基于HDFS的海量指纹数据云存储优化研究*1
2015-08-18张宇翔赵建民朱信忠徐慧英
张宇翔, 赵建民, 朱信忠, 徐慧英
(浙江师范大学 数理与信息工程学院,浙江 金华 321004)
基于HDFS的海量指纹数据云存储优化研究*1
张宇翔, 赵建民, 朱信忠, 徐慧英
(浙江师范大学 数理与信息工程学院,浙江 金华 321004)
HDFS设计之初只考虑到如何更好地处理大文件,并没有针对海量小文件进行优化,因此,当使用HDFS管理海量指纹数据小文件时会出现NameNode内存负载过重、上传及查询性能过低等问题.采用SequenceFile序列化技术进行小文件的合并,并且对于小文件合并、元数据存储、缓存策略等进行了针对性优化.实验证明,该优化方案可以有效地解决NameNode内存负载过重的问题,并且海量指纹数据小文件的上传和查询性能得到了提高.
HDFS;小文件;SequenceFile;文件合并;元数据存储;缓存策略
0 引 言
近年来电子商务的飞速发展使得网上的交易量日渐增大,例如在2013年的“双十一”中,淘宝的日交易额就突破了350亿元人民币[1].随之而来的问题是如何更好地保障网上交易的安全性.相对于传统的密码方式,有学者提出了使用每个人唯一的指纹信息来保证交易的安全性[2].采用指纹识别技术保证网上交易的安全性,首先要解决的问题就是海量指纹数据的存储问题.最近出现的云存储技术为我们提供了一种新的解决思路.云存储系统有很多种,例如 GFS,HDFS,MooseFS,Haystack,TFS等.其中,HDFS已经比较成熟,而且是一款开源软件.因此,本文决定采用HDFS进行指纹数据的存储管理.HDFS(Hadoop Distributed File System)采用了Master/Slave架构,该系统由一个NameNode和多个DataNode组成[3].由于HDFS在设计之初是用来处理大量的大文件的,所以当需要用HDFS写入海量指纹数据小文件时,就会出现NameNode内存负载过重的问题:1)一个指纹数据文件大概需要1 kb的空间,而这一个文件的元数据大概需要150 b.由于云存储集群中使用的大部分都是普通的PC机,因此,当指纹数据文件的数量以亿为单位时,NameNode的内存就无法支持存储这么多的元数据了[4];2)上传查询大量小文件时速度过慢.为了更好地处理大文件,在HDFS中控制流与数据流是分开的,元数据的生成、查询等由NameNode完成,而数据的上传读取由各个节点分布式完成.但是当读写大量指纹数据小文件时,每一个小文件的读写都需要NameNode建立一个任务,每一个任务的启动和释放都需要耗费一定的控制时间,而这样一次任务也许只需要1 kb的数据传输,造成数据流传输消耗的时间小于控制流传输消耗的时间,这样会导致对小文件访问的延迟.如果有大量的小文件等待,甚至会造成NameNode的崩溃.
目前,解决HDFS下的小文件存储效率问题的主流思想是将小文件合并为大文件[5-6].主要有2种方法:一种是基于Hadoop自带的HAR[7](Hadoop archives)技术,HAR将大量的小文件合并到一个大文件中,虽然文件个数减少了,但是所需的存储空间并不变,而且合并前的源文件不会被自动删除,需要管理员手动进行删除;另一种方法是基于SequenceFile[8]的序列化文件技术,主要思想是采用〈key,value〉的形式合并大量的小文件,这种方法可以建立良好的索引,而且还可以支持数据分割与数据压缩.因此,本文选择采用SequenceFile技术将大量的小文件合并为大文件.但是,实际应用中仅仅采用SequenceFile技术并不能达到理想的效果,需要按照实际情况具体问题具体分析.
1 指纹数据存储优化方案设计
本文针对指纹数据小文件存储问题提出了一种优化方案.由于本文方案中指纹数据一般是一次存储、多次读取,所以主要优化其读取性能,提高查询的速度.采用SequenceFile技术将大量小文件合并成大文件,并且按照地理位置信息进行文件的合并及存储.大文件的元数据还是存储在NameNode的内存中,对于小文件来说,热点文件的元数据放置在NameNode的内存中,非热点文件的元数据分布式地放置在DataNode的内存中.由于本系统中的小文件是按照地理位置进行合并及存储的,因此,在搜索小文件时可以通过增加2~4位有关地理位置的控制信息来缩短搜索所需要的时间.同时,本文方案针对小文件采用特定的缓存策略,可以有效地减少磁盘写入及读取的次数,提高系统性能.
1.1文件合并
本文方案采用SequenceFile技术完成小文件的合并.SequenceFile是Hadoop提供的一个API接口,是为了存储二进制形式的Key-value对而设计的.SequenceFile共有3种压缩类型,分别为None,Record和Block.其中:None 是不对记录进行压缩;Record仅仅压缩每一个Record中的value值;Block将一个块中所有的Records压缩到一起.由于本文提出的优化方案是将元数据分布式存储在DataNode上的,所以不需要考虑元数据所占的空间,为了查询更方便,可以选择仅仅压缩每一个Record中的value的压缩方式.同时,在每一个生成的块的头文件中增加4 bit的Location Parity用于以后地域位置校验.经过Record类型的SequenceFile合并压缩之后生成的文件格式如图1所示.
为了减轻NameNode负担,系统设计在客户端与NameNode之间增加一个文件判别合并器,该模块的功能如流程图2所示.
首先,文件判别合并器分析待上传文件是否属于小文件,本方案设定小于1 M的文件属于小文件,然后按照文件的大小决定存储方式.若待上传的文件不属于小文件,则按照HDFS的常规方式完成数据的存储;若待上传的文件属于小文件,则在文件判别合并器中创建一个文件用来临时存储数据,以后上传的小文件都写入到这个文件中,当这个文件大于等于63 M且系统空闲时进行文件的合并上传.同时,也要设定一个等待阈值,不能让文件等待上传的时间过长,超过阈值时,即使块的大小没有达到63 M,也要在系统空闲时进行数据的上传.

图1 SequenceFile中Record压缩类型文件格式
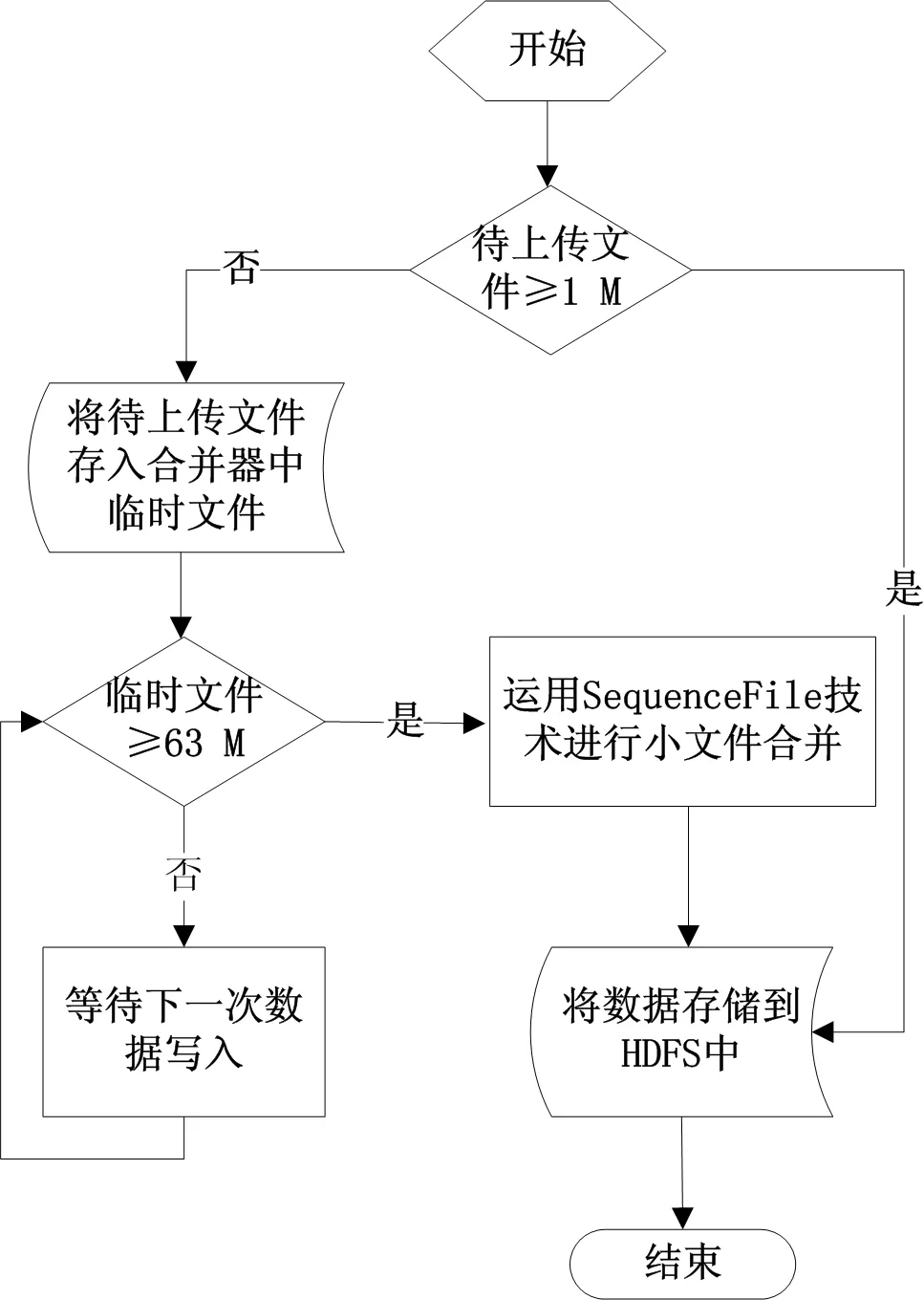
图2 文件判别合并器工作流程
网上支付系统中的指纹验证有其特殊性.用户使用网上支付系统需要先登入账号,然后通过指纹验证来完成交易,可以从用户的账户信息中获得其地理位置信息.本文方案按照地域信息将用户的指纹数据进行合并,相同地域信息的指纹数据合并到同一个数据块中.若一个地域的指纹数据需要合并成多个数据块,则尽量将它们保存到同一个DataNode中.将DataNode与地域信息之间的映射关系表存储到NameNode中,方便客户端的读取.当客户端发出查询请求时,需要在发给NameNode文件名之前增加4位地理位置位(可以根据需要具体设置,位数越多越精确,消耗的资源也相对越多).查询时优先查找NameNode内存,若内存命中,则完成此次查询;若NameNode的内存没有命中,则可以根据地域信息与DataNode之间的映射表,告知客户端需要联系的DataNode列表,客户端可以在这些DataNode的内存中寻找元数据.由于这些查找工作都是在内存中进行的,并不需要进行磁盘读取,因此提高了系统的查询性能.
1.2元数据存储
当HDFS被用来处理大量小文件时会出现名字节点内存不足的问题,很多学者提出采用SequenceFile技术解决这一问题.SequenceFile技术在一定程度上可以解决内存占用率过高的问题,但是大量的小文件经过SequenceFile处理之后,其元数据也将是大量的.传统方案中将大量小文件合并时产生的索引信息存放在NameNode的磁盘中,当有大量的小文件同时需要查找时,查找的速度会过慢.本文提出的针对指纹数据的存储优化案,大文件的元数据还是存储在名字节点的内存中,只有小文件元数据中的热点数据才被存储在名字节点的内存中,非热点的小文件的元数据则按照地域信息分布存储在各个数据节点上.地域信息与数据节点的映射关系表存储在名字节点的内存中.每一个数据节点的内存中只需要保存它所存储的小文件的元数据,管理员可以根据实际情况具体分配名字节点的内存.例如,在本方案中,由于重点处理的是大量的指纹数据小文件,因此分配给小文件的内存可以适当多一些,本文将名字节点内存的60%用来存储小文件的元数据,其余的内存用来存储大文件的元数据或者空闲.保存在名字节点中的小文件的元数据采用动态置换策略,当某一个小文件1 d的读取次数达到设定的阈值时被判定为热点文件,然后将它的元数据存储到名字节点的内存中;当一个已经被判定为热点数据的小文件3 d内读取次数达不到设定的阈值时,判定为热点失效,将其元数据从名字节点的内存中移除.元数据存储方案如图3所示.
1.3缓存策略
为了进一步加快客户端查询文件的速度,可以采取一定的缓存策略.首先,在客户端的缓存中存储一个最常访问的DataNode列表,用户查询时可以先查询这个列表中的DataNode内存,如果内存命中就可以节省大量的时间.其次,在DataNode的缓存中可以存储一部分频繁访问的小文件数据,使得高频率的小文件数据读取不需要经过磁盘I/O,一定程度上减少了磁盘读取的次数,提高了访问效率.最后,由于NameNode需要经常访问DataNode与地域位置信息的映射关系表,因此,可以将这个关系表也存放在缓存中.考虑到热点数据,NameNode可以缓存一些热点小文件的元数据,即其所在的DataNode、块ID及在块中的偏移量.这样的缓存策略可以进一步提高客户端的访问速度,优化系统性能.

图3 元数据存储方案
2 实验设计及实验结果
接下来通过实验将本文方案、仅仅经过SequenceFile改进的HDFS方案和原HDFS方案在文件上传、查询过程中NameNode的内存使用率和所需要的时间作性能比较.
2.1实验环境
为了对改进后的HDFS性能进行评估,搭建了一个有10个节点的HDFS集群,其中1个节点为NameNode,9个节点为DataNode.实验环境为:5台SuperCloud SC-R6220服务器(2U,2节点),其中CPU为Intel Xeon 4C E5506,2.13 GHz;内存4 G;硬盘1 000 G,7 200转.操作系统为64位CentOS 5.5;0.20.1版的Hadoop,千兆以太网.
2.2实验数据集
采用中国科学院大规模多模式指纹数据库中的多采集仪交叉匹配数据库.该数据库包含9个子库,分别由9种主流设备采集,共有10万个指纹数据文件.一个文件大约10 kb,文件的总大小为1 Gb.
2.3实验方案及实验结果
2.3.1 文件上传性能测试
实验1为了方便描述,将本文提出的方案、仅仅采用SequenceFile技术的HDFS方案分别简称为本文方案和SF_HDFS.分别从数据集中取出100,1 000,5 000,10 000,50 000,100 000个数据上传到3种系统中,每种实验进行3次,记录每次上传所需的时间,并计算其平均值及当10万个数据上传完毕后NameNode内存的占用率,最后将3种方案得出的结果进行对比.得出的实验结果分别如图4与图5所示.
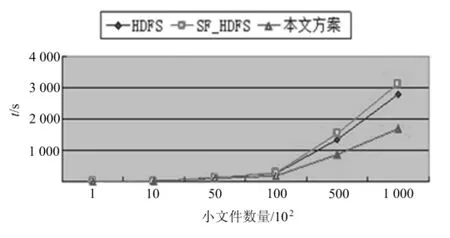
图4 小文件上传时间
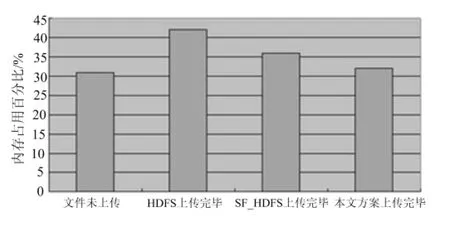
图5 NameNode内存占用百分比
由实验结果可以得出,虽然SF_HDFS采用了SequenceFile对小文件进行合并有效地节省了NameNode的内存空间,但是由于每一个小文件进行上传时都要进行一次SequenceFile,因此,当小文件数量增多时就会将很多时间浪费在SequenceFile工作中.而本文方案增加了文件判别合并器,减少了SequenceFile的次数,在节省内存的同时减少了上传文件所需要的时间.
2.3.2 文件查询性能测试
实验2当系统中分别存储100,1 000,5 000,10 000,50 000,100 000个小文件时分别用3种方案对随机小文件进行查询,每一种情况进行20次随机查询,统计各种情况下查询所需要的平均时间,并进行对比.考虑到热点数据问题,对同一文件连续进行30次查询,从实验数据集中选择30组指纹数据文件,计算查询的平均时间.实验结果分别如图6与图7所示.

图6 小文件随机查询测试
图7 热点小文件查询测试
从随机小文件性能测试的结果中可以看出,当文件数量较少时,3种方案的性能差别不明显,但随着小文件数量的增大,本文方案的优势逐渐体现出来.这是由于SF_HDFS需要进行二级查询,HDFS需要进行遍历查询,但本文方案是针对地域进行查询,只需要查询地域表再去DataNode的内存中进行查找.由于在DataNode的内存中所需遍历的数据较少,同时在查找到的DataNode上可以直接进行数据读取而不需要再进行DataNode间的跳跃,因此,当小文件增多时本文方案的性能才能更好地体现出来.
从热点小文件查询测试结果可以得出,当文件数量增多时,SF_HDFS的性能会变差,这是由于它没有针对热点数据进行改进,相比于HDFS多了一层硬盘级别的查询,因此,性能不是特别理想.本文方案设定对应的缓存策略,客户端可以直接从其经常访问的DataNode列表进行查询,同时热点小文件的内容也会保存在缓存中,一定程度上提高了本文方案的查询效率.
由以上实验结果可以得出,本文针对海量指纹数据小文件存储提出的优化方案确实可以提高小文件存储性能.
3 结 语
针对海量指纹数据小文件,采用SequenceFile技术进行小文件的合并,解决NameNode的内存问题,同时进行了优化.通过实验证明,本文提出的方案确实解决了海量小文件上传时NameNode内存负载过重的问题,同时提高了小文件上传及查询的效率.由于本文方案只用由10个节点组成的实验平台进行验证,当真正应用到几千个节点组成的集群时,索引信息在DataNode上如何更好地进行分布式存储,各个DataNode之间的负载如何均衡,都需要进行进一步的研究.本文提出的优化方案一定程度上增加了系统设计的复杂度,如何减少系统的复杂度也需要进一步的研究.
[1]魏一东.“双十一”天猫淘宝交易额破350亿突破马云预期[EB/OL].2013-03-04[2013-11-12].http://cq.people.com.cn/news/20131112/20131112119149310301.html.
[2]于秀霞.指纹识别技术在身份认证系统中的应用[J].现代情报,2005,9(5):217-220.
[3]White T.Hadoop:The definitive guide[M].Peking:O′Reilly Media Inc,2011:30-32.
[4]Konstantin S,Kuang H,Radia S,et al.The Hadoop distributed file system[C]//Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST).Nevada:IEEE,2010:273.
[5]赵晓永,杨扬,孙莉莉,等.基于hadoop的海量MP3文件存储架构[J].计算机应用,2012,32(6):1724-1726.
[6]余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安交通大学学报,2011,45(6):59-63.
[7]Dhruba B.Hadoop Archives[EB/OL].2013-08-04[2014-03-04].http://hadoop.apache.org/common/docs/current/Hadooparchives.html.
[8]Liu X J,Xu Z Q,Gu X.Study on the small files problem of Hadoop[C]//2012 IEEE 2nd International Conference on Cloud Computing and Intelligence Systems.Hangzhou:IEEE Beijing Section,2010:278-281.
(责任编辑 陶立方)
HDFS-basedstorageresearchformassfingerprintdata
ZHANG Yuxiang, ZHAO Jianmin, ZHU Xinzhong, XU Huiying
(CollegeofMathematics,PhysicsandInformationEngineering,ZhejiangNormalUniversity,JinhuaZhejiang321004,China)
When designed the HDFS, it was usually only considered how to handle large files better, and HDFS was not optimized for massive small files. When used HDFS to manage massive small files such as fingerprint datafiles there were some difficulties. For example, overloading of the NameNode and the performances of upload and query were not satisfied. The serialization technology named SequenceFile to merge small files was used and some targeted optimization about the merging of small files, the storage of metadata and the caching strategies were considered. Experimental results showed that the proposed scheme could effectively deal with the problem of NameNode memory′s overloading. The upload and query performances about massive small files sucn as fingerprint datafiles were also improved.
HDFS; small files; SequenceFile; merging of files; metadata storage; caching strategies
10.16218/j.issn.1001-5051.2015.02.010
2014-09-12
国家自然科学基金资助项目(6127268)
张宇翔(1989-),男,河南安阳人,硕士研究生.研究方向:云计算;虚拟现实技术.
TP391.4
A
1001-5051(2015)02-0179-06
