不确定条件下中间存储时间有限多产品间歇生产过程调度
2015-06-19耿佳灿顾幸生
耿佳灿,顾幸生
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
引 言
间歇过程适用于生产中小批量且高附加值的产品,广泛应用于精细化工、食品饮料、生物医药等行业[1]。它固有的灵活性决定了可通过合理调度达到增产降耗和节能减排等目的[2]。
在间歇过程中,常需设立存储设备用来暂存中间产品,以增加生产能力、提高生产柔性。目前,学者们对中间存储容量有限(capacity-constrained intermediate storage)的调度问题已进行了广泛研究[3],而在许多间歇过程中也存在中间存储时间有限(time-constrained intermediate storage)的情况,如在食品加工过程中,未包装的食品容易变质,在中间储罐中存储一定时间后必须及时包装出售或进入下级单元加工,否则会降低生产质量甚至造成浪费。目前对中间存储时间有限的问题研究还较少[4],因此,本文对中间存储时间有限多产品间歇生产过程调度进行研究。
对间歇生产过程调度问题的研究集中在调度模型和优化算法上[5-6],这些研究一般假设生产过程是在静态、确定的环境下进行的,所有的数据都是精确可知的。然而,企业实际生产运营活动是动态不确定的,客观存在着许多不确定因素,如产品处理时间波动、交货期不确定、设备突发故障等。忽略这些不确定因素会导致预定的生产调度方案性能降低甚至不可行,因此在制定调度方案时考虑不确定因素的影响显然更符合实际情况。目前对不确定性调度的研究方法主要有随机调度规划和模糊调度规划等[7-8]。由于在生产实际中根据历史信息统计不确定参数的概率分布比较困难,而大致估计其区间则相对容易,因此本文采用模糊规划理论处理生产调度问题中的不确定因素。
粒子群优化算法(particle swarm optimization,PSO)[9]结构简单、便于实施,已成功应用于生产调度问题。近年来,基于对概率模型学习和采样的分布估计算法(estimation of distribution algorithm,EDA)[10]成为进化计算领域的研究热点。本文在粒子群算法中引入遗传操作和分布估计算法,提出一种基于改进粒子群和分布估计的混合算法(improved particle swarm optimization with estimation of distribution algorithm, IPSO-EDA),并将其应用于解决产品处理时间不确定条件下中间存储时间有限多产品间歇生产过程调度(time-constrained intermediate storage multiproduct batch process scheduling with uncertainty, UTISBPS),取得了满意的效果。
1 不确定条件下中间存储时间有限多产品间歇生产过程调度
1.1 问题描述与数学模型
中间存储时间有限多产品间歇生产过程调度可描述为:所有产品遵循相同的加工路径,中间产品在中间储罐内存储的时间不能超过某一有限值。为了保证满足中间存储时间有限的约束,产品在第1台设备上的开始时间可以适当延迟。图1为一般的中间存储时间有限多产品间歇生产过程。
有n种产品要在m台设备上处理,产品i在设备j上的处理时间是给定的,它包括装配、传输、卸载、加工以及清洗时间等,是不确定量,本文采用三角模糊数对其进行描述。MSTij为第i种产品在设备j和j+1间的中间储罐内的最大存储时间。定义和分别表示产品i在设备j上的开始处理时间和完工时间,模糊最大完工时间(fuzzy makespan)用表示。由于产品的处理时间是不确定量,开始处理时间和完工时间也是不确定量。为了更好地衡量模糊调度的好坏,本文以最小化模糊最大完工时间的值以及不确定度作为调度目标。
中间存储时间有限多产品间歇过程调度问题的数学模型如下
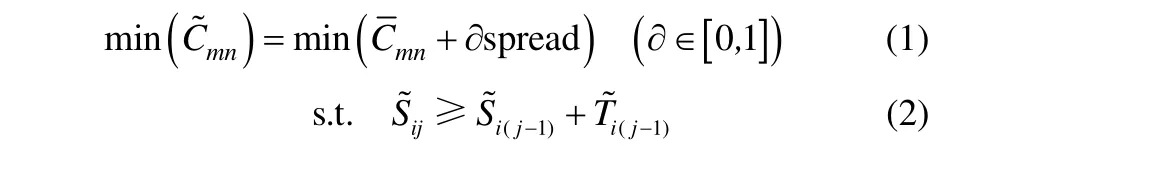

图1 中间存储时间有限多产品间歇生产过程Fig.1 Time-constrained intermediate storage multiproduct batch process
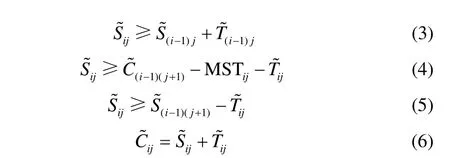
其中,跨度spread是模糊最大完工时间的最大值和最小值之差,表示模糊完工时间的不确定程度,spread越大说明模糊完工时间的不确定度越大;∂为加权系数。本文的调度目标是使模糊最大完工时间的平均值和不确定度同时最小。
式(2)~式(6)为约束条件。式(2)表示加工顺序约束:产品i必须在j−1台设备上完工后才能进入下一设备j进行加工,即任意时刻每种产品只能在一台设备上进行处理。式(3)表示资源约束:产品i必须在其前一个产品i−1在某一设备完工后,才能进入该设备进行加工,即每台处理设备只能同时处理一种产品。式(4)表示中间存储时间有限约束:中间产品在中间储罐的存储时间不能超过规定的最大存储时间。式(5)表示中间储罐只能同时存放一种产品,产品不能混合存放,以免发生反应。式(6)表示产品的完工时间等于开始加工时间和加工处理时间之和。
另外,产品加工过程中不允许中断,所有产品可以在零时刻投入生产。
1.2 模型转换
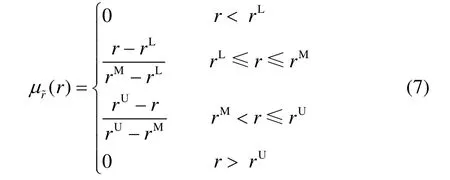
隶属度函数如图2所示。其中,rL、rM、rU分别表示最小值、最可能值和最大值。
文献[11]定义了用于模糊调度的模糊加法和模糊极大运算
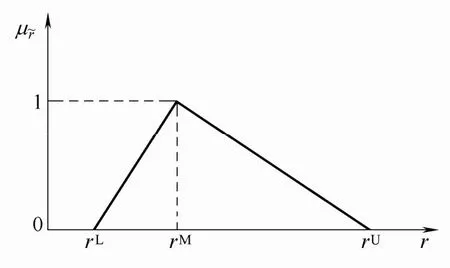
图2 三角模糊数的隶属度函数Fig.2 Membership function of triangular fuzzy number
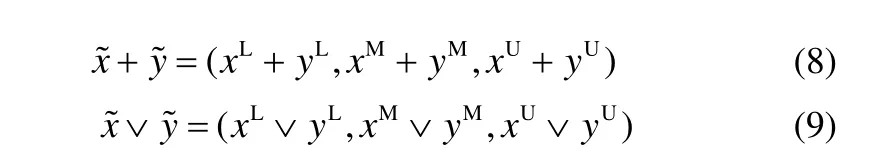
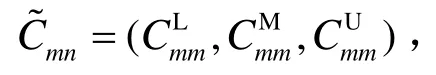
本文采用Lee等[12]提出的以模糊事件概率测量求算平均数及标准差的方法来实施模糊数排序,当模糊事件的概率分配服从比例分布时,其平均数和标准差为
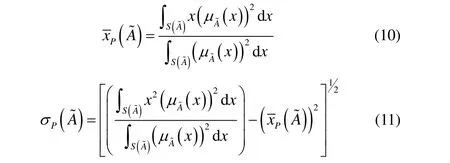
当模糊数为三角模糊数时,式(10)、式(11)可简化为
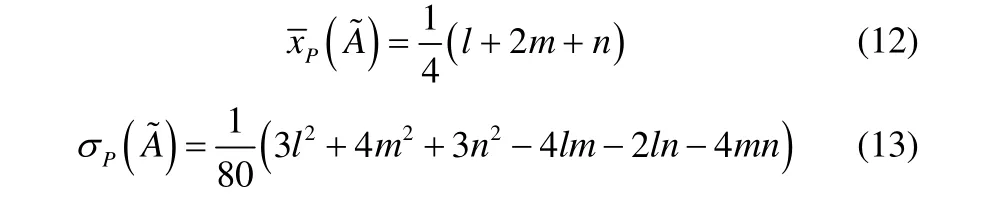
2 求解 UTISBPS的改进粒子群和分布估计混合算法
2.1 基于遗传操作的改进粒子群算法
粒子群优化算法是一种基于群体智能、模拟鸟群觅食活动的仿生算法,粒子群中的每个粒子都根据自身速度、自身最优位置Pbest和全局最优位置Gbest调整搜索方向,种群间粒子合作竞争实现对优化问题的求解。PSO已成功应用于多个领域,表现出优良的性能。
但标准PSO算法采用实数编码,具有连续的本质,调度问题属于离散域的组合优化问题,直接用标准PSO算法求解存在困难。本文借鉴文献[13]的思想,采用遗传操作对粒子群算法的更新公式进行重新定义和改进,使之适用于求解调度问题。
基于遗传操作的改进粒子群算法中每个粒子用一个可行的调度排序表示,如一个有8个产品的调度排序(2,5,3,4,7,8,1,6)表示一个粒子。粒子通过自身当前位置、自身最优位置和全局最优位置进行更新,更新公式如下
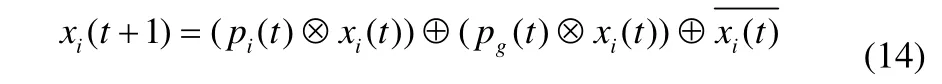
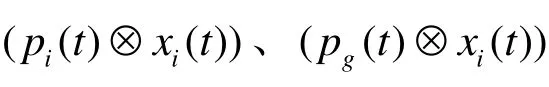
本文采用两点交叉方式,随机选择两个交叉点,位于两个交叉点之间的信息来自于一个父代,位于交叉点之外的信息来自另一个父代。图3给出了一个两点交叉操作的例子。父代 1为(6,1,4,5,8,2,3,7),父代 2为(3,5,2,6,1,7,4,8),假设两个随机交叉点为3和6,则父代1交叉点之间的信息序列为(4,5,8,2),这个序列保留到子代1中,父代2中除去这些信息的剩余信息序列为(3,6,1,7),这两个序列组合生成子代1为(3,6,4,5,8,2,1,7),同理生成子代2为(4,5,2,6,1,7,8,3)。生成的两个子代中的较优个体作为交叉操作的后代进行下一步操作。
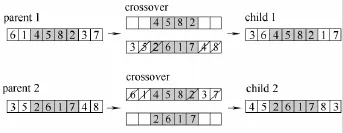
图3 两点交叉操作示意图Fig.3 Method of two-point crossover
本文采用插入变异方式,随机选择两个位置,将其中一个位置插入到另一个位置之前,如个体(2,5,3,4,7,8,1,6)经过将第6个位置插入到第2个位置前生成变异个体(2,8,5,3,4,7,1,6)。
2.2 分布估计算法
分布估计算法是一种新兴的进化算法,没有传统的交叉变异等遗传操作,通过统计学习的手段建立解空间内个体分布的概率模型,然后对概率模型随机采样产生新种群,如此反复进行,实现群体的进化。其基本步骤如下[10]:①随机产生初始种群;②根据个体的适应度值选择Q个较优个体用于构建概率模型;③采用某种概率模型对优质个体进行评估并构建概率模型;④根据概率模型采样,生成M个新个体;⑤判断是否满足终止条件,满足则输出最优解,否则返回步骤②。
EDA的核心操作是建模和采样,通过选择种群内的优质个体集合,评估它们的分布,建立优质个体的概率模型,然后根据这种包含了优质个体分布信息的概率模型采样生成新种群。其中构建何种概率模型对EDA算法的性能影响很大,Jarboui等[14]考虑调度排序中产品的顺序和相似模块构建了一种针对Flow Shop调度问题的概率模型,Pan等[15]对Jarboui等提出的概率模型进行了补充和改进,本文应用Pan等提出的改进概率模型进行EDA操作。
2.3 改进粒子群和分布估计混合算法
粒子群算法是一种随机性比较高的进化算法,且更新公式中对社会认知部分的信息包含得不够全面。通过粒子自身最优位置和全局最优位置指导搜索,没有利用到种群中非全局最优位置的优质粒子信息,随着进化代数的增大,种群多样性降低,易陷入局部最优。
分布估计算法是统计学习和随机优化算法的结合,通过建立全局范围内优质个体的概率模型,从宏观的角度获得优质个体的分布信息,解决了许多传统进化算法难以求解的复杂优化问题。
本文考虑用基于所有粒子自身最优位置的优质个体分布信息引导粒子群进行更新。对粒子群中所有粒子的自身最优位置进行评估选择建模,并根据此模型采样生成新种群。包含优质个体分布信息的新种群和全局最优位置共同指导粒子群搜索,可以改进粒子群的更新机制,提高算法的全局搜索能力。因此,本文提出一种基于改进粒子群和分布估计混合算法,并用于解决不确定条件下中间存储时间有限多产品间歇生产过程调度问题,IPSO-EDA算法的流程如图4所示。
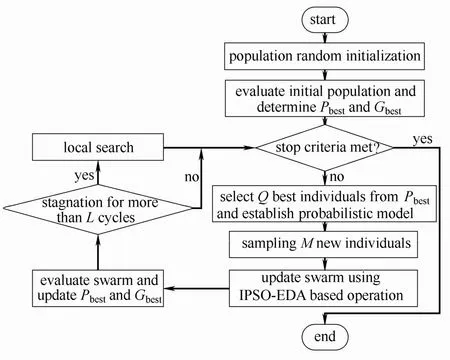
图4 IPSO-EDA算法流程Fig.4 Flowchart of IPSO-EDA algorithm
2.3.1 解的表达与初始化 本文采用基于工件排序的表达方式,一个可行的调度排序代表一个可行解。
为了保证初始种群的质量和多样性,本文采用基于NEH启发式算法[16]的初始化方法,NEH启发式算法步骤如下:① 按各产品在所有设备上的处理时间总和递减的顺序排列n个产品;②取前两个产品进行最优调度;③依次将剩余产品插入已调度好的产品排序中的某个位置,使得子调度指标最小,直到所有产品调度完成。
由于本文的产品处理时间是不确定的,在采用NEH启发式方法生成初始解时,本文对产品的最小处理时间、最可能处理时间和最大处理时间分别进行NEH操作,得到3个高质量的初始解,其余初始解随机生成。
2.3.2 选择与构建概率模型 对所有粒子的自身最优位置进行评估,按调度目标值升序排列,选择其中调度目标值最小的前Q个个体用于构建模型。此选择方法相比轮盘赌和锦标赛的选择方法更为迅速。
文献[15]中将产品j分配在调度排序中的第i个位置进行处理的概率为
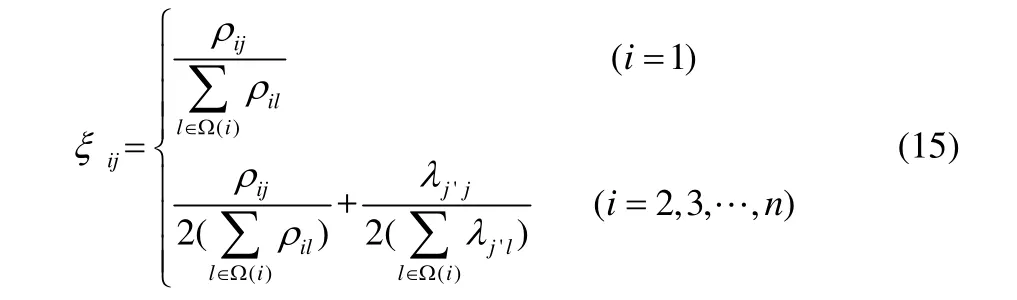
式中,ρij为在选择的Q个优质个体中,产品j出现在位置i及位置i以前的总次数,ρij的值代表了调度排序中产品处理顺序的重要性;λj′,j为在选择的Q个优质个体中,所有位置上出现(j′,j)调度排序的总次数,j′为当前采样个体在第i−1个位置上处理的产品,λj′,j的值代表了调度排序中相似模块的重要性。Ω(i)为当前采样个体中截止到位置i仍未被分配的产品集合。
以一个有4个待处理产品的调度问题为例进行说明,假设选择的优质个体为(1,3,4,2)、(2,1,4,3)、(3,4,2,1),则
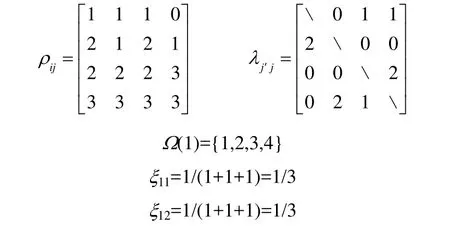
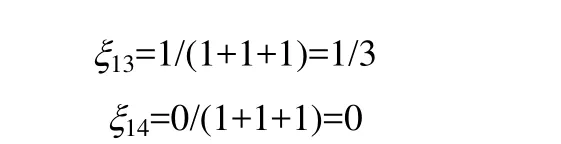
假设产品1被安排在第一个位置进行处理,则
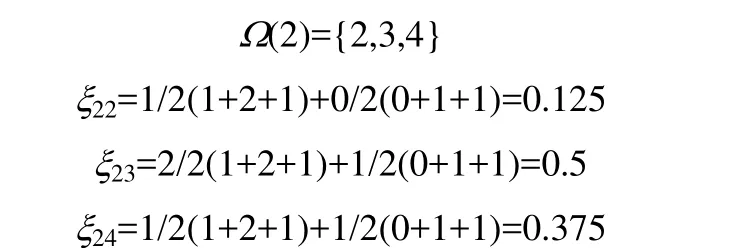
2.3.3 采样与种群更新 首先计算概率模型中每一行的累积概率P,Pij表示概率模型中的第i行上第j列之前的概率之和;然后生成0~1之间的一个随机数ε,若Pi(j−1)<ε≤Pij,则第i个位置选择产品j进行处理;并将概率模型的第j列全部设为零,同时更新每一行的非零元素,使每行的所有元素之和仍为 1,以保证采样产生的新个体中每个产品只出现一次;重复上述操作直至对所有位置分配产品,即采样生成了一个新个体。
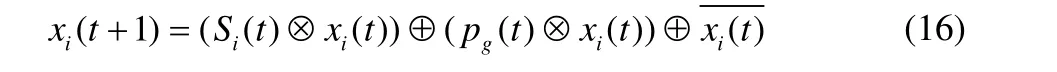
本文提出的IPSO-EDA算法的更新公式如下其中,S(t)为基于对所有粒子的自身最优位置进行选择建模采样生成的包含优质个体分布信息的新种群。改进的更新公式中粒子在S(t)、全局最优位置pg(t)以及当前粒子位置x(t)这3个因素的引导下进行更新,粒子群的更新机制中包含的信息更加全面,提高了算法的全局搜索能力。
2.3.4 局部搜索 采用局部搜索策略可以增强算法的局部搜索能力,提高算法的性能。基于插入邻域和交换邻域的局部搜索是常用的有效局部搜索方法。本文采用一种基于插入操作的 NEH局部搜索策略对最优解进行局部搜索。经过实验发现,NEH局部搜索的效果要好于交换以及插入局部搜索。NEH局部搜索步骤如下:首先将当前最优解的排序作为初始排序,其余步骤同 NEH启发式算法的步骤②、③,得到一个当前最优解的邻域解,判断此解是否具有更好的调度目标,是则对最优解进行更新。考虑到局部搜索比较费时,本文设置一个参数L表示算法的最优调度目标值连续L代没有发生变化,此时对算法最优解进行上述局部搜索,这样可以在保证算法性能的同时提高算法的搜索速度。
3 仿真研究
3.1 仿真实验设置
为了验证IPSO-EDA算法在解决不确定条件下中间存储时间有限多产品间歇生产过程调度时的有效性,本文进行了一系列的仿真实验,仿真硬件环境为Intel(R)Core(TM)i7-2006 CPU/3.4GHz/4.0GB。仿真软件平台为Windows 7系统,所涉及的算法均采用Matlab R2011b编写。
对于不确定多产品间歇过程调度问题,没有合适的标准算例,本文采用文献[17]提出的方法对Reeves[18]设计的标准算例进行模糊化。将标准算例中每一个确定数据x转变为一个三角模糊数,三角模糊数最左边的值为[δ1x,x]之间的一个随机数,0<δ1<1,三角模糊数最右边的值为[x,δ2x]之间的一个随机数,δ2>1。本文设置δ1=0.9,δ2=1.2。而对于中间存储时间有限的调度问题,为了方便起见,设中间存储时间均为 MST个时间单元。在算法参数讨论和算法性能测试中,所有算法运行终止条件都设为达到最大进化代数Gen。
3.2 算法参数讨论
算法参数对算法的性能有很大的影响,需要对算法的参数进行调节,以保证算法在其最优状态下运行。本文提出的IPSO-EDA算法涉及以下4个关键参数:最大进化代数Gen(在m×n附近取值较好[19])、种群规模M(在20~50之间取值较好[20])、优质个体规模Q(用q%×M并取整表示)、最优解连续L(用l%×Gen表示)代不发生变化。对每个参数设置 3个不同值进行实验,采用全面实验共需要34=81组参数组合,本文采用因子设计(factorial design,FD)[21]方法对参数进行选择,只需要 32=9组参数组合就能找到较好的算法参数。表1给出了正交实验因素和水平。
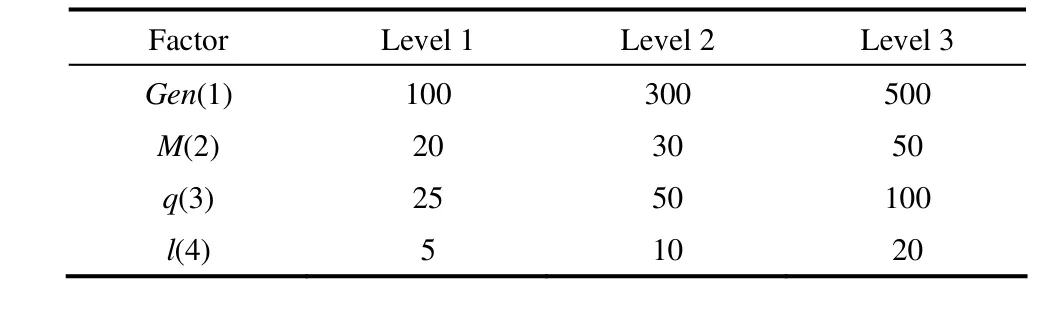
表1 正交实验因素和水平Table 1 Factors and levels for orthogonal experiment
对Rec系列算例中不同规模的算例各取一个进行正交实验,表2为以正交设计表L9(34)为基础的正交实验结果,图5给出了每个参数在不同水平下的趋势。表2中包含了9组参数组合,其中每组参数组合运行 5次取平均值,则共需要 7×9×5=315组实验。将根据式(17)求得的相对百分偏差(relative percentage deviation, RPD)列于表的最后一列。表中第10~12行、第j列的ki表示参数j在i水平上3组实验结果的平均值,第j列的SD表示参数j的k1到k3的标准差(standard deviation,SD)。对于每个参数,最小的ki对应的i水平所对应的参数值最好。SD越大说明该参数对算法的影响越大。表2中每一列最小的ki值被加粗,并给出SD的降序排序。

式中,ci是第i组参数组合的最大完工时间,c*是所有参数组合中最小的最大完工时间。
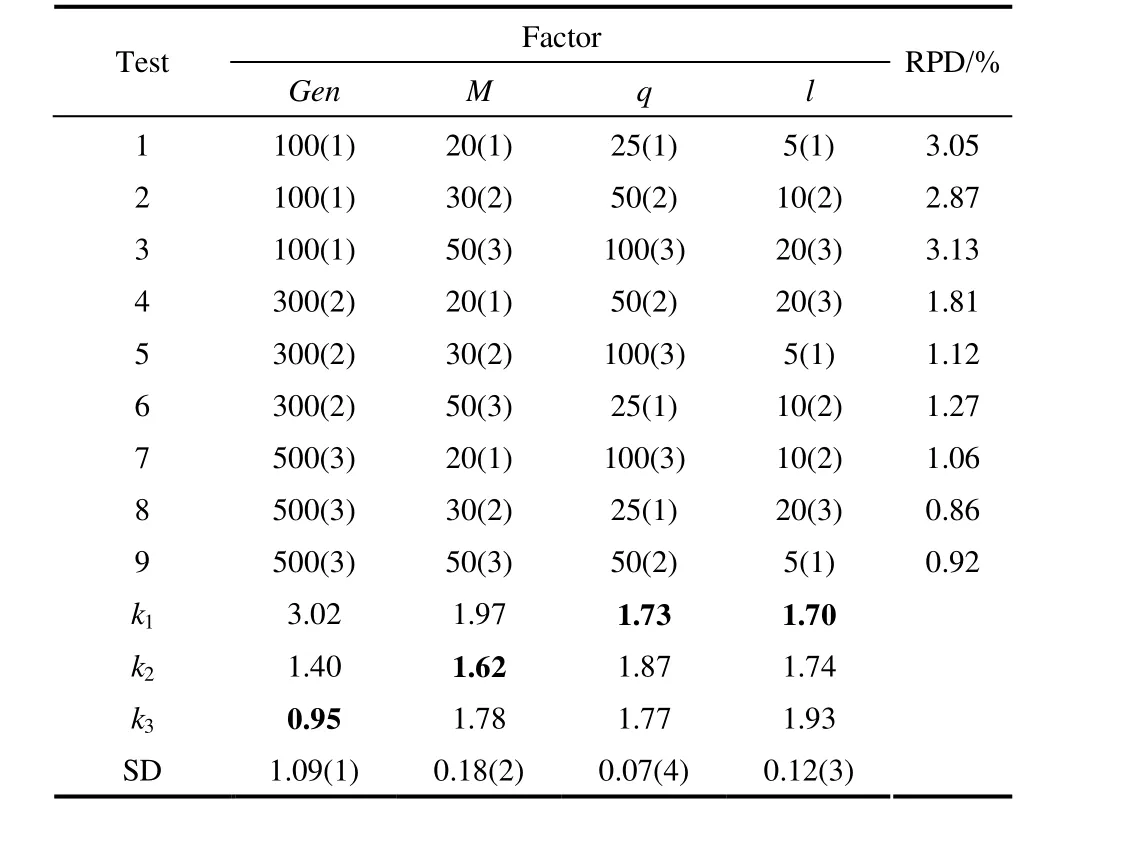
表2 L9(34)正交表及实验结果Table 2 Orthogonal parameter table L9(34)and results
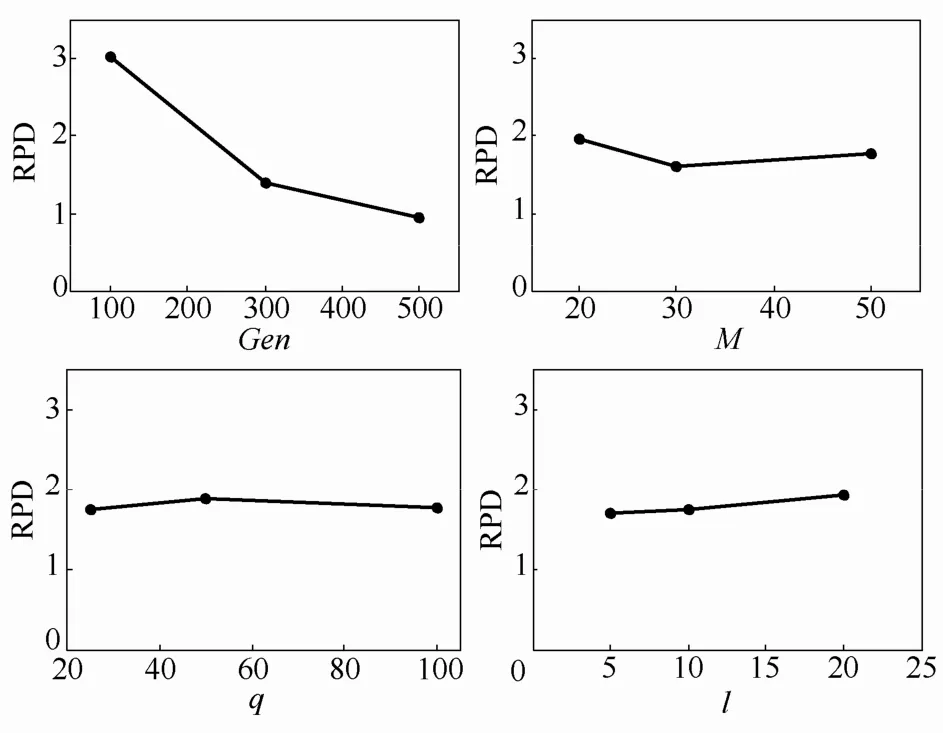
图5 IPSO-EDA算法参数变化趋势Fig.5 Trend graph of parameters in IPSO-EDA
从表2和图5可以看出,最大进化代数Gen对IPSO-EDA算法的性能影响最大。Gen过小会导致算法终止时还没有完全收敛,很大程度上降低算法的收敛精度,而随着Gen逐渐增大,其对算法收敛精度的影响逐渐降低,算法完全收敛后,再增大Gen算法的收敛精度将不再提高,因此合理设置Gen可以保证算法的收敛性。参数M对算法的影响排在第2位,较大的种群规模M可以包含较多的信息,从图5中可以看出M过小或过大都会降低算法的收敛精度,本文中M取30时算法的收敛精度最高。参数l对算法影响排在第3位,l越小对最优解的局部搜索越多,越可能跳出局部极值,算法的收敛精度也越高,但是局部搜索次数太多即l过小时对算法收敛精度的影响趋于不明显,且会花费较多的运行时间,因此需综合考虑运行时间和算法精度,合理设置参数l。参数q对算法影响最小,较小的优质个体规模q可以建立更加准确的优质个体分布信息模型,从而提高算法的收敛精度。
根据上述分析,本文选择Gen=500,M=30,q=25,l=5时算法有较高的收敛精度,能够取得较好的效果,因此在3.3节的算法性能测试中参数取值如上。下文与其他算法进行对比的实验结果也验证了本文算法具有较好的收敛精度和收敛速度。
3.3 算法性能测试
MST=0时为零等待的情况,MST=∞时为中间存储无限的情况。本文分别取MST={0,10,50,100,500},研究不同 MST情况下的调度问题。以 Rec29为例,对每个 MST值,IPSO-EDA算法独立运行10次,取平均值,绘制了如图6所示的不同MST情况下模糊最大完工时间的变化趋势。由图6可以看出,MST越小,中间产品在中间储罐中的可停留时间越小,限制越多,完工时间越大;MST越大,中间产品在中间储罐中的可停留时间越大,限制越少,完工时间也越小;当MST达到某一值后,调度问题的完工时间迅速减小,之后将趋于稳定,说明MST达到某一阈值后对调度问题的影响将大大减小,找到这一阈值并合理利用可以帮助企业提高生产效率。在之后的对比实验中选择MST=10的调度情况进行实验。
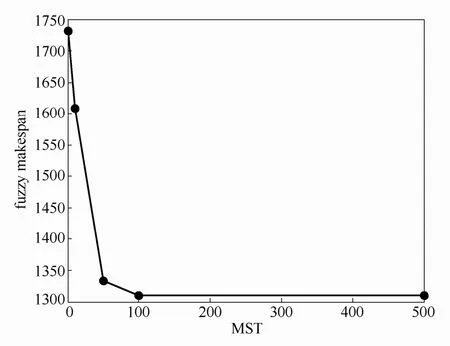
图6 不同MST情况下最大完工时间趋势Fig.6 Trend graph of fuzzy makespan with different MST
通过选择不同的权重系数∂可以调整调度目标中对完工时间的值和不确定程度的侧重,本文对∂={0,0.5,1} 3种不同情况下的调度问题进行研究。∂=0表示只最小化最大完工时间的值,不考虑完工时间的不确定度;∂=0.5和∂=1时同时考虑了最小化最大完工时间的值和不确定度,其中∂=1时对不确定度的侧重更大。以Rec29为例,表3给出了不同∂下的调度结果,对每个∂独立运行10次,取其最小值(min)和平均值(avg)列于表3中。可以看出随着∂增大,调度目标的值也会增大,主要是由于对完工时间的不确定度的侧重增大。∂取何值要依赖不同的生产环境,如在时间代价比较大的生产环境中,应该选择较小的∂值;而在不确定性较大的生产环境中,则应该选择较大的∂值。在之后的对比实验中选择∂=0.5的情况进行实验。

表3 不同∂情况下的调度问题Table 3 Scheduling problems with different ∂
本文通过将提出的IPSO-EDA算法与一种改进粒子群算法(GPSO)[13]和一种有效的分布估计算法(EDA)[22]进行比较以测试IPSO-EDA算法的性能。每个算法独立运行10次,10次结果的最小值记为min,平均值记为avg,平均运行时间记为time。
表4给出了IPSO-EDA算法与其他各算法的比较结果,其中每一行中最优的min、avg和time被加粗。可以看出,在大多数规模较小的算例上,IPSO-EDA算法优势不明显,优化性能不如 GPSO算法,但优于 EDA算法,且运行时间最短。而在规模较大的算例上,所提出的IPSO-EDA算法优势明显,在解的性能、稳定性以及运算时间上均好于其他算法。这是因为本文提出的IPSO-EDA算法是考虑调度排序中产品顺序和相似模块构建的针对多产品间歇过程调度问题的概率模型,是对实际模型的简化,当问题规模较大时,每个解中包含的信息较多,使用的模型更接近实际模型,算法的寻优性能更好。本文提出的算法只在最优解连续L代没有发生变化时对其进行简单有效的NEH局部搜索,对局部搜索的依赖不大,大大提高了算法的运行速度。
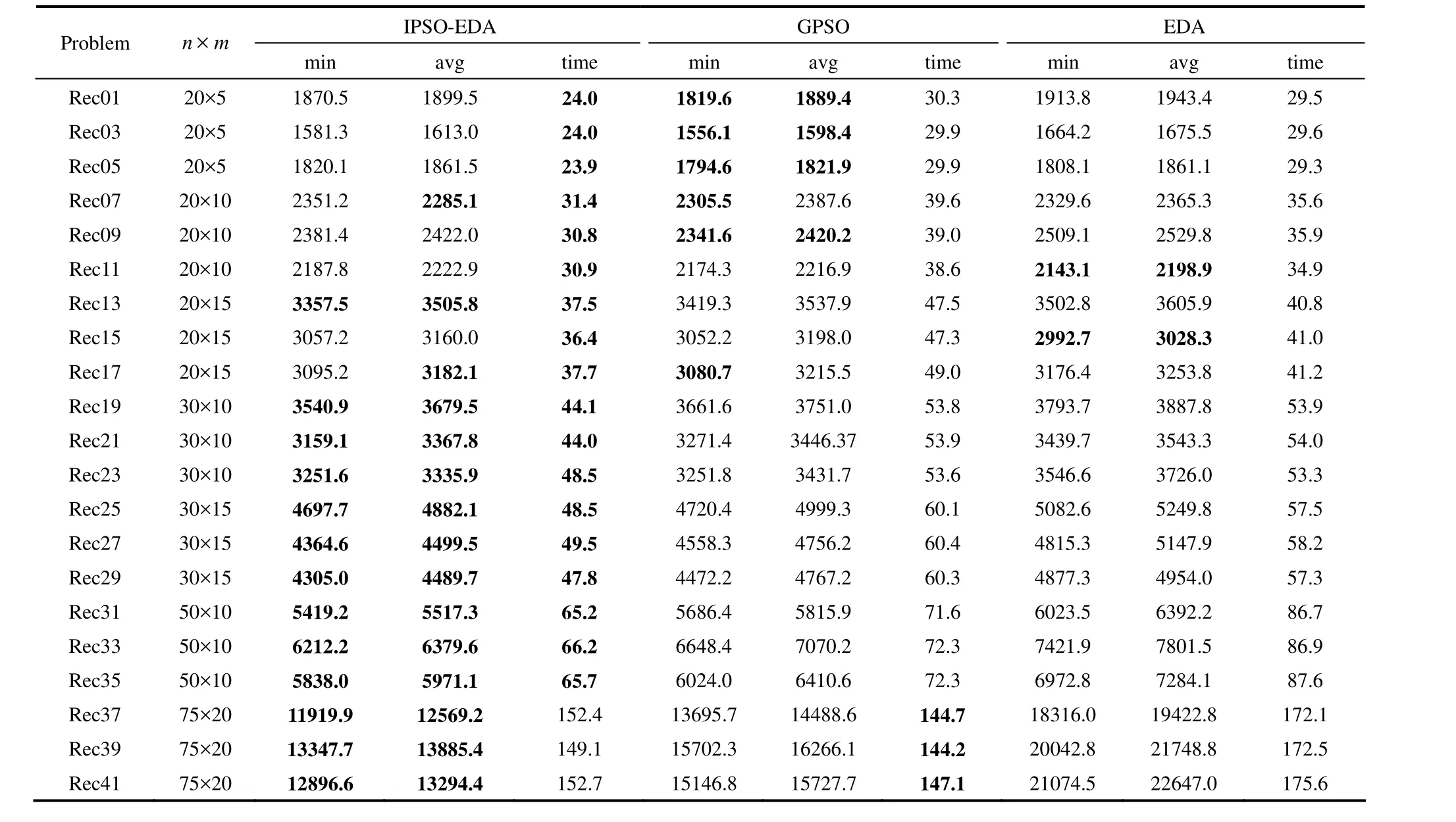
表4 IPSO-EDA算法与其他各算法的比较Table 4 Comparisons of IPSO-EDA with other algorithms
以Rec29为例,图7给出了上述3种算法的收敛曲线对比。从图7可以看出,在相同的最大进化代数终止条件下,IPSO-EDA算法收敛到的值最小,搜索精度最高,GPSO算法其次,EDA算法最终得到的结果较差。从图中还可以看出EDA算法收敛速度较慢,GPSO较IPSO-EDA算法的收敛速度稍快但陷入了局部最优,IPSO-EDA算法的收敛速度较快,而且搜索精度最高。综上可以看出IPSO-EDA算法相比于其他两种算法的优越性。
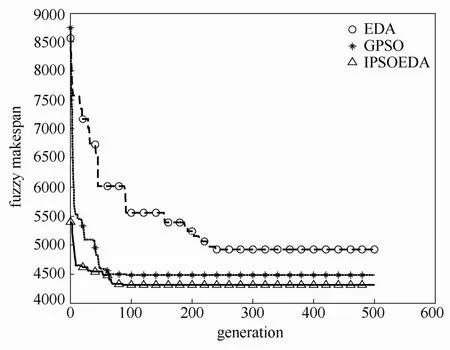
图7 算例Rec29的各算法收敛曲线对比Fig.7 Convergence curves of instance Rec29
5 结 论
本文研究不确定条件下中间存储时间有限多产品间歇生产过程调度问题,该问题广泛应用在许多实际生产过程中,且考虑不确定的处理时间,更符合实际情况,可以指导实际生产。用模糊排序的方法对模糊完工时间的值和不确定程度进行评估,将模糊完工时间的平均值和标准差进行加权作为调度目标,建立了一个清晰的调度规划模型。提出了一种适用于求解上述调度模型的IPSO-EDA算法。通过在粒子群算法中引入遗传操作和分布估计思想,改进了算法的更新机制,同时采用基于 NEH的初始化和局部搜索提高算法的性能。实验结果证明了IPSO-EDA算法有较快的求解速度和较好的寻优性能。对不确定间歇过程调度还需进一步研究中间存储时间约束只存在于部分任务中以及多目标间歇过程调度等问题。
符 号 说 明
——模糊最大完工时间的平均数
MSTij——第i种产品在设备j和j+1间的中间储罐内的最大存储时间
m——设备总数
n——产品总数
,——分别为产品i在设备j上的开始处理时间和完工时间,均为模糊数
spread ——模糊最大完工时间的跨度
——产品i在设备j上的模糊处理时间
[1]Yue D, You F. Sustainable scheduling of batch processes under economic and environmental criteria with MINLP models and algorithms [J].Computers & Chemical Engineering, 2013, 54: 44-59
[2]Liang Tao(梁涛), Li Qiqiang(李歧强). Self-organizing approach to multistage batch scheduling with batching optimization [J].Control and Decision(控制与决策), 2011, 26(12): 1818-1823
[3]Pan Q K, Wang L, Gao L, Li W D. An effective hybrid discrete differential evolution algorithm for the flow shop scheduling with intermediate buffers [J].Information Sciences, 2011, 181(3): 668-685
[4]Akkerman R, Van Donk D P, Gaalman G. Influence of capacity-and time-constrained intermediate storage in two-stage food production systems [J].International Journal of Production Research, 2007,45(13): 2955-2973
[5]Belaid R, T’kindt V, Esswein C. Scheduling batches in flowshop with limited buffers in the shampoo industry [J].European Journal of Operational Research, 2012, 223(2): 560-572
[6]Zhou Xiaohui(周晓慧), Chen Chun(陈纯), Wu Peng(吴鹏), Zheng Junling(郑骏玲). Optimized scheduling of production process based on continuous-time in printing and dyeing industry [J].CIESC Journal(化工学报), 2010, 61(8): 1877-1881
[7]Li Z, Ierapetritou M. Process scheduling under uncertainty: review and challenges [J].Computers & Chemical Engineering, 2008, 32(4):715-727
[8]Gu Xingsheng(顾幸生). A survey of production scheduling under uncertainty [J].Journal of East China University of Science and Technology(华东理工大学学报), 2000, 26(5): 441-446
[9]Kennedy J, Eberhart R C. Particle swarm optimization//Proceeding of IEEE International Conference on Neural Networks[C]. Perth,Australian, 1995: 1942-1948
[10]Larrañaga P, Lozano J A. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation[M]. Boston: Kluwer Academic Publishers, 2002
[11]Sakawa M, Kubota R. Fuzzy programming for multiobjective job shop scheduling with fuzzy processing time and fuzzy duedate through genetic algorithms [J].European Journal of Operational Research, 2000, 120(2): 393-407
[12]Lee E S, Li R J. Comparison of fuzzy numbers based on the probability measure of fuzzy events [J].Computers & Mathematics with Applications, 1988, 15(10): 887-896
[13]Niu Q, Jiao B, Gu X. Particle swarm optimization combined with genetic operators for job shop scheduling problem with fuzzy processing time [J].Applied Mathematics and Computation, 2008,205(1): 148-158
[14]Jarboui B, Eddaly M, Siarry P. An estimation of distribution algorithm for minimizing the total flowtime in permutation flowshop scheduling problems [J].Computers & Operations Research, 2009, 36(9):2638-2646
[15]Pan Q K, Ruiz R. An estimation of distribution algorithm for lot-streaming flow shop problems with setup times [J].Omega, 2012,40(2): 166-180
[16]Nawaz M, Enscore E, Ham I. A heuristic algorithm for them-machine,n-job flow-shop sequencing problem [J].The International Journal of Management Sciences, 1983, 11(1): 91-95
[17]Omar A G. A bi-criteria optimization: minimizing the integral value and spread of the fuzzy makespan of job shop scheduling problems[J].Applied Soft Computing, 2003, 2(3): 197-210
[18]Reeves C R. A genetic algorithm for flowshop sequencing [J].Computers & Operations Research, 1995, 22(1): 5-13
[19]Wang L, Zhang L, Zheng D Z. An effective hybrid genetic algorithm for flow shop scheduling with limited buffers [J].Computers &Operations Research, 2006, 33(10): 2960-2971
[20]Eberhart R C, Shi Y. Particle swarm optimization: developments,applications and resources//Proceedings of the IEEE Congress on Evolutionary Computation [C]. Seoul, Korea, 2001: 81-86
[21]Montgomery D C. Design and Analysis of Experiments[M]. New York: Wiley, 2008
[22]Wang S Y, Wang L, Liu M, Xu Y. An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem [J].International Journal of Production Economics, 2013, 145(1): 387-396
