一种虚拟机负载均衡调度算法
2015-08-09张莹李华
张 莹 李 华
(国家知识产权局专利局专利审查协作河南中心,河南 郑州 450000)
虚拟化技术是企业创建绿色数据中心的核心技术之一,多处理器技术的快速发展使计算能力有了突破性的提高,同时也使虚拟化技术成为研究热点。虚拟化技术通过在底层物理环境与虚拟机之间建立虚拟机监视层,从而屏蔽了复杂的底层物理环境,使物理机硬件资源不仅能够同时被多个虚拟机共享,处于运行状态的虚拟机还可以在两台不同的物理机之间进行无间断的迁移[1]。因此,为了合并服务器资源和应用,虚拟化技术逐渐成为大型企业构建安全稳定的企业架构的最佳解决方案。
目前,在商业发展和开源技术研究中有多种虚拟化架构,其中包括剑桥大学的XEN。在Xen中,多个虚拟机同时运行在相互隔离的虚拟环境中,共享底层物理硬件,包括处理器资源,且各个虚拟机能够以接近物理计算系统的性能运作[2]。Xen中常用的三种CPU调度算法包括:BVT(借用虚拟时间算法)、SEDF(最早截止时间优先算法)和基于信任值算法(Credit),三种算法各有不同的性能瓶颈,因此,如何实现高效调度成为虚拟化技术中面临的更大挑战。
专利CN102053858A中提出了一种虚拟机调度算法,通过监测虚拟机的CPU 调度以及状态标识信息,解决了锁抢占问题,从而在多处理器架构中实现更精确的可调度状态监测,提高底层物理CPU 资源的利用率[3]。华中科技大学的金海提出了一种Xen虚拟化环境中动态感知音频应用的CPU 调度算法,通过设置合适的时间片大小以及增加实时优先级等策略,提高了Xen 中音频应用的播放性能[4]。
本文提出了一种SMP(对称多处理器)系统中的动态负载均衡调度算法—动态最早截止时间优先算法(DLB_DEF)来提高物理CPU 利用率,从而减少空闲CPU。为了实现该算法,我们设计了一种共享等待队列,考虑到多处理器环境中cache和内存的同步关系,使虚拟CPU在执行完任务之前都在同一个物理CPU上执行。仿真实验表明,改进后的DLB_DEF 算法能够优化系统性能,并完全消除空闲物理CPU。
2 SEDF算法以及SMP架构
2.1 SEDF算法
在虚拟化计算环境中,多个虚拟机通过分时调度策略共享物理处理器资源,每个虚拟机就是一个域,每个域对应一个或多个虚拟CPU(VCPU)[5]。因此,如何公平高效地将物理CPU 资源分配给多个虚拟机,并使CPU 有效利用率达到合理范围就是一个问题。
SEDF 算法是一种基于最早截止时间策略的实时算法,每个VCPU都会根据自身处理情况设置一个参数:最早截止期限(deadline),SEDF根据该时间参数决定VCPU的调度顺序[6],而且VCPU 的优先级根据deadline 的改变而变化。SEDF 算法将调度具有最早截止时间的VCPU,从而保证虚拟机任务能及时完成。
每个域都设置一个三元组(s, p, x),时间片s 和周期时间p共同表示该域请求的CPU份额和时间,flag是一个boolean 类型的值,表示该域是否能够占用额外的CPU 份额,三个参数时间粒度的设置对调度的公平性影响很大。VCPU 结构体的属性如图1 所示,每个PCPU 包含2个双链表队列,如图2所示。

图1 VCPU结构体

图2 PCPU的双链表队列
runnableq 队列中的VCPU 都是处于running 或runnable状态,根据deadline参数排序,队首的VCPU处于running 状态,而其他VCPU 都处于runnable 状态,必须在deadline规定时间内执行调度;waitq队列中的VCPU处于runnable状态,还未开始计时。
总之,SEDF 算法可以通过参数动态配置VCPU 的优先级,因此在负载较大的实时系统中具有较高性能,当系统负载较小时其CPU 使用率可以达到100%,然而,随着负载逐渐增大,一些任务就会发生时间错误,错过截止期来不及处理而夭折。另外,SEDF 算法不支持SMP 架构,从而不能实现对多CPU间全局负载均衡的控制。
2.2 SMP架构
在SMP架构中,多个处理器共享内存,但每个处理器都对应一个私有cache,大多数调度算法都遵循就近原则执行调度,也就是说首选本地CPU来执行相应的任务,从而提高cache 命中率。当一个私有cache 被修改后,就要考虑内存和cache之间的一致性问题,即不仅要确保修改后cache和相应内存之间的一致性,而且要确保内存和其他cache 之间的一致性。在执行过程中,VCPU 可能会处于挂起状态,比如时间片到或被其他事件阻塞,此时VCPU 虽然停止执行,但是其对应的私有cache 中还保存着运行时环境[7],当处于挂起状态的VCPU 被再次唤醒时,使其在上次执行过的物理CPU上继续执行,从而减少数据一致性产生,即就近调度原则。
为了提高CPU资源的利用率,就要重视cache和内存一致性带来的性能消耗问题。即VCPU 在PCPU 之间的频繁调度会产生严重的cache抖动,进而使数据一致性问题产生额外的性能损耗,严重降低CPU执行速度[8]。
3 DLB_DEF算法的设计
通过上节中对SEDF 算法的分析可知:SEDF 在实时性环境中具有较好性能,但不支持SMP 架构,如果一个CPU空闲,它只能等待新的VCPU任务到来,而此时其他CPU 的任务量可能已经超载,此时SMP 架构中的多处理器系统的物理性能远低于具有相同处理器个数的系统。基于此研究结论,本文提出一种基于SMP 架构的虚拟机负载均衡调度算法——DLB_DEF算法。
在DLB_DEF 算法中,共享队列shareWaitq 中的VCPU 按照deadline 参数进行排序,且都处于runnable 状态,如图3所示为shareWaitq结构体属性:

图3 shareWaitq结构体
每个PCPU 具有不同的等待时间权值,即为对应runnableq 队列中存放的VCPU 的运行时间总和。当PCPU 空闲时就从共享等待队列中调取VCPU 任务,同时,考虑到cache 就近原则,将该VCPU 任务上次执行过的PCPU 记作pre_pcpu,改进后CPU 和VCPU 的结构体属性分别如图4和图5所示:
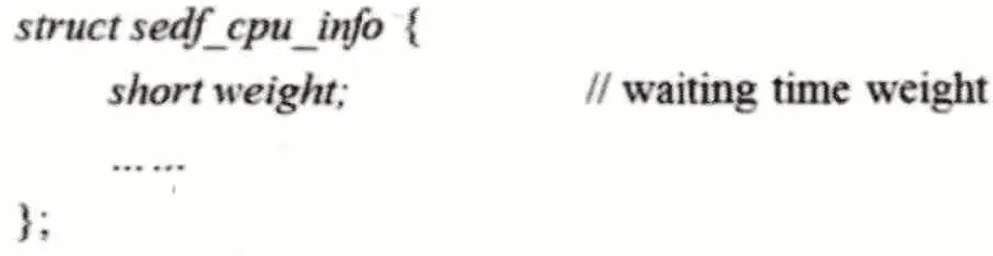
图4 改进后的PCPU结构体

图5 改进后的VCPU结构体
假设物理机有M个可运行的PCPU,如式(1)所示;式(2)为runnableq队列中的所有VCPU;式(3)为所有PCPU的weight集合;式(4)为weight集合中的最小时间权值。
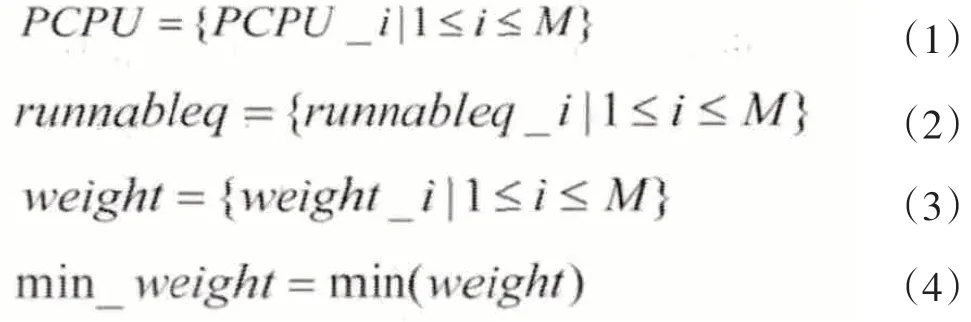
改进后的动态负载均衡算法DLB_DEF与SEDF算法相同,PCPU都是优先调用具有最早截止期限的VCPU,通过增加并实时更新共享等待队列shareWaitq,从而实现动态负载均衡。DLB_DEF算法如图6所示:

图6 DLB_DEF算法
4 仿真实验与结果
4.1 仿真平台及环境配置
Schedsim 是一种CPU 调度模拟器,提供了良好的接口,能够实现先来先服务算法、短作业优先算法等多种常见的调度算法[9]。基于Schedsim,本文设计并实现了SEDF 算法和改进后的DLB_EDF 算法,并模拟了两种算法在不同数量处理器上的调度情况,最后对两种算法调度的系统性能进行了分析和比较。
将SEDF 和DLB_EDF 中的一个VCPU 任务记作一个进程,由5个参数表示:进程ID 号、优先级、就绪时间、执行时间和最早截止期限。为了满足仿真实验的需要,假设PCPU个数最大为6,配置5个进程池,分别包含10、20、40、60、80个进程,仿真实验步骤如下:
步骤1:创建的进程池至少符合以下要求:①2个就绪时间相同而最早截止期限不同的进程,②2个就绪时间和最早截止期限都相同的进程,③2个执行时间不同而就绪时间和最早截止期限相同的进程,④2个分别具有不同的就绪时间、执行时间和最早截止期限的进程,⑤就绪时间与执行时间之和大于最早截止期限的2个进程,⑥将所有进程的最早截止期限设置为与优先级成反比。
步骤2:进程池中的所有进程入队。
步骤3:配置PCPU个数,选择调度算法和调度模式。
步骤4:运行模拟器。
以下实验结果是以包含40个VCPU的进程池作为参考,对每个进程池分别做10 组测试,并取10 组数据的平均值。
4.2 仿真结果分析
当两个算法的进程都完成时,如图7、图8、图9 分别为系统吞吐量、平均周转时间和平均应答时间的比较结果。
通过图7-9我们可以看到,当PCPU个数为1时,由于需要考虑cache 就近原则,因此DLB_DEF 的系统吞吐量和任务完成率比SEDF算法略小,但是平均周转时间以及平均响应时间比SEDF略大;当PCPU个数增多,即在支持SMP 架构的多处理系统中,具有负载均衡策略的DLB_DEF 算法的各个性能指标都略超过SEDF,系统吞吐量和任务完成率逐渐增大,平均周转时间以及平均响应时间却逐渐减小。特别地,当DLB_DEF 和SEDF 的系统吞吐量具有最大差值时,PCPU个数等于4,即在PCPU为4时DLB_DEF算法具有最优性能。当PCPU个数继续增大为6 时,SEDF 算法由于空闲PCPU 的出现而导致多种系统指标性能降低,而此时,在DLB_DEF算法中,虽然PCPU个数增多,但由于共享等待队列的互斥性,PCPU调用任务时等待互斥锁的解锁时间逐渐增大,同时,共享等待队列的更新也要占用更多时间,因此,DLB_DEF 算法的系统吞吐量、任务完成率、平均周转时间以及平均响应时间也逐渐达到平稳状态。
当PCPU个数逐渐增多时,即具有更多处理器来执行系统任务时,SEDF 和改进后的DLB_DEF 算法的任务完成数和任务完成率都逐渐增大,但是两者的完成率都达不到100%,即有些VCPU 由于错过截止时间而错过执行的机会,但是DLB_DEF 在总体上完成量比SEDF多。
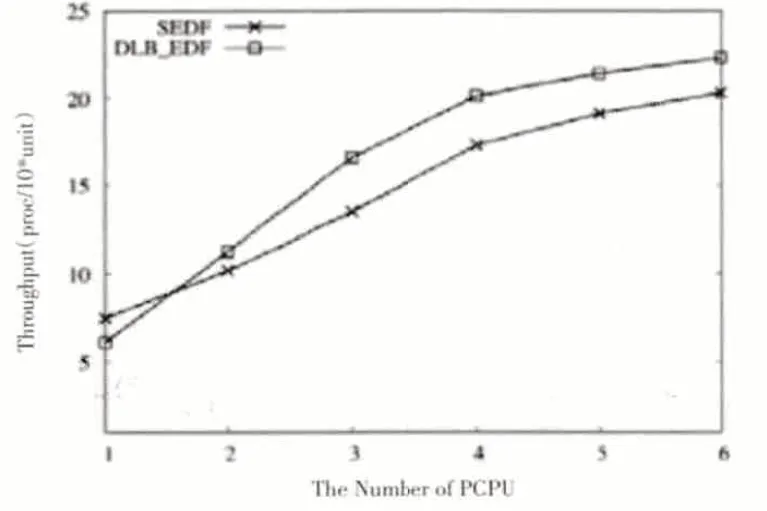
图7 系统吞吐量对比
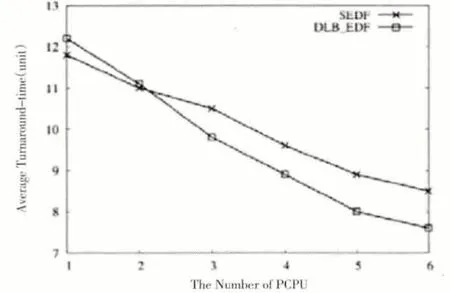
图8 平均周转时间对比
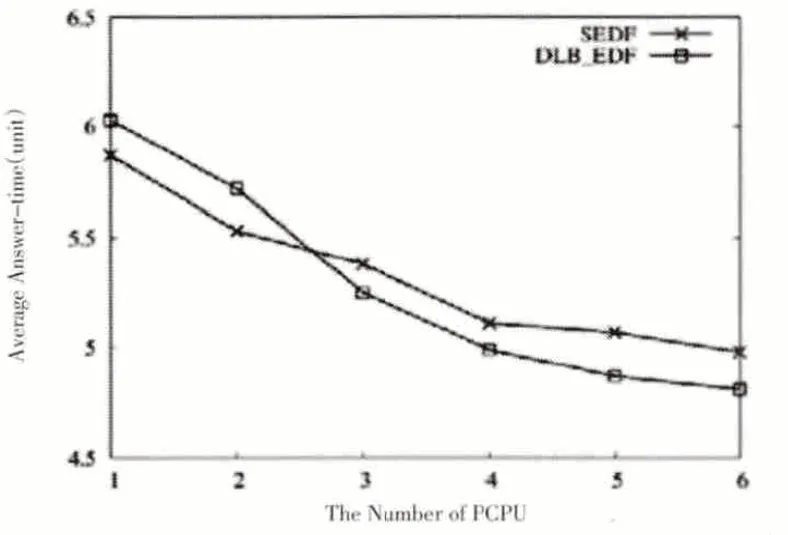
图9 平均应答时间对比
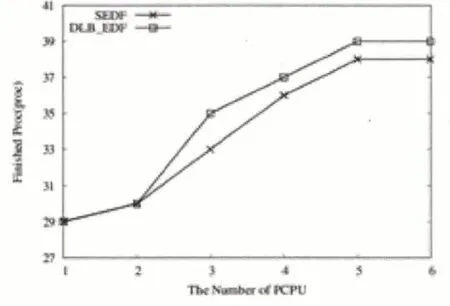
图10 完成进程数对比
5 总结
本文主要对SEDF算法进行分析,针对其不支持SMP架构的不足,提出一种动态负载均衡算法DLB_DEF。该算法设计了一个共享等待队列存储VCPU 任务,并根据cache就近原则和PCPU的等待时间权值,VCPU可选择最优PCPU 执行其任务。DLB_DEF 算法不仅可以降低cache 抖动带来的性能损耗,还可以通过获取PCPU 的最小等待权值来增大PCPU使用率。最后,在Schedsim仿真环境中模拟SEDF和DLB_DEF,仿真结果表明,DLB_DEF在系统吞吐量、平均周转时间和应答时间、进程完成率等性能指标上都略优于SEDF 算法。目前仅在模拟环境中执行DLB_DEF 算法,下一步任务要将DLB_DEF 嵌入到XEN源代码中并运行在真实虚拟环境中。
[1]怀进鹏,李沁,胡春明. 基于虚拟机的虚拟计算环境的研究与发展[J]. 软件学报,2007,18(8):1016-1026.
[2] Paul Barham,Ian Pratt,Keir Fraser,et al,“Xen and the art of virtualization,”In SOSP’03:Proc of the nineteenth ACM symposium on Operating systems principles,New York,ACM,2003,15:164-177.
[3]金海,吴松,石宣化,等. 一种虚拟CPU 调度方法[P].中国专利,102053858,2011-05-11.
[4] Huacai Chen,Hai Jin,Kan Hu,et al.“Adaptive audio-aware scheduling in Xen virtual environment,”In AICCSA’10: Proc of the ACS/IEEE International Conference on Computer Systems and Applications. USA, IEEE Computer Society Washington,2010:1-8.
[5]Hyunsik Choi,Saeyoung Han,Sungyong Park and Eunji Yang,“A CPU Provision Scheme Considering Virtual Machine Scheduling Delays in Xen Virtualized Environment,”TENCON’09:2009 IEEE Region 10 Conference.2009:1-6.
[6]Xinjie Zhang,Dongsheng Yin,“Real-time Improvement of VCPU Scheduling Algorithm on Xen,”In CSSS’11: Computer Science and Service System.2011:1506-1509.
[7]常建忠,刘晓建.虚拟机协同调度问题研究. 计算机工程与应用,2011,47(6):38-41.
[8] Min Lee, A.S.Krishnakumar, P.Krishnan et al.“Supporting Soft Real-Time Tasks in the Xen Hypervisor,”In VEE '10: Proceedings of the 6th ACM SIGPLAN/SIGOPS international conference on Virtual execution environments[J].New York,ACM,2010,45:97-108.
[9]姚文斌,郑兴杰.一种改进的SEDF 算法[J].小型微型计算机系统.2010,31(3):446-450.
