一种快速频繁模式挖掘算法
2015-06-23石杰
石 杰
(1.山东青年政治学院实验设备管理处,山东济南250103;2.山东省高校信息安全与智能控制重点实验室,山东济南250103)
一种快速频繁模式挖掘算法
石 杰1,2
(1.山东青年政治学院实验设备管理处,山东济南250103;2.山东省高校信息安全与智能控制重点实验室,山东济南250103)
频繁模式挖掘是数据挖掘领域中一个重要的研究方向,目前已有很多算法被用于挖掘频繁模式.本文在研究FP-growth算法的基础上,提出一种新的频繁模式挖掘算法——QFP算法.首先对每一个频繁项建立一棵QFP树,进而根据设定的条件对每棵树进行挖掘,直到找出符合条件的频繁模式.实验证明该算法能够减少条件子树的生成数量,降低对内存空间的依赖和CPU的计算时间,从而提高关联规则挖掘的效率.
数据挖掘;频繁模式;项集
数据挖掘一直是数据库技术中一个活跃的研究领域.随着存储设备成本的降低和压缩技术的不断进步,使得每一个事务都可以存储到事务数据库中成为可能.这种存储解决了2个问题:第1,可以随意访问数据;第2,这些数据可以有助于发现数据项之间的关系.发现不同数据项之间存在的关联,以帮助提高收益,优化存储.Agrawal等[1]提出的Apriori算法就是第1个被用于发现不同数据项之间是否存在关联的算法.
一般来说,从数据中可以挖掘出许多种类的模式.例如,可以从市场购物篮分析中挖掘出关联规则,分类可以发现的分类规则,聚类和异常值可以定义客户关系管理.频繁模式挖掘是数据挖掘研究中一个重要方向,它适用于多种类型的数据库,如时间序列数据库[2]、事务数据库[3]、数据流数据库[4],在许多数据挖掘任务中发挥了重要作用,如挖掘关联规则、关联、因果关系、序列模式、多维模式,显露模式.
1 相关知识
1.1 FP-growth算法
频繁模式增长(FP-growth)算法,由Han等[5]提出,该算法采用分治策略[6],在发现频繁模式时不需要产生候选集的一种挖掘关联规则的算法.第1步,扫描数据库一遍得到各项目的频度,根据minsup得到频繁项目;对频繁项目按其频度由大到小排列(次序记为R),并形成头表.第2步,再次扫描数据库,对每一条交易中的所有频繁项目,按次序R组成相应的项目集并插入到FP树中.对每一频繁项目对应的条件FP树进行挖掘获得所有的频繁项目集.FP树中除了根节点,每一个节点包含了项的名称,支持度,一个指向链接在树中具有相同名称的节点[7],这些节点被用于创造FP树.
procedure FP-growth(Tree,α)
(1)if Tree含单个路径P then
(2)for路径P中结点的每个组合(记作β)
(3)产生模式β∪α,其支持度support=β中结点的最小支持度;
(4)else for each ai在Tree的头部{
(5)产生一个模式β=ai∪α,其支持度support =ai.support;
(6)构造β的条件模式基,然后构造β的条件FP树Treeβ;
(7)if Tree β≠ø then
(8)调用FP-growth(Tree β,β);}
2 数据存储结构与QFP算法
2.1 数据存储结构
关系数据库以二维表的形式存储数据,在数据库中事务以这种方式存储对于决定关联规则挖掘算法效率的高低起着重要的作用.大多数现代关系数据库都是事务型数据库.一个数据库的布局方式能够描述数据的表示方法.目前有2种常用的布局方式,水平布局方式[8,10-11]垂直布局方式[9-10],如垂直位图表示法[12]、倒排矩阵表示法[13].水平布局方式应用较多,垂直布局方式应用较少[14].
2.2 QFP算法
FP-growth算法的执行过程中需要重复递归地生成条件FP子树,这对空间的要求非常高.当数据库太大以至于不容易装进内存时,FP-growth算法的性能下降得很快.毕竟,数据挖掘面对的是海量的数据,将这样大量的数据在内存中组织有时是一个太高的要求.针对FP-growth算法的不足之处,本文提出了一种新的算法——快速频繁模式(Quick Frequent Pattern,QFP)算法,利用该算法建立、挖掘QFP-tree,提高扫描数据库速度的同时降低了反复构建条件频繁模式树以及条件模式基的数量,降低了算法计算的复杂度和对内存空间的占用,提高了频繁模式挖掘的速度,适合对大型数据库挖掘的要求.
首先给出QFP-tree的定义:
一棵QFP-tree为满足以下3个条件的树型结构.
(1)它由一个频繁度最低项作为树的根节点,作为根节点的孩子的项目前缀子树集合,以及频繁项目头表组成.
(2)树中每一个节点有项名(item-name),支持度(sup),计数器(cou),其中,item-name记录项目名,sup记录每一个频繁项的支持度,cou记录每一个频繁模式的频繁度(初始为0).其功能是在树的挖掘过程中用于临时记录中间模式的频繁度,避免对模式的重复计算,降低计算开销.
(3)频繁项目头表的每一个表项只包含一个域:item-name.
(4)树中父节点与子节点之间,频繁项目表与节点之间用单箭头连接.树型结构如图1.

图1 QFP-tree模型Fig.1 Quick Frequent Pattern-tree model
QFP算法的主要步骤.
(1)扫描数据库,根据支持度找到频繁项.
(2)针对给定事务中的频繁项建立QFP-tree结构.
(3)挖掘QFP-tree,生成频繁模式.
2.3 QFP-tree的建立
QFP-tree的建立的原则是:选择事务中频繁度最低的项作为树的根节点,为每一个频繁项建立相应的QFP-tree.在建立过程中,事务中每一个频繁项作为其相应QFP-tree的根节点建树.下面用一个实例来介绍QFP-tree的建立和挖掘过程.

表1 事务数据库Tab.1 Transaction database
如表1是事务数据库的一部分,其频繁项为{I1,I2,I3,I4,I5,I6},假定I1的频繁度最高,I6的频繁度最低.首先我们以I6项为根建立一棵QFP-tree.如图2,所有频繁度大于或等于I6且和I6属于同一个事务的项作为节点参与了树的建立.图2包括了2个节点.根节点I6和它的孩子节点I2.从表1中我们可以看到I2和I6同属于一个事务,且I6 I2在表1的数据库中只出现了2次.与此相同的是以I5为根的QFP-tree,I5 I1也在同一个事务中,且只出现了2次,如图3.而项I3同时与3个项出现,分别为I1,I2和I4.所以以I3为根的QFP-tree存在2个分支,如图4.即I3I2I1和I3I4I1.从表1中我们可以得到分支I3I2I1的频繁度为4,分支I3I4I1的频繁度为1.而此时I3的频繁度应变为5(=4+1).在表1中I3I4的频繁度为2,但是I3 I4属于分支I3I4I1,所以只更新I3和I4的频繁度,即I3的频繁度变为7(=5+2),I4的频繁度变为3(=2+1).同理I3 I2也属于分支I3I2I1,I3I2的频繁度为1,所以也只更新I3和I2的频繁度,即I3的频繁度为8(= 7+1),I2的频繁度为5(=4+1).剩下的分别以I4和I2为根与频繁度最高的I1构成QFP-tree如图5,图6.
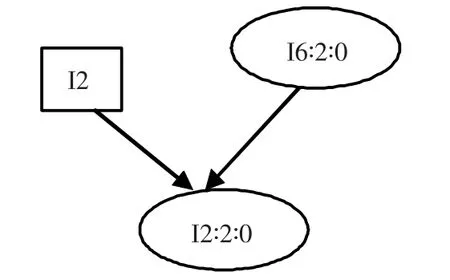
图2 I6项为根的QFP-treeFig.2 I6 is the root of the QFP-tree

图3 I5项为根的QFP-treeFig.3 I5 is the root of the QFP-tree

图4 I3项为根的QFP-treeFig.4 I3 is the root of the QFP-tree

图5 I4项为根的QFP-treeFig.5 I4 is the root of the QFP-tree
在建树的过程中,所有频繁项的QFP-tree不是同时建立的,而是在前一棵QFP-tree被建立、挖掘、删除后才建立的.这样就避免产生大量的或无用的QFP-tree对内存空间的占用.

图6 I2项为根的QFP-treeFig.6 I2 is the root of the QFP-tree
2.4 QFP-tree的挖掘
对每棵QFP-tree的挖掘过程是独立的.目的是找出每棵树的根节点所在的所有频繁k-项集模式.而其他的子模式的频繁度可以从它们的父模式中得到,无需再计算它们在数据库中的出现次数.我们以图4中的QFP-tree为例,通过挖掘以I3为根节点的QFP-tree发现包含I3的频繁模式,过程如图7.
假设支持度sup>3.在挖掘过程中,我们要使用到每个节点的支持度(sup)和计数器(cou),同时把得到的候选频繁模式存储在一个临时表中.在处理完每棵树的所有分支后根据sup的值删除不频繁的模式,从而生成符合条件的频繁模式.
在挖掘以I3为根节点的QFP-tree时,我们从树中频繁度最高的节点开始,即从节点I1开始.I1存在于分支I1I2I3(I1∶4,I2∶5,I3∶8)和分支I1I4I3(I1∶1,I4∶3,I3∶8)中.每一个分支的频繁度为第1个项的sup减去它的cou值.项I1在分支I1I2I3中,其sup值为4,cou的初始值为0,因此模式I1I2I3的频繁度为4,同时分支I1I2I3中所有节点的cou值加4.在第1个模式I1I2I3∶4中,生成包含项I3的所有子模式,即I1I3∶4,I2I3∶4.在I1所属的第2个分支I1I4I3中,I1的sup值为1,cou的初始值为0,所以模式I1I4I3的频繁度为1,同时分支I1I4I3中所有节点的cou值加1.在第2个模式I1I4I3中,生成包含I3项的子模式,即I4I3∶1和I1I3∶1.由于在模式I1I2I3也生成了模式I1I3,其频繁度为4,即I1I3∶4.所以更新模式I1I3的频繁度为5(=4+1),即I1I3∶5.此时处理完节点I1.顺着分支向上,得到第2个频繁项I2,项I2存在于分支I2I3(I2∶5,I3∶8)中.模式I2I3的频繁度为项I2的sup值5减去其cou的值4,即I2I3∶1,同时分支I2I3中所有节点的cou值加1.此前已经生成了模式I2I3∶4,所以要更新模式I2I3的频繁度为5(=4+1),即I2I3∶5.树中最后一个节点I4存在于分支I4I3(I4∶3,I3∶8)中,其sup值为3,cou值为1.所以模式I4I3的频繁度为2(=3-1),同时分支I4I3中所有节点的cou值加2.此前已经生成了模式I4I3∶1,所以更新模式I4I3的频繁度为3(=2+1),即I4I3∶3.此时以项I3为根节点的FP-tree挖掘完毕,根据sup,我们删除包含项I3的不频繁模式,保留频繁模式,同时删除此树生成、挖掘下一个QFP-tree,产生相应的频繁模式.
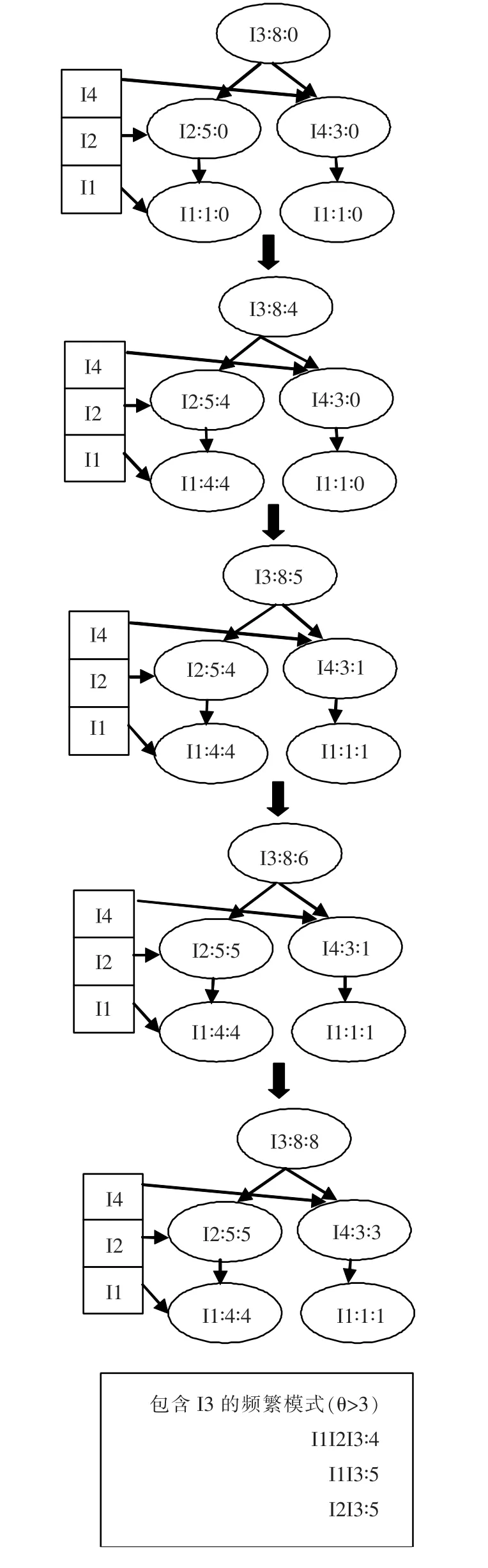
图7 QFP-tree挖掘过程Fig.7 The mining process of QFP-tree
QFP算法描述:
输入:事务数据库D;最小支持度阈值minsup.
输出:频繁模式.
(1)按以下步骤构造QFP-tree
1.1 扫描事务数据库D,根据min-sup找到第一个频繁项A;
1.2 A=Frequency Item at transaction;
1.3 Creat a root node for the(A)-QFP-tree with sup and cou=0;
1.4 While(node-fre-transaceion<Frequency of item A)
B=item from transaction;
Follow the chain of item B to produce subtransacion C;
Items on C form a prefix of the(A)-QFP-tree;
If the prefix is new then;
Set sup=1 and cou=0 for all nodes in the path;
Else
Adjust the pointer of the Header list if needed;
Increment node-of-QFP-tree;
Goto1.4;
(2)Mine QFP-tree(A)
1.node A=select-node;
2.While there are nodes do
2.1 Set of nodes from node A to the root;
2.2 F=sup-cou of node A;
2.3 Generate all Candididate patterns X from items in D.Patterns that do not have A will be discarded;
2.4 Patterns in X that do not exist in the A-Candidate List will be added to it with frequency=F.otherwise just increment their frequency with F;
2.5 Increment the value of cou by F for all node in D;
2.6 node A=select-node
2.7 Goto 2;
3.Base on min-support remove non-frequent patterns from A Candidate list;
3 算法性能分析
QFP算法生成频繁模式的过程中,首先从事务数据库中读入包含频繁项的子事务,然后依次为每个频繁项建立独立的QFP-tree.这样的QFP-tree树型结构的规模较小,需要的存储空间很小,从而能够降低计算的复杂度和对内存空间的占用.在挖掘过程中按照QFP-tree的生成顺序,每建立一棵QFP-tree树,就对其进行挖掘,当挖掘完成后立即删除QFP-tree,接着建立下一棵QFP-tree,然后再挖掘再删除,直到生成所有的频繁模式为止.这样做的好处是能够在挖掘过程中最大限度的减少候选项集产生的数量并且不用递归的建立条件子树.该算法与FP-growth算法相比,能够有效的降低计算的复杂度和对内存空间的要求,从而能够适应对大型数据库挖掘的要求.
为了进一步验证QFP算法的性能,在Windows XP,CPU为Celeron 2.4GHz,内存256,VC++6.0的环境下对QF算法和FP-growth算法在性能上进行了比较.实验数据集为济南快速公交车系统采集的乘客乘车记录,如表2.我们从中选取8 000条记录,记录了公交车的线路、站点、上车和下车人数、时间等信息.实验结果如图8.

表2 乘车记录表Tab.2 Travel record table

图8 算法性能比较Fig.8 Algorithm performance comparison
从图8中可以看到,QFP算法在运行时间上要优于FP-growth算法,当支持度改变时,其曲线平缓得多,说明其计算性能稳定.
4 结束语
本章提出了一种新的的频繁模式挖掘算法——QFP算法.分别从算法的思想、设计步骤、特点、实例分析和性能分析几方面进行了说明,并和经典的FP-growth进行性能上的比较,实验结果表明新算法较FP-growth算法具有良好的时间和空间性能.
[1]Han Jiawei,Kamber M.Data Mining Concept and Techniques[M].San Francisco:Morgan Kaufmann Publishers,2001.
[2]Eltabakh M Y,Ouzzani M,Khalil M A,et al.Incremen-tal mining for frequent patterns in evolving time series database[J].IEEE Transactions on Knowledge and Data Engineering,2008,7(2):158-165.
[3]Pei Jian,Han Jiawei,Lu Hongjun,et al.H-mine:Fast and space preserving frequent pattern mining in large database[J].Data Mining and Knowledge Discovery,2001,11(2):53-87.
[4]Lin C H,Chiu D Y,Wu Y H,et al.Mining frequent itemsets from data stream with a time-sensitive sliding window[C]//Proc of 5th SIAM International on Data Mining,Newport Beach:SIAM Press,2005.
[5]Han Jiawei,Pei Jian,Yin Yiwen.Mining frequent patterns without candidate generation[C]//Proc of ACMSIGMOD Int’1 Conference on Management of Data.New York:ACM Press,2000.
[6]Sathish K.Efficient tree based distributed data mining algorithms for mining frequent patterns[J].International Journal of Computer Applications,2010,11(10):233-242.
[7]Rahul M.Comparative analysis of apriori algorithm and frequent pattern algorithm for frequent pattern mining in web log data[J].International Journal of Computer Science and Information Technologies,2012,3(4):4662-4665.
[8]Han Jiawei,Pei Jian,Yin Yiwen.Mining frequent patterns without candidate generation:a frequent-pattern tree approach[J].Data Mining and Knowledge Discovery,2004,8(1): 53-87.
[9]Kantarcioglu M,Clifton C.Privacy-preserving distributed mining of association rules on horizontally Partitioned Data[J]. IEEE Transaction on Knowledge and Data Engineering,2004,16 (9):1026-1037.
[10]Shenoy P,Hartisa JR,Sudarshan S.Turbo-charging vertical mining of large database[C]//Proc of ACM SIGMOD Int’t Conf.on Management of Data.New York:ACM Press,2000.
[11]Han Jiawei,Pei Jian,Yin Yiwen.Mining Frequent Patterns Without Candidate Generation[C]//Proc of the ACM SIGMOD Conf on Management of Data.Dallas:ACM Press,2000.
[12]Burdic D,Calimlim,Gehrke J.A maximal frequent itemset algorithm for transaction database[C]//Proc of the Int'1 Conf on Data Engineering.Heidelberg:ICDE Press,2001.
[13]Gouda K,Zaki M J.Mining maximal frequent itemsets[C]//Proc of the 1st IEEE Int'1 Conf on Data Mining.Piscataway:IEEE Press,2001.
[14]石杰,刘希玉.山东省计算机学会信息技术与信息化研讨会论文集[C]//山东:山东科学出版社,2005.
A Fast Algorithm for Mining Frequent Patterns
SHI Jie1,2
(1.Laboratory And Equipment Management Office,Shandong Youth University of Political Science 250103,China;2.Key Laboratory of Information Security and Intelligent Control in Universities of Shandong Youth,Jinan 250103,China)
A new algorithm,Quick Frequency Pattern(QFP),is presented for the frequent pattern on the basis of studying FP-growth.Firstly,a QFP-tree is made for every frequent item set,and then every tree is being mined according to the configured conditions until the pattern is found.It is proved that QFP can reduce the amount of the sub-trees,the requirement for the RAM space and the calculating time of the CPU,the efficiency of data mining related with the association rules can be improved accordingly.
data mining;frequent pattern;itemset
TP311
A
(责任编辑 苏晓东)
1004-8820(2015)02-0113-06
10.13951/j.cnki.37-1213/n.2015.02.007
2014-08-23
山东省自然科学基金资助项目(ZR2013FM010).
石杰(1980-),山东济南人,讲师,硕士,主要研究方向:人工智能、数据挖掘等.
