Intrusion detection model based on deep belief nets
2015-07-25GaoNiGaoLingHeYiyue2GaoQuanliRenJie
Gao NiGao LingHe Yiyue,2Gao QuanliRen Jie
(1School of Information Science and Technology,Northwest University,Xi’an 710127,China)
(2School of Econom ics and Management,Northwest University,Xi’an 710127,China)
Intrusion detection model based on deep belief nets
Gao Ni1Gao Ling1He Yiyue1,2Gao Quanli1Ren Jie1
(1School of Information Science and Technology,Northwest University,Xi’an 710127,China)
(2School of Econom ics and Management,Northwest University,Xi’an 710127,China)
This paper focuses on the intrusion classification of huge amounts of data in a network intrusion detection system.An intrusion detectionmodelbased on deep belief nets(DBN)is proposed to conduct intrusion detection,and the principles regarding DBN are discussed.The DBN is composed of a multiple unsupervised restricted Boltzmann machine(RBM)and a supervised back propagation(BP)network.First,the DBN in the proposed model is pre-trained in a fast and greedy way,and each RBM is trained by the contrastive divergence algorithm.Secondly,the whole network is fine-tuned by the supervised BP algorithm,which is employed for classifying the low-dimensional features of the intrusion data generated by the last RBM layer simultaneously.The experimental results on the KDD CUP 1999 datasetdemonstrate that the DBN using the RBM network w ith three or more layers outperforms the self-organizing maps(SOM)and neural network(NN)in intrusion classification.Therefore,the DBN is an efficient approach for intrusion detection in high-dimensional space.
intrusion detection;deep belief nets;restricted Boltzmannmachine;deep learning
W ith the grow th of network technologies and applications,computer network security has become a crucial issue that needs to be addressed.How to identify network attacks is a key problem.As an important and active security mechanism,intrusion detection(ID)has become a key technology of network security,and has drawn the attention of domestic and foreign scholars world-w ide.Intrusion detection based on different machine learning methods is amajor research project in network security,which aims at identifying unusual access or attacks on internal networks[1].
In literature,many machine learning methods have made great achievements in IDS,such as the NN[2],support vectormachine(SVM)[3]and SOM[4].Thesemethods have been introduced to the field of intrusion detection by previous researchers.Most of traditional learning machinemethodsw ith shallow architectures have one hidden layer(e.g.,BP)or no hidden layer(e.g.,maximum entropy model).
Owing to lim ited samples and computing cells,the expressive power of shallow learning methods for complex function is lim ited,and its generalization ability for complex classification problems is subjected to certain constraints[5].The continuous collection of traffic data by the network leads to problems concerning the huge amounts of data in network intrusion detection and prediction.Therefore,how to develop an efficient intrusion detection model oriented towards huge amounts of data is a theoretical and practical problem that should be solved urgently.
The deep learning model used in large-scale data analysis has an outstanding performance,which is a prom ising way of solving intrusion detection problems.The DBN w ith deep architectures is proposed by Hinton et al.[6],and it uses a learning algorithm which greedily trains one layer at a time w ith an unsupervised learning algorithm employed for each layer[6].Bengio et al.[7]followed the research on deep learning,which shows the strong capacity of learning essential characteristics of data sets from a few samples.A lthough DBN can be trained w ith unlabeled data,DBN is successfully used to initialize deep feedforward neural networks.
In this paper,an intrusion detectionmodel based on the greedy layer-w ise DBN is presented.In order to improve the performance of DBN,its parameters are explored,including the depth of DBN,the number of nodes in the first hidden layer,the number of nodes in the output layer and so on.Finally,the efficiency of DBN is evaluated on the KDD CUP 1999 dataset.The DBN outperforms SOM and NN in detection accuracy and false positive rate.
1 Proposed DBN M odel for Intrusion Detection
An overall framework of the network intrusion detection model based on DBN is trained in three stages,as shown in Fig.1.First,the symbolic attribute features in KDD CUP 1999 dataset[8]are numeralized and subsequently normalized.Then,a DBN is trained on the standardized dataset and the weights of the DBN are used to initialize a neural network.This pre-training procedure consists of learning a stack of RBM s w ith the unsupervised contrastive divergence algorithm.The learned fea-ture activations of one RBM are used as the data for training the next RBM in the stack.The nonlinear high-dimensional input vector is sampled as its corresponding optimal low-dimensional output vector.Finally,a DBN is constructed by unrolling the RBMs and fine-tuned by using the BP algorithm of error derivatives according to the class labels of the input vectors.The obtained DBN can be used to recognize attacks.
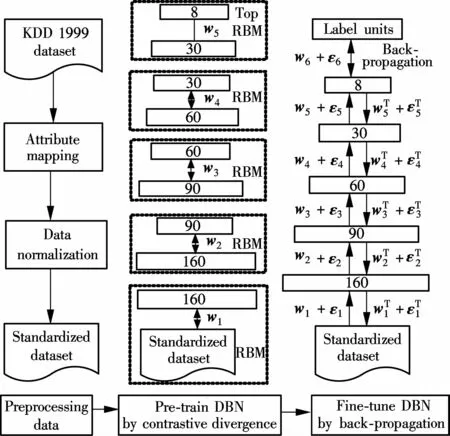
Fig.1 The pipeline for training IDS
2 Deep Belief Network
The deep learning model attracts more attention from researchers at home and abroad due to its outstanding learning ability for the complex data[6].A deep learning model containingmultilayer hidden units is used to gradually establish the optimal abstract representation of the raw input at the penultimate layer in Fig.2.The representative deep learning model is the DBN based on the RBM in stacks.Learning DBN is a process of greedy layer-w ise training RBM.
The DBN[6],which isa probabilistic generativemodel,is a deep neural network classifier of a combination of multilayer unsupervised learning networks named RBM and a supervised learning network named BP[9].In a DBN,the units in each layer are independent given the values of the units in the layer above.Fig.2 shows a multilayer generative model,in which the top two layers have symmetric undirected connections and the lower layers receive directed top-down connections from the layer above.The bottom layer is observable,and the multiple hidden layers are created by stacking multiple RBM s on top of each other.The upward arrows represent the recognition model,and the downward arrows represent the generativemodel.In the greedy initial learning,the recognition connections are tied to the generative connections.In the learning process of the generative model, once the weight parameter W is learned,the original data v can be mapped through WTto infer factorial approximate posterior distributions over the states of the variables in the first hidden layer h1.A DBN with n layers can be represented as a graphicalmodel.The joint distribution of the visible layer v and the hidden layer hk,for k=1∶n,is defined as
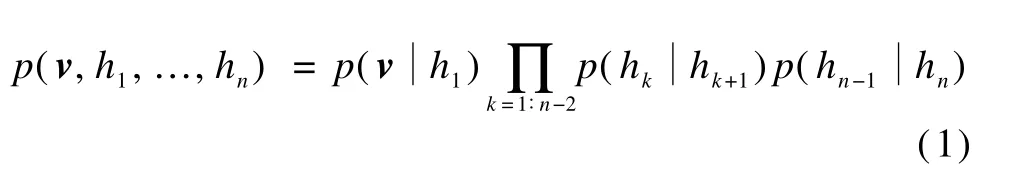
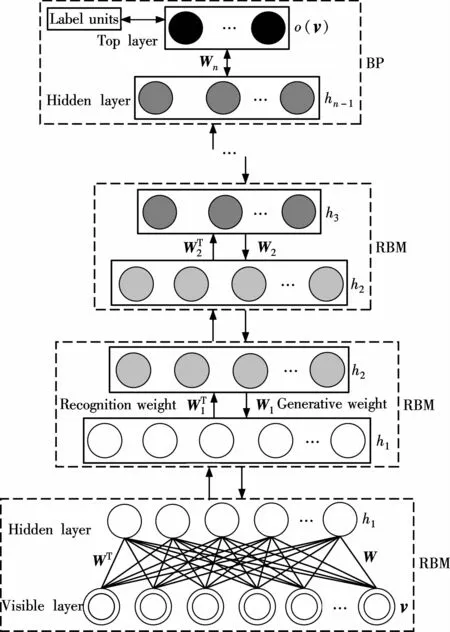
Fig.2 A graphical representation of a DBN and its parameters
In a bottom-up process,the recognition connections of DBN can be used to infer a factorial representation in one layer from the binary activities in the layer below.In a top-down process,the generative connections of DBN are used to map a state of the associativememory to the raw input.The DBN performs a non-linear transformation on its input vectors and produces low-dimensional output vectors.Using the greedy initial learning algorithm,the original data are perfectly modeled and a better generative model can be acquired.
The procedure of the training DBN consists of two phases.In the first phase,a layer-w ise greedy learning algorithm is applied to pre-train a DBN,and the RBM of each layer is trained by the CD algorithm[10].To obtain an approximate representation of the input vector v,the follow ing procedure is used.First,the posterior distribu-tionis sampled from the first-level RBM,and the visible variables v are sampled by the posterior distribution).Subsequently,the hidden variables h1are sampled repeatedly in the same way.The alternating Gibbs samplings are repeatedly performed k times until an equilibrium distribution is arbitrarily approached.The optimal representation h1of the input vector v becomes the input for learning the second-level RBM,and a sample h2is computed.The former procedure is repeatedly executed to train each RBM in a bottom-up way until hn-1is computed.A DBN is trained by using the layer-w ise greedy learning method which can be recursively repeated,and m illions of parameters can be learned efficiently.In practice,applying the CD algorithm can avoid the monstrous overall complexity of training DBN,so this algorithm is efficient.
In the second phase,the parameters of the whole DBN are fine-tuned.Theweights on the undirected connections at the top-level RBM are learned by fitting the posterior distribution of the penultimate layer.Using the BP learning algorithm,exact gradient descent on a global supervised cost function between the actual output vector and the desired output vector can be performed in DBN.This phase aims at obtaining the optimal parameters,which corresponds to the minimized difference between the above two vectors.
3 Restricted Boltzmann M achine
3.1 M odel structure
The core block networks for the DBN are RBMs,each of which is a two-layer neural network that consists of a visible layer and a hidden layer.Each unit of the hidden layer connects to all the units of the visible layer,and the visible and hidden units form a bipartite graph w ith no visible-visible or hidden-hidden connections.RBM is an energy-based undirected generativemodel that uses a layer of binary variables to explain its input data.The visible variables are described as the characteristics of the input data,and the hidden variables automatically generated through machine learning often have no actualmeaning.The undirected model is a binary stochastic neuron,meaning that each of them can latch onto one of two states:on or off.Thismodel is called RBM whose probability distribution obeys the Boltzmann distribution.
3.2 Inference of RBM parameters
RBM is an energy-based undirected generative model,which is constructed from a set of visible variables v={vi}and a set of hidden variables h={hj},as shown in Fig.3.Node i is in the visible layer,and node j is in the hidden layer.A property of RBM is the lack of direct connections within nodes of the same layer,while there are connections between the visible layer and the hidden layer.The visible units are conditionally independent given the hidden units states,and vice versa.Therefore,the posterior distributions P(H|V)and P(V|H)are sampled and factorized as

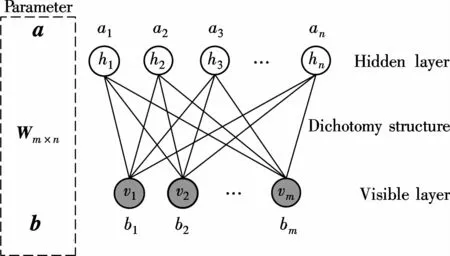
Fig.3 A graphical representation of RBM and its parameters
Given a visible v,a low-dimensional representation h can be sampled by the posterior distributionsTherefore,given a hidden variable h,a new representation v can be sampled by the posterior distributionsh).Since hj∈{0,1},the binary hidden unit probabilities are given as
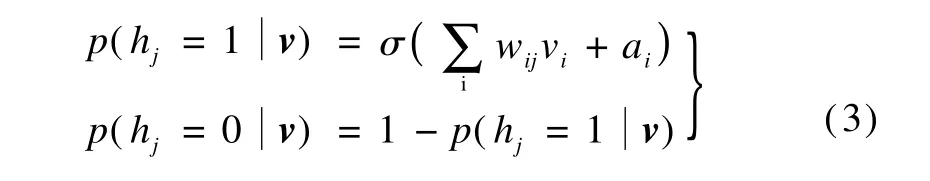
Since the RBM is a completely symmetric derivation,the binary visible unit probabilities are given as
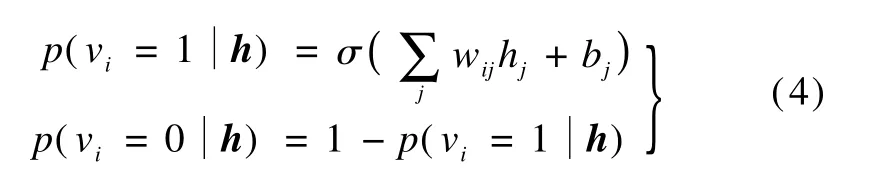
whereσdenotes the logistic sigmoid,

The visible units and the hidden units are assumed to be the binary stochastic units.In an RBM,the energy function w ith every configuration of visible and hidden variables is defined as

where W is the weightmatrix between the visible variable v and the hidden variable h;b is a visible variable bias;a is a hidden variable bias;and the parametersθ={W,a,b}of the energy function are learned.The probability of any particular configuration of the visible and hidden units is denoted by the following energy function:

4 Learning by M inim izing Contrastive Divergence
The optimal joint probability distribution can be acquired w ith the Markov chain method on the condition that the number of iterations is close to infinity.However,it is difficult to guarantee fast convergence and determ ine the step size of the iteration.The maximization process of log likelihood is the same as them inimization process of the Kullback-Leibler(KL)divergence,which is expressed as KL.Here,P0denotes the posterior distribution of the data,anddenotes the equilibrium distribution defined by RBM.Contrastive divergence proposed by Hinton[10]is a fast RBM training method.Instead of m inim izing KL),the m inim ized difference between KL)and KL)is defined as CD=KL(P0‖P∞θ)-KL(Pnθ‖P∞θ)(8)wheredenotes the posterior distribution of the reconstructive visible variables sampled by n steps of Gibbs sampling.The surprising empirical result is that even n=1 often gives a good result.KL)exceeds KL()unless P0=.Since the contrastive divergence is positive,P0is equivalent toThe contrastive divergence is equal to zero only when the RBM model is at equilibrium.
The parameters of the model,θ={W,a,b},can be adjusted in proportion to the approximate derivative of the contrastive divergence:
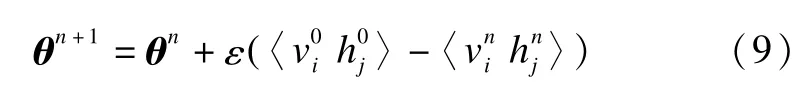
Itworks relatively well in practice that the original vector data is reconstructed only by one Gibbs step[10].The updated parameters are given as
Using an alternative CD learning algorithm,the highdimensional data is always close to the low-dimensional data.The procedure of the fast CD-k learning algorithm is listed as follows.
Algorithm 1 TrainRBM(V,ε,M,N,W,a,b)
Input:V is a sample from the training for the RBM,V={v1,v2,…,vM};εis the learning rate for the stochastic gradient descent in CD;M is the number of the RBM viable units;N is the number of the RBM hidden units;W is the RBM weight matrix;a is the RBM offset vector for viable units;b is the RBM offset vector for hidden units.Initialize parameter Wij=ai=bj=0,i=1,2,…,M,j=1,2,…,N;set the number of iterations T and the number of steps of Gibbs sampling K.


5 Fine-Tuning A ll Layers of DBN by Back-Propagation Algorithm
The weightmatrices,which are pre-trained at each layer by contrastive divergence learning,are efficient butnot optimal.Therefore,the unsupervised layer-by-layer training algorithm is performed for each RBM network,and the final supervised fine-tuning learning is used to adjust all the parameters simultaneously.The BP algorithm for feed-forward multi-layered neural network plays a key role in fine-tuning the weights of the connections in the DBN[9].Fine-tuning a DBN based on the BP algorithm consists of two phases.In the first phase,in order to obtain better initialization parameters,the feed-forward DBN is trained by the RBM learning algorithm based on k-step contrastive divergence.In the second phase,a measure of the difference between the actual output vector of DBN and the desired output vector isminimized,and the weight matrices are repeatedly adjusted during the down-pass.The down-pass,which propagates derivatives from the top layer back to the bottom layer,employs the top-down generative connections to activate each lower RBM layer in turn.Then the procedure of the fine-tuning learning algorithm based on the BP algorithm is listed as follows.
Algorithm 2 FineTuneDBN(example,l,numhid,εfine-tune,W,a,b)
Input:Example is a training set of〈vi,ti〉(i=1,2,…,m);l is the number of RBM layers;numhid is a set of hidden units{numhid1,numhid2,…,numhidl}at each RBM layer;εfine-tuneis a learning rate for the DBN training;Wkis the weight matrix for RBM at level k,for k from 1 to l;akis the offset vector for viable units for RBM at level k,for k from 1 to l;bkis the offset vector for hidden units for RBM at level k,for k from 1 to l.%Forward propagation
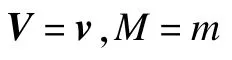

6 Experimental Results
6.1 Benchm ark dataset description
The KDD Cup 1999 dataset[8],which is provided by the Defense Advanced Research Projects Agency(DARPA)and contains the attack data of severalweeks,is employed to assess the performance of various IDS.
The KDD Cup 1999 dataset contains494 021 records in the training data and 11 850 records in testing data.The data distribution of the dataset is shown in Fig.4.

Fig.4 Attacks distribution in the KDD Cup 1999 dataset
6.2 Data preprocessing
Each record of the KDD Cup 1999 dataset,which is labeled as either normal or one specific kind of attack,is described as a vector w ith 41 attribute values.Those attributes consist of 38 continuous or discrete numerical attributes and 3 categorical attributes.Deep belief networks require floating point numbers for the input neurons,and the values of floating point numbers range from 0 to 1.Therefore,all features are preprocessed to fulfill this requirement.Preprocessing data consists of two phases as follows:
1)Numeralization of symbolic features.Three symbolic features,including protocol type,service type and flag type,are converted into binary numeric features.For example,protocol type“tcp”is converted into binary numeric features vector{1,0,0},“udp”is converted into vector{0,1,0},and“icmp”is converted into vector{0,0,1}.Since the features“service type”can be expanded into 70 binary features and the features“flag type”can be expanded into 11 binary features.Finally,41 attributes are numeralized as 122 attributes.
2)Normalization of numeric features.Each numerical value obtained in the first phase isnormalized to the interval[0,1],according to the follow ing data smoothing method.
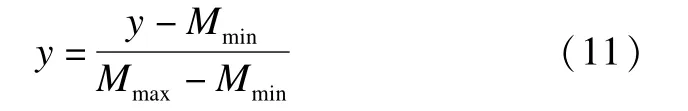
6.3 Evaluation measurem ent
An IDS requires high accuracy,high detection rate and low false alarm rate.In general,the performance of IDS is evaluated in terms of accuracy AC,detection rate DR,and false alarm FA.

where true positive TPis the number of attack records correctly classified;true negative TNis the number of normal records correctly classified;false positive FPis the number of normal records incorrectly classified;false negative FNis the number of attack records incorrectly classified.
The squared reconstruction error of the raw input is often used to monitor its performance.The squared reconstruction error is defined as
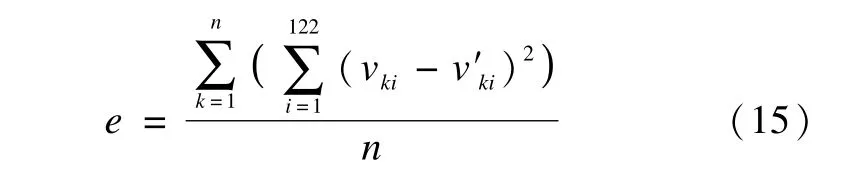
where vkiis the i-th component belonging to the k-th sample vector;v′kiis the i-th component belonging to the k-th reconstructed sample vector;n is the total number of samples,and the number of attributes after data preprocessing is 122.
6.4 Experimental results and analysis
Experiments are designed and implemented,in whichthe KDD Cup 1999 dataset is used to evaluate the performance of the proposed model.A ll programs are coded in Matlab 7.0 and run in a personal computer w ith an Intel CPU 1.86 GHz and 2 GB memory.
It is important to determine a proper iteration number.W ith the increase of iteration numbers,the detection rate increases accordingly,as shown in Fig.5.DBN can be expressed as DBNi,where i denotes the number of RBM layers.The deep DBN4is used to evaluate the detection rates corresponding to iteration times from 10 to 500.The curve of detection rate shown in Fig.5 appears to increases and then stabilizes.If the iteration number is greater than 150,the curve w ill be smoother.
据王涤非介绍,受中国环保、美国美盛Plant City工厂关停等因素影响,全球磷肥供应在2018开年之际就注定大幅减少。尽管沙特二期项目陆续提高开工率带来了少量额外供应,但由于中国国内一季度需求良好,印度市场2018年开年库存处于历史低位,且美国市场因Plant City关停而需求增加,上半年全球供应处于不足状态,价格也被持续稳步推涨。

Fig.5 The iteration number of RBM training
Tab.1 compares the performances of DBN,SOM and NN on the KDD Cup 1999 dataset.Four different DBNs,including a shallow 122-5 DBN1,a shallow 122-60-5 DBN2,a deep 122-80-40-5 DBN3and a deep 122-110-90-50-5 DBN4,are selected.According to the results in Tab.1,the detection rates of the shallow DBN1and DBN2are not better than that of SOM,but the detection rate of the deep DBN3added one layer RBM is higher than those of SOM and NN.Therefore,the ACof the deep 122-110-90-50-5 DBN4is improved by 2.67%and 6.19%,respectively,compared w ith SOM and NN.The DRof the deep DBN4is improved by 2.76%and 5.7%,respectively.The FAof the deep DBN4 is improved by 0.4%and 0.55%,respectively.Therefore,DBN using the RBM network w ith three or more layers outperforms SOM and NN in AC,DRand FA.
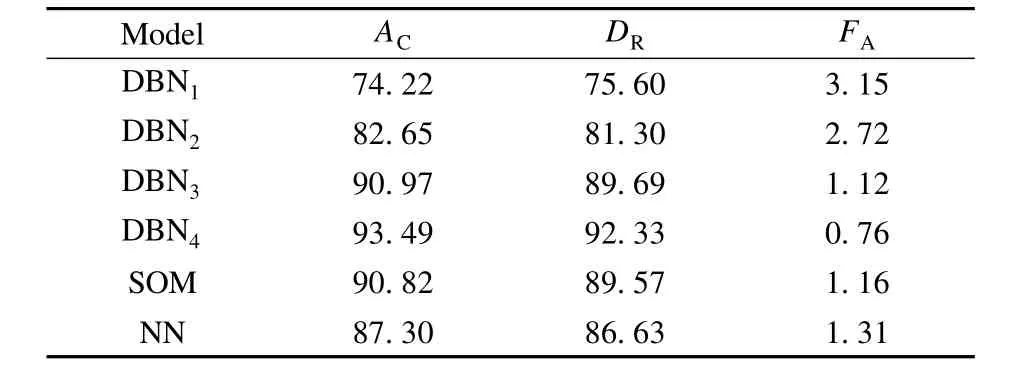
Tab.1 Performance comparison of the six network structures %
Larochelle et al.[11]argued that the number of nodes in the first hidden layer has a significant influence on classification performance.Fig.6 compares the performances of DBN w ith different number of nodes in the first hidden layer when a deep 122-110-90-50-5 DBN4is set.According to the results in Fig.6,the classified accuracy is the bestwhen the number of nodes in the first hidden layer is set to be 110.

Fig.6 Performance comparison of DBN w ith different numbers of nodes in the first hidden layer
Another important exploration is to choose an optimal number of nodes in the output layer to improve the performance of intrusion detection.In Fig.7,a deep 122-110-90-50-5 DBN4is selected,w ith the different numbers of nodes in the output layer set from 1 to 10.According to the results in Fig.7,the classification accuracy and detection rate are the optimal when the number of nodes in the output layer is set to be 5.
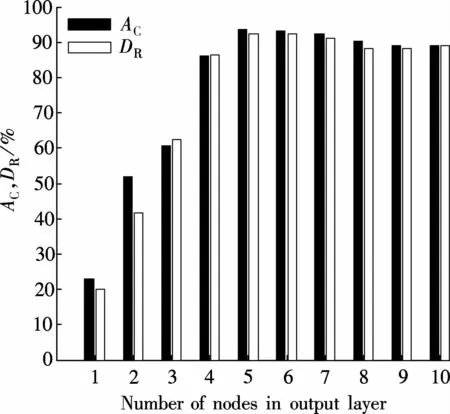
Fig.7 Performance comparison of DBN w ith different numbers of nodes in the output layer
The intrusion classification experiment is performed w ith different types of attacks in the KDD CUP 1999 dataset.Tab.2 compares the performances of DBN4,SOM and NN.In Tab.2,the accuracy rate of the DBN4is improved by 2.54%and 5.525%on average,respectively,compared with SOM and NN,and the false alarm rate of the DBN4is improved by 0.56%and 0.72%,respectively.The experimental results show that deep DBN4can effectively enhance the IDS detection rate and reduce their error rate.
Fig.8 compares the squared reconstruction errors of pre-trained DBN4and random ly initialized DBN4,both of which have the same parameters.As shown in Fig.8,the DBN4w ith pre-training can make the fine-tuning faster than thatw ithout pre-training.A fter 100 iterations in the fine-tuning,the average squared reconstruction error per input vector of pre-trained DBN4is smaller than that ofrandom ly initialized DBN4,as shown in Fig.8.If the iteration number is greater than 450,the curve basically maintains stable.The difference of the average squared reconstruction error between the pre-trained and random ly initialized is about 4.36.The experimental results show that using pre-training and fine-tuning can improve the performance in IDS classification.
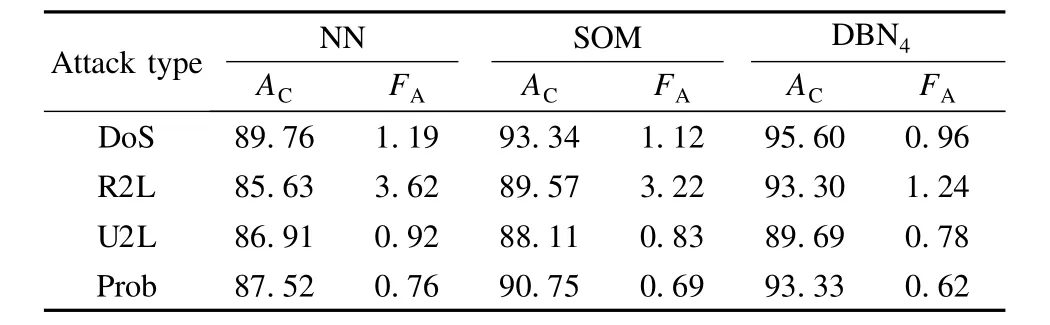
Tab.2 Performance comparison of three classifiers on different types of attacks%_
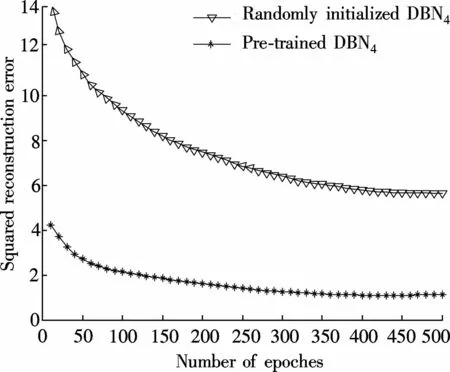
Fig.8 Comparison of the squared reconstruction error
Another challenge in the classification of huge amounts of data using the proposed model is the real-time analysis and processing of data in a short period of time.Therefore,the assessment of the proposed model is crucial.In order to increase the number of experimental data,duplicate records are random ly added to the KDD CUP 1999 dataset,and the running time of our computer using the DBN4model is recorded,as shown in Fig.9.The experimental results show that the running time approximately increases linearly as the number of records increases.
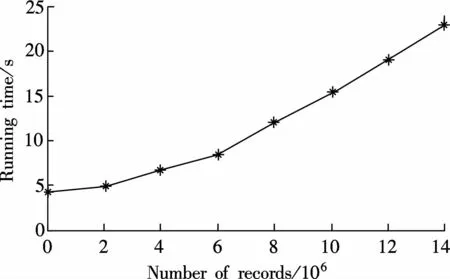
Fig.9 The scalability of DBN4
7 Conclusion
This paper aim s at demonstrating that DBN can be successfully applied in the field of intrusion detection.DBN can not only extract features from high-dimensional representations but also efficiently perform classification tasks.This paper explores the idea of applying DBN to classify attacks accurately.The performance of DBN is evaluated by experiments,and DBN is compared w ith othermachine learning models,such as SOM and NN.Finally,the experimental results on the KDD CUP 1999 dataset show that a good generative model can be acquired by DBN,which perform s well on the intrusion recognition task.To some extent,the DBN,which can replace the traditional shallow machine learning,provides a new design idea and method for future IDS research.
[1]Kuang F,Xu W,Zhang S.A novel hybrid KPCA and SVM w ith GA model for intrusion detection[J].Applied Soft Computing,2014,18(4):178- 184.
[2]Beqiri E.Neural networks for intrusion detection systems[J].Global Security Safety&Sustainability,2009,45:156- 165.
[3]Ahmad I,Abdullah A,Alghamdi A,etal.Optim ized intrusion detection mechanism using soft computing techniques[J].Telecommunication Systems,2013,52(4):2187- 2195.
[4]Depren O,Topallar M,Anarim E,et al.An intelligent intrusion detection system(IDS)for anomaly and m isuse detection in computer networks[J].Expert Systems with Applications,2005,29(4):713- 722.
[5]Bengio Y.Learning deep architectures for AI[J].Foundations and Trends in Machine Learning,2009,2(1):1 -127.
[6]Hinton G E,Osindero S,Teh YW.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527- 1554.
[7]Bengio Y,Lamblin P,Popovici D,et al.Greedy layerw ise training of deep networks[C]//Advances in Neural Information Processing Systems.Vancouver,Canada,2006:153- 160.
[8]Stolfo S J,Fan W,Lee W K,et al.Cost-based modeling for fraud and intrusion detection:results from the JAM project[EB/OL].(1999-10-28)[2011-06-27].http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.htm l.
[9]Rumelhart D E,Hinton G E,W illiams R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533- 536.
[10]Hinton G E.Training products of experts by m inim izing contrastive divergence[J].Neural Computation,2002,14(8):1771- 1800
[11]Larochelle H,Bengio Y,Louradour J,et al.Exploring strategies for training deep neural neural networks[J].Journal ofMachine Learning Research,2009,10(1):1-40.
基于深度信念网络的入侵检测模型
高 妮1高 岭1贺毅岳1,2高全力1任 杰1
(1西北大学信息科学与技术学院,西安710127)
(2西北大学经济管理学院,西安710127)
研究了入侵检测系统中海量数据分类的问题.讨论了深度信念网络(DBN)的原理,提出了基于DBN的入侵检测模型.DBN由多层无监督的限制玻尔兹曼机(RBM)网络和一层有监督的反向传播(BP)网络构成.该入侵检测模型采用一种快速、贪婪的方法对DBN网络进行预训练,利用对比分歧算法逐层训练每一个RBM网络;然后,利用有监督的BP算法对整个DBN网络进行微调,并同时对RBM网络输出的低维特征进行入侵数据分类.基于KDD CUP 1999数据集的实验结果表明,使用3层以上的DBN模型分类效果优于自组织映射和神经网络方法.因此,DBN是一种有效且适用于高维特征空间的入侵检测方法.
入侵检测;深度信念网络;限制玻尔兹曼机;深层学习
TP393.08
10.3969/j.issn.1003-7985.2015.03.007
2015-02-25.
Biographies:Gao Ni(1982—),female,graduate;Gao Ling(corresponding author),male,doctor,professor,gl@nwu.edu.cn.
s:The National Key Technology R&D Program during the 12th Five-Year Plan Period(No.2013BAK01B02),the National Natural Science Foundation of China(No.61373176),the Scientific Research Projects of Shaanxi Educational Comm ittee(No.14JK1693).
:Gao Ni,Gao Ling,He Yiyue,etal.Intrusion detectionmodel based on deep belief nets[J].Journal of Southeast University(English Edition),2015,31(3):339- 346.
10.3969/j.issn.1003-7985.2015.03.007
猜你喜欢
杂志排行

Journal of Southeast University(English Edition)的其它文章
- CoMP-transm ission-based energy-efficient scheme selection algorithm for LTE-A system s
- Detection optim ization for resonance region radar w ith densemulti-carrier waveform
- Dimensional emotion recognition in whispered speech signal based on cognitive performance evaluation
- Cascaded projection of Gaussian m ixturemodel for emotion recognition in speech and ECG signals
- Action recognition using a hierarchy of feature groups
- Ergodic capacity analysis for device-to-device communication underlaying cellular networks