适应节能与异构环境的MapReduce数据布局策略*
2015-06-09廖彬,张陶,于炯,刘继,钟磊,刘炎
廖 彬,张 陶,于 炯,刘 继,钟 磊,刘 炎
(1.新疆财经大学统计与信息学院,新疆 乌鲁木齐 830012; 2. 新疆大学软件学院,新疆 乌鲁木齐 830008; 3. 新疆医科大学医学工程技术学院, 新疆 乌鲁木齐 830011; 4.清华大学软件学院, 北京 100084)
适应节能与异构环境的MapReduce数据布局策略*
廖 彬1,2,张 陶3,于 炯2,刘 继1,钟 磊1,刘 炎4
(1.新疆财经大学统计与信息学院,新疆 乌鲁木齐 830012; 2. 新疆大学软件学院,新疆 乌鲁木齐 830008; 3. 新疆医科大学医学工程技术学院, 新疆 乌鲁木齐 830011; 4.清华大学软件学院, 北京 100084)
大数据处理过程中产生的高能耗问题亟待解决,尤其是在数据量规模剧增的背景下。在对已有数据布局策略存在问题分析的基础上,分析了与基于存储区域划分的节能模式及与异构HDFS集群的不适应、数据块切分算法不灵活、存储节点选择的随机性等几个方面的问题,继而提出面向节能的MapReduce数据布局策略。首先,新策略适应将集群划分为不同存储区域(Active-Zone与Sleep-Zone)的节能模式;其次,新策略对传统的数据块数计算方法进行了改进,提出作业截止时间约束下的最小任务数计算方法确定数据块数量;最后,新的存储策略增加了对异构集群环境的适应能力,并能根据不同的作业类型进行存储节点的选择。实验结果表明:新的数据布局策略能够适应异构集群环境,达到减小MapReduce作业能耗的目的。
绿色计算;MapReduce;异构环境; 数据布局
随着云计算、物联网、移动互联网等技术的不断发展,数据正以前所未有的速度在不断增长和积累。数据从简单的处理对象开始转变为一种基础性资源,如何更好地管理和利用大数据已经成为普遍关注的话题,同时大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战[1]。MapReduce是最流行的大数据计算模式[2],而MapReduce对大数据的分析与处理离不开底层的分布存储系统提供的数据存储服务,目前比较著名的分布存储系统有Google的GFS (Google File System, 谷歌分布式文件系统)[3], HDFS (Hadoop Distributed File System, Hadoop分布式文件系统)[4]、Lustre、MooseFs以及清华大学自主研发的CarrierFs等。其中GFS管理着Google公司百万服务器上的海量数据,基于GFS的分布式数据库BigTable支撑着Google搜索、地图、社交网络等服务[5]。HDFS作为Hadoop底层分布式文件系统,由于能够部署在通用平台上,并且具有可扩展性(Scalable)、低成本(Economical)、高效性(Efficient)与可靠性(Reliable)等优点使其在分布式计算领域得到了广泛运用,并且已逐渐成为工业与学术届事实上的海量数据并行处理标准[6]。
据文献[7]统计,2007年全球数据量达到281 EB,而2007年到2011年这5年时间内,全球数据量增长了10倍。数据量的高速增长伴随而来的是存储系统规模的不断扩大,这使得运营成本不断的提高,其成本不仅包括硬件、机房、冷却设备等固定成本,还包括IT设备与冷却设备的电能消耗等其它开销。并且,系统的高能耗将导致过量温室气体的排放并引发环境问题。据文献[8]统计,目前IT领域的二氧化碳排放量占全球的2%,而到2020年这一比例将翻番。2008年路由器、交换机、服务器、冷却设备、数据中心等互联网设备总共消耗8 680亿度电,占全球总耗电量的5.3%。纽约时报与麦肯锡经在《纽约时报》上发表了“Power, pollution and the Internet”[9],调查显示全球的数据中心总用电量约为3 000亿W,相当于30座核电厂的出电量,而巨大的能耗中却只有6%~12%的能耗被用于相应用户的请求。事实上,在能源价格上涨、数据中心存储规模不断扩大的今天,高能耗已逐渐成为制约大数据快速发展的一个主要瓶颈[1]。
已有对MapReduce的数据布局研究工作的目的大多以提高MapReduce作业的执行效率为首要目标,并没有考虑到能耗因素。本文在对已有数据布局策略深入研究的基础上,总结了与基于存储区域划分的节能模式及与异构HDFS集群的不适应、数据块切分算法不灵活、存储节点选择的随机性等几个方面的问题;针对以上问题分别提出了对应的解决方案。
1 相关工作
从2012 -2014 年Gartner 公布的技术发展趋势报告中可以看出,绿色IT 技术已经成为十大IT关键技术之一。通过优化数据布局策略提升系统能耗效率属于节能的分布式存储系统研究方向之一。所以,本文首先将分布式存储系统的节能研究进行简要介绍,继而针对具体的数据布局相关工作进行阐述。
将分布存储系统中的能耗优化问题根据研究内容进行划分,可分为基于硬件的节能与基于调度的节能两个方面[10]。基于硬件的节能方法主要通过低能耗高效率的硬件设备或体系结构,对现有的高能耗存储设备进行替换,从而达到节能的目的。基于硬件的节能方法效果立竿见影,且不需要复杂的能耗管理组件;但是对于已经部署的大规模应用系统,大批量的硬件替换面临成本过高的问题。基于调度的节能通过对存储资源的有效调度,在不影响系统性能的前提条件下将部分存储节点调整到低能耗模式(如:休眠、降频等),以达到节能的目的。由于不需要对现有硬件体系进行改变,基于调度的节能方法是目前分布式存储节能技术的研究热点。当前,基于调度的节能研究主要集中在基于节点调度与数据调度两方面。节点调度主要研究如何选择存储系统中的部分节点或磁盘为上层应用提供数据服务,并让其它节点进入低能耗模式以达到降低能耗的目的。节点调度中被关闭节点的选择与数据调度技术紧密相关,而目前已有的数据调度技术主要有基于静态数据放置、动态数据放置与缓存预取三种。其中基于静态数据放置的数据调度根据固定的数据放置策略将数据存储到系统中各节点上后,将不再改变其存储结构[11-15]。基于动态数据放置的数据调度根据数据访问频度动态调整数据存放的位置,将访问频度高与频度低的数据迁移到不同磁盘上,对存储低频度数据的磁盘进行节能处理以降低系统能耗[16-20]。基于缓存预取的数据调度借鉴内存中的数据缓存思想,将磁盘中的数据取到内存或其他低能耗辅助存储设备并使原磁盘进入低能耗模式以此达到节能的目的[21]。
研究MapReduce数据布局策略方面,已有工作主要有CoHadoop、Hadoop++及CHMJ[22-25]。CoHadoop解决了Hadoop无法把与作业相关的数据定位到同一个节点集合下的性能瓶颈,是对Hadoop的轻量级扩展,目的是使得应用层能控制数据的存储。CoHadoop提高了索引(Indexing)、聚合(Grouping)、聚集(Aggregation)、纵向存储(Columnar Storage)、合并(join)以及Sessionization等操作的效率。Hadoop++改进思路与CoHadoop类似,它将同一个作业产生的两个数据文件放置在一起;但是当有新文件写入系统的时,系统需要对数据进行重新组织。CHMJ设计了多副本一致性哈希算法,将具有连接关系的表根据其连接属性的哈希值在机群中进行分布,在提升连接查询处理中数据本地性的同时,也保证了数据的可用性。并且,CHMJ在多副本一致性哈希数据分布的基础上,提出了HashMapJoin 并行连接查询处理算法,有效地提高了连接查询的处理效率。以上对MapReduce的数据布局研究工作的目的都是以提高MapReduce作业的执行效率为首要目标,并没有考虑到能耗因素,这是本文与已有工作的最大不同之处,针对已有布局策略有可能导致的能耗问题,本文在第3章进行了详细阐述。本文研究节能的MapReduce数据布局策略,主要做了如下几个方面的工作。
1) 归纳分析了已有的数据布局策略存在:不适应基于存储区域划分的节能模式及异构的HDFS集群环境,数据块切分算法缺乏灵活性,存储节点选择的存在随机性等问题。
2) 通过返回节点状态矩阵中处于活动状态的节点,对通过将RACK划分为Active-Zone与Sleep-Zone存储区域的节能模式进行了适应。
3) 当作业具有截止时间约束时,通过对MapReduce计算原理及公式的推导,得到了任务截止时间约束下的最小任务计算方法,从而可以有效的确定数据布局前的数据块的切分数量(即Map任务的数量)。
4) 已有方法采用平均主义及随机方法确定数据块的大小及存储位置,不能很好的适应异构集群及不同MapReduce作业的特点。异构集群环境下,本文对各异构节点执行不同MapReduce作业类型的计算能力进行评估,提出了适应异构集群的数据块大小切分方法及适应不同作业类型的存储节点选择方法。
2 已有数据布局策略存在的问题
MapReduce任务执行前首先要将任务处理的数据存储到HDFS中,HDFS提供了分布、高效的数据存储及访问能力。数据文件被切分成固定大小的数据块(Data Block)分布的存储到DataNode节点中,其中数据块的大小是可配置的(默认大小为64 MB)。HDFS中数据文件只能一次写入,并不允许对已经写入的数据块进行修改。NameNode节点内存中维护着文件系统的目录信息,即维护着活动的DataNode节点列表及每个DataNode节点中所有的数据块信息(BlockMap)。HDFS通过副本机制达到容错及故障恢复的目的,系统默认副本系数为3,并采用基于机架感知的数据块存储策略 (如图1所示)将数据块布局到HDFS系统中[26]。

图1 基于机架感知的数据块存储策略Fig.1 The rack-aware block replica placement policy in HDFS
机架感知的数据块存储策略首先将数据块的第1个副本存放在创建该数据块的本地DataNode上(前提条件是本地DataNode节点空间足够),此策略叫就近写(Write Affinity);第2个副本会被存储到同第1个副本不同机架(Rack)的DataNode上;第3个副本会被存储到同第2个副本同机架但不同DataNode的节点中。由此可见,基于机架感知的数据块存储策略使得数据块的存储位置具有较大的随机性[27],这种随机的布局策略虽然能够均衡系统的负载,但是同样存在以下几个方面的问题。
2.1 与基于存储区域划分的节能模式的不适应
文献[27]中将存储区域划分为Active-Zone与Sleep-Zone,并适时的将Sleep-Zone中的节点进行休眠处理以达到节能的目的,基于机架感知的数据块存储策略在进行数据布局时并没有对节点的区域(Active-Zone与Sleep-Zone)进行区分对待,致使不能很好的适应节能模式的需求。
2.2 与异构HDFS集群的不适应
现有的数据放置策略并没有考虑到系统中数据存储节点的异构性问题,基于机架感知的数据块存储策略认为HDFS集群中所有节点的服务能力相同,数据按照平均主义的原则进行切分、布局。在这种布局策略下,服务能力强的节点能够较早的完成任务,而服务能力较弱的节点则需要较长的时间完成任务,将引发以下两种情况:第一,当快任务能够容忍慢任务时,将造成“任务等待”,即早完成的任务等待还未完成的任务。第二,当块任务不能容忍慢任务时,将引发Hadoop的推测执行(Speculative Execution)机制,推测执行机制是为了防止运行速度慢的任务影响作业的整体执行速度,根据推测算法推测出“拖后腿”的任务,并为该任务启动一个备份任务,并最终选用最先成功运行完成任务的计算结果作为最终结果。由此可见,不论是那种情况,都会造成资源的浪费。
2.3 数据块切分算法不灵活
Hadoop中利用类InputFormats来定义文件是如何被切分并由Map任务使用,InputFormats为用户提供了一种扩展的手段,用来通过组装定制化的分片来将一些分布的数据提供给Map任务。当任意MapReduce任务启动的时,数据文件会被InputFormats切分为多个分片(splits),每一个分片对应了MapReduce程序中的一个Map任务。默认情况下,不同的FileInputFormat实现将一个文件分成64 MB的chunk(HDFS的默认块大小)。Hadoop调度器尽量将Map任务调度给那些包含分片的本地副本的Datanode。大多数情况下,split与block呈一一对应关系,数据块block与split对应关系如图2所示。

图2 数据块block与split之间的对应关系Fig.2 The relationship between data block and split
已有的数据块大小只能由固定的配置参数进行设置,并不能很好的适应不同MapReduce任务的特点,更不能根据作业的完成时间需求及集群中各节点的计算能力的不同而进行灵活的设置。
2.4 存储节点选择的随机性
基于机架感知的数据块存储策略在选择存储节点时具有较大的随机性,不能很好的进行作业类型与节点类型之间的匹配。一方面,不同MapReduce作业对CPU、内存、磁盘、网络等资源的需求不同,而异构HDFS集群环境下不同节点之间的CPU、内存、磁盘、网络等资源的服务能力不尽相同;另一方面,MapReduce作业调度时的本地优先策略容易导致部分任务在不合适的节点上执行(由存储节点选择的随机性造成),从而影响作业的整体进程。由此可见,必须为不同的MapReduce作业类型所处理的数据选择合适的存储节点,是适应节能的数据布局算法必须考虑的问题。
针对以上问题,本文第3节提出面向节能的MapReduce数据布局算法对问题予以解决。
3 面向节能的MapReduce数据布局策略
3.1 面向节能的数据布局策略总体流程
如图3所示为面向节能的MapReduce数据布局策略流程图。

图3 面向节能的MapReduce数据布局策略流程图Fig.3 The flow chart for energy saving MapReduce data layout strategy
首先,判断是否处在节能模式;如果处于节能模式,则接着判断存储区域的划分状态;如果不处于节能模式,则采用基于机架感知的数据布局策略进行数据的存储。当处于节能存储区域划分模式时,返回Active-Zone区域中存储节点(参见3.2节);否则,返回集群中所有节点。当作业具有截止时间约束时,通过3.3节中提出的任务截止时间约束下的最小任务计算方法确定数据块的切分数量;否则,按照系统配置参数确定数据块数。当系统为异构集群时,通过3.4节中提出的适应异构集群的数据大小切分方法确定具体数据块的大小;如果系统为同构集群,数据块的大小由系统参数配置确定。最后,数据块的存储节点根据3.5节适应不同作业类型的节点选择算法进行确定。
3.2 支持节能存储区域划分的数据布局
我们的早期工作[27]将RACK划分为Active-Zone与Sleep-Zone两个存储区域,根据不同数据的访问频率与规律计算活动因子以配置数据的存储区域,通过数据中心负载规律适时对Sleep-Zone区域中的服务器进行休眠处理以达到节能的目的。基于机架感知的数据块存储策略在进行数据布局时并没有对节点的区域(Active-Zone与Sleep-Zone)进行区分对待,致使不能很好的适应节能模式的需求。在通过划分Active-Zone与Sleep-Zone存储区域节能模式下,不是所有的节点都处于可用状态,必须返回处于活动状态的节点,即返回节点状态矩阵[27](式1)中Smn=1(1≤m≤sm,1≤n≤i)的节点[27]
(1)
3.3 作业截止时间约束下的最小任务数
通过4.2节任务数对任务完成时间及能耗的影响实验我们发现:首先,理论上任务数越大作业完成时间越小,但实际上任务数目与任务完成时间之间并不呈线性关系。当任务数量增加到某临界点时,作业完成时间并不会因为任务数量的增加而减小;其次,随着任务数量的不断增大,作业能耗不断的增加;即完成相同作业,任务数越大,完成该任务能耗越大。由于MapReduce作业大多受到任务完成时间的约束,所以本节主要对满足作业截止时间约束下的MapReduce作业最小分解任务数进行建模,试图通过减小任务数量达到节能的目的。
设某MapReduce作业J被初始化为NM个Map任务与NR个Reduce任务,并且这些任务在拥有RM个Map任务执行资源(mapslot)与RR个Reduce任务执行资源(reduceslot)的集群中运行。在数据量大小与节点计算能力确定的情况下,能够通过表1对Map任务完成时间进行预测,但由于MapReduce任务由Map阶段,Shuffle&Sort阶段与Reduce阶段组成,Shuffle&Sort阶段与Reduce阶段的任务完成时间无法进行直接计算。所以,下面通过任务采样的方法来预测作业J的完成时间,其主要步骤如下:
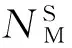

(2)
(3)
4)记录每个采样Reduce任务j的完成时间TR(j)与处理数据量大小DR(j)。利用得到的采样数据建立Reduce任务输入数据量与完成时间的函数关系
(4)
其中,式(2)-(4)中的C表示任意节点dnij处理作业J时的计算能力(其值可通过训练获得)。
5)计算Map阶段的采样任务平均完成时间为
(5)
6)计算Shuffle&Sort阶段的采样任务平均完成时间为
(6)
7)计算Reduce阶段的采样任务平均完成时间为
(7)
基于采样任务的运行结果,可预测作业J在Map阶段的平均完成时间为
(8)
同样方法,可预测Reduce阶段(包含Shuffle&Sort阶段)任务的平均完成时间为
(9)
值得注意的是,由于作业J在集群中运行Shuffle&Sort的第一次操作与Map阶段有重叠部分,所以式(8)中减去了重叠部分的时间。
设Tavg表示作业J的总完成时间,在式(8)与式(9)的基础上,总完成时间可用式(10)进行计算
(10)
对式(10)进行变换,可得到式(11)
(11)
(12)
本文提出截止时间约束下的最小资源分配的计算方法,即是RM与RR值最小,通过最优化的办法,建立最优化目标函数为
(13)
利用拉格朗日乘数法求函数f(RM,RR)最小值为
(14)

(15)
由于MapReduce作业的类型是有限的,相同类型的作业Map、Shuffle&Sort与Reduce的数据量与完成时间的函数(式(5)-(7))相同。所以对于相同类型的MapReduce作业,函数式(5)-(7)具有可重用性。即通过大量的训练与测试,可确定不同类型作业的处理数据量与完成时间之间的函数关系。再则,通过3.4节的方法可确定任意节点dni的处理作业J时的计算能力。所以,式(15)可解。同样,当参数RM与RR值已知时,可利用式(15)确定参数NM与NR的值,即当可用Map资源slot及Reduce资源slot数已知的情况下,可对满足作业完成时间deadline约束条件下的最小Map任务数及Reduce任务数进行计算。而本文中则主要取Map任务数的值,因为Map任务数决定了数据布局过程中数据块的数量。
3.4 适应异构集群的数据大小切分
异构环境中的数据放置策略应当适应不同节点的计算能力之间的差异,数据块的大小应与存储该数据块节点的数据处理能力成正比。这样的数据块切分原则可以有效的解决异构集群中各个节点处理能力的差异性问题,保证同一个作业的多个并行数据处理任务尽量在相同的时间内完成,在有效地缩短等待时延的同时,减小“MapReduce任务等待能耗”。
设Cij表示节点dni处理任务taskj时的计算能力,那么Cij可表示为
(16)
其中Timeij表示节点dni完成任务taskj所花的时间,DataVolij表示任务所处理数据量的大小。不论是异构还是同构Hadoop集群,集群每个节点对于不同作业类型的计算能力可通过大量的训练得到,本文中设Cij值为已知。将训练后不同节点处理不同任务时的计算能力用表1进行记录。
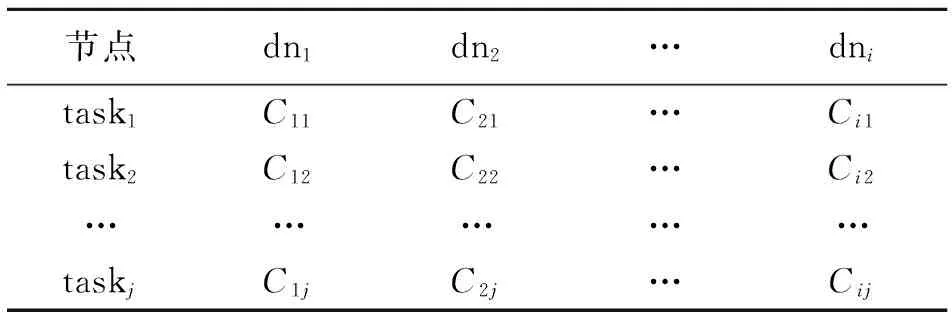
表1 节点计算能力记录表
设某MapReduce作业J被分解为n个Map任务(或由3.3节中任务截止时间约束下的最小切分方法确定),每个Map任务映射到具有不同计算能力的节点资源slot上。为使这n个Map任务完成时间均衡并缩短等待时延,即适应异构的集群环境,数据的切分规则应满足(16)式
(17)
其中C1,C2,...,Cn与D1,D2,...,Dn分别表示对应节点计算能力与被分配到的数据量,而D表示作业J需要处理的总数据量。
3.5 适应不同作业类型的存储节点选择
不同MapReduce作业对CPU、内存、磁盘、网络等资源的需求不同,而异构HDFS集群环境下不同节点之间的CPU、内存、磁盘、网络等资源的服务能力不尽相同。解决已有数据布局策略的随机性,须为不同的MapReduce作业类型所处理的数据选择合适的存储节点(任务执行节点)。
某MapReduce任务数据块存储点选择由式(18)与式(19)计算结果共同决定,其中式(19)为MapReduce任务对节点的评价函数,式(19)为节点选择函数。
(18)

由式(19)选择服务评价值最高的节点为数据存储节点。
Max(Capacitydn1,Capacitydn2,...,Capacitydny)
(19)
以上方法需要进行大量的计算且参数难以获得,也可通过3.4节中提出的方法,通过大量的训练得到表1所示的数据记录形式,对与不同的MapReduce作业可通过查询已有数据,并通过式(19)决定存储节点。
4 实验及结果分析
4.1 实验环境配置
为了对本文提出的MapReduce数据布局策略进行实验分析,项目组搭建了拥有22个节点的Hadoop集群;其中NameNode与SecondNameNode分别独立为一个节点,其余20节点为DataNode(5RACK×4DataNode)。实验环境拓扑结构如图4所示。

图4 实验环境拓扑结构图Fig.4 Topology diagram of experimental environment管理节点2个,DataNode节点20个
为了控制实验过程中的Map任务数量,达到控制实验数据的统计与计算量的目的,特将数据块默认的分块大小配置为128MB,即dfs.block.size=128MB。单个DataNode节点上Map与Reduce任务Slot资源槽数设置为1,即配置项为
mapred.tasktracker.map.tasks.maximum=1
mapred.tasktracker.reduce.tasks.maximum=1
能耗数据测量方面,实验采用北电电力监测仪(USB智能版),数据采样频率设置为1s/次,各节点能耗数据(包括瞬时功率、电流值、电压值、能耗累加值等)可通过USB接口实时地传输到能耗数据监测机上,实现能耗数据的收集。实验总体环境描述见表2。

表2 总体实验环境描述
4.2 任务数对任务完成时间及能耗的影响
本实验采用Terasort作业,运行过程中对Map与Reduce任务进行不同的设置,记录不同条件下作业的执行时间及能耗。其中按数据量的不同分为3组:第一组,数据量为1 907.4MB并设置Map数量为40,每个split大小为47.685MB;第二组,数据量为2 861MB并设置Map数量为60,每个split大小为47.683MB;第三组,数据量为4 768.4MB并设置Map数量为80,每个split大小为59.605MB。MapReduce任务分解数与作业完成时间之间的关系如表3所示。

表3 任务数与作业完成时间之间的关系
从图5可以看出:三组实验作业完成时间都随着任务数的增大而减小,说明可以通过适当的增大任务数量来满足作业的deadline需求。另一方面,理论上任务数越大作业完成时间越小,但实际上任务数目与任务完成时间之间并不呈线性关系。当任务数量增加到某临界点时,作业完成时间并不会因为任务数量的增加而减小(减小效果不明显)。

图5 任务数与作业完成时间之间的关系Fig.5 The relationship between task number and job complete time
由图6趋势与表4中的数据可以看出,随着任务数量的不断增大,作业能耗不断的增加;即完成相同作业,任务数越大,完成该任务能耗越大。这是因为当任务数较多时,任务之间的数据传输成本增加;任务之间的关联变得复杂,任务之间的协调成本增加,更多的任务启动操作及任务完成后的清理动作,以上几方面都导致了能耗的增加。图6表明:作业被分解的任务数越少,完成相同作业所需能耗越小,作业能耗利用率越高;但是作业具有截止时间QoS约束时,需满足作业完成时间deadline约束需求。利用3.4节提出的任务截止时间约束下的最小任务切分方法能够计算出能耗最优的作业分解方案,即能够在满足作业完成时间约束前提条件下,最小化作业执行能耗。
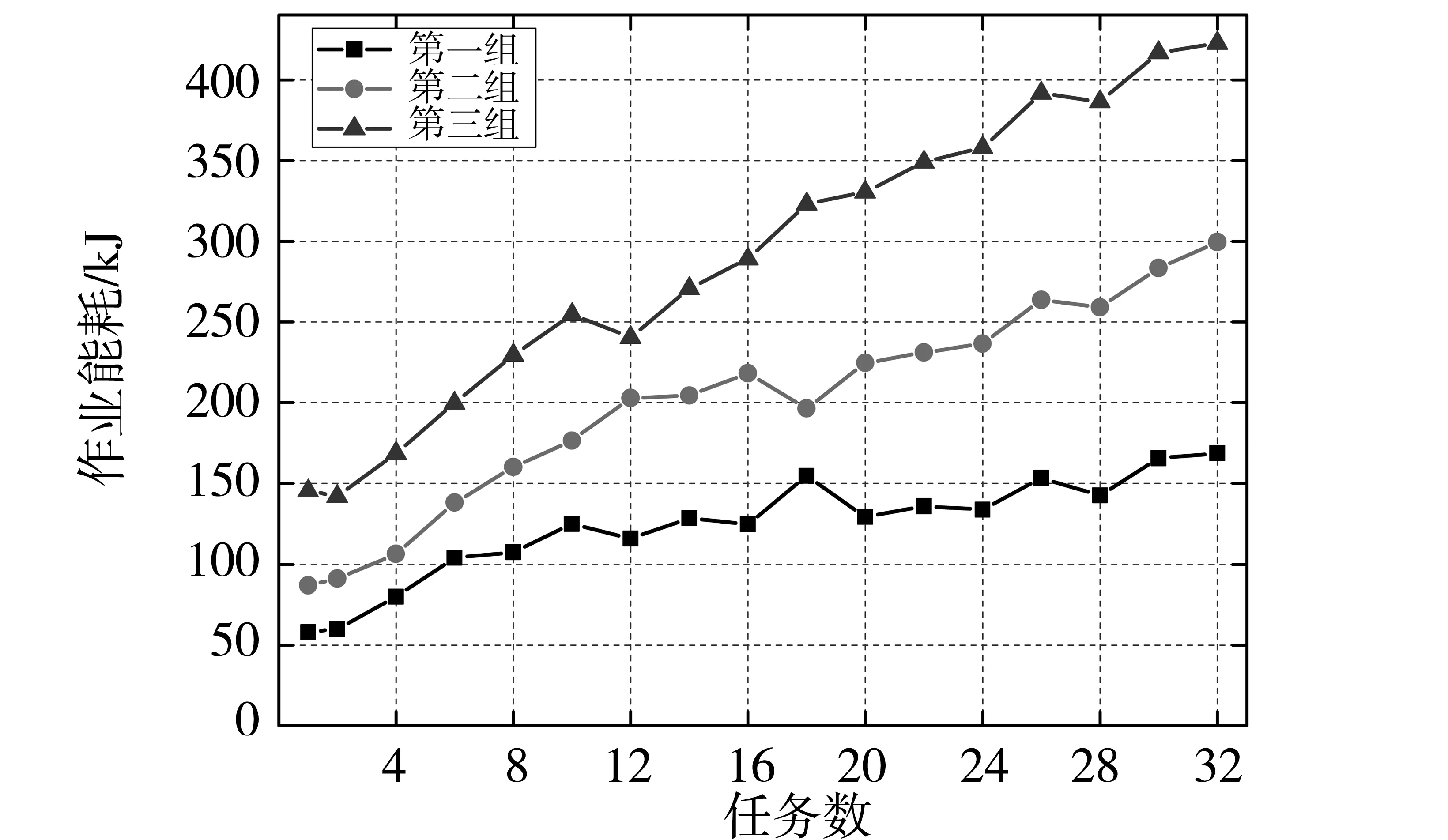
图6 任务数与作业能耗之间的关系Fig.6 The relationship between task number and energy consumption
4.3 综合对比实验
为构造出异构集群环境,本实验将一组RACK中的4台机器替换为性能较差的节点(配置为单核IntelPentium4 1.5GHz,512MB内存及40GB硬盘),即本实验中集群环境由两种不同配置的节点组成(设配置高节点类型为A,配置低节点类型为B)。将表5中配置的MapReduce作业运行50次,记录各作业的运行结果,整理出不同节点类型对于不同作业的计算能力,即3.4节中节点计算能力记录表(表1)。

表4 任务数与作业能耗之间的关系

表5 作业类型说明
实验结果如表6所示。
数据布局阶段,首先按照机架感知的数据块布局策略将6种不同的作业数据进行分布存储,数据块大小相同,最后记录各作业的运行时间及能耗;再次,按照本文中提出的作业截止时间约束下的最小任务数确定Map与Reduce的任务数量,再适应异构环境下的数据切分(3.4节)及存储节点选择方法(3.5节)进行数据的布局,记录各作业的运行时间及能耗。两种布局策略下6种作业(作业配置参数如表5所示)的能耗及完成时间(实验20次平均值)对比如表7所示。
如表7所示,与异构环境下原数据布局策略(机架感知的数据布局策略)相比较,本文的数据布局策略能够分别提高WordCount、TeraSort、NuthIndex、K-means、PageRank及Bayes作业完成时间24.5、23.6、38.4、25.7、47.4及71.9s,提升作业完成时间3.55%、5.00%、6.22%、7.59%、10.14%和17.17%;分别节能33.31、34.41、42.29、33.47、59.7和76.14kJ,节能效率分别为3.650%、5.185%、5.186%、7.723%、10.423%和15.100%。通过分析可以发现本文提出的数据布局策略对于WordCount、TeraSort、NuthIndex及K-means四种作业完成时间及节能效率提升有限(5%左右),而PageRank及Bayes有较为明显的提升(10%以上)。分析PageRank与Bayes作业的执行过程,发现Reduce任务需要等待所有Map任务完成才能开始,造成等待时延较长;这是由于PageRank与Bayes作业的Map与Reduce的任务存在强的先后依赖关系,Reduce任务必须等待所有的Map任务完成后才能开始。而与PageRank与Bayes作业不同的是,WordCount、TeraSort、NuthIndex及K-means四种作业完成部分Map任务后Reduce任务就能够开始执行,所以等待时延较短。

表6 作业Map与Reduce任务的平均功耗及计算能力
1)单位为MB/s;2)单位为page/s;3)单位为sample/s
表7 不同数据布局策略下作业完成时间及能耗对比
1)机架感知策略;2)本文策略
5 结论及下一步工作
在能源价格上涨、数据中心存储规模不断扩大的今天,高能耗已逐渐成为制约大数据快速发展的一个主要瓶颈,所以研究节能的MapReduece数据布局策略具有重要意义。已有对MapReduce的数据布局研究工作的目的大多以提高MapReduce作业的执行效率为首要目标,并没有考虑到能耗因素。本文在对已有数据布局策略深入研究的基础上,总结了与基于存储区域划分的节能模式及与异构HDFS集群的不适应、数据块切分算法不灵活、存储节点选择的随机性等几个方面的问题;针对以上问题分别提出了对应的解决方案。首先,新策略适应将集群划分为Active-Zone与Sleep-Zone存储区域的节能模式;其次,新策略对传统的数据块数计算方法进行了改进,提出作业截止时间约束下的最小任务数计算方法确定数据块数量;最后,新的存储策略增加了对异构集群环境的适应能力,并能根据不同的作业类型进行存储节点的选择。为了对新的数据布局算法的有效性进行验证,本文搭建了异构集群环境,并对不同作业的完成时间及能耗进行了测量,通过实验数据表明:新的数据布局策略能够适应异构集群环境,达到减小MapReduce作业能耗的目的(但不同作业之间存在着差异)。
下一步主要工作是研究MapReduce作业能耗模型。MapReduce能耗模型是将来开发MapReduce作业能耗监控及优化软件的理论基础及关键技术,因为能耗模型能够实现在作业执行前对能耗进行预测,执行过程中为节能调度系统提供调度依据,执行后对作业进行能耗计算。
[1] 孟小峰,慈祥. 大数据管理: 概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1):146-149.
[2]DEANJ,GHEMAWATS.MapReduce:Simplifeddataprocessingonlargeclusters[C]∥ProceedingsoftheConferenceonOperatingSystemDesignandImplementation(OSDI),NewYork:ACM, 2004: 137-150.
[3]GHEMAWATS,GOBIOFFH,LEUNGST.Thegooglegilesystem[C]∥Proceedingsof19thACMSymposiumonOperatingSystemPrinciples,NewYork:ACM, 2003:29-43.
[4]BORTHAKUD.Thehadoopdistributedfilesystem:Architectureanddesign[EB/OL]. (2007-07-01) [2011-2-12],http:∥hadoop.apache.org/common/docs/r0.18.2/hdfs_design.pdf.
[5]CHANGF,DEANJ,GHEMAWATS,etal.Bigtable:ADistributedStorageSystemforStructuredData[C]∥Proceedingsofthe7thSymposiumonOperatingSystemsDesignandImplementation(OSDI),Seattle,WA,USA, 2006: 205-218.
[6] 王鹏,孟丹,詹剑锋,等. 数据密集型计算编程模型研究进展[J]. 计算机研究与发展, 2010, 47(11): 1993-2002.
[7]GANTZJ,CHUTEC,MANFREDIZA,etal.Thediverseandexplodingdigitaluniverse:Anupdatedforecastofworldwideinformationgrowththrough2011 [EB/OL]. [2013-5-25],http:∥wwww.ifap.ru/library/book268.pdf.
[8]GlobalActionPlan.Aninefficienttruth[EB/OL].Globalactionplanreport, 2007 [2011-02-12],http:∥globalactionplan.org.uk.
[9]TIMESNY.Power,PollutionandtheInternet[EB/OL]. [2013-5-20],http:∥www.nytimes.com/2012/09/23/technology/data-ceneters-waste-vast-amounts-of-energy-belying-industry-image.html.
[10] 于炯,廖彬,张陶,等. 云存储系统节能研究综述[J]. 计算机科学与探索, 2014, 8(9): 1025-1040.
[11]GREENANKM,LONGDDE,MILLEREL,etal.ASpin-upSavedisEnergyEarned:AchievingPower-Efficient,Erasure-CodedStorage[C]∥Proceedingsofthe4thWorkshoponHotTopicsinSyetmsDependability(HotDep‘08),SanDiego,USA, 2008.
[12]WEDDLEC,OLDHAMM,QIANJ,etal.Agear-shiftingpower-awareraid[J].ACMTransactionsonStorage, 2007, 3(3): 1553-1569.
[13]LID,WANGJ.ConservingenergyinconventionaldiskbasedRAIDsystems[C]∥Proceedingsofthe3rdInternationalWorkshoponStorageNetworkArchitectureandParallelI/Os(SNAPI’05).Piscataway,NJ:IEEE, 2005: 65-72.
[14]YAOXY,WANGJ.Rimac:Anovelredundancy-basedhierarchicalcachearchitectureforenergyefficient,highperformancestoragesystems[C]∥Proceedingsofthe1stACMSIGOPS/EuroSysEuropeanConferenceonComputerSystems(EuroSys'06),Leuven,Belgium, 2006.NewYork,USA:ACM, 2006: 249-262.
[15]PINHEIROE,BIANCHINIR,DUBNICKIC.Exploitingredundancytoconserveenergyinstoragesystems[C]∥ProceedingsofthejointinternationalconferenceonMeasurementandmodelingofcomputersystems(SIGMetrics’06/Performance’06),SaintMalo,France, 2006.NewYork,USA:ACM, 2006: 15-26.
[16]COLARELLID,GRUNWALDD.Massivearraysofidledisksforstoragearchives[C]∥Proceedingsofthe2002ACM/IEEEconferenceonSupercomputing(SC’02),Baltimore,USA, 2002.LosAlamitos,CA,USA:IEEEComputerSocietyPress, 2002: 1-11.
[17]NARAYANAND,DONNELLYA,ROWSTRONA.Writeoff-loading:Practicalpowermanagementforenterprisestorage[J].ACMTransactionsonStorage, 2008, 4(3): 253-267.
[18]STORERM,GREENANK,MILLERE,etal.Pergamum:Replacingtapewithenergyefficient,reliable,disk-basedarchivalstorage[C]∥Proceedingsofthe6thUSENIXConferenceonFileandStorageTechnologies(2008),SanJose,USA, 2008.Berkeley,CA,USA:USENIXAssociation, 2008: 1-16.
[19]ZHUQB,CHENZF,TANL,etal.Hibernator:Helpingdiskarrayssleepthroughthewinter[C]∥Proceedingsofthe20thACMSymposiumonOperatingSystemsPrinciples(SOSP’05),Brighton,UK, 2005.NewYork,NY,USA:ACM, 2005: 177-190.
[20]VASICN,BARISITSM,SALZGEBERV.Makingclusterapplicationsenergy-aware[C]∥Proceedingsofthe1stWorkshoponAutomatedControlforDatacentersandClouds(ACDC’09),Barcelona,Spain, 2004.NewYork,NY,USA:ACM, 2009: 37-42.
[21]ZHUQB,DAVIDFM,DEVARAJCF,etal.Reducingenergyconsumptionofdiskstorageusingpower-awarecachemanagement[C]∥Proceedingsofthe10thInternationalConferenceonHigh-PerformanceComputerArchitecture(HPCA’04),Madrid,Spain,Piscataway,NJ,USA:IEEE, 2004: 118-129.
[22]MOHAMEDY,TIANYY,OZCANF,etal.CoHadoop:flexibledataplacementanditsexploitationinHadoop[C]∥ProceedingsoftheVLDBEndowmentVLDB2011,2011, 4(9): 575-585.
[23]DITTRICHJ,QUIANE-RUIZJA,JINDALA,etal.Hadoop++:Makingayellowelephantrunlikeacheetah(withoutitevennoticing) [C]∥ProceedingsofthePVLDB2010,2010,3(1/2):518-529.
[24]ZHAOYR,WANGWP,MENGD,etal.Adatalocalityoptimizationalgorithmforlarge-scaledataprocessinginHadoop[C]∥ProcessingsoftheISCC2012, 2012: 655-661.
[25] 赵彦荣,王伟平,孟丹,等. 基于Hadoop的高效连接查询处理算法CHMJ[J]. 软件学报, 2012, 23(8): 2023-2041.
[26] 廖彬,于炯,张陶,等. 基于分布式文件系统HDFS的节能算法[J]. 计算机学报, 2013, 36(5): 1047-1064.
[27] 廖彬,于炯,孙华,等. 基于存储结构重配置的分布式存储系统节能算法[J]. 计算机研究与发展, 2013, 50(1): 3-18.
An Energy-Efficient and Heterogeneous Environment Adaptive Data Layout Strategy for MapReduce
LIAOBin1,2,ZHANGTao3,YUJiong2,LIUJi1,ZHONGLei1,LIUYan4
(1. College of Statistics and Information, Xinjiang University of Finance and Economics, Urumqi 830012, China; 2. School of Software, Xinjiang University, Urumqi 830008, China; 3. Department of Medical Engineering and Technology, Xinjiang Medical University, Urumqi 830011, China; 4. School of Software, Tsinghua University, Beijing 100084, China)
The problem of high energy consumption producing from big data processing is an important issue that needs to be solved, especially under the background of data explosion. Based on analyzing problems of the existing data layout policy, the problems of the in adaptation of energy-saving mode based on storage area division and heterogeneous HDFS cluster, the inflexibility of data block segmentation algorithm, the randomness of storage node selection, proposing a data layout strategy orienting to energy conservation are analyzed. Firstly, the new strategy divides the cluster into two different storage areas to meet the needs of saving energy: Active-Zone and Sleep-Zone; secondly, the new strategy has made improvements on traditional data block computing method, proposes a minimum number of jobs calculation method to determine the number of data blocks; at last, the new strategy can increase the adaptability of the heterogeneous cluster environment and can choose the appropriate storage nodes according to different job types. Experimental results show that the new data layout strategy can adapt to the heterogeneous cluster environment and reach the goal of reducing energy consumption for MapReduce jobs.
green computing; MapReduce; heterogeneous environment; data layout
10.13471/j.cnki.acta.snus.2015.06.011
2014-12-07 基金项目:国家自然科学基金资助项目(61562078, 61262088, 71261025);新疆财经大学博士启动基金资助项目(2015BS007)
廖彬(1986年生),男;研究方向:绿色计算、数据库系统理论及数据挖掘;E-mail:liaobin665@163.com
TP
A
0529-6579(2015)06-0055-12
