多层次数据分析
2015-05-15祁鹏年
祁鹏年
(长沙理工大学经济与管理学院,长沙 410114)
多层次数据分析
祁鹏年
(长沙理工大学经济与管理学院,长沙 410114)
对于专业的数据分析而言,一定要有很强的针对性,什么样的需求就要提供与之层次相匹配的分析结果。否则就会造成不必要的信息价值浪费,也会大大增加需求者获取信息的成本。就如何有效实现多层次的数据分析,以理论实例相结合的方式,做相应的探讨。
大数据;数据挖掘;数据分析;分布式数据库
0 引言
“In God We Trust;All Others Use Data”。在美国企业流传这样一句话:除了毫无保留地信奉上帝,其他的一切均以数据说话。这句话足以揭示数据的价值,数据将是未来世界的主宰。首先,多层次的数据分析正改变着企业做决策的模式。在海量的数据中通过不同维度的钻取,可以得到不同价值的信息,这些信息以不同比例的价值使得企业高层做出更精准的决策。其次,多层次的数据分析也改变着企业创造价值的方式,可以通过分析技术,把分析应用于每一个领域,甚至每一件事情,由分析结果可以把更多相关的领域叠加起来再分析,又将产生新的价值。所以,多层次数据分析正在为企业创造着前所未有的价值。最后,多层次的数据分析将直接改变企业对每一个客户提供价值的方式。数据分析可以帮助企业发现每一个潜在的用户群,针对不同的用户提供不同的个性化服务,无疑这将极大地提高营销效率。
1 海量数据处理流程
1.1 数据采集
数据的采集是指利用传感器、社交网络以及移动互联网等方式获得的各种类型的结构化、半结构化以及非结构化的海量数据,这是一切数据分析的基础。数据的采集需要解决分布式高速高可靠数据的采集、高速数据全映像等数据收集技术。还要设计质量评估模型,开发数据质量技术。而数据采集一般分为大数据智能感知层:主要包括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实现对海量数据的智能化识别、定位、跟踪、接入、传输、信号转换、监控、初步处理和管理等。
1.2 数据预处理
数据采集的过程本身就有会有很多数据库,但如果想达到有效分析海量数据的目的,就必将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,而且在导入基础上做一些简单的辨析、抽取、清洗等操作。①抽取:因为我们通过各种途径获取的数据可能存在多种结构和类型,而数据抽取过程可以有效地将这些复杂的数据转换为单一的结构或者便于处理的类型。以达到快速分析处理的目的。②清洗:对于海量数据而言,数据所处的价值层次不一样,就必然存在由于价值低而导致开发成本偏大的数据,还有与数据分析毫无关系的数据,而另一些数据则是完全错误的干扰项,所以对数据通过过滤“去噪”从而提取出有效数据是十分重要的步骤。
1.3 数据的存储与管理
当我们采集数据完成后,就需要将其存储起来统一管理,主要途径就是建立相应的数据库,进行统一管理和调用。在此基础上,需要解决大数据的可存储、可表示、可处理、可靠性及有效传输等几个关键问题。还需开发可靠的分布式文件系统(DFS)、能效优化的存储、计算融入存储、数据的去冗余及高效低成本的大数据存储技术;以及分布式非关系型大数据管理与处理技术、异构数据的数据融合技术、数据组织技术、研究大数据建模技术、索引、移动、备份、复制、可视化技术。
1.4 数据的统计分析
一般情况下,统计与分析主要就是利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。
1.5 数据分析与挖掘
所谓数据挖掘是指从数据库中的大量不完全的、有噪声的、模糊的、随机的实际应用数据中,揭示出隐含的、先前未知的并有潜在价值的信息的过程。与前面统计和分析过程不同的是,数据挖掘一般不会有预先设计好的主题,主要是在现有数据上面进行基于各种算法的计算,从而起到预测(Predict)的效果,从而实现一些高级别数据分析的需求。比较典型的算法有用于聚类的K-means、用于统计学习的SVM和用于分类的NaiveBayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于挖掘的算法很复杂,并且计算涉及的数据量和计算量都很大,常用数据挖掘算法都以单线程为主。
2 数据分析的8个层次
2.1 标准化报告(Standard Reports)
标准化报告作为数据分析的第一个层次,要求相对较低,主要是借助相应的统计工具对数据进行归纳总结,得出包含主要参数指标的标准化报告。类似于一个销售企业每月或者每季度的财务报表。
2.2 即席查询(Ad Hoc Reports)
用户可以通过自己的需求,灵活地选择查询条件,系统就能够根据用户的需求选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询所有的查询条件都是用户自己定义的。在面向高层的数据分析软件中,用户随意添加想要查询的指标按钮再加上相应的限制条件,就可以立即生成可视化的统计结果,不仅一目了然,而且没有任何操作难度。
2.3 多维分析(Query Drilldown)
多维分析是指对具有多个维度和指标所组成的数据模型进行的可视化分析手段的统称,常用的分析方式包括:下钻、上卷、切片(切块)、旋转等各种分析操作。以便剖析数据,使分析者、决策者能从多个角度多个侧面观察数据,从而深入了解包含在数据中的信息和内涵。上卷是在数据立方体中执行聚集操作,通过在维级别中上升或通过消除某个或某些维来观察更概括的数据。上卷的另外一种情况是通过消除一个或者多个维来观察更加概括的数据。下钻是在维级别中下降或者通过引入某个或者某些维来更细致地观察数据。切片是在给定的数据立方体一个维上进行的选择操作,切片的结果是得到了一个二维的平面数据(切块是在给定的数据立方体的两个或者多个维上进行选择操作,而切块的结果是得到了一个子立方块)。转轴相对比较简单,就是改变维的方向。
2.4 仪表盘与模拟分析(Alerts)
仪表盘用于监控一些关键指标。模拟分析是由操作者动态地加以调节的控件(如滑动块、可调旋钮、选择框等),来控制管理决策模型行为某些参数。当操作者通过控制面板对模型中的参数值或变量值进行调节时,图形中的曲线、柱形组或分析指标等要素就会发生相应的运动,而这种运动正好反映了该参数的变化对模型行为的影响,如果这种变动引起了模型中最优解或其他关键数字的变化,能够随时将关于这种变化的结论正确地显示出来。
2.5 统计分析(Statistically Analysis)
我们知道概率论是数理统计的基础,数理统计是在其基础上研究随机变量,并应用概率论的知识做出合理的估计、推断与预测。概率论中讨论的各种分布在数理统计中作为统计模型来分析处理带有随机误差的数据。典型的数理统计方法有参数估计、假设检验和回归分析。而统计分析主要是对用户所关注的问题进行推断、预测和控制的分析方法。具体可以分为以下三方面:
①描述统计:主要是集中趋势、离散程度、分布形状等,统计图(方图、箱线图、散点图等);
②数据的分类汇总;
③基础统计分析:方差分析、时间序列分析、相关和回归分析、(主成分)因子分析等统计分析方法。
2.6 预测(Forecasting)
在统计分析和数据挖掘领域,对未来的预测已经有了很多数学模型以及解决具体问题的相关算法。其核心思想便是从历史数据中找出数据的发展模式,然后以这些模式为支点,就可以对未来进行预测。
2.7 预测模型(Predictive Modeling)
随着数据分析学家对数据挖掘技术的不断探索,出现了很多预测模型以及与之相对应的算法,但是很难确定某个模型是最精确的,因为不同的领域,不同的条件,对应的预测模型是不一样的,所以没有统一化的最优模型,只存在有选择性的最优模型。下面介绍几种典型的预测模型。
①回归模型:回归模型可以分为一元线性回归模型和多元线性回归模型。一元线性回归模型可表示为yt=b0+b1xt+ut,该式表示变量yt和xt之间的真实关系。其中yt称作被解释变量(或相依变量、因变量),xt称作解释变量(或独立变量、自变量),ut称作随机误差项,b0称作常数项(截距项),b1称作回归系数。b0+b1xt是非随机部分,ut是随机部分。而在很多情况下,回归模型必包含两个或更多自变量才能够适应地描述经济现象各相关量之间的联系,这就是多元线性回归模型需要解决的问题,其一般形式为:Y=a+b1X1+b2X2+…+bmXm,式中X1、X2、…、Xm是这个多元回归问题的m个自变量,b1、b2、…、bm是回归方程对应于各自变量的系数,又称偏回归系数。
②贝叶斯网络:贝叶斯网络是基于概率推理的数学模型,而概率推理是通过一些产量的信息来获取其他概率信息的过程。贝叶斯网络会建立一个有向无环图和一个概率表集合,有向无环图中的每一个节点便是一个随机变量,而有向边表示随机变量间的条件依赖,条件概率表中的每一个元素对应有向无环图中唯一的节点,存储此节点对其所有直接前驱节点的条件概率。贝叶斯网络是为了解决不定性与不完整性问题而提出的,在多个领域中获得广泛应用。
③基于时间序列分析的指数平滑模型
在时间序列分析中指数平滑模型是最灵活和准确的方法,在经济领域也被证明是最有效的预测模型。在不同的时间序列下,指数平滑模型可以分为简单指数平滑法、带有趋势调整的指数平滑法、带有阻尼趋势的指数平滑法、简单季节指数平滑法、带有趋势和季节调整的指数平滑法五种不复杂度的模型。
2.8 最优化(Optimization)
因为优化问题往往可以带来巨额的收益,通过一系列可行的优化,可以使收益得到显著提高。所谓最优化就是从有限或者无限种可行的方案中选取最优的方案。如果可以通过简单的评判,就可以确定最优方案那是最好的。但是事实不会那么简单,所以优化技术已经发展出了一系列的理论来解决实际问题。其常用的优化技术为:
①线性规划:当目标函数与约束函数都是线性函数时,就是一个线性规划问题。而当同时满足约束函数和目标函数时,则可以认为是最优解。
②整数规划:要求决策变量取整数值的数学规划。
③多目标规划:指衡量一个决策优劣的标准不止一个,也就是有多目标函数。
④动态规划:将一个复杂的问题划分为多个阶段,逐段求解,最终求出全局最优解。
3 用Excel实现简单的数据分析
表1是某产品某季度的销售数据,根据表中所给出的数据可以做出不同层次的分析。
①对于企业而言最重要的是利润,所以管理者必须要从这张表中得到最关键也最容易得到的销量和销售额以及与其相关的一些数据,通常是用最基本的数理统计结果来直观地反映该企业在某个期间的盈利情况。
②其次,我们必须要做进一步的分析。已经对整体的情况有了一定的把握,所以就可以朝着不同的方向去挖掘一些有价值的信息,为企业高层做决策提供有力的依据。对产品销售而言,客户结构能够有效地反映客户的地域分布,企业可以根据客户的来源,在未开辟客户的地域去寻找新的目标客户群。而销量结构可以直观地反映企业最大销量来自哪个地区,对销量较小的地区可以加大宣传力度或者增加销售网点来保持各地区销售均衡。还可以及时地调整销售方式来扩大市场份额,而对于销量最小的地区考虑开辟新的市场。
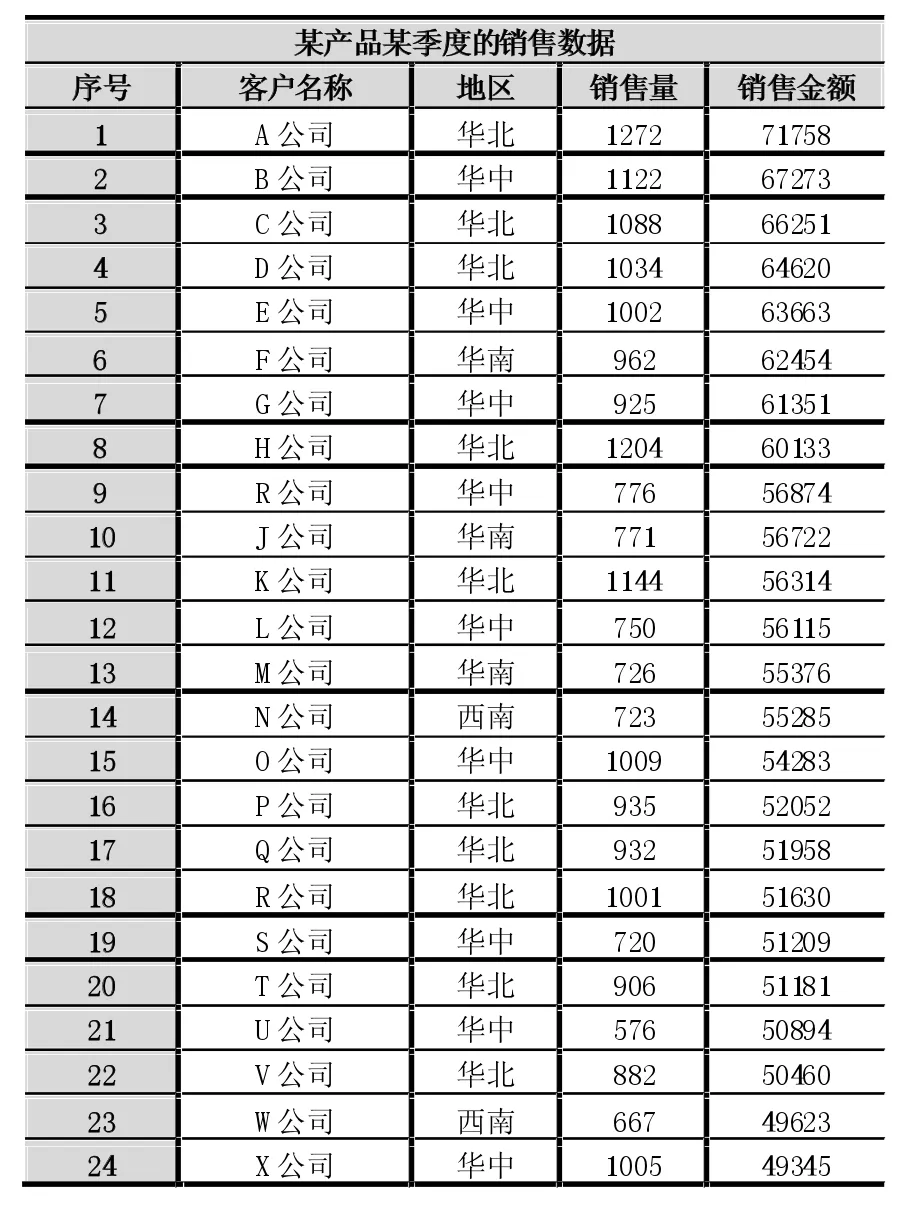
表1
③图3统计了各地区的销售总额和平均销售额以及两者的对比关系。由此可以得出地区平均购买力大小,以及各地区总销售额大小。借助图表描述,管理者可以对企业在某段期间内的销售状况有一个大概的把握,只有掌握了这些的信息,才能更细化地去研究具体的影响因素。
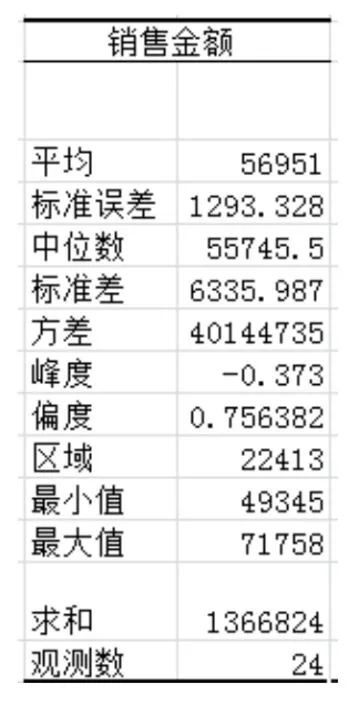
图1
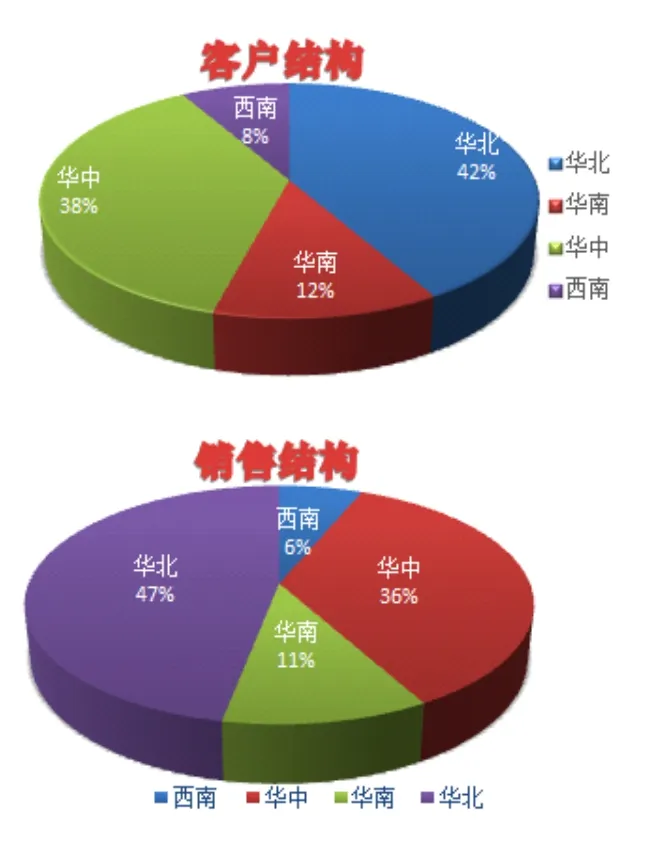
图2
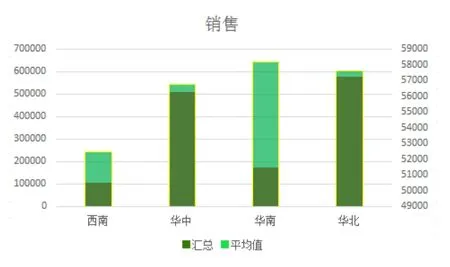
图3
④一般以销售为主的企业都需要对客户的购买力划分等级,对于经常性大量购买的客户必须要以最优惠的价格和最好的服务让其满意,以形成一个稳定的大客户群。而对于那些少量购买的客户,也要制定出相应合适的方案来留住客户。所以,分析销售额的分布情况,可以掌握客户的购买力度而且还能及时做一些留住大客户的举措。
4 用R语言实现数据多层次分析
R语言是一种自由软件编程语言与操作环境,是一套完整的数据处理、计算和制图软件系统,它是一种用来进行数据探索、统计分析和作图的解释型语言。它可以提供一些集成的统计工具,但更大量的是它提供各种数学计算、统计计算的函数,从而使使用者能灵活机动地进行数据分析,甚至创造出符合需要的新的统计计算方法。而在使用R语言进行数据分析处理时,当我们遇到很大的原始数据,但用来建模的数据较小,则可以先在数据库中进行整理,然后通过R与数据库的接口提取数据,数据库适合存放和整理比较规整的数据,和R中的数据框有良好的对应关系,这也是R中绝大多数统计模型的标准数据结构。数据库中大部分的运算都不需要消耗很大的内存。
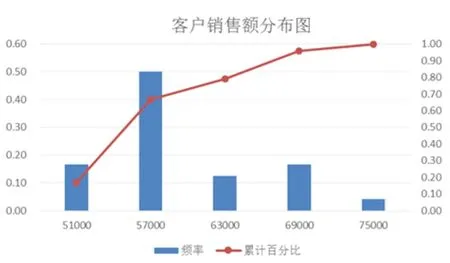
图4
如今的社交平台已经做得相当完善,我们可以随时掌握朋友圈的一些动态,以及最近很热的一些话题。下面我们以微博话题为例,用R语言实现相关的分析,并呈现出可视化的分析结果。
具体分析思路:
可以从新浪微博开放平台:http://open.weibo.com中使用R函数抓取数据。获取与“最新话题”相关的微博约10000条,对微博内容进行分词,构造词频矩阵,即每条微博是一个观测,语料库中每个词语出现的频率是自变量,微博的主题为因变量,对因变量做回归并进行变量选择,找到那些最能将因变量区分开来的词语。也可以通过访问http://s.weibo.com/weibo/<search_ content>&rd=MjAxN&page=<page_number>抓取微博的HTML文本,注意抓取网页的频率限制,利用XML软件包解析HTML,获取微博的文本内容,利用rmmseg4j软件包进行中文分词将数据导入数据库,进行简单的处理(大写转小写,删去某些词语),利用ff软件包读取数据,并结合Matrix软件包构造稀疏词频矩阵,12147条微博,4711个词语,完整的词频矩阵大小为0.97G,稀疏化后仅占据3.6M,使用Lasso对回归进行变量选择,核心算法用Rcpp软件包和C++实现,结果使用wordcloud软件包进行可视化展示如下:

图5
5 结语
多层次数据分析在管理上有十分重要的意义,因为它所产生的价值是完全建立在真实的数据层面,而对一个企业而言搜集数据模式的改进是管理过程的完善,对企业符合时代潮流和规范管理过程是至关重要的。多层次数据分析能够及时纠正企业错误的决策,能够对进度展开实时跟踪,还能了解成本管制情况和人员思想动态等。
对于个人而言,数据分析可以帮助我们更好地去生活,消费者可以通过分析结果去选择物美价廉的商品。还可以用数学模型来分析电影的票房,来减少不必要的损失等。
总之,大数据时代多层次数据分析的价值是无可估量的,它可以囊括我们能想到方方面面以及我们现在还想不到的一些领域。也许,在不久的将来数据分析技术会变成一个独立的学科,而掌握数据分析技术是以后社会中人才必备的技能。
[1] 彭鸿涛,聂磊.发现数据之美-数据分析原理与实践[M].北京:电子工业出版社,2014:1~200
[2] 刘兰娟等.《经济管理中的计算机应用(第二版)》[M].北京:清华大学出版社,2013:1~300
Multilevel Data Analysis
QI Peng-nian
(School of Economics and Management,Changsha University of Science&Technology,Changsha 410114)
As for the analysis of professional data,it must be very strong pertinence,the results of the analysis provides with what kind of demand. Otherwise it causes unnecessary waste of information value,which will greatly increase the cost for information acquisition.Makes a corresponding discussion about how to realize the multi-level analysis data by combining with examples of the way of theory.
Big Data;Data Mining;Data Analysis;Policy Desicion and Distributed Database
1007-1423(2015)02-0045-06
10.3969/j.issn.1007-1423.2015.02.012
祁鹏年(1992-),青海海东人,本科,研究方向Web开发、数据分析
2014-10-30
2014-12-24
