基于特征序列的语义分类体系的自动构建
2015-04-21陈刚,刘扬
陈 刚,刘 扬
(1. 北京大学 计算语言学研究所,北京 100871;2. 北京大学 计算语言学教育部重点实验室,北京 100871)
基于特征序列的语义分类体系的自动构建
陈 刚1,2,刘 扬1,2
(1. 北京大学 计算语言学研究所,北京 100871;2. 北京大学 计算语言学教育部重点实验室,北京 100871)
词义知识表示主要依赖属性描述或分类描述,这两种方式各有所长,但不同表示之间相互转换的可行性与现实状况还未被关注。在属性描述的基础上,该文引入序关系的思想,提出基于特征序列的概念与方法,以此来模拟、分析概念涵义从一般到特殊的渐次生成过程,发掘尚未显性化的中间概念,自动构建出一个语义分类体系。以HowNet(2000版)数据为例,实验表明该方法可以生成一个性质优良、覆盖完全的新的语义分类体系,并反映此前的属性描述在语言知识工程实践中不易察觉的一些问题。
词义知识;属性描述;分类描述;序关系;特征序列;语义分类体系
1 引言
本体(Ontology)是一种形式化的、可共享的概念模型,它能够在知识层面上为一般或特定领域的概念及其关系提供明确的描述,实现对相关领域知识的共同理解和共享复用[1-2]。词义知识库作为一种特定本体,关注的是语言系统内部的词汇语义以及它们之间的相互关系,其知识表示方式主要有两种: 属性描述和分类描述。
词义知识的属性描述一般采取构造方式,借助义素分析等方法预先定义出一组基本语义单位,然后按照一定的描写规则将这些基本语义单位组合起来,形成针对特定词义的相互独立的概念描写,使用这种方法的典型系统是HowNet[3]等;而分类描述则不同,它并不注重单一的概念描写,而是意在对全体概念进行系统性的区分,以上下位关系为主干结构将概念组织成一个语义分类体系,在此基础上再添加其他类型的语义关系,进一步构成一个复杂的语义网络,使用这种方法的典型系统是WordNet[4]。属性描述和分类描述在方法、手段上各有所长,前者强于对概念自身的精细描写、在词义计算中便于实现多样的特征选取,后者强于对系统结构的整体把握、在词义计算中便于在不同粒度上的意义归约。我们认为,在一定程度上实现两种描述方式的计算性转换,可以结合两方面的优势,在语言知识工程上做迭代性的评估和构建,这也是在实际的语言知识工程中需要特别关注的一个方面。
此前,Wong等[5]曾对HowNet和WordNet进行了系统性的分析和比较,认为它们使用两种截然不同的知识表示方法,表达了十分相似的概念与关系,但是并未进一步研究这两种表示方式相互转换的可能性。卢鹏等[6]尝试将HowNet中六万多词的属性描述分配到高层义原分类树的1 500多个节点上去,并对同一节点内的词聚类,期望得出一个语义分类体系。后者已经注意到了两种描述方式之间转换的可能性,但是,他们选取的聚类的技术路线依赖语料,算法复杂度高而精度也难以保障,最终得到的义原分类树下的次级结构不甚清晰、可靠性也不高,具体表现在不同概念之间的“弱”分类依据上以及同一概念内的不同词之间的“弱”同义依据上。此外,使用各种资源自动或半自动地构建本体也是语言知识工程近年来的一个研究热点,Chen等[7]、Liu等[8]的实验表明了此类做法的有效性。
基于以上观点,本文希望在属性描述的基础上,依据更合理的语言学假设,自动地构建出一个性质优良、覆盖完全的语义分类体系,实现从属性描述到分类描述的计算性转换,并评估现有工作在语言知识工程上的状况,以促进高质量的、实用化的词义知识库的演化、生成。
2 基于特征序列的语义分类体系的自动构建方法
2.1 广义特征、特征集合、特征序列的约定
一般而言,词义知识的属性描述不仅涉及当前概念的多种语义属性,也描述它与其他概念之间的多种语义关系。例如,HowNet对“医生”概念的描述为: “DEF=human|人,#occupation|职位,*cure|医治,medical|医”。其中,“医生”不仅具有“human|人”、“medical|医”这两种属性,还具有与“occupation|职位”之间的“相关”关系(以“#”来标识)以及与“cure|医治”之间的“施事-动作”关系(以“*”来标识)这两种关系。
不难发现,属性的描述针对当前概念、相对单纯,而关系与程序中的指针类似,以它为媒介,从当前概念指向了另外的概念,这也是其不便处理的地方。基于方便结构计算的特殊考虑,我们不妨把属性和属性值封装起来,同时把关系标识和它所指向的目标概念也封装起来,先不做形式上的二元区分,则关系在整体上也相当于普通的描述项,即“医生”概念有“human|人”、“#occupation|职位”、“*cure|医治”、“medical|医”这样的字符串值分别作其概念涵义。在此约定下,我们可以把属性、关系统一视为用来定义当前概念的广义特征,以下均简称特征。换句话说,用来描述一个概念涵义的信息就是若干项特征,无须再区分属性、关系这样的子类了。
从语言学、尤其是词汇语义学的角度看,一个概念涵义的界定由多项特征来描述,它们构成了一个无序的特征集合W={F1, F2, …, Fn},其中的每个元素分别描述了词W的词义的不同方面。
为凸显词义的不同方面的重要程度,我们在此集合上追加关于多项特征之间的序关系的认定,则特征集合W={F1, F2, …, Fn}在给定序关系下的排列W′= < Fs1, Fs2, …, Fsn>即为特征序列,其中si∈[1, n], 对于任何i≠j,满足si≠sj。在给定的序关系下,从Fs1,Fs2,…,到Fsn,它们对整体的概念涵义的约束从左到右依次减弱。如此一来,特征在特征序列中的位序尤其重要,它决定该特征对于整体的概念涵义贡献的大小。易见,理论上词W的一组特征可以构成n!种排列。
序关系的引入,扩展了属性描述的表达能力。例如,“中南海”一词的概念涵义可能采取的特征包括 “人群”、“地点”、“机构”等多个方面,在不同的语境下要做不同的设定、选择。在知识库中若采用多继承方式或单一属性的多取值方式,往往会破坏数据的层次性、带来结构的复杂化,甚至造成语义理解上的冲突。而序关系的限定和要求自然回避了特征之间非此即彼的硬性选择,转为表征它们之间重要性的位序的认定和记录,且无任何语义上的损失。对于上面的例子,如果语料实例关注的是人,那么就可以将“人群”这个特征提前,然后才考虑“机构”和“地点”的排列;同理,如果关注地点、机构,那么只要将“地点”、“机构”特征提前即可,而其它特征后移。
2.2 中间概念生成与语义分类层次的扩展
依据上述理解,同一特征序列的不同长度的子序列,或称序列前缀,也因此负载了特殊的意义。一个特征序列的序列前缀可以按照其长度的增长逐步展开,形成不同的分类层次、构成不同的中间概念,并自然地模拟了概念涵义从一般到特殊的渐次生成过程。在此解释下,我们将全体概念的所有中间概念按分类层次收集起来,就能获得一个相对完整的语义分类体系。
实际上,序列前缀表达的概念与该特征序列表达的概念之间形成了一种宽泛的分类关系。从左往右观察特征序列,也可以看到概念涵义的生成过程: 每施加一项新的特征,概念就被约束到一个更小的内涵上去,模拟、分析了现实分类中的父类、子类关系。这种约束不限于狭义的kind-of或is-a关系,是一种更为“广义”的上下位关系,也为一般的语义分类实践提供了新的契机。
举例来说,假设在给定的序关系下,有且仅有如下五个词的特征序列构成的一个概念空间。
W(1)=
W(2)=
W(3)=
W(4)=
W(5)=
易见W(2)和W(5)具有相同的特征序列,这是语言中的“一义多词”现象(注意,“一词多义”现象在知识库构建中并无特殊性,仅涉及词形问题,为描述简洁起见没有列入)。我们把具有相同特征序列的词结合形成同义词集,表示同一个概念,从而避免词形带来的对概念表示的干扰。然后,对于每个特征序列,提取其所有的序列前缀作为新的特征序列持续加入。将所产生的特征序列去重并按字典序排列,可得如下新的概念空间。
{ }=
{ }=
{W(1)}=
{W(2),W(5)}=
{W(4)}=
{W(3)}=
其中,
另外,Kahrl和 Roland-Host对中国整体的水—能关系进行了研究。他们根据中国国家统计局和水利部公布的用电和用水数据以及中国的投入产出表,计算出了我国非农业用水对应的单位能耗。该方法与前文所述的采用逐步分析方法的研究不同,是应用投入产出模型,计算水资源产品和供给的能耗。该研究指出目前中国非农业供水的能耗占中国总能耗的比例较小,但是,随着中国水处理能力的提高和水利设施的增加(如南水北调等),该比例会不断增大。
将这些特征序列按顺序翻转90度,纵向观察,所有的特征序列在字典序下对应着一个树结构的先序遍历结果,而序列前缀恰好对应着树结构中的概念节点,因此自动导出一个如图1所示的小型的语义分类体系。
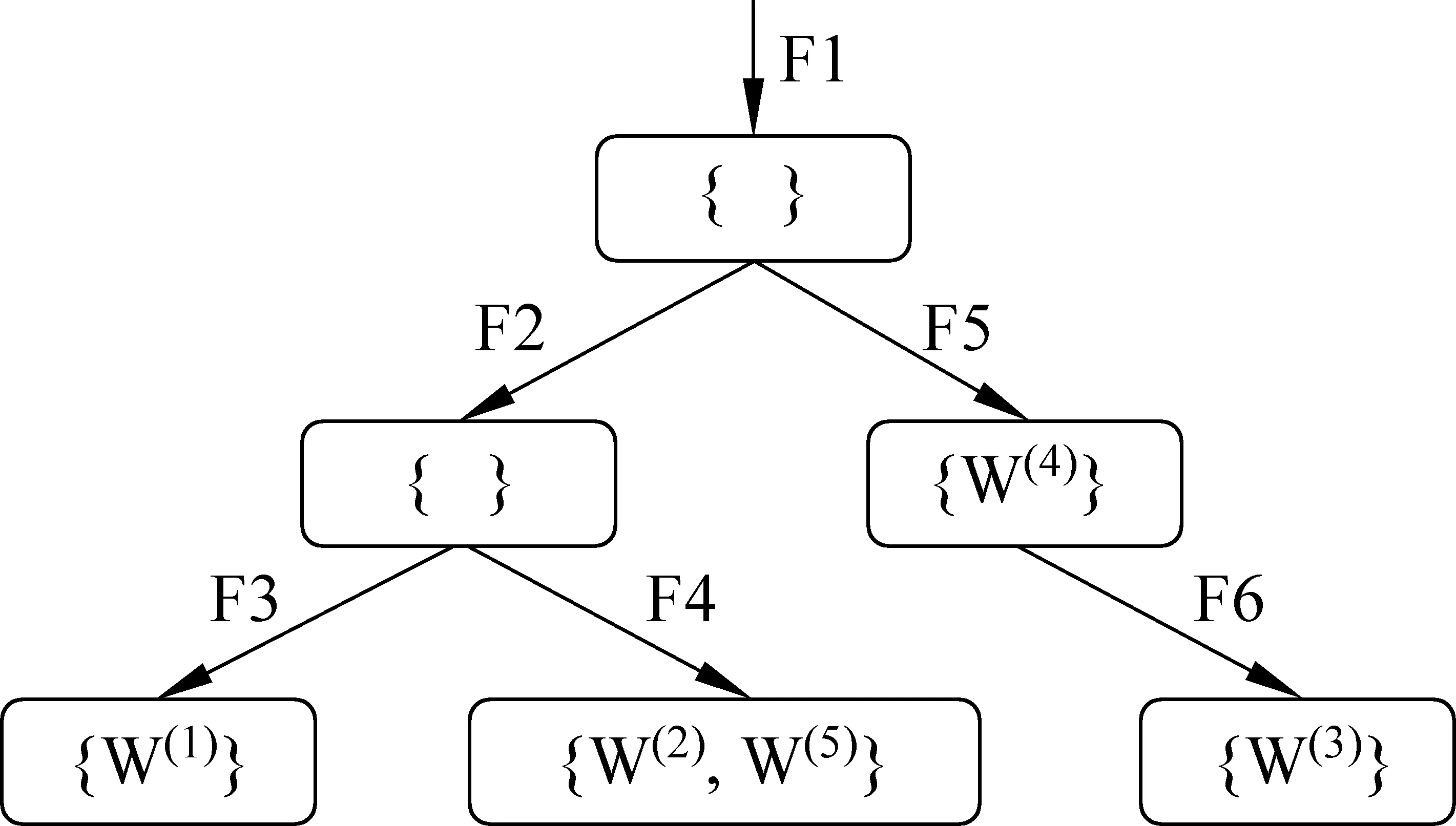
图1 序列前缀扩展生成的树结构
2.3 自动构建算法伪码描述
上述方法的算法实现并不困难,我们仅以伪码描述表示如下。易证,该算法的时间复杂度为O(M·N),其中,M为知识库中的词条数目,N为特征序列的平均长度。
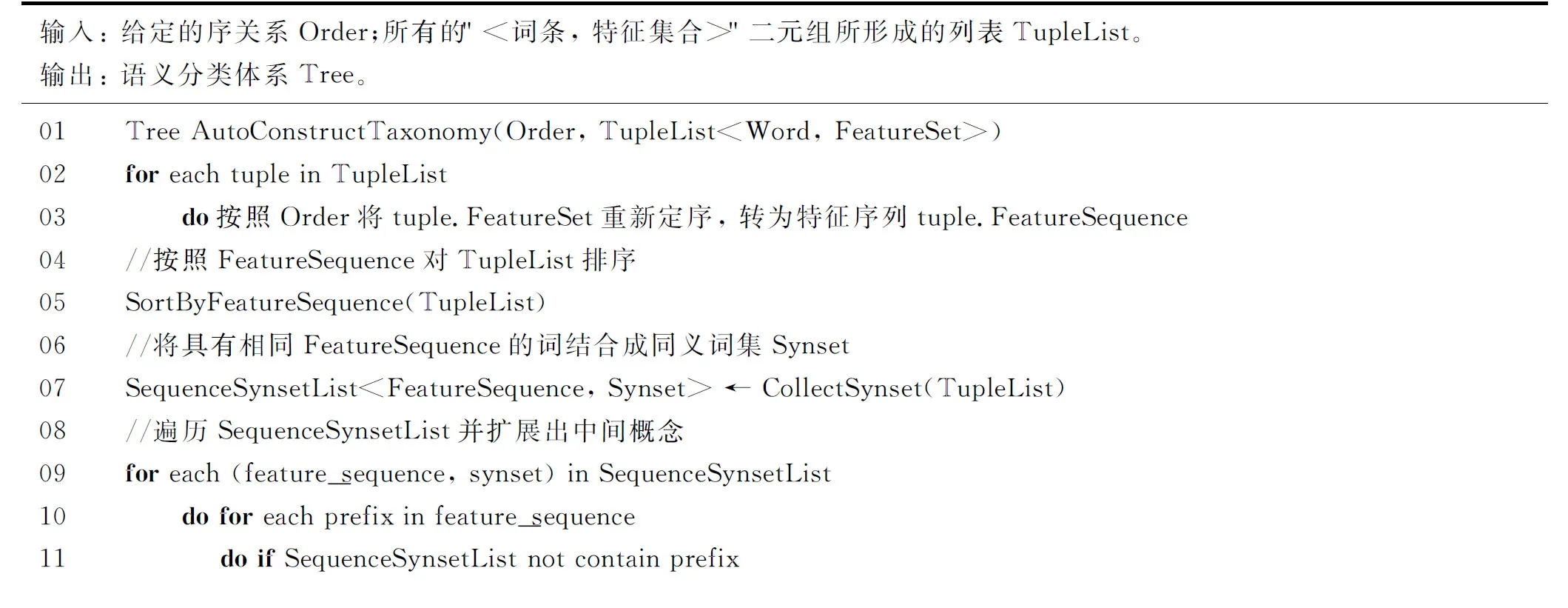
输入:给定的序关系Order;所有的"<词条,特征集合>"二元组所形成的列表TupleList。输出:语义分类体系Tree。01 TreeAutoConstructTaxonomy(Order,TupleList

3 自动构建实验与数据分析
3.1 实验数据描述
HowNet(2000版)是采用属性描述的一个典型的词义知识库,下面以其为例验证本文方法的有效性。首先,HowNet定义了语义基本单位——义原,并依上下位关系把它们组织在几个小型的树结构中,包括“实体”、“事件”、“属性”、“属性值”、“动态角色与特征”等类。此外,HowNet进一步定义了上下位关系、整体-部分关系、施事-工具关系、受事-事件关系、相关关系等数十种关系。之后,通过义原和关系的组合来描述概念涵义,一些示例如表1所示。
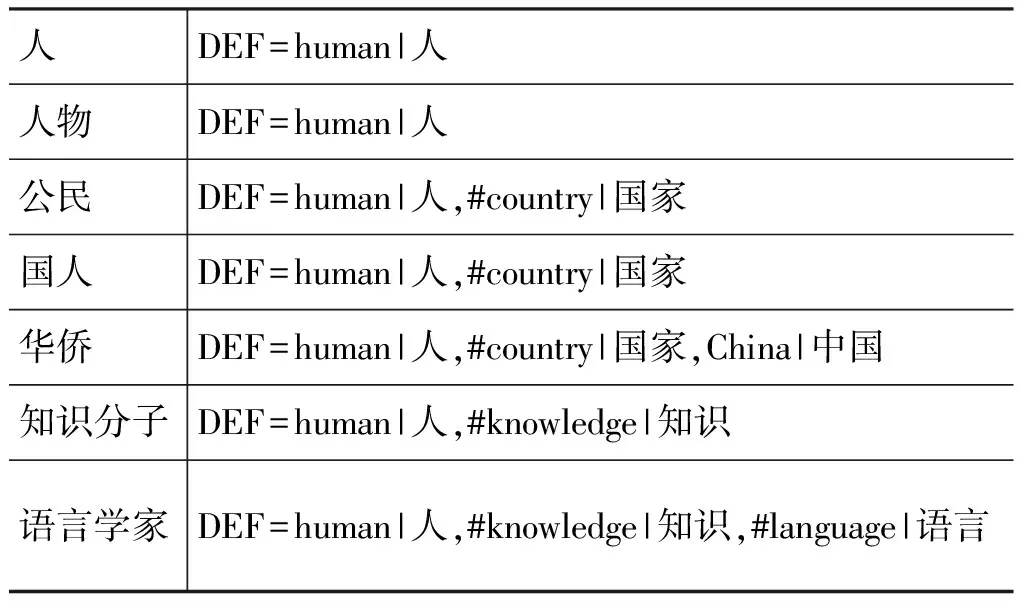
表1 HowNet基于属性描述的释义举例
其中,“human|人”、“country|国家”、“China|中国”、“knowledge|知识”和“language|语言”是义原,“#”是“相关”关系标识。我们用特征定义来简化概念表示。例如,在“公民: DEF=human|人,#country|国家”中,认定“公民”一词具有两项特征: “human|人”、“#country|国家”。HowNet已规定DEF项的第一项为概念的主要特征,其余为次要特征,我们也发现DEF定义项从左到右自然地反映了从主到次的序关系,因此,我们直接将这种序关系作为算法的输入,不做任何调整。
3.2 分类体系的自动扩展及优化方案
使用本文方法,对上述用例自动扩展生成的一个语义分类如图2右半部分示意。由于HowNet中的义原已经组织在如图2左半部分示意的小型树中,且同样可转写为特征序列,这启发我们在自动扩展的基础上,依据DEF项对应的主要特征的取值,可将此前生成的语义分类直接“拼接”在义原树上——或者,从另一个视角说,是将义原的特征序列直接追加在DEF项的主要特征上并重新做全局的自动扩展。这样,利用已有结构,就把全部概念有机地结合在一个分类体系中了。考虑HowNet描述特性的优化方案生成的完整树结构则如图2所示。

图2 HowNet分类体系的自动扩展及其优化方案示意
HowNet原始文件中不重复的DEF项(即概念定义)的总次数为17 216,在这些DEF项中义原出现的总次数为66 478,DEF项的平均长度为3.86。优化方案除覆盖了原始的17 216个概念外,同时新生成了6 384个此前未加定义的中间概念,它们暂时还没有词的实例来承载。这些尚未显性化的中间概念的数量占原有概念数量的37.08%,而全体概念数量增长到23 600个,其中的义原出现的总次数增长到182 686,DEF项的平均长度约7.74。从概念涵义的有意义扩展以及新的中间概念自动生成的角度看,这对语言知识库建设是一个积极的现象。
在词义知识表示上,属性描述的详细程度、均匀与否等关乎基于特征选取的词义计算的稳定性。对比原始DEF项(含17 216个概念)的长度分布以及在优化方案下扩展出的特征序列(含23 600个概念)的长度分布,如图3所示,其长度分布的右向漂移十分明显。与卢鹏等工作相比,优化方案下构建的语义分类体系将义原的特征序列直接追加在DEF项的主要特征上, 增加了特征序列的长度,也增强了概念之间的区分性,而且,概念的特征序列长度的分布更均匀,这也有助于确保词义计算的质量。此外,本文方法采用简单、可靠的语言学假设,充分挖掘HowNet包括义原分类信息、DEF项定义信息在内的全部属性描述信息,也避免了使用外部语料可能带来的不确定性,同时,算法复杂度显著降低,能很快完成分类体系的计算并输出全局数据。

图3 原始DEF项长度分布与优化方案下的特征序列长度分布的对比
基于特征序列的概念、方法并采取优化方案,我们在HowNet的全集规模(覆盖全部原始概念,分类节点数在两万以上)上首次给出了一个分布均衡的语义分类体系,并保证同一概念节点内的词享有完全相同的DEF项定义。表2列举了自动构建的一些代表示例,它们本身即构成一棵子树。其中,“@”、“#”分别标识“场所-事件”、“相关”关系,而null表示生成了新的有意义的中间概念,但在原知识库中暂时还没有词的实例来承载,参考图1,它们的语言学解释不难理解。

表2 自动构建的一些代表示例
在自动构建的语义分类体系下,我们可以从整体结构上把握原始数据,反映此前的属性描述在语言知识工程实践中不易察觉的一些问题,表明了语言学假设和概念、方法的有效性。首先,本文提出的方法便于核查同一概念节点内不同词的同义性状况。例如,表2第一行为“亭子|碑亭|垛|构筑物|明沟|窨井”,虽然它们的特征序列(注意同时也是原始DEF项信息)相同,但是真实的词义参差不齐,将这些词分开做精细化描述可能是更好的选择;其次,本文方法能进一步判断概念涵义继承链条的潜在缺失。对于那些新产生的中间概念,顺应其作为“概念化”的自然成果,思考其概念涵义“词汇化”的可能性,可以系统化地扩张知识库中的词量。例如,对于表2第二行,依据新产生的特征序列“facilities|设施,@exercise|锻练”的概念涵义的指示,还可以添加“训练场”、“健身中心”等词;最后,本文方法也有助于发掘概念涵义继承链条的潜在错误。依据现有的属性描述,“DEF=facilities|设施,@exercise|锻练,#ice|冰,sport|体育”的概念涵义明显比“DEF=facilities|设施”更限定、更具体,则“冰场”在新分类体系下应认定为“亭子|碑亭|垛|构筑物|明沟|窨井”的子孙概念,而目前的这种状况显然是不合理的,需要修改部分词的属性描述的原始定义(即原始DEF项信息),这种情况在知识库中也有较多出现。
总之,在词义知识的属性描述下,针对单个词的属性描述难以对不同的词进行系统化的横向、纵向比较,在语义分类体系下则可把相关问题清晰呈现出来。反过来,单纯的分类描述缺乏对多种特征的有效认识和把握,在工程实践中也会衍生出许多问题。两种方式的结合有助于发挥综合优势,在语言知识工程上做迭代,以生成高质量的、实用化的词义知识库。
4 结语
在知识库的构建中,词义知识表示主要依赖属性描述或分类描述,这两种方式各有所长,但不同表示之间相互转换的可行性与现实状况还未被关注。
在属性描述的基础上,本文引入了序关系的思想,提出了特征序列的概念以及基于该概念的分类层次展开方法。该方法能够模拟、分析概念涵义从一般到特殊的渐次生成过程,并发掘、记录那些尚未显性化的中间概念,自动地构建出一个语义分类体系,实现从属性描述到分类描述的计算性转换。以HowNet数据为例,实验表明本方法可以生成一个性质优良、覆盖完全的新的语义分类体系,并反映此前的属性描述在语言知识工程实践中不易察觉的一些问题。
值得注意的是,不同特征之间的序关系的认定至关重要。为方便起见,本文直接采用了原始DEF项的定义顺序,以此生成了一个单一分类体系。进一步,序关系的变更和认定也可以不仅限于特征之间,而是先将全部特征按照某种相关性分组(例如,确定分别属于领域、格框、情感、语域等不同方面的特征),然后依据“组间”顺序和“组内”顺序来形成有侧重的、不同的序关系。这样的研究有利于多分类体系的自动构建和调整,形成不同应用需求下的可定制知识库系统。
此外,特征序列的概念、方法也具有通用性,在从分类描述向属性描述的转换中同样适用。其做法为: 对于语义分类体系中的每个概念节点,持续界定、收集从根节点到该概念节点的路径上的每一处分类的区分性凭证(即区分特征),若知识库中存在多继承现象和多种其它关系,则需要在序关系上做一些特殊的认定和处理。鉴于篇幅所限,这部分内容不再赘述。
目前,我们正将基于特征序列的概念、方法应用于北大“中文概念词典”的迭代评价和结构重构等方面,希望在语言知识工程上不断演化,生成出高质量的、实用化的词义知识库。
[1] T Gruber. Toward Principles for the Design of Ontologies Used for Knowledge Sharing[J]. International Journal of Human-Computer Studies, 1995, 43 (5-6): 907-928.
[2] 邓志鸿, 唐世渭, 张铭,等. Ontology研究综述[J]. 北京大学学报(自然科学报), 2002, 38(9): 728-730.
[3] 董振东. 知网(2000版)[DB/OL], http://www.keenage.com.
[4] G A Miller, B Richard, F Christiane, et al. Introduction to WordNet: An On-line Lexical Database[R]. Five Papers on WordNet, CSL Report 43, Cognitive Science Laboratory, Princeton University, 1993.
[5] P W Wong, P Fung. Nouns in Wordnet and HowNet: An Analysis and Comparison of Semantic Relations[C]//Proceedings of GWC′02, India, 2002: 319-322.
[6] 卢鹏, 孙明勇, 陆汝占. 基于知网的词汇语义自动分类系统[J]. 计算机仿真, 2004, 21(2): 127-133.
[7] H P Chen, L He, B Chen. Research and Implementation of Ontology Automatic Construction Based on Relational Database[C]//Proceedings of International Conference on Computer Science and Software Engineering-CSSE, 2008: 1078-1081.
[8] N Liu, G Y Li, Y F Zhang. Research on Domain Ontology Semi-automatic Construction Model towards Chinese Text[C]//Proceedings of International Convention on Information and Communication Technology, Electronics and Microelectronics-MIPRO, 2010.
Automatic Construction of Semantic Taxonomy Based on Feature Sequences
CHEN Gang1,2, LIU Yang1,2
(1. Institute of Computational Linguistics, Peking University, Beijing 100871, China; 2. Key Laboratory of Computational Linguistics (Ministry of Education), Peking University, Beijing 100871, China)
Feature description and taxonomic description are two basic knowledge representations widely employed in lexical semantics. However, the the transformation between them remains an open issue with well discussion. In this paper, we applies the notion of ordering relationship into the feature description, and automatically derive a taxonomy from general to specific concepts, in which the previous undefined intermediate concepts are revealed. Experiments on HowNet (2000) show that a semantic taxonomy, with a fine-defined inheritance and a full coverage of all concepts, can be automatically generated by this approach. Further analysis of the output also indicates some underlined defects in the feature description for natural language knowledge engineering.
lexical semantics;feature description;taxonomic description;ordering relation;feature sequences;semantic taxonomy

陈刚(1988—),硕士研究生,主要研究领域为自然语言处理、语言知识工程。E⁃mail:gangchen@pku.edu.cn刘扬(1971-),男,副教授,主要研究领域为自然语言处理、语言知识工程。E⁃mail:liuyang@pku.edu.cn
1003-0077(2015)03-0052-06
2013-04-08 定稿日期: 2013-07-25
国家重点基础研究发展计划资助项目(2014CB340504);国家社科基金重大项目(12&ZD119)。
TP391
A
