一种基于视觉词袋模型的人脸识别方法
2015-05-05吕江靖
王 玲,吕江靖,程 诚,周 曦
(中国科学院 重庆绿色智能技术研究院 智能多媒体中心,重庆 400714)
一种基于视觉词袋模型的人脸识别方法
王 玲,吕江靖,程 诚,周 曦
(中国科学院 重庆绿色智能技术研究院 智能多媒体中心,重庆 400714)
针对人脸图像因受表情、光照、角度等因素影响,导致人脸识别率较低的状况,提出了一种基于视觉词袋模型的人脸识别方法。该方法首先对图像进行分块并提取局部特征,其次利用训练样本的所有局部特征训练全局的混合高斯模型,然后以此为初始化训练单张图像的混合高斯模型,生成该图像全局特征向量,最后用PLDA进行人脸识别。通过在LFW数据库上进行实验,结果显示该方法的识别率高于传统的特征提取方法,证明其具有更强的识别性能。
视觉词袋模型;人脸识别;混合高斯模型;特征提取
1 词袋模型简介
人脸识别作为计算机视觉与模式识别领域的一个重要研究方向,已经在身份认证、视觉监控以及自动通关等方面得到了广泛应用。虽然近年来人脸识别取得了长足的进步,但是仍受到一些因素的制约,如人脸角度、光照条件、表情以及年龄变化等主客观因素。为了减少这些因素对人脸识别准确率的影响,需要持续的算法研究作为支撑。
词袋模型[1]作为文本建模中的经典模型,因其简单、有效的优点被广泛应用于文本处理领域,用来对文档进行分类和识别。目前,词袋模型已被应用到图像处理领域[2],用来进行图像分类,即通过将一幅图像看成是由一系列视觉单词组成的文章,实现图像的高速分类,是一种有效的基于图像语义特征提取与描述的图像分类算法。人脸识别的主要思想是对人脸图像进行分类判别,将同一个人的图片归为一类,属于经典的图像分类问题。基于词袋模型的人脸特征编码过程如图1所示:首先,对图片库里所有的人脸图像进行分块;其次,对每块区域提取特征(如LBP、HOG、SIFT)形成局部特征描述子;然后,对所有局部特征进行量化形成字典(如k-mean,GMM);最后,通过用字典对单张人脸图像的所有局部特征进行编码,形成该人脸图像的全局特征向量。

图1 基于词袋模型的人脸特征编码过程
2 相关研究
基于经典的词袋模型结构,研究者们提出了很多种基于词袋模型的特征编码方法。Hu等人提出了基于矢量量化(VQ)编码方法[3],该编码方法先对图库中所有图像提取局部特征,利用k均值算法聚类得到包含K个聚类中心(μ1,μ2,…,μK)的视觉字典。当给定一幅新图像时,提取N个局部特征x1,x2,…,xN,将N个局部特征硬量化编码分配到聚类中心得到相应的系数qki,最后统计属于每个聚类中心的局部特征的个数,形成局部特征的统计直方图。Wang等人提出了局部约束线性编码方法(LLC)[4],该方法是加入局部线性约束的空间金字塔匹配算法。LLC同样使用k均值聚类得到K个聚类中心,构成视觉字典;然后,对给定图像的每一个局部特征,计算与其相似的k个空间相邻的视觉关键词来稀疏表示;最后,通过空间金字塔匹配算法(Spatial Pyramid Matching,SPM)[5],将图像划分为不同大小的区域进行池化(pooling),形成LLC特征。Simonyan 等人提出了Fisher 编码方法[6],该方法首先对图库中所有图像分块并提取局部特征;再使用EM算法训练全局的GMM;最后,计算一幅图像所有局部特征与全局GMM中每个高斯中心的一阶、二阶差分的平均值,拼接形成Fisher特征向量。Jégou 等人提出的VLAD编码方法[7]与Fisher编码方法类似,只是在最后生成基于图像的特征向量时,利用了局部特征与全局混合高斯模型聚类中心的残差信息。然而,这些编码方法对局部特征进行简单硬量化或利用差异信息进行特征编码,无法对局部特征的分布进行精确描述,使得人脸识别的准确率降低。
针对这些问题,本文提出了基于混合高斯模型(GMM)的特征编码方法,在下文中简称为GMMC。GMM作为概率密度估计中最常用的统计模型,其主要特性是只要拥有足够数量的高斯个数就能对任意复杂的分布进行精确的量化,因此被广泛用来描述各种复杂分布。因此,GMMC能在一定程度上解决上述方法在编码过程中的信息丢失或者失真的问题。
3 GMMC的基本原理
GMMC同Fisher编码一样,首先对人脸图像进行分块,提取局部特征,再训练图库的混合高斯模型。其创新点是在对单张图片的局部特征进行编码的过程中,Fisher编码只是求取每个局部特征与高斯中心的一阶、二阶差分的平均值,拼接形成图片的全局特征向量,而GMMC却用单张图片所有的局部特征来求基于图片的全局GMM,然后提取该图像的全局特征向量。在此过程中,GMMC充分利用了混合高斯模型的优势,更准确地描述了图像的局部特征。
3.1 局部特征提取
在词袋模型中,图像的局部特征被称为视觉单词(visual words),对图库中所有视觉单词进行聚类量化形成的聚类中心被称为视觉关键字(visual keywords),所有视觉关键字组成视觉字典(visual codebook)。
3.1.1 人脸图像预处理
对给定的人脸图像通过人脸检测器定位人脸位置,再根据人脸检测框的位置,使用SDM算法[8]进行关键点检测定位,最后利用关键点信息对人脸进行对齐,生成160×160大小的灰度图像,人脸对齐流程如图2所示。

图2 人脸对齐流程
3.1.2 局部特征提取
方向梯度直方图(Histogram of Oriented Gradient,HOG)特征[9]是通过计算和统计图像局部区域的梯度方向直方图来构成特征,对旋转、尺度缩放、亮度变化等具有较强的稳定性,因此选用HOG描述子来提取图像的局部特征。人脸局部特征提取的具体过程如图3所示:首先,把对齐后的每幅图像以步长为8边长分别为16,25,31的方形划分成若干个子区域,并对每个子区域提取128维的HOG特征;然后,用PCA把128维HOG局部特征降到50维;最后,为了保留每个局部特征的空间位置信息,在每个降维后的局部特征中加入该区域的中心坐标和边长[x,y,s],形成53维的局部特征向量。

图3 人脸局部特征提取过程
3.2 全局混合高斯模型的生成
全局混合高斯模型的训练对应于经典词袋模型中的字典生成阶段。

(1)

随机初始化参数为
(2)
1)E-step
计算每一个训练样本xt属于第k个高斯的后验概率
(3)
式中:n表示第n次迭代。
2)M-step
计算新的一组参数
(4)
(5)
(6)
不断迭代E-step和M-step直到参数收敛。
当给定一个新样本xi时,可以通过式(7)计算样本xi属于各个高斯的后验概率
(7)
3.3 基于图像的混合高斯模型的生成
训练单幅图像的混合高斯模型对应于经典词袋模型中的特征编码阶段。由于单幅图像拥有的局部特征数量相对较少,不能有效地对GMM进行参数估计,因此利用全局的GMM作为初始化。最后,通过式(8)、式(9)计算图像各个局部特征向量出现的最大后验概率(Maximum A Posteriori,MAP),从而求解单幅图像的GMM的参数
(8)

图4 LFW库中经过关键点对齐的人脸图像示例
其中
(9)

(10)
1)E-step
(11)
(12)
2)M-step:
(13)
(14)
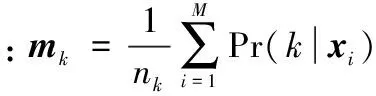
3.4 全局图像特征生成
当求得基于单幅图像的GMM参数后,图像I的描述用以下向量表示
(15)
4 实验结果及分析
本文在LFW[11](Labeled Faces in the Wild)人脸数据库上进行实验以验证所提出算法的可行性。
LFW数据库是由美国马萨诸塞大学阿姆斯特分校计算机视觉实验室整理完成,共收集5 749人共13 233张人脸图像,提供了10组交叉验证集用于人脸识别性能评测,每组包含600对人脸,其中300对为同一个人的人脸图像,另300对则不是。该数据库由于包含了复杂光照、角度、表情等因素下的人脸,主要用于研究非限制条件下的人脸识别问题,已成为学术界和工业界评测识别性能的基准数据库。本文在实验时,采用其中1组作为测试集,剩下的9组作为训练集,计算测试集的分类正确率,最后选取10次交叉验证结果的平均值作为每个方法的识别率。图4为LFW库中经过关键点对齐的人脸图像示例。
本文对提取的全局人脸特征均使用概率线性判别分析(PLDA)[12-13]进行人脸识别。PLDA主要通过计算类内和类间的协方差矩阵,计算给定两个人脸特征向量属于同一个人和不同人的后验概率进行分类判别。
为了评测本文提出的算法,在相同的实验设置下,对GMMC、VQ、LLC、Fisher和VLAD等方法在LFW上进行了实验。
4.1 各种编码方法在LFW库上的识别结果
表1给出了各种编码方法在LFW数据集上的识别率,其中字典大小均设定为256。实验结果显示,在相同的实验设定下,GMMC的识别率最高,达到90.88%,证明了在这种情况下GMMC的识别性能优于其他特征编码方法。
表1 各种编码方法在LFW数据集上的识别率

编码方法评价精度±标准差GMMC09088±00002Fisher08935±00005VLAD08898±00005LLC08420±00002VQ08073±00006
4.2 比较不同局部特征对识别性能影响
为了评测不同局部特征对不同编码方法识别率的影响,使用了其他两种常用的局部特征描述子SIFT[14]和LBP[15]来做实验。其中,SIFT对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;LBP特征是一种用来描述图像局部纹理特征的算子,它具有旋转不变性和灰度不变性等显著的优点。
表2给出了各种编码方法在不同特征特征下的识别率,字典大小仍然为256。结果显示,除VQ外其他编码方法均在使用HOG局部特征情况下的识别率为最高,但是GMMC的最佳识别率仍然是最高的。
表2 各种编码方法在不同局部特征下的识别率

编码方法HOGSIFTLBPGMMC090880889007480Fisher089350852707453VLAD088980885207705LLC084200835307700VQ080730825707797
4.3 比较不同字典大小对识别性能影响
为了评测不同字典大小对识别性能的影响,比较了各种编码方法在不同字典大小下的识别率,其结果如表3所示。其中,GMMC、Fisher和VLAD均在字典大小为256时识别率最好,而LLC和VQ随着字典增大,识别率显著提升,当字典大小为2 048时,LLC的识别率高于Fisher和VLAD。
表3 各种编码方法在不同大小字典下的识别率

编码方法字典大小12825651210242048GMMC0898309088090670901308812Fisher0891008935088850873208517VLAD0892208898087930869308435LLC0833808420085230867708795VQ0802808073082380825708298
5 小结
本文提出了一种新的基于词袋模型的特征编码方法。该方法在用字典对局部特征编码阶段并非使用简单的硬量化或者一些简单差分计算,而是通过生成基于图像混合高斯模型的方式对图像局部特征进行编码,能够对图像局部特征信息的分布进行更精确的描述,提高了人脸识别率。另外,由于LFW数据库中人脸的表情、角度以及光照等条件变化都很复杂,从表2和表3中也可以看出GMMC的最佳识别率高于其他几种基于词袋模型的编码方法,说明了GMMC具有较稳定的识别性能,具有实用性。
[1] SIVIC J,ZISSERMAN A. Efficient visual search of videos cast as text retrieval[J].IEEE Trans. Pattern Analysis and Machine Intelligence,2009,31(4):591-606.
[2] HUANG Y,WU Z,WANG L,et al. Feature coding in image classification:a comprehensive study[J].IEEE Trans. Pattern Analysis and Machine Intelligence,2014,36(2):493-506.
[3] HU Y C,WEN C H,LO C C,et al. Image vector quantization using geometric transform and lossless index coding[J].Optical Engineering,2013,52(3):402-410.
[4] WANG J,YANG J,YU K,et al. Locality-constrained linear coding for image classification[C]//Proc. 2010 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2010:3360-3367.
[5] LAZEBNIK S,SCHMID C,PONCE J. Beyond bags of features:spatial pyramid matching for recognizing natural scene categories[C]//Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2006.[S.l.]:IEEE Press,2006(2):2169-2178.
[6] SIMONYAN K,PARKHI O M,VEDALDI A,et al. Fisher vector faces in the wild[C]//Proc. 13th European Conference on Computer Vision,2014.Zurich,Switzerland:Springer,2014:470.
[7] JÉGOU H,DOUZE M,SCHMID C,et al. Aggregating local descriptors into a compact image representation[C]//Proc. 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE Press,2010:3304-3311.
[8] XIONG X,TORRE F. Supervised descent method and its applications to face alignment[C]//Proc. 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE Press,2013:532-539.
[9] DALAL N,TRIGGS B. Histograms of oriented gradients for human detection[C]//Proc. 2005 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2005:886-893.
[10] KOCH K R. Robust estimation by expectation maximization algorithm[J].Journal of Geodesy,2013,87(2):107-116.
[11] HUANG G B,RAMESH M,BERG T,et al. Labeled faces in the wild:a database for studying face recognition in unconstrained environments[EB/OL].[2015-02-10].https://hal.archives-ouvertes.fr/inria-00321923/.
[12] LI P,FU Y,MOHAMMED U,et al. Probabilistic models for inference about identity [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(1):144-157.
[13] LI Z,CHANG S,LIANG F,et al. Learning locally-adaptive decision functions for person verification[C]//Proc. 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE Press,2013:3610-3617.
[14] LOWE D G. Object recognition from local scale-invariant features[C]//Proc. the 7th IEEE International Conference on Computer Vision,1999. [S.l.]:IEEE Press,1999:1150-1157.
[15] AHONEN T,HADID A,PIETIKAINEN M. Face description with local binary patterns:application to face recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(12):2037-2041.
王 玲(1989— ),女,硕士生,主要研究领域为人脸识别;
吕江靖(1990— ),博士生,主要研究领域为人脸识别、深度学习;
程 诚(1982— ),助理研究员,主要研究领域为人脸识别、深度学习;
周 曦(1981— ),教授,博士生导师,主要研究领域人脸识别。
责任编辑:任健男
Face Recognition Method Based on Bags of Visual Words
WANG Ling, LÜ Jiangjing, CHENG Cheng, ZHOU Xi
(DepartmentofIntelligentMultimediaTechnologyResearchCenter,ChongqingInstituteofGreenandIntelligentTechnology,ChineseAcademyofSciences,Chongqing400714,China)
In order to improve the state of low recognition rates because face images are affected by the factors of expression, light, pose,et al, a new encoding method based on bags of visual words is proposed. Firstly, all training images are sampled into local areas in a dense and local appearance feature descriptors are gained from the local areas. Next, global GMM is obtained from local feature descriptors of all training images. Then, using global GMM as initialization of every image from the test database, image-specified GMM is gotten from which the face feature vector generates. Finally, PLDA is used for face recognition. The experiments are carried on the databases of LFW and the results show that the recognition rates of the proposed method are higher than the other traditional feature extracting method, it proves that the proposed method has a stronger recognition performance.
bags of visual words; face recognition; GMM; feature extracting
中国科学院战略性先导科技专项基金项目(XDA06040103);国家自然科学基金项目(61472386);重庆市科委科技攻关重大项目(cstc2012gg-sfgc4001)
TP391
A
10.16280/j.videoe.2015.17.027
2015-03-10
【本文献信息】王玲,吕江靖,程诚,等.一种基于视觉词袋模型的人脸识别方法[J].电视技术,2015,39(17).
