基于K-means聚类的组合测试用例生成优化算法
2015-06-23王曙燕孙家泽
冯 霞, 王曙燕, 孙家泽
(西安邮电大学 计算机学院, 陕西 西安 710121)
基于K-means聚类的组合测试用例生成优化算法
冯 霞, 王曙燕, 孙家泽
(西安邮电大学 计算机学院, 陕西 西安 710121)
针对组合测试生成的测试用例在程序结构测试中出现冗余的问题,应用K-means聚类算法对基于蚁群算法生成的组合测试用例集进行聚类优化。以白盒测试中的逻辑覆盖为依据,将测试用例程序覆盖差异度作为分类的量化标准,根据测试代价决定聚类数目,在每个聚类簇中抽取处于中心点的测试用例构成新的集合。实验结果表明,该算法可以有效减小测试用例集的规模;对比分析不同覆盖准则,可找到在测试用例标准化过程中最优的逻辑覆盖方法。
K-means聚类算法;蚁群算法;组合测试;白盒测试
软件测试是保证软件可信度的重要手段,也是开发软件系统的基本环节。在测试过程中选择合适的用例驱动待测程序可以提高故障检测能力。组合测试是一种有效的测试用例生成技术,其充分考虑各个因素以及它们之间的相互作用对软件系统产生的影响,从统计学角度设计测试用例,能够在保证错误检出率的前提下采用较少的测试用例测试系统,力求用尽可能少的测试用例覆盖尽可能多的影响系统的参数。将智能算法运用到组合软件测试中以其进行优化,如粒子群算法[1]、模拟退火算法[2]和蚁群算法[3],可以有效降低软件测试费用,然而组合测试属于黑盒测试,所生成的测试用例在白盒测试中可能会出现冗余。Jangbok Kim等[4]将白盒测试与组合测试相结合,提出了针对完整系统的两两组合测试覆盖算法WBPairwise,但并没有考虑到在系统参数众多、测试用例数量十分庞大时如何进一步优化。
数据挖掘是处理大数据的有效途径,在软件测试中数据挖掘具有广阔的应用前景[5-6]。文献[7]提出通过凝聚层次聚类对用户交互测试用例进行优化,但因测试Web应用十分复杂,很难实际有效地得到应用。陈阳梅等[8]采用K中心点算法对测试用例进行约简,该方法采用K个中心点与非中心点的线性距离衡量各测试用例之间相异度,对于非数字形式的属性缺乏客观评价。本文根据白盒测试逻辑覆盖准则对判定路径进行标准化,找到各个测试用例所经过的路径差异,再运用K均值聚类算法对蚁群算法优化后的组合测试所得用例进行分类,根据实际需要抽取测试用例,并对用例进行优化。
1 组合测试模型
某待测软件系统(Software Under Testing,SUT)有n个参数,这些参数可以是外部输入、内部事件或者配置参数。对n个输入参数中任意t个参数的所有取值组合进行覆盖,称为覆盖强度为t的组合测试。当t=2时,称为两两组合测试[9]。在最终生成的测试用例集中,所有软件系统外部参数可能取值的两两组合至少覆盖一次。
假设有一个待测软件系统,该系统有4个参数,每个参数包含3个因子。如果采用穷举测试方式,需要34=81个测试用例才能覆盖所有的可能参数取值组合,而如果采用两两覆盖组合测试,只需要9个测试用例就可以实现两两覆盖,检测出大部分的软件错误[10]。
2 基于蚁群算法的组合测试
2.1 蚁群算法
蚁群算法是根据蚁群觅食活动规律建立的一个利用群体智能进行优化搜索的算法。蚁群算法包括两个阶段:适应阶段和协作阶段。算法本身是根据一定规则随机寻找最优解。
(1)刚开始蚂蚁随机选择路径,每条从出发节点到结束节点的路径都对应于一个解决方案,并且附有该路径的增益。
(2)当每只蚂蚁到达结束节点时,在路径的每条边上释放信息素,信息素的取值为信息素挥发与蚂蚁释放信息素的综合。
(3)蚂蚁在选择路径时按照概率去选择增益较大的边。某一路径经过的蚂蚁越多,后面的蚂蚁选择该路径的概率越大。
最终,所有蚂蚁会选择一条增益较大的路径,这是一个最优或接近最优的解。
2.2 基于蚁群算法的组合测试优化方法
将蚁群算法应用到组合测试中,采用one-test-at-a-time策略,以获得最高总增益(即最优测试质量)为目标生成测试用例。对每只蚂蚁选择的路径进行排序,将增益最大的作为当前最优解。蚁群算法具有一定的并行性,蚂蚁的搜索过程彼此独立,可以减少计算时间。此外,蚁群算法具有正反馈特性,通过判断路径信息素浓度选择较短路径。这样可以保证在较少的时间内生成有效的测试用例,减小测试用例集规模,降低测试成本。
假设某测试用例集有n个参数
F=(f1,f2,…,fn),
每个参数有m个属性
Vi=(Vi1,Vi2,…,Vim)。
每个属性对应有表示其重要程度的权值wim。
基于蚁群的组合测试用例生成算法[11]步骤如下。
步骤1 输入蚂蚁数、信息素矩阵,禁忌表置零。蚂蚁最初随机选择下一节点并将其记录到禁忌表中,修改所经过路径的信息素浓度。
步骤2 当蚂蚁选择节点不在禁忌表中时,该节点可以访问。依据转移概率式[12]
(1)
计算下一节点,其中h表示可访问节点,τij(t)表示t时刻边(i,j)的信息素浓度,ηij(t)表示边(i,j)相应的启发式的值。α和β分别反映了信息素浓度和启发式的影响程度。
步骤3 蚂蚁完成一次节点遍历后,根据蚂蚁选择的路径[12],按照
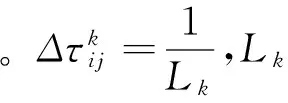
步骤4 所有蚂蚁巡回完毕后,对生成的候选解进行排序,依据最优解更新禁忌表。
步骤5 按步骤2至步骤4不断循环,直到所选择的路径获得最高增益。
3 基于K-means测试用例优化算法
3.1 K-means算法
K-means算法是数据挖掘中著名的划分聚类算法,它根据某一目标函数将给定的数据划分为k个簇,簇内对象相似,而与其他簇中的对象差异较大。K-means算法把簇内点的均值作为簇的中心。在聚类过程中先随机选择k个聚类中心,通过计算余下的点与中心点的欧式距离划分所有数据,之后不断迭代改变簇内的变差。分别求出各个簇上一次迭代后所生成聚类簇的均值作为新的聚类中心,重新对所有数据进行分类,直到分配的k个簇不再发生变化或满足迭代次数。
3.2 K-means测试用例优化技术
蚁群算法的组合测试用例生成技术虽然能够有效的减少测试用例,但其基本思想仍然是黑盒测试。黑盒测试没有清晰简明的规格,缺乏对程序结构的考虑。从白盒测试角度进行分析时,测试用例可能会出现冗余。在白盒测试中,逻辑覆盖包括语句覆盖、判断覆盖、条件覆盖、判断/条件覆盖、条件组合覆盖和路径覆盖。本文以6种覆盖方法为依据,结合覆盖方案的不同要求,对已经生成的测试用例进行聚类优化。
假设某待测系统有n个输入参数,每个参数有m个可选项。通过蚁群算法后可以生成Z个测试用例,每个测试用例都含有n个参数。现使用K-means聚类方法对Z个测试用例进行分类。由于测试用例集与一般的数据不同,它们没有固定的量化标准,因此测试用例聚类划分标准的选择尤为重要。对判定条件执行进行标准化记录,根据测试用例在程序运行时不同逻辑覆盖准则对判定条件执行结果的要求不同,将测试用例转化为由0-1表示的路径数组,0表示没有经过该路径,1表示经过该路径。转化后,Z个测试用例由Z个路径数组表示。
语句覆盖要求程序中每条语句至少被执行一次。判断覆盖要求每个判断至少取一次为真,取一次为假,即程序中每个if条件的分支至少要执行一次。条件覆盖要求判断中每个条件的每种可能性至少运行一遍,如果if条件中包含多个判断语句,每条语句为真为假的情况都应区分开,成为不同的划分路径。判断/条件覆盖满足了判断覆盖准则,同时也满足条件覆盖准则。条件组合覆盖要求判断中各条件结果可能性的组合至少出现一次。路径覆盖可以对程序进行彻底的测试,设计用例测试所有可能的判定路径。
以判断/条件覆盖为例,假设程序中有i个判断条件,每个条件有成立或者不成立两条路径,即每个测试用例有2i项。这样,每个测试用例所选择的判断路径都可以唯一表示。在进行聚类时,将每个测试用例与作为簇中心的测试用例相异或所求的选择路径差异程度D作为对测试用例进行分类的量化标准。当用例经过的路径相同或者相似时,参数D大小相近。在基于判断/条件的聚类分析中,D是有效的分类依据。实际软件测试过程中,可以依据测试的现实状况,如程序结构、时间紧迫性、规格要求等指定所需测试用例的个数k。依照K-means的一般算法将用例集划分为k类即可得到k个簇。在各个簇中进行抽样,得到约简后的测试用例集。算法的流程如图1所示。
第二,组织做好《条例》的宣传培训。按照干部职工牢固掌握、相关人员深入理解、社会公众了解支持的要求,在“六五”普法期间,深入开展《条例》的宣传。积极发挥新闻媒体、网络的作用,通过多种方式和途径在全流域广泛开展宣传活动,进一步增强全社会爱水、护水、节水意识和水法制观念,努力营造规模大、密度高、形式新的宣传氛围,确保广大干部群众深刻领会《条例》确立的基本原则、主要制度,准确把握《条例》的深刻内涵,增强贯彻实施的自觉性,保障《条例》的全面、顺利、有效实施,全面提升流域综合管理能力。

图1 K-means组合测试用例生成优化流程
4 仿真实验
4.1 实验设计
某文字处理软件为待测系统,该软件如表1所示,包含字体、字号、字体颜色、效果、字符间距、段落格式6个功能标签,每个标签包含10个选项,对于写入其中的文字可以进行设置。通过蚁群算法优化选项的组合进行测试,将6个功能标签作为旅行商问题中的城市节点,10个选项作为城市之间的不同路径。之后在程序中执行所得测试用例集,根据不同的逻辑覆盖准则进行通过路径的标准化,最后使用K-means聚类。观察所得测试用例集的特点,这样就可以验证所提出优化算法的有效性。
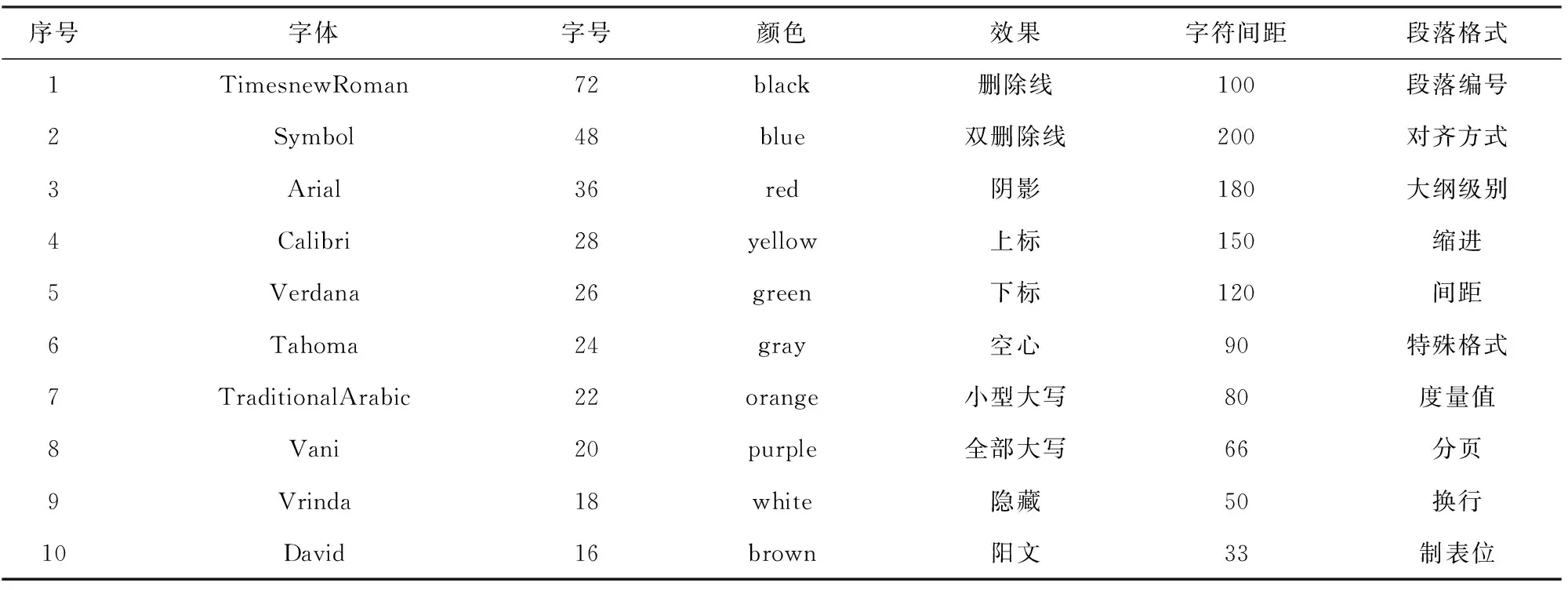
表1 待测软件系统
待测软件系统的程序伪代码为
If(commonly used typeface && textsize<50){
If(character scaling)
Then road1
If (warm color || good text effect){
Then road2
算法在eclipse编程环境下采用Java语言实现。其中蚁群算法涉及到的参数为:迭代次数150,蚂蚁20只,α=1,β=3,信息素挥发速率ρ=0.6,系统初始信息素浓度为0.5。对软件系统进行回归测试时,根据时间紧迫程度以及实际任务需要,将测试用例聚集为4类。所以K-means得到的最终用例个数为4。
4.2 实验结果分析
实验中首先使用微软公司的配对测试工具PICT对于系统6个参数进行两两配对组合测试,生成测试用例173个;其次使用经过蚁群算法优化后的组合测试用例生成方法生成73个测试用例;最后在第二项基础上,采用基于K-means的测试用例优化算法生成4个测试用例,通过聚类选择出最佳测试用例,明显减小了测试用例集。图2为使用Weka数据挖掘软件对本文提出的聚类算法进行仿真,经过多次迭代后所生成的4个聚类簇的分布状况。
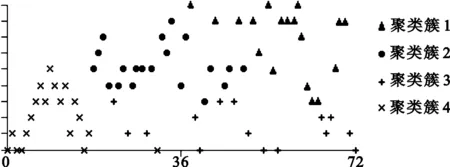
图2 聚类结果
根据逻辑覆盖中不同的覆盖准则对基于蚁群算法的组合测试进行标准化后,使用K-means对测试用例进行分类,4类的聚类情况如表2所示。表中的判定路径表示,测试用例标准化时,由于覆盖准则的要求不同,程序执行的判定结构也不同。聚类簇1、聚类簇2、聚类簇3和聚类簇4为K-means聚类后生成的4个簇。6种逻辑覆盖准则发现错误的能力由弱至强变化,判定路径越来越多,覆盖范围越来越全面。在语句覆盖和判定覆盖中,各测试用例的可选路径较少,路径差异小,所以聚类后测试用例分布不平衡,出现第四类用例个数为0,语句覆盖中第一类占比63%,判定覆盖中第二类占比56.2%的情形。随着条件覆盖、判断/条件覆盖、条件组合覆盖、路径覆盖或者判定路径逐渐增多,测试用例间的路径差异会越来越大,故在使用K-means进行划分时,簇间差异会加大。路径覆盖对于程序结构的检测最为全面,判定路径也最多,经过多次聚类迭代后,4个簇中测试用例的数目接近25%,测试用例划分均匀,聚类效果最好。

表2 K-means具体聚类情况分析
通过实验仿真,可以观察到测试用例标准化时,采用路径覆盖准则对于用例间差异路径的区别最为详尽。在此基础上使用K-means聚类,可以克服组合测试所生成的测试用例在白盒测试方面出现的冗余。
5 结束语
将数据挖掘中K-means聚类算法与蚁群算法优化后的两两组合测试用例生成技术相结合,提出了一种新的组合测试用例约简算法。该算法采用白盒测试中逻辑覆盖方法对测试用例进行数据挖掘标准化,并在6种覆盖方法中找到路径覆盖作为最优方案。实验结果证实了该优化算法的灵活性和有效性,可以依据测试需求决定测试用例个数,通过聚类选择最优测试用例,在保证所得软件增益的情况下,去除程序结构测试中冗余的测试用例,从而降低了测试成本。
[1] 潘烁, 王曙燕, 孙家泽. 基于K-均值聚类粒子群优化算法的组合测试数据生成[J]. 计算机应用, 2012, 32(4): 1165-1167.
[2] 王博, 王曙燕. 一种新的基于模拟退火的测试用例生成与约简算法[J]. 计算机应用与软件, 2013, 30(2): 78-81.
[3] Liu Dan, Wang Jianmin, Zheng Lijuan. Automatic test paper generation based on ant colony algorithm[J]. Journal of Software, 2013, 8(10): 2600-2606.
[4] Kim J, Choi K, Hoffman D. White box pairwise test case generation[C]//Seventh International Conference on QualitySoftware. Piscataway: IEEE Press, 2007: 286-291.
[5] Ilkhani A, Abaee G. Extracting test case by using data mining; reducing the cost of testing[C]//2010 International Conference on Computer Information Systems and Industrial Management Applications (CISIM). Krackow: IEEE Press, 2010: 620-625.
[6] Zeng Fanping, Li Ling, Li Juan. Research on test suite reduction using attribute relevance analysis[C]//Eigth IEEE/ACIS International Conference on Computer and Information Science. Shanghai: IEEE Press, 2009: 961-966.
[7] Liu Yue, Wang Kang, Wei Wang. User-session-based test cases optimization method based on agglutinate hierarchy clustering[C]//2011 IEEE International Conferences on Internet of Things, and Cyber, Physical and Social Computing. Dalian: IEEE Press, 2011: 413-418.
[8] 陈阳梅, 丁晓明. 一种基于K中心点算法的测试用例集约简方法[J]. 计算机科学, 2012, 39(6A): 422-424.
[9] 孙家泽.程序不变量驱动的组合测试用例约简方法[J].西安邮电学院学报, 2012, 17(2):71-74.
[10] 严俊, 张健. 组合测试: 原理与方法[J]. 软件学报, 2009, 20(6): 1393-1405.
[11] 张驰, 王曙燕, 孙家泽. 基于序优化蚁群算法的成对交互测试用例集生成[J]. 计算机应用与软件, 2013, 30(1): 71-74.
[12] Liu Weimin, Li Sujian, Zhao Fanggeng. An ant colony optimization algorithm for the multiple traveling salesmen problem[C]//ICIEA 2009.4th IEEE Conference on Industrial Electronics and Applications. Xi’an: IEEE Press, 2009: 1533-1537.
[责任编辑:祝剑]
Combinatorial test case optimization based on K-means clustering
FENG Xia, WANG Shuyan, SUN Jiaze
(School of Computer Science and Technology, Xi’an University of Posts and Telecommunications, Xi’an 710121, China)
To eliminate test suite redundancy of combinatorial testing in white-box testing,optimized pairwise test suites are generated based on K-means algorithm merging with ant colony algorithm. While building test suites,the logic coverage strategy in white-box testing is adopted. The difference of program coverage is used as quantitative criteria to classify test cases. The clustering number is decided by test cost. A new test suite is built through clustering system choosing data at clusters’ center. Simulation experiments show that this method reduces the size of test set effectively. Moreover, this paper presents a method of test standardization by applying different coverage criteria, and thus provides a better solution for test suite data mining technology.
K-means clustering algorithm, ant colony algorithm, combinatorial testing, white-box testing
2014-09-01
国家自然科学基金资助项目(61050003);西安邮电大学青年教师科研基金资助项目(ZL2013-26)
冯霞(1989-),女,硕士研究生,研究方向软件测试、数据挖掘。E-mail:fengxia166@sina.com 王曙燕(1964-),女,博士,教授,从事软件测试、数据挖掘、智能信息处理研究。E-mail:wsylxj@126.com
10.13682/j.issn.2095-6533.2015.01.009
TP301
A
2095-6533(2015)01-0044-05
