基于GPU的目标识别算法的并行化研究
2015-06-23刘宝平陈庆奎李金静刘伯成
刘宝平,陈庆奎,,李金静,刘伯成
(上海理工大学 a.光电信息与计算机工程学院;b.上海理工大学 管理学院,上海 200093)
基于GPU的目标识别算法的并行化研究
刘宝平a,陈庆奎a,b,李金静a,刘伯成b
(上海理工大学 a.光电信息与计算机工程学院;b.上海理工大学 管理学院,上海 200093)
针对可变形部件模型算法(DPM)的计算量大,无法完成实时检测等问题,通过GPU编程模型CUDA,在Nvidia GPU上实现了HOG算法和DPM算法的并行化;采用OpenCL编程模型实现了DPM算法在集成显卡上的并行化。通过CPU和GPU的协同计算,保证目标识别效果的前提下,并行化的算法的执行效率相比于OpenCV中的CPU或GPU实现有明显的提高;通过对目标识别算法的并行化,结合其他算法,使得这类复杂算法能够在一些需要实时监测的工程领域中得到应用。
梯度方向直方图;可变形部件模型;图形处理器;协同计算;统一计算设备架构;开放运算语言
目前,在汽车自动驾驶、智能交通、智能监控安防等领域中,人工智能正在发挥越来越重要的作用,人工智能的应用也使得人们从机械的简单而重复的工作中解放出来,但是这也就要求这类人工智能算法有更加精确的效果和实时的监测,对算法提出了更高的要求。传统的算法都是基于CPU串行实现的,由于算法的计算量大,因此CPU无法完成对算法的实时计算。在这些领域中,对算法的并行化就是一个非常的需求,通过并行化算法使得算法的执行效率相比于CPU得到数十倍的提高,从而实现算法的实时性计算。
笔者将重点介绍两种目标识别算法,梯度方向直方图算法[1](HOG,histogram of oriented gradient)和可变形部件模型算法[2](DPM,deformable part model)。HOG算法是一个广泛应用在计算机视觉和图像处理中的目标检测的特征描述子,而DPM算法是一个从HOG算法演化而来的一个检测精度非常高的算法,相比于HOG算法,DPM算法增加了根和部件的思想。对一个目标的描述由之前的单一模板改为根和部件来对目标进行描述,在目标检测和人脸识别等方面都有很好的应用,但是这些算法都有计算量非常大,无法完成实时性处理的缺点。正是在这种对算法进行加速的需求下,笔者采用并行化编程模型CUDA和OpenCL,重新设计算法的并行化实现方案,采用CUDA编程模型对HOG和DPM算法在Nvidia GPU上实现了并行化,同时采用OpenCL编程模型对DPM算法在intel 集成显卡上完成了实现和测试,提高算法的执行效率,使得这两个目标算法应用在实时性环境成为可能,以后DPM算法也将应用在更多的领域之中。
1 相关工作
目标检测一直是计算机视觉领域中的难题,对于条形码等刚性目标,一些简单算法可能会取得比较好的检测效果,但是对于人体这种易发生形变和部分遮挡的目标,检测起来难度要更大。在2005年的CVPR会议上,Dalal和Triggs[1]两位科学家提出了梯度方向直方图 (HOG)的特征描述子,在进行目标检测和分类过程中,采用基于HOG特征的单一模板来表示目标。HOG算法是一个早期的目标检测算法,HOG+SVM在刚性目标检测中会取得比较好的检测效果,但是对于人体等非刚性目标的检测效果一般。
2010年,Felzenszwalb et al[2]提出了基于HOG的改进算法可变形部件模型算法,在HOG算法的原理基础上,设计了检测更为精确的可变形部件模型算法。DPM算法使用根和n个部件来描述目标的结构,通过根来描述目标的整体轮廓,通过n个部件来描述目标的各个组成部分,对于人体这种容易发生形变的目标,根和部件的设计方案使得目标检测更加准确。
2012年,在欧洲计算机视觉会议(ECCV)上,来自美国伯克利大学的团队,提出一种稀疏模型[3],再结合GPU加速,使DPM算法的执行效率显著提高,达到实时性要求。2014年,来自法国的一个实验室团队,发表了一篇关于DPM算法的并行化[4]实现,他们基于CUDA实现了DPM算法的并行化,文中详细介绍了DPM算法的GPU实现细节,并测试了最终的加速效果。
通过分析算法的实现,结合其他研究成果[5-9],通过CUDA和OpenCL编程模型实现了算法的GPU移植,并训练不同目标的分类器,实现多目标分类。将以HOG算法为出发点,重点介绍 DPM算法的GPU并行化实现方案,提高算法的执行效率,使得DPM算法在人体检测以及人脸检测[10]等计算机视觉领域能够得到更加广泛的应用。
2 HOG算法概述
通过分析HOG算法实现细节,发现HOG算法特别适合并行化处理,下面将简单介绍HOG算法的并行化实现过程。
2.1 图像Gamma校正
通过对输入图像进行标准化,降低由于局部阴影和光照的剧烈变化所造成的影响,同时可以移植噪声的干扰。对于RGB图像需要对三通道都做Gamma校正,而灰度图则只需要对灰度值Gamma校正。Gamma校正公式为,
I(x,y)=I(x,y)g.
(1)
式中,指数g值取0.5。
显而易见,Gamma校正时各个像素点之间没有任何逻辑相关,我们为每个像素点分配一个线程进行计算,这样大大提高了计算效率。
2.2 计算图像梯度
计算图像中像素值在横纵坐标方向上的梯度,每个像素点算出一个梯度幅值和方向。
Gx(x,y)=H(x+1,y)-H(x-1,y) ;
(2)
Gy(x,y)=H(x,y+1)-H(x,y-1) .
(3)
式中:Gx(x,y),Gy(x,y)为图像像素点(x,y)处的水平和垂直梯度;H(x,y)表示该点的像素值,则像素点(x,y)处的梯度幅值G(x,y)和梯度方向α(x,y)如下
(4)

(5)
对于灰度图像来说,只需要计算出一通道灰度值。如果在RGB彩色图像上进行计算,则需要我们对RGB三通道分别算出梯度幅值和方向,然后选择幅值较大的一个通道,作为该像素点(x,y)的梯度幅值和方向。
从算法实现来看,每个像素点计算梯度都是独立进行的,不同像素点之间不会有任何逻辑关联,所以在并行化的时候,我们依然是为每个像素点分配一个线程,每个线程计算对应像素点的梯度。
2.3 计算细胞单元cell梯度方向直方图
通过已得到的每个像素点的梯度幅值和方向,定义了每8×8个像素点为一个cell,这样便可以将图像表示为由一个个cell组成。我们为每个cell定义了一个9个bin的直方图来统计当前cell的梯度方向分布信息。所有像素点的方向范围为0°~360°,我们需要其转换为0°~180°,每20°一个bin,我们要将其投票到9个bin中,当前cell中每个像素点都对自己对应的梯度方向直方图中进行加权投影,我们就得到了当前cell的梯度方向直方图,每个cell都对应一个9维的特征向量。
上面只是最简单的获得梯度方向直方图的方式,在各种HOG算法的改进中,关于如何进行投票,方法有很多。比如,在可变形部件模型算法中,一个像素点将根据规则算出4个像素点的坐标,然后将这4个像素点的坐标算出权重,根据权重加权投票到当前像素点所在的cell的梯度方向直方图中,根据0°~360°和0°~180°,分别算出一个对比度敏感18维梯度方向直方图和对比度不敏感的9维梯度方向直方图,对两种梯度方向直方图分别进行归一化,然后再进行组合,加入归一化因子,得到最终当前cell的梯度方向直方图。而且DPM算法中有应用到PCA主成分分析算法进行特征向量的将维,使得整个算法的计算量有明显的降低。
本文依然为每个像素点分配一个线程,在HOG算法的GPU实现中,我们分配8×8的线程块来处理8×8的cell单元,但是在投票的时候,8×8个线程同时往9维的梯度方向直方图中进行投票,这样线程之间就会产生冲突,采用原子操作进行显存读写,这样保证了数据的正确性。但是在DPM算法的GPU实现时,分别采用了折半规约和原子操作的两种方式进行投票,折半规约就是每个像素点都分配一个梯度方向直方图,然后将cell内所有像素点的梯度方向直方图通过折半规约的方式进行整合,最终得到整个cell的梯度方向直方图。而原子操作就更加容易理解,就是当前block内的所有线程通过计算对应像素点的梯度,然后采用原子操作将每个线程的结果累加到当前cell所对应的直方图中。
2.4 块(block)内直方图归一化
上面我们得到了组成图像的所有cell的梯度方向直方图,为了进一步弱化光照,阴影,噪声等一系列因素的影响,我们将对特征向量进行归一化操作。我们将各个cell单元组合成更大的组成单元block,我们定义每2×2个cell组成一个block。这样,block的HOG特征就是组成该block的4个cell的梯度方向直方图串联起来,每个block将得到一个36维的梯度方向直方图。
将归一化block内的HOG特征向量,比较常用的归一化函数:
ε表示一个很小的常量,防止分母为0;
2) L2-Hys,方法同式(1),增加截断操作,将v的最大值限制为0.2,再次重新归一化。
一般采取第二种归一化方法,这只是HOG算法中比较常用的归一化函数的计算过程。在改进的HOG算法中,也有很多其他的归一化因子的计算,比如可变形部件模型算法中,根据当前cell位置算出4个cell,然后将4个cell的block能量算出来以后,作为归一化因子对特征向量进行归一化,而且是算出4个归一化因子,分别对对比度敏感的18维梯度方向直方图和对比度不敏感的9维梯度方向直方图进行归一化操作,进行4次归一化操作,最终得到一个31维的梯度方向直方图,也就是当前cell对应的最终的HOG特征向量。
并行化设计实现时,线程分配其实有很多种实现方法,本文的实现大概过程是为每一个特征向量中的每一维度计算都分配一个线程,可以采用折半规约的方式算出每个block的归一化因子,然后采用上面的一种归一化函数,进行归一化操作。当然,也可以采用为每个block的特征向量的归一化操作分配一个线程,然后用该线程循环处理特征向量中的每一个维度。
2.5 窗口HOG特征值
完成block内的特征向量的归一化操作之后,我们需要进一步得到检测窗口的HOG特征值,这个特征值是我们最终用来进行SVM分类的特征值。同理,对于opencv中的是实现的HOG算法,其检测窗口有48×96和64×128两种,cell由8×8个像素点组成,block有2×2个cell组成,那么64×128的检测窗口由7×15个block组成,所以64×128对应的窗口特征值为3 780维特征向量。同理可以得到,48×96对应1 980维的窗口特征向量。
2.6 SVM分类和非最大值抑制
利用HOG+SVM进行目标检测时,计算出每个窗口的特征值之后,然后将计算出的窗口特征值和事先训练好的SVM分类器进行计算判别。最基本的线性判别函数
w·x+b=0 .
(6)
式中:w为窗口HOG特征值;x是训练好的分类器,两个向量做点积计算,最后加上一个偏移量得到一个窗口分数,根据分数得到最终的判别结果。特征向量和分类器进行点积计算时,本文依然采用折半规约的方式进行计算。
关于窗口的非最大值抑制,由于是在多尺度上所有位置处进行目标检测,所以在同一尺度的相邻位置和不同尺度的相邻位置可能会多次检测出同一个目标,这样会导致窗口重叠,本文采用非最大值抑制算法来去除多余窗口。将不同尺度上的窗口都还原到原图像中,如果窗口重叠面积大于某一个阈值,就会比较两个窗口的分数值,留下较大一个窗口的分数值。
3 可变形部件模型算法
3.1 可变形模型算法的概述
可变形部件模型算法是HOG算法的改进,也是基于HOG特征值进行目标检测,但是DPM算法增加了根和部件的思想,DPM算法用根和n个部件来描述一个目标。DPM算法的前几步的算法实现原理和上面介绍的原理一致,但是由于增加了根和部件的思想,所以在计算检测窗口的得分时,就等于该窗口中根得分加上n个部件得分,由于部件捕捉更加精细的目标特征,所以部件所在图像金字塔中的分辨率是根所在层分辨率的二倍。计算部件得分时,由于考虑到目标可能会发生形变,所以我们需要在部件锚点附近一定范围内开始搜索,找到部件的实际位置,然后根据偏离锚点的位置进行部件惩罚,实际得分减去偏移惩罚得到部件在实际位置的最终得分,最后加上一维的偏移量。
下面公式表示了检测窗口的得分:
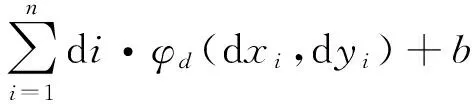
(7)
式中:H表示特征金字塔;p代表金字塔中某一层中坐标为(xi,yi)处的窗口特征值,第一部分表示根和部件的得分加起来,第二部分表示所有部件的偏移惩罚,其中(dxi,dyi)表示第i个部件的形变偏移,(dxi,dyi)=(xi,yi)-(2(x0,y0)+vi),(xi,yi)表示进行部件搜索时的实际位置,(x0,y0)表示根的位置,由于部件滤波器所在层的特征分辨率是根滤波器所在层的特征分辨率的2倍,所以2(x0,y0)+vi就是部件的锚点位置,di表示惩罚系数。第三部分b表示最终分数偏移。
3.2 可变形部件模型的并行化实现
可变形模型算法,采用GPU编程模型CUDA和OpenCL,设计了DPM算法的并行化解决方案。
由于DPM算法是基于HOG算法的改进,并且增加了根和部件的链接,本文在设计DPM算法的GPU移植的实现方案时,根据GPU架构的特点,通过合理的内存使用和线程分配,通过CPU端的循环控制,调用GPU的执行核函数,建立图像金字塔,然后再算出特征金字塔,通过根和部件滤波器将图像金字塔中所有尺度上所有位置的分数都算出来,最后通过距离转换,将根和部件链接起来,得到整个窗口的检测得分。GPU端完成计算之后,我们将合并冗余窗口的处理转移到CPU端进行处理,因为合并冗余窗体逻辑性较强,不适合GPU端进行处理,通过这种CPU和GPU的协同计算,最大限度的提高处理效率。
3.3 距离转换两种并行化实现中的协同计算
下面我们将重点介绍DPM算法中的距离转换部分的GPU实现,分析两种实现中GPU流处理器之间的协同计算,比较两种并行化设计方案的效率。
前面我们已经分析了,DPM算法中由一个根和n个部件来表示一个目标的组成。我们如何设计方案将根和部件链接起来呢?下面是采用OpenCL在intel集成显卡上实现的两种解决方案。
一种方案是我们为每个根的链接分配n个线程,这样每个线程负责处理一个部件,最终根得分和n个部件的实际得分相加,得到整个目标窗口的得分。以n值取8为例,这样我们就只能在一个线程块分配8,对于每个检测窗口,通过线程块中8个线程的协同处理,同步操作之后,8个线程的将负责的部件的得分进行汇总,这样就得到该检测窗口的整体得分。这种设计中,虽然每个检测窗口的部件是并行处理的,但是每个线程块中却只能分配少量线程。
另一种方案中,我们让每个线程负责更多的工作,即每个线程负责检测窗口中的根和n个部件的处理,我们为每个检测窗口的根和部件的链接计算分配一个线程,也就是一个线程负责根和n个部件的链接,同时由于考虑的部件的可变形性,所以每个线程在计算时,需要在部件的锚点附近进行搜索部件的实际位置。这样,由于每个线程都是负责一个窗口的计算,每个线程的计算量将变得非常大,但是线程块中却可以分配尽量多的线程。同时我们通过优化内存的使用,减少对全局内存的访问,使得代码的执行时间成倍的降低,最终使得这部分的计算时间完全满足了要求。
在前期距离转换部分测试中,第一种解决方案,虽然为每个部件的处理都分配一个线程,但是由于这种方案设计导致线程块中所能分配的线程数量极少,这种设计的执行时间要1 200ms。第二种解决方案中,虽然每个线程负责处理n个部件,但是这种设计,线程块中可以分配尽可能多的线程,使得算法更高效执行,这种设计方案的执行时间大概为300ms。
在可变形部件算法的GPU实现中,我们通过GPU的众多流处理器的协同处理,并行化实现了梯度方向直方图计算,归一化,根和部件的链接等一系列操作,并最终由CPU完成了冗余窗口的合并,发挥了GPU和CPU各自的优势,通过CPU和GPU的协同和GPU内部多处理器的协同计算,完成了DPM算法的设计实现,使得算法的执行效率成倍提高。
4 实验结果分析对比
4.1 实验环境及内容概述
实验环境:CPU:IntelCore(TM)2DuoCPUE8400,GPU:NvidiaGeForceGTX670,内存:2GB.
本文测试的主要内容是:
1) 对比OpenCV中的基于GPU实现的HOG算法和通过CUDA实现的HOG算法,本文将 对比两者的检测效果和执行时间;
2) 对比HOG算法和DPM检测效果对比;
3) 对比基于CUDA和OpenCL实现的DPM算法的执行效率。
4.2 HOG算法的检测效果及加速效果对比
4.2.1 两种实现的检测效果对比
OpenCV库中实现的HOG算法检测效果如图1所示。CUDA实现的HOG算法的检测效果如图2所示。

图1 OpenCV中HOG算法检测

图2 CUDA实现的HOG算法检测
通过图1和图2的检测效果我们发现,两种是实现的检测效果已经比较接近。
4.2.2 两种实现的执行效率对比
OpenCV库GPU实现和我们通过CUDA实现的加速效果对比,如表1所示。

表1 两种实现的运行时间对比
4.3 HOG算法的检测效果和DPM算法检测效果对比

图3 OpenCV中HOG算法检测

图4 CUDA实现的HOG算法

图5 OpenCL实现的DPM算法
OpenCV库函数检测效果如图3所示;CUDA实现的HOG算法的检测效果如图4所示;OpenCL实现的DPM算法的检测效果如图5所示。从上面给出的HOG算法和DPM算法的检测效果中可以明显看出HOG算法和DPM算法应用在人体检测中检测精度的巨大差异,在人体等非刚性目标的检测中,DPM算法的检测精度远远要高于DPM算法的检测精度。
4.4 基于集成显卡和独立显卡的DPM算法执行效率对比
一般印象中,独立显卡的计算资源远大于集成显卡,所以采用基于独立显卡的优化肯定会明显的强于基于集成显卡的实现,因为显卡的计算资源是一定的,而编程模型只是一种调用显卡资源的手段,无论采用何种编程模型,最终算法的执行效率还是由并行化实现方案和显卡的资源所决定。所以,本文将通过实验来测试集成显卡和独立显卡的各自优势。现在本文就将依照DPM算法在Nvidia独立显卡上和intel集成显卡上的执行效率做个对比。
基于intel集成显卡的测试环境,测试设备使用intelCorei5-4460CPU,内存4GB,显卡采用intel集成显卡HDGraphics4600。
基于Nvidia独立显卡的测试环境,本文采用intelCorei7-3930KCPU,内存32GB,显卡采用NvidiaGTX670独立显卡。
将对比采用DPM算法在intel集成显卡和在Nvidia独立显卡上对于不同尺寸的图片的检测时间。

表2 DPM算法在集成显卡和独立显卡的测试
通过对DPM算法在intel集成显卡和Nvidia独立显卡上的执行情况分析,虽然采用了不同的编程模型,但是编程模型只是对资源的调度方式不同,而显卡的资源是一定的。我们对不同显卡的设计方案也根据显卡的特点进行了调整,从上面的实验结果可以看到,集成显卡也并没有想象中的那么弱,而且我们也从实际中得到,intel集成显卡对于逻辑操作明显要好于Nvidia独立显卡,由于算法的某些需要,我们在核函数中加入循环时,可以看到集成显卡对这类操作的支持性明显优于独立显卡。但是由于独立显卡有绝对数量优势的流处理器,所以集成显卡在流处理器的数量上处于绝对劣势,导致集成显卡的计算性能明显要比独立显卡低。
5 结论
以HOG算法为出发点,引出了更为优秀的DPM算法,通过对DPM算法的详细分析,本文重新采用CUDA和OpenCL两种GPU编程模型分别在intel集成显卡和Nvidia独立显卡上重新设计实现算法的并行化解决方案,使得HOG算法相比于OpenCV库中的GPU实现有了明显提高,同时使得DPM算法的执行效率相比于OpenCV库中的DPM算法的实现有了近10倍的提高,并且比较了两种不同的DPM算法实现,同时也分析了集成显卡和独立显卡的计算性能。通过DPM算法的并行化,可以结合其他算法,将DPM算法应用在某些特定场合进行实时性检测,比如通过某些提取前景算法得到运动区域,然后对得到的运动区域进行目标识别。同时,我们希望能够将GPU用在深度学习上,使得GPU能够应用到更加多的领域中,发挥GPU的并行计算优势,在更多领域中发挥更重要的作用。
[1]DalalN,TriggsB.Histogramsoforientedgradientsforhumandetection[C]∥CordeliaS,StefanoS,GarloT.ProceedingofConferenceonComputerVisionandPatternRecognition.CA:SanDiego.,2005(1):886-893.
[2]FelzenszwalbPF,GirshickRB,McAllesterD,etal.Objectdetectionwithdiscriminativelytrainedpart-basedmodels[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2010,32(9):1627-1645.
[3]SongHO,ZicklerS,AlthoffT,etal.Sparseletmodelsforefficientmulticlassobjectdetection[J].SpringerBerlinHeidelberg,2012:802-815.
[4]GadeskiE,FardHO,LeBorgneH.GPUdeformablepartmodelforobjectrecognition[J].JournalofReal-TimeImageProcessing,2014:1-13.
[5]ChenYanping,LiShaozi,LinXianming.FasthogfeaturecomputationbasedonCUDA[C]∥IEEE.ProceedingofComputerScienceandAutomationEngineering(CSAE).China:Shanghai,2011,4:748-751.
[6]PedersoliM,VedaldiA,GonzalezJ,etal.Acoarse-to-fineapproachforfastdeformableobjectdetection[J].PatternRecognition,2014:1353-1360.
[7]HirabayashiM,KatoS,EdahiroM,etal.GPUimplementationsofobjectdetectionusingHOGfeaturesanddeformablemodels[C]∥IEEE.ProceedingofCyber-PhysicalSystems,Networks,andApplications(CPSNA).Taiwan,2013:106-111.
[8]AmitY,KongA.Graphicaltemplatesformodelregistration[J].PatternAnalysisandMachineIntelligence,IEEETransactionson,1996,18(3):225-236.
[9] 熊聪,王文武.基于DPM模型的行人检测技术的研究[J].电子设计工程,2014(23):172-173.
[10] 尹雪聪.基于可变形部件模型的人脸检测方法研[D].西安:西安电子科技大学,2012.
(编辑:朱 倩)
Parallelization of Target Recognition Algorithms Based on GPU
LIU Baopinga,CHEN Qingkuia,b,LI Jinjinga,LIU Bochengb
(a.CollegeofOptical-ElectricalandComputerEngineering;b.CollegeofManagement,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)
Aiming at the disadvantage of large amount of calculation,the parallel solution methods of deformable part model(DPM) algorithm and Histogram of Oriented Gradient(HOG) algorithm based on GPU were proposed base on GPU with CUDA,and the parallel solution method of DPM algorithm was also proposed based on integrated graphics card with OpenCL.With the cooperative computation of GPU and CPU,under the premise of ensuring the target recognition effect,the execution efficiency of the parallel algorithms was significantly improved compared with the GPU or CPU implementations in OpenCV.Through the parallel implementations of target detection algorithms,and combination with other algorithms,the target recognition algorithms can be applied in some engineering fields that need to be monitored in real time.
Histogram of oriented gradient; Deformable part model; GPU; Collaboration computing; CUDA;OpenCL
1007-9432(2015)06-0713-06
2015-05-23
国家自然科学基金资助项目:面向实时并发数据流的能耗优化的GPU集群可靠处理机制研究(61572325),高等学校博士学科点专项科研博导基金资助(20113120110008),上海重点科技攻关项目资助(14511107902),上海市工程中心建设项目资助(GCZX14014),上海智能家居大规模物联共性技术工程中心项目资助(GCZX14014),上海市一流学科建设项目资助(XTKX2012),沪江基金研究基地专项资助(C14001)
刘宝平(1990-),男,山东临沂人,硕士生,主要从事模式识别、计算机视觉与并行计算的研究,(E-mail)1262782363@qq.com
陈庆奎,男,教授,博士生导师,中国计算机学会(CCF)会员,(E-mail)chenqingk@tom.com
TP 301
A
10.16355/j.cnki.issn1007-9432tyut.2015.06.015
