软件构件选择方法研究
2015-04-18赖晓燕
赖晓燕,林 娟
(1.福建农林大学 金山学院, 福建 福州 350002;2.福建农林大学 计算机与信息学院, 福建 福州 350002)
软件构件选择方法研究
赖晓燕1,林 娟2
(1.福建农林大学 金山学院, 福建 福州 350002;2.福建农林大学 计算机与信息学院, 福建 福州 350002)
为了有效地进行软件构件选择,将软件构件选择分成单构件选择和多构件选择两类问题.针对单构件选择问题,把改进的Vague集引入构件质量评价,通过评价给出构件质量的优劣排序,将多构件选择问题映射为一个多选择背包问题,提出一种混合的自适应遗传算法,该算法在迭代初期采用固定的交叉概率和变异概率,在迭代末期采用改进的自适应遗传算法.通过仿真实验表明,与其他算法比较该算法具有较好的全局寻优能力和执行效率.
单构件选择;Vague集;构件质量评价;多构件选择;自适应遗传算法
基于构件的软件开发(Component-based Software Development, CBSD)通过对已有构件的复用和组装来构建新的软件系统,大幅度的降低了软件开发成本,提高了软件开发效率,是目前主流的软件开发方法.随着CBSD技术的日益成熟,在开放的互联网中分布了大量的构件,如何快速、有效地选择合适的构件,是基于构件的软件工程(Component-based Software Engineering, CBSE)所面临的首要问题.
目前,在软件构件选择方面的研究已经取得了一些成果,文献[1]提出了基于场景匹配的可信构件选择方法,文献[2]提出了一种满足用户可信度期望的构件选择方法,文献[3]提出了基于非线性模糊质量功能展开的构件选择模型.上述文献从不同角度探讨了软件构件的选择方法,为构件选择方法的研究提供了重要的参考,但是现有的方法大多针对单个构件的选择,对于多构件选择的研究甚少,文献[4]指出了多构件选择为特定约束下的组合优化问题,但并没有建立具体的实现模型.按选择构件的数量可将用户分为两种:选择单个构件用户和选择多个构件用户,而在具体操作过程中,选择单构件的用户通过检索技术在构件库中检索出的满足用户基本要求的构件少则几十种,多则几百种,而多构件选择用户的检索结果则达上千种,因而,如何在检索结果集中挑选出最满意的目标构件或构件组合具有非常重要的现实意义.基于此,本文分别对单构件和多构件选择问题进行研究,并给出相应的构件选择方法.
1 单构件选择
1.1 单构件评价与选择
基于构件组装的软件产品的质量很大程度依赖于构件的质量.面对众多的构件产品,构件质量是用户进行构件选择的重要依据.因此,为了选择合适的单个构件,必须对符合用户需求的批量构件进行质量评价,并根据评价的结果对构件进行优劣排序.但是目前针对构件质量的有效评价模型比较缺乏,为此,本文提出一种基于改进Vague集的构件质量评价模型,为用户选择构件提供一种度量参考.
1.2 Vague集的改进
构件质量评价是涉及多指标的决策,多数的指标具有模糊性和不确定性,为了增加决策的柔性,引入Vague集,它是模糊集的一个扩展,可以同时表示评价者肯定、否定两个方面的信息,而改进的Vague集除了可以同时考虑隶属度、非隶属度,还增加了犹豫度,描述了人类对事物的认知过程中存在不同程度的犹豫的现象,能更客观地刻画事物的模糊性本质.
定义1 设μA(x),νA(x),πA(x)分别表示x关于A的隶属度,非隶属度和犹豫度,则称
A={<μA(x),νA(x)>|x∈X,X≠Φ}
(1)

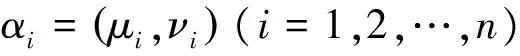
d(α1,α2,…,αn)=
(2)
(3)
为方案的贴近度.
1.3 基于改进Vague集的构件质量评价与选择
1.3.1 确定评价指标体系及权重系数
结合ISO/IEC25010软件质量模型,参照文献[6]中软件构件质量特性与子特性的选择需求,通过增加质量特性、质量子特性,甄选、裁剪子特性,构建了两级的构件质量评价指标体系见表1.
表1 构件质量评价体系

质量特性子特性功能性适合性、准确性、互操作性、安全性可靠性成熟性、容错性、易恢复性易用性易理解性、易操作性、吸引性效率时间特性、资源利用性维护性易分析性、易改变性、稳定性、易测试性可移植性适应性、共存性、易替换性可复用性接口成熟性、易组装性、独立性、通用性、演化兼容性
权重系数是指标重要程度的度量,为了减少权重确定的主观性和盲目性,本文参照文献[7]中的基于改进的层次分析法与专家群体决策相结合的方法,确定了二级指标体系的权重.
第一级指标体系U的权重向量为
(4)
第二级指标体系Ui的权重向量为
(5)
其中i=1,…,n,ni为质量特性Ui所对应的质量子特性的个数.
1.3.2 构造二级决策矩阵

(6)
其中ni为质量特性Ui所对应的质量子特性的个数.
根据(2)式,可以得到第二级指标的综合属性值di:
(7)
所有的第二级指标的综合属性值构成了第一级指标的决策矩阵D:
(8)
根据(2)式,可以得到第一级指标的综合属性值d:
(9)
1.3.3 计算贴近度及排序
根据式(3),分别计算m个构件最终评价值dCk(k=1,2,…,m)的贴近度,并按照贴近度的大小进行排序.
2 基于混合的自适应遗传算法的多构件选择
2.1 多构件选择问题
在组装应用系统的过程中,为了实现一个较复杂的任务,用户往往需要同时选择不同类型的多个构件.假设某用户为了实现一个较大的任务,需要功能独立,低耦合的M个构件,但是考虑到成本问题,经费限定为COST千元.多构件选择过程为:首先该用户在构件库中基于功能刻面分类检索,得到M类构件,其中第i类中有Ni个不同的构件;然后该用户从每一类中选择一个构件,每类必须且只能选择一个构件,将得到一个M个构件的组合,为了获得最高的性价比,该组合构件的费用在COST之内,但是组合构件的综合评价值最高.因此,多构件选择是一个多选择背包问题,为0/1背包问题的其中一种变形,被定义为有附加约束的背包问题,多构件选择的数学模型描述如下:
(10)
(11)
(12)
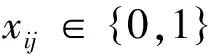
其中,cij表示第i类中第j个构件的评价值,wij表示第i类中第j个构件的费用,COST是购买构件的最大费用.xij的值表示第i类中第j个构件是否被选择,如果被选择则取1,否则取0.式(10)为目标函数,目标是构件的综合评价值最高,式(11)和式(12)为约束条件,分别表示总费用限制和每类必须选择一个构件.
多构件选择是一个NP难问题.下面采用改进的自适应遗传算法来求解构件组合的最优解.
2.2 自适应遗传算法的改进
2.2.1 交叉概率和变异概率的改进
遗传算法在求解0-1背包问题上应用广泛,但在实际操作中,基本的遗传算法存在容易早熟,收敛速度慢等缺点,使得求解质量不高,执行效率不理想.遗传算法中控制搜索能力的交叉算子、变异算子的取值直接影响了算法的收敛速度和全局寻优能力,交叉概率越大,产生新个体的速度越快,然而,具有低价、短定义距的高适应度个体的模式串被破坏的可能性也越大,将不利于寻找全局最优解,交叉概率越小,搜索过程越慢;对于变异概率,取值很小,将不利于生成新的模式,取值过大,遗传算法就变成了随机搜索方法.很多学者研究了如何在遗传操作中控制交叉算子、变异算子,如传统的自适应遗传算法中,交叉概率和变异概率可以随着适应度自动改变,其定义公式如下[8-10]:
(13)
(14)
式中:fmax为群体中最大的适应度值;favg为每代群体中的平均适应度值;fbig为要交叉的两个个体中较大的适应度值;f为要变异个体的适应度值.
从式(13)和式(14)可以看出,对于较差的个体,采用较大的交叉和变异概率,将其淘汰;对于较好的个体,采用较低的交叉和变异概率,使其优良的性能得以保护;每代中的最优个体的交叉和变异概率都为零,即不参与交叉和变异,直接保存下来,这种策略比较适合进化的后期,在迭代的早期,最优个体其极易“迷惑”遗传算法,使其陷入局部解的陷阱.为此对交叉概率和变异概率作进一步的改进,定义如下:
(15)
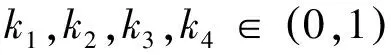
其中,当参与交叉、变异的个体的适应度为最大值时,交叉概率为k1-k2,变异概率为k3,均为正数,可以确保最优个体也参与交叉和变异运算.另外,鉴于自适应算法比较适合迭代末期的情况,本文将采用混合的自适应遗传算法,设定一个固定参数将遗传算法分成初期和后期两部分,当迭代次数小于固定参数时执行固定的交叉概率和变异概率的遗传操作,当迭代次数大于固定参数时,执行自适应遗传算法.固定参数由多次实验获得.
2.2.2 修复操作
遗传算法中的交叉和变异操作都可以使群体多样性得到维持,其中,变异操作是对个体串中的某些基因座上的基因值用其基因座的等位基因来替换,从而生成一个新的个体,保持了群体的多样性.但是在基本遗传算法中,变异操作的基因座是随机确定的,替换过程也是在一定变异概率下的基因突变,是对单个个体的行为,如果将群体看成是一个矩阵,那么一个个体可以看成是一行,基本遗传算法中的变异是从行的角度考虑的,但是这种操作方式没有从列的方向即从整个群体的角度来进行突变,进而增加群体的多样性.我们在实验过程中发现当某一代群体中某一列取值都相同时,如图1所示,假设群体规模为5,染色体长度为8,在某一次遗传操作后,所有5个个体的第4个基因座的基因值都为3,表示父代第4位的很多特征在子代丢失,按照通常的交叉和变异操作,在该位的基因将很难有突破,群体多样性提高很困难,从而发生不成熟收敛的现象.基于此,提出群体修复操作,以提高种群的多样性.修复的方法是:在遗传进程进入下一代之前,统计种群矩阵中每列的取值情况,若在某一列取值都相同时,则强制其中某一个(或某几个)个体在该列所对应的基因在变异概率下发生突变.
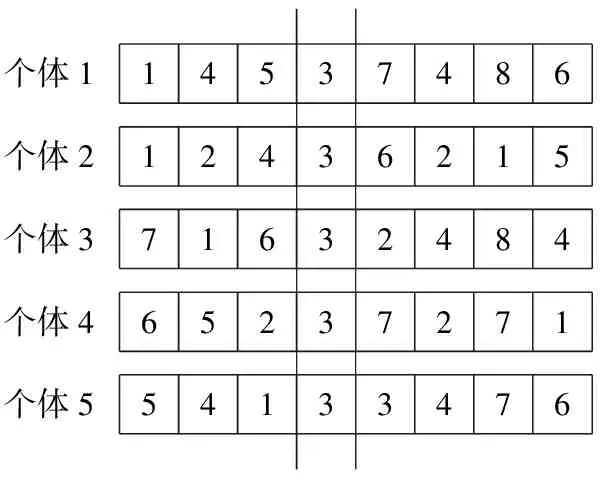
个体1个体2个体3个体4个体51453748612436215716324846523727154133476
图1 迭代中的群体
2.3 利用改进的自适应遗传算法进行多构件选择
2.3.1 编码
根据多选择背包问题的特点,本文选用一维染色体编码.一条染色体由m个基因组成,对应m个构件类,基因位置表示构件的类,每一个基因的值表示所对应构件类中选出的一个构件,如个体的第i个基因取值为k,表示从第i个构件类中选择了第k个构件.如一条染色体序列为52381,表示在五个构件类中,第一个构件类中的第5个构件,第二个构件类中的第2个构件,第三个构件类中的第3个构件,第四个构件类中的第8个构件,第五个构件类中的第1个构件被用户选中.
2.3.2 适应度函数
适应度函数是对群体中各个个体的环境适应能力进行评价的函数,是遗传算法进化过程的驱动力.环境适应能力强即适应度高的个体相较于适应度低的个体遗传到下一代的概率较大,对于多构件选择来说,适应度越高,表示该个体的多构件组合方式的综合评价值越高,用户对其越青睐.本文选择用式(10)作为适应度评价函数,其中每个构件的评价值由上文中的单构件评价方法获得.
2.3.3 遗传操作
遗传操作是实现优胜劣汰的过程,通过选择、交叉和变异的遗传操作,可以使得群体一代又一代地优化,进而逐步逼近最优解.在对群体中个体的适应度评估完后,可以进行选择操作,本文采用最基本的适应度比例选择机制——赌轮方式进行随机选择,在选择轮盘时,采用折半查找的方法提高搜索效率.
基于上述染色体编码的特殊结构,采用一致交叉算子.采用位点变异操作,其基本步骤如下:先从染色体编码串中随机挑选一个或多个变异点,然后在变异概率下,将变异点的基因替换为其他的等位基因,当其他等位基因有多个时,通过随机选择,在构件选择中,位点变异是指在变异概率下从基因位置所对应的构件类中找一个任意构件来替换当前被选构件.
在一致交叉、位点变异后检查群体中所有个体同一个基因座的取值情况,如果出现同一个基因座取值都相同时,从群体中随机挑选一个或多个的个体,在变异概率下进行修复操作.
为了确保算法收敛及收敛效率,本文采用精英保留策略.改进的自适应遗传算法的基本流程如图2所示.
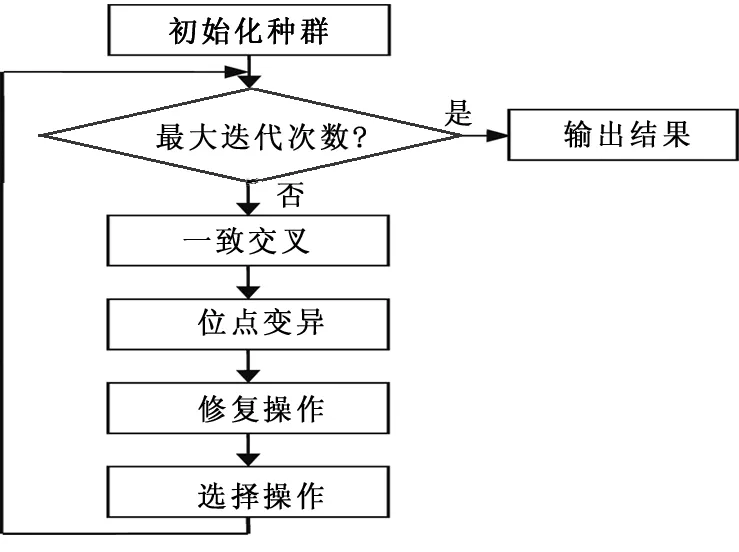
图2 改进遗传算法的基本流程
3 算例研究
3.1 单构件选择实例
某用户为了实现一个简单的任务需要一个构件,在构件库中经检索找到了一批功能相近的构件,假设在用户期望的价格区间仍有3个软件构件(构件1、构件2和构件3)供其选择,运用本文的基于改进Vague集的构件质量评价方法对3个构件进行评价并给出排序结果.
3.1.1 确定两级指标的权重
采用改进的层次分析法获得的指标权重与专家权重进行线性相加后获得的各个指标的综合权重为:
第一级指标体系的权重向量
w=(w1,w2,…,w7)=
(0.3,0.22,0.08,0.21,0.08,0.07,0.04)
第二级指标体系的权重向量
wU1=(w11,w12,…,w14)=
(0.4,0.3,0.15,0.15),
wU2=(0.35,0.35,0.3),
wU3=(0.4,0.5,0.1),
wU4=(0.5,0.5),
wU5=(0.3,0.3,0.2,0.2),
wU6=(0.2,0.5,0.3),
wU7=(0.2,0.3,0.2,0.1,0.2)
3.1.2 构造二级决策矩阵
聘请10位相关领域的专家,对3个构件的质量子特性进行评价,根据式(6),可以得到功能性、可靠性、可复用性等7个质量特性的决策矩阵:






按(2)式计算,可以得到第二级指标的综合属性值:
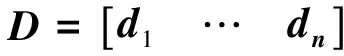

3.1.3 计算贴近度并排序
从综合属性值可知,所有专家对3个构件的评价是非常接近的,如,对于第一个构件有71%专家是支持的,16%的专家是反对的,对于第二个构件有70%的专家是支持的,17%的专家是反对的.因此,需要进一步计算3个构件的贴近度,根据式(3)可得
ε1=0.816,
ε2=0.805,
ε3=0.831
按照贴近度大小,3个构件质量的优劣排序为:构件3>构件1>构件2.
根据构件质量的优劣排序,该用户可以选择质量评价最高的第3个构件.
3.2 多构件选择实例
为了验证本文提出混合的自适应遗传算法的有效性与可行性,对一个由8类构件,每类构件数目分别为{8,5,6,8,7,5,8,6}的多构件选择进行仿真实验,见式(17).为了比较,使用DEV-C++编写了3套程序来求解:分别采用基本遗传算法、自适应遗传算法、本文的混合的自适应遗传算法.为了更好的比较,三种算法的参数设置为一样,种群规模为40,最大迭代次数为100,交叉概率pc=0.6,变异概率pm=0.15,自适应遗传算法和本文中混合的自适应遗传算法中的系数为k1=0.8,k2=0.3,k3=0.2,k4=0.1.
maxf(x)=3x11+4x12+5x13+4x14+8x15+
5x16+4x17+4x18+7x21+9x22+8x23+4x24+
5x25+5x31+6x32+9x33+8x34+4x35+6x36+
2x41+8x42+7x43+5x44+4x45+3x46+7x47+
8x48+8x51+5x52+7x53+9x54+7x55+4x56+
7x57+6x61+8x62+7x63+9x64+5x65+
6x71+9x72+7x73+4x74+3x75+7x76+9x77+
8x78+9x81+2x82+5x83+5x84+8x85+6x86
(17)
约束条件为
6x11+8x12+5x13+4x14+9x15+5x16+9x17+
3x18+6x21+5x22+3x23+5x24+9x25+
8x31+6x32+4x33+8x34+4x35+3x36+
9x41+4x42+8x43+9x44+4x45+9x46+
4x47+5x48+3x51+7x52+4x53+2x54+
3x55+8x56+5x57+8x61+3x62+2x63+8x64+
6x65+5x71+4x72+3x73+8x74+9x75+2x76+
4x77+4x78+2x81+9x82+2x83+6x84+4x85+
3x86≤38
x11+x12+x13+x14+x15+x16+x17+x18=1
x21+x22+x23+x24+x25=1
x31+x32+x33+x34+x35+x36=1
x41+x42+x43+x44+x45+x46+x47+x48=1
x51+x52+x53+x54+x55+x56+x57=1
x61+x62+x63+x64+x65=1
x71+x72+x73+x74+x75+x76+x77+x78=1
x81+x82+x83+x84+x85+x86=1
通过多次实验,本文提出的混合的自适应遗传算法引入的固定参数设置为20时,寻优的平均结果最为理想,即在前20代采用固定的交叉、变异概率进行遗传操作,在20代以后采用本文改进的自适应遗传算法进行遗传操作.利用本文的混合的自适应算法运行40次,可以求得该问题的最优值为70,共找到2个最优解:{5,2,3,2,4,4,2,1},{5,2,3,2,4,4,7,1},表示在一定费用的限制下,选择第一类的第5个构件、第二类的第2个构件、第三类的第3个构件、第四类的第2个构件、第五类的第4个构件、第六类的第4个构件,第七类的第2个或第7个构件、第八类的第1个构件的多构件组合方式最贴近用户的需求.
对于多构件选择问题,将本文的算法与基本遗传算法、自适应遗传算法进行比较,三种算法各进行40次的运算,平均适应度随迭代次数的变化曲线如图3所示,三种算法的运行对比结果见表2.

图3 平均适应值变化
从图3 可知,本文的算法在较少的迭代次数下可以获得较高的平均适应度值,在相同的迭代次数下,本文算法获得的群体平均适应度最好,明显高于另外两种算法,自适应遗传算法的平均适应度其次,基本遗传算法的最差.
表2 三种算法比较

算法最优值找到最优解次数找到最优解的概率基本遗传算法7016次40%自适应遗传算法7018次45%混合的自适应遗传算法7027次67.5%
由表2可知,三种算法都可以找出最佳的多构件组合,但是在找到最优解的频次上不同,本文的算法在40次的实验中,找到最优解的次数可以达到27次,找到最优解概率可达67.5%,比基本遗传算法找到最优解的概率40%提升了27.5%,比自适应遗传算法的求解概率也提升了22.5%,说明本文的算法提高了求解质量,算法有效.
4 结束语
如何从批量的构件中选择合适的单个构件或构件组合是CBSE的首要问题,针对单个构件选择的基于改进Vague集的构件质量评价模型,既考虑了指标的模糊性,又考虑了评价中存在反对和不确定性的情况,实例表明该评价方法客观合理,操作简便,可以推广;针对多个构件选择的混合的自适应遗传算法大大提高了算法的寻优能力.对交叉算子和变异算子的改进,加快了算法的收敛速度,修复操作的实施增强了种群的多样性.仿真实验表明,本文方法的求解质量优于基本遗传算法和自适应遗传算法,说明采用混合的自适应遗传算法进行多构件选择方法非常有效.
[1] 魏乐,赵秋云,舒红平.一种基于场景匹配的可信构件选择方法[J].微电子学与计算机,2011,28(8):176-179.
[2]马华,张红宇.结合可信度模糊评价与动态聚类的构件选择[J].计算机工程与应用,2011,47(21):73-76.
[3] 孙剑,徐莹.基于NF-QFD的构件选择方法[J]. 高师理科学刊,2013,33(5):24-28.
[4]盛津芳,王斌.基于FCD扩展的多构件选择过程[J].计算机应用,2007,27(4):860-862.
[5] 徐泽水.直觉模糊信息集成理论及应用[M].北京:北京科学出版社,2008,13-15.
[6] 李晓丽,刘 超,金茂忠,等.《软件构件产品质量》标准介绍[J].信息技术与标准化,2006(6):19:24.
[7]贺海波,陈立潮,张英俊,等.基于群体决策的软件构件质量评价模型研究[J].计算机工程与设计. 2010,31 (21):4 639-4 642.
[8]王娜,向凤红,毛剑琳.改进的自适应遗传算法求解 0/1 背包问题 [J]. 计算机应用,2012,32(6): 1 682 -1 684.
[9]梁旭,黄明,宁涛,等.现代智能优化混合算法及其应用[M].北京:电子工业出版社,2014.
[10]鲍江宏.用遗传算法实现罚函数法解多选择背包问题[J]. 计算机工程与设计,2008,29(17):4 518-4 521.
(编辑:刘宝江)
Research on software component selection methods
LAI Xiao-yan1, LIN Juan2
(1.Jinshan College, Fujian Agriculture and Forestry University, Fuzhou 350002, China;2.College of Computer and Information, Fujian Agriculture and Forestry University, Fuzhou 350002, China)
In order to select software component effectively, the software component selection is divided into two kinds of problem, one is single component selection and the other is multiple component selection. For the single component selection, improved vague set is introduced into the evaluation of component quality. By using the evaluation method the ranking of the component quality is given. Multiple component selection is mapped as the multiple-choice knapsack problem and we propose a hybrid adaptive genetic algorithm. In the algorithm, crossover probability and mutation probability are fixed in the early iterations, while in the last stage of iteration we use improved adaptive genetic algorithm. The simulation experiments show that comparisons with other algorithms the algorithm has strong ability of global optimization and high efficiency.
single component selection; Vague set; evaluation of component quality; multiple component selection; adaptive genetic algorithm
2015-05-12
福建省自然科学基金资助项目(2014J01219);福建省教育厅基金A类资助项目(JA14110)
赖晓燕,女,lxyfj@163.com
1672-6197(2015)06-0025-07
TP
A
