存所直接响应,而不需要被路由到内容源。缓存命中率是缓存命中的服务请求数占所有服务请求数量的比重。缓存命中率能够直观地体现缓存效率。命中率越高,则意味着缓存机制越高效。
图5(a)展示了在AS-3967拓扑下,不同的缓存机制对于缓存命中率的优化。如图所示,我们将缓存空间大小表示为网络中缓存容量与仿真中所有服务内容大小的比值。在仿真中,我们逐步提高缓存容量并统计缓存命中率。随着缓存空间大小增加,缓存命中率也相应增加。其中,CoLoRCache的缓存命中率最高。举例来说,当缓存空间大小为5%时,All-Cache、Prob(p)、Probcache、Ran-Cache、Cop-Cache和CoLoRCache的缓存命中率分别为20.56%、32.25%、51.83%、60.56%、66.75%和70.06%。由此可见,跟其他的缓存优化机制相比,CoLoRCache对缓存命中率的优化效果更加显著。
图5(b)展示了利用Tier生成的拓扑下,不同缓存机制的缓存命中率。在相同的仿真环境下,CoLoRCache的缓存命中率更高。
3.2命中距离优化
命中距离是测量服务时延的一个参数,它被定义为请求找到所需内容的平均距离。图6展示了在不同仿真拓扑下的请求命中距离减少程度。根据图6,我们发现当缓存空间大小增加时,命中距离会相应地减小,这意味着更短的服务获取时延。同时,与现有的优化机制相比,CoLoRCache能够更有效地减少请求命中距离。
4结束语
文章介绍了一种能够有效支持协作缓存的未来网络体系架构——智慧协同网络,并提出了一种基于智慧协同网络的协作缓存机制——CoLoRCache。CoLoRCache的基本思想是利用缓存共享来减小缓存冗余并提高缓存内容可用性。仿真建立在一个实际的网络拓扑AS-3967和一个生成的网络拓扑。大量仿真实验结果证明CoLoRCache在缓存命中率和平均命中距离上拥有更优的缓存性能。
参考文献
[1] KOPONEN T, CHAWLA M, CHUN B -G, ERMOLINSKIY A, KIM K H, SHENKER S, and STOICA I. A data-oriented (and beyond) network architecture [J]. ACM SIGCOMM Computer Communication Review, 2007, 37(4): 181-192
[2] Project CCNX [EB/OL]. [2015-04-30]. http://www.ccnx.org/
[3] Named Data Networking [EB/OL]. http://www.named-data.net/
[4] The FP7 4WARD Project [EB/OL]. http://www.4ward-project.eu/
[5] Scalable and Adaptive Internet Solutions (SAIL) [EB/OL]. http://www.sail-project.eu/
[6] Publish-subscribe Internet Routing Paradigm [EB/OL]. http://www.psirp.org/
[7] Publish-Subscribe Internet Technology [EB/OL]. http://www.fp7-pursuit.eu/PursuitWeb/
[8] LUO H, CHEN Z, CUI J, ZHANG H, ZUKERMAN M, and QIAO C. Color: an information-centric internet architecture for innovations [J]. IEEE Network, 2014, 28(3): 4-10. doi: 10.1109/MNET.2014.6843226
[9] JACOBSON V, SMETTERS D K, THORONTON J D, PLASS M F, BRIGGS N H, and BRAYNARD R L. Networking named content [C]// Proceedings of 2009 ACM CoNEXT conference, Rome, Italy, 2009: 1-12
[10] PSARAS I, CHAI W K, and PAVLOU G. Probabilistic in-network caching for information-centric networks [C]// Proceedings of the 2nd ACM SIGCOMM Workshop on Information-Centric Networking, Helsinki, Finland, 2012:55-60
[11] ROSENSWEIG E J and KUROSE J. Breadcrumbs: Efficient, best-effort content location in cache networks [C]// Proceedings of 2009 INFOCOM, Rio de Janeiro, Brazil, 2009: 2631-2635
[12] EUM S, NAKAUCHI K, MURATA M, SHOJI Y, and NISHINAGA N. Catt: potential based routing with content caching for icn [C]//Proceedings of the 2nd ACM SIGCOMM Workshop on Information-Centric Networking, Helsinki, Finland, 2012: 49-54
[13] WANG J M, ZHANG J, and BENSAOU B. Intra-as cooperative caching for content-centric networks[C]// Proceedings of the 3rd ACM SIGCOMM workshop on Information-Centric Networking, Hong Kong, China, 2013: 61-66
[14] 张宏科, 苏伟. 新网络体系基础研究——体化网络与普适服务 [J]. 电子学报, 2007, 35(4):593-598
[15] 张宏科, 罗洪斌. 智慧协同网络体系基础研究 [J]. 电子学报, 2013, 41(7): 1249-1254
[16] CALVERT K L, DOAR M B, and ZEGURA E W. Modeling internet topology [J]. IEEE Communications Magazine, 1997, 35(6): 160-163
[17] SPRING N, MAHAJAN R, and WETHERALL D. Measuring isp topologies with rocketfuel [J]. ACM SIGCOMM Computer Communication Review, 2002, 32(4):133-145
[18] LAOUTARIS N, CHE H, and STAVRAKAKIS I. The lcd interconnection of lru caches and its analysis [J]. Performance Evaluation, 2006, 63(7): 609-634
[19] WANG S, BI J, and WU J. Collaborative caching based on hashrouting for information-centric networking [J]. ACM SIGCOMM Computer Communication Review, 2013, 43(4):535-536
