基于支持向量数据描述的报警融合方法
2015-04-16曹薇薇尹传环牟少敏
曹薇薇,尹传环,牟少敏
CAO Weiwei1,YIN Chuanhuan1,MU Shaomin2
1.北京交通大学 计算机与信息技术学院,北京100044
2.山东农业大学 信息科学与工程学院,山东 泰安271018
1.School of Computer and Information Technology,Beijing Jiaotong University,Beijing 100044,China
2.School of Computer and Information Engineering,Shandong Agriculture University,Tai’an,Shandong 271018,China
1 引言
随着计算机的普及,网络传播的信息涉及各行各业,网络安全问题逐渐成为人们关注的一个焦点。防火墙隔离、网络访问控制等静态防御手段已经不能满足当前的需要,因此能够主动检测并且报告不安全行为的入侵检测系统应运而生。
然而在实际的应用过程中,极高的漏报率、误报率和大量的重复报警是入侵检测系统无法避免的缺陷,报警融合技术就是为此而提出的。报警融合的目的是降低漏报率、误报率,减少重复报警,以利于管理员清晰地掌握网络的发展态势。然而现今大部分报警融合的方法主要是为了减少重复报警[1-4],对于提高检测率和降低漏报方面很少关注,但是这些对于改善攻击的检测效果也是至关重要的。本文提出的基于支持向量数据描述的报警融合方法,通过局部分类、数据融合以及最终的决策分析,既避免了普通支持向量机在处理样本不均衡问题上的检测率很低的现象[5],同时,通过结合模拟退火的思想,能够剔除冗余特征,提高参与训练的报警的质量,最终通过数据融合,能够在很大程度上提高报警的检测率,降低漏报率和误报率,明显地改善了攻击的检测效果。
2 支持向量数据描述
支持向量数据描述(SVDD)是用于异常检测的一类分类器。它源于Vapnik[6]提出的支持向量机(SVM),在2004 年由Tax 和Duin[7]提出。一类分类支持向量机包括两种:一种是普通的一类分类支持向量机(OCSVM)[8],它寻找的是一个最优的分类超平面,将训练数据与原点以最大间隔进行划分;然而在现实中,异常数据点也是存在的,只是不足以和正常数据构成一个样本均衡的两类分类器,于是就出现了另外一种一类分类器即本文所采用的SVDD,它寻找的是一个能够包括所有目标数据的最小超球体,而尽可能地将少量异常数据点划分在超球体的外面。
SVDD 的数学模型如下:
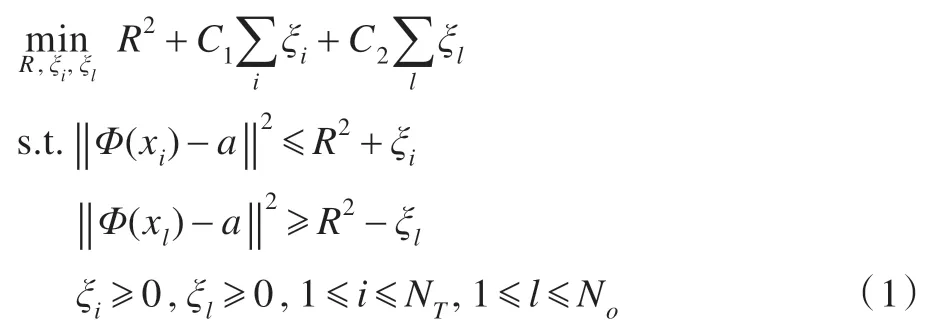
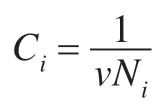
引入拉格朗日乘子,可将上述问题转化为其对偶问题:
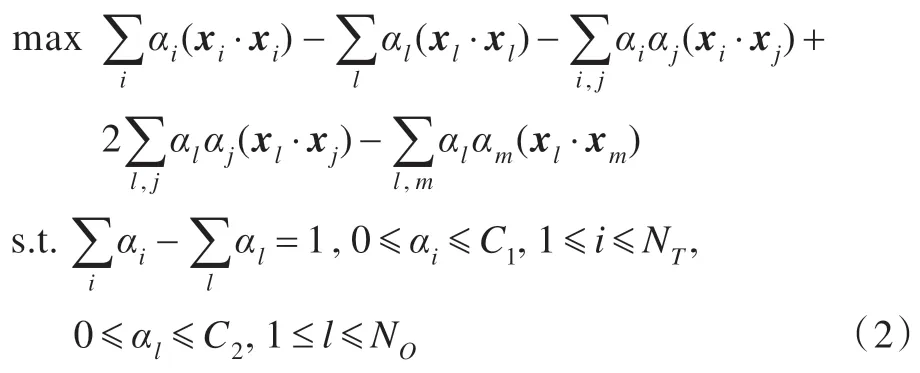
根据文献[7],引入核函数K(xi,xj)=(Φ(xi)·Φ(xj)),可以将上述线性问题转化为非线性问题,具体的引入过程见文献[7],转化后的问题表示如下:
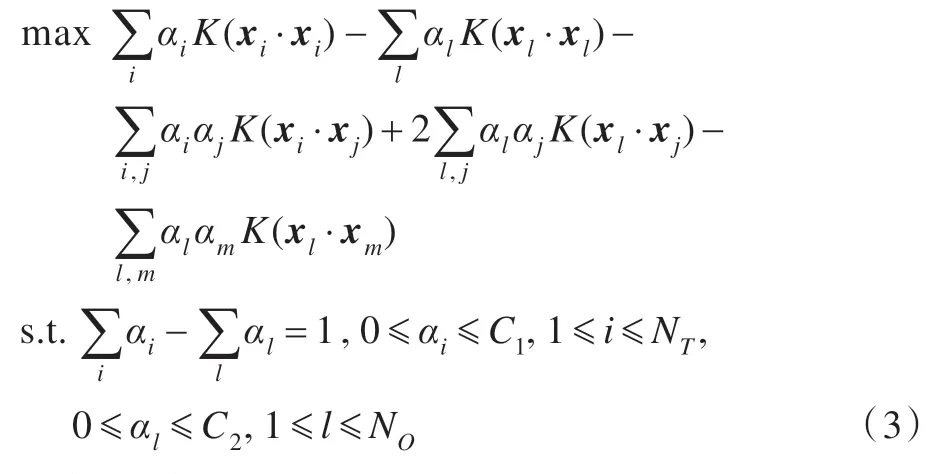
决策函数为:
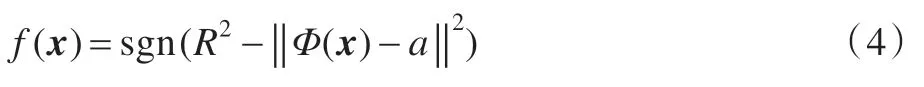
对于一个待测的样本z,如果它到球体中心的距离小于超球的半径,则判断它为正常数据,否则即为异常数据。判断公式如下:
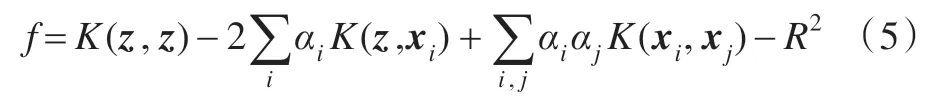
如果f小于等于0,则认为待测样本属于正常类,否则即为异常类。其中K(xi,xj)代表核函数,现在常用的核函数包括线性核函数,高斯核函数,多项式核函数以及sigmoid 核函数[9],本文采用高斯核函数[10],其公式如下:
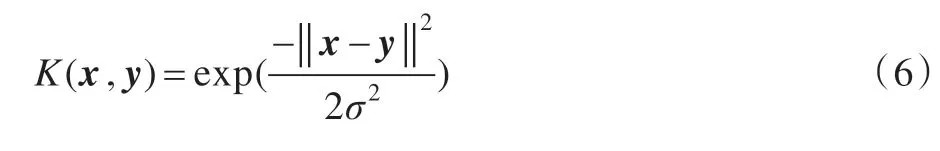
3 模拟退火
模拟退火(SA)的思想源于固体降温,众所周知,固体必须缓慢降温才能使得它在每一个温度下都能达到热平衡,最终趋向于平衡状态。模拟退火的思想最早是由Metropolis[11]提出的,1983 年,Kirkpatrick[12]等人将其引入到组合化领域,至此得到了许多学者对其更加深入的研究与推广。
模拟退火的具体过程如下:从选定的初始解开始,借助于温度控制参数t,在t缓慢降低时产生的一系列Markov 链中,利用一个随机产生新解的案和Metropolis准则,重复下面的过程“产生新解→计算目标函数差→判断是否接受新解→根据Metropolis准则判断是否接受新解”,如此的进行迭代,直到目标函数达到最优。
4 SA-SVDD 算法
将SA 思想引入到SVDD 中是为了寻找最优的折中参数C1、C2,高斯核参数σ和属性特征[13]。算法流程如下:
(1)首先设置一个初始的温度值T=T0和最大迭代次数,温度值是一个很大的数。
(2)随机产生一个解决方案x,作为初始的参数值和属性特征。
(3)以x为出发点,产生一个随机向量作为下一个可行方案y。
(4)分别计算两个解决方案的目标函数值,在这里目标函数值指的是分类准确率,记为X和Y,ΔE=Y-X。
(5)如果ΔE>0,则用新的解决方案y代替原来的解决方案x,温度立即减小,转(7)。
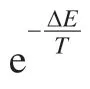
(7)判断是否达到最大迭代次数,如果没有达到,则转(3)继续执行;否则终止算法,输出最优的解决方案。
通过SA-SVDD 算法可以找到SVDD 模型中的参数C1、C2,高斯核参数σ和所选择的属性特征,之后将这些参数和属性特征用于SVDD 模型的训练,不仅可以提高分类的准确率,同时减少了无关属性的干扰,既缩短了训练的时间,也进一步提高了模型的分类质量。
5 SA-SVDD 在报警融合中的应用
报警数据的多源性与复杂性使得传统的单个分类器检测效率急剧下降,由此多个分类器同时被用来进行报警数据的检测成为必然趋势[14]。根据可能存在的不同攻击类型分别建立相应的分类检测器,多个检测器协同作用,再通过最终的决策中心进行判断,这样的结构如图1 所示,能够很大程度上提高检测效率,降低漏报率和误报率。
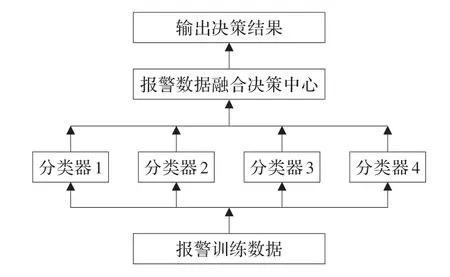
图1 多个分类器协同检测结构
5.1 模型的构建
1998 年,美国国防部高级规划署(DARPA)在林肯实验室建立了一个模拟美国空军局域网的一个网络环境,通过仿真各种用户类型、各种不同的网络流量和攻击手段收集了9 周时间的网络连接和系统审计数据,形成了KDD CUP 99 数据集[15],随后来自哥伦比亚大学的Sal Stolfo 教授和来自北卡罗来纳州立大学的Wenke Lee 教授采用数据挖掘等技术对以上数据集进行特征分析和数据预处理,形成了现在著名的KDD99 数据集,这个数据集的每个数据包含41 种属性,第42 个是标明数据类型的。本文采用KDD99 数据集构建了一个具体的模型,并且用相关数据对模型进行了测试。
KDD99 数据集根据其攻击的特征分为4 种类型:拒绝服务攻击类型DOS(Denial of Service)、端口检测和扫描攻击类型PROBING(probing)、权限提升攻击类型U2R(User to Root),远程登录攻击类型R2L(Remote to Local)。本文将4 种攻击类型与正常数据类型分别建立4 个有针对性的分类器,对攻击类型和正常数据进行检测,然后将局部的检测结果发到决策中心,通过报警融合规则进行融合以做出最终的决策判断。与普通分类器不同的是,这4 个分类器采用上述SA-SVDD 算法,分别以4 种攻击类型为正类,而正常数据看成负类,这样做的目的是每个分类器有针对性的对攻击类型进行检测,而且由于每种攻击类型对于数据41 个属性的需要程度不同,所以结合SA-SVDD 算法可以自动为每个攻击类型筛选出适合它自己的数据属性,既减少了无关属性对于分类精度的干扰,同时对数据进行了约减,大大节约了训练所需要的时间,因此这样训练出来的模型能够明显地降低漏报率和误报率。本文选取KDD99的部分子集进行了实验,分别从4 种攻击类型的子集中抽取部分作为训练集合,而剩余的数据进行测试,4 个训练的数据集如下(图2 左边)训练结果分别表示为ui,i∈{1,2,3,4},ui∈{1,-1},其中1 表示属于攻击类型,-1 表示属于正常数据。然后统一将局部检测的结果送到报警数据融合决策中心,通过决策融合得到最终的判断,4 个分类器的决策函数如图2 所示。
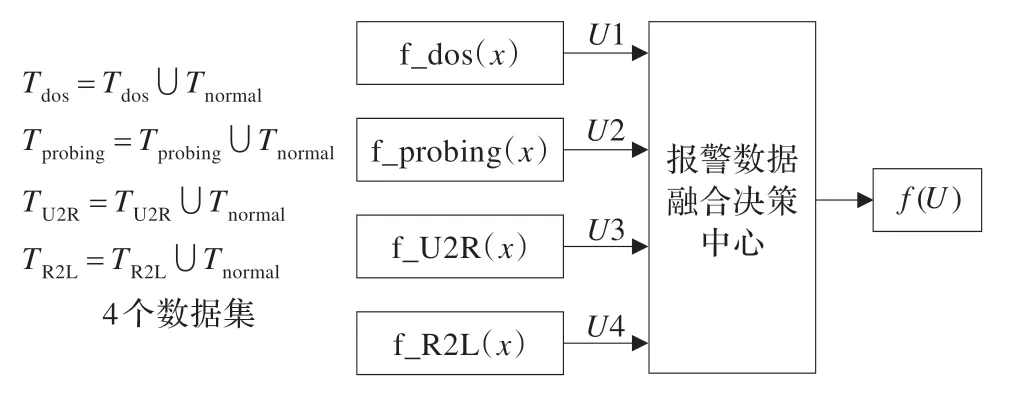
图2 融合实现过程的具体结构
5.2 融合规则算法
由于各个分类器中参与训练的数据集大小是不同的,所以每个分类器的分类性能也是不同的,采用一个矩阵Q表示各个分类器的分类性能,针对本文的实验,这个Q是一个5×4 的矩阵:

矩阵中的每个元素qij表示第j个分类器对于第i个数据集的分类准确度,根据风险最小化准则,融合算法设计如下:
(1)由U={u1,u2,u3,u4}得到V={v1,v2,v3,v4}={-u1,-u2,-u3,-u4}。
(2)由U和α1,α2,α3,α4计算得到,,由V和α1,α2,α3,α4计算得到,其中i=1,2,3,4,表示对角线元素为αi,其余元素都为0 的i阶方阵。
决策的依据是如果属于所有攻击类中概率最大的值都比属于正常类中概率最小的值还要小,那么这个报警判定为正常类,否则即为攻击类,实验结果记录这个攻击类的类型以及被哪个检测器检测得到。
6 实验结果及分析
本文选取的报警数据来自KDD99 数据集的一个子集,这个子集带有正确的分类标签,以便于对于模型进行验证,表1展示了这个子集中每种攻击类型的数据条数。

表1 实验所用到的各种数据的条数统计
实验只是选取了一部分数据进行建模,剩余的大部分数据进行模型的测试,模型的建立过程中需要两种数据同时存在,因此本实验随机从KDD99 数据集中选取了部分作为建模,表2 展示了参加训练的所有攻击数据的条数以及形成的各个模型中的支持向量的个数。
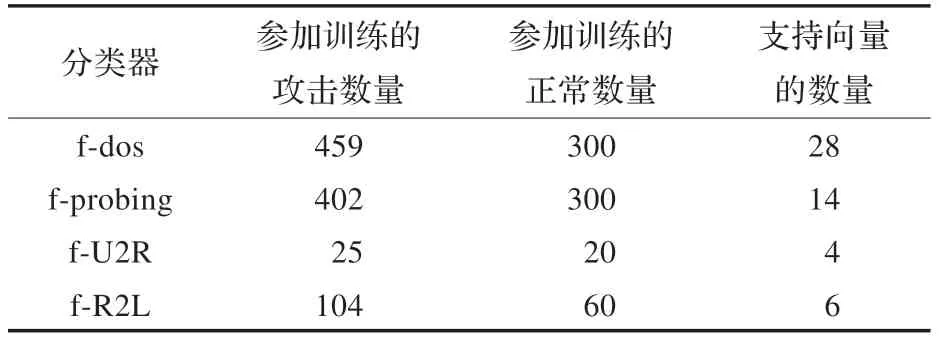
表2 训练数据的条数及各个模型中支持向量的个数统计
模型的检测结果如表3,左侧的一列表示数据集,表格的第一行表示各个分类器,中间的数据表示各个分类器的检测准确率。
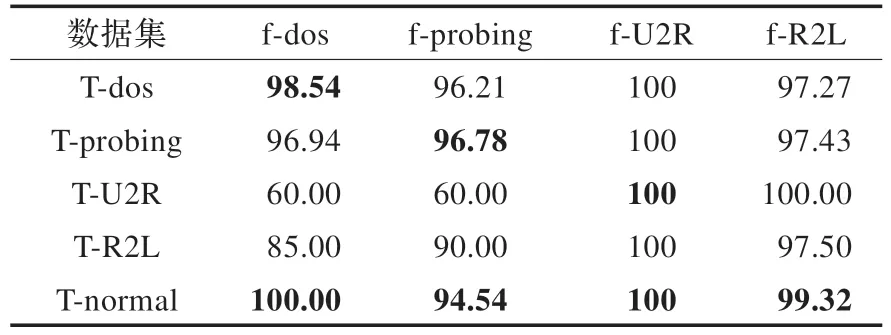
表3 模型的检测结果 %
表3 显示了各个模型的分类准确率,其中f-U2R 分类器之所以出现对所有数据的检测都是100%的结果是因为U2R 这种攻击数据的数据量太小,从表1 和表2 可以看出,参加训练的数据只有25 条,模型中只有4 个支持向量,这就有可能导致形成的超球体半径很小,而参加测试的数据只有5 条,因此当这5 个数据点全部恰好位于这个超球体内,而剩下的数据点全部位于超球体外面,就导致了实验的结果是100%的检测准确率。表3是采用融合算法之前的各个模型对于每个被测数据集的测试结果展示,表4 显示了采用本文所提融合算法之后的检测结果,其中矩阵Q即是表3 中的数据值。
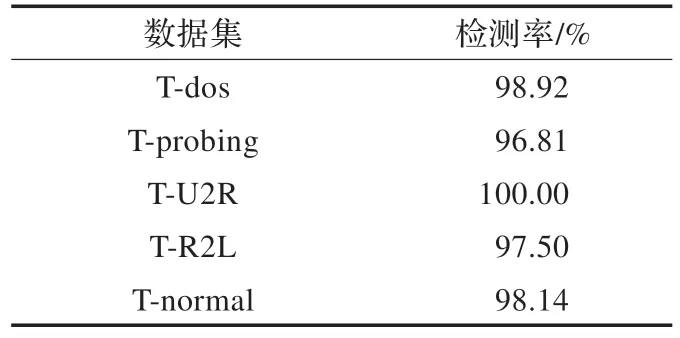
表4 经过融合决策中心之后的检测结果
通过将表4 与表3 对比,发现融合后对于DOS 和PROBING 两种攻击类型的检测都有了一些提高,而对于U2R 和R2L 两种数据的检测没有变化,对于正常数据的检测相比单个分类器有了少许降低,但是从实际情况来看,少许的误报换来对于频繁攻击的更精确检测还是值得的。
最后本文还统计了融合前后模型的漏报率,漏报率指未被检测出来的数据占其所在数据类型的数据的百分比。
通过表5 可以很明显看出融合算法之后各个数据集的漏报率都有了明显的降低,只是正常数据的漏报率有了稍许的增加。这意味着可能稍许正常的数据被误判断为异常数据,但是对于像DOS 和PROBING 这两种非常大量的攻击,检测率有了明显的提升,这里认为少量的误判还是值得的。
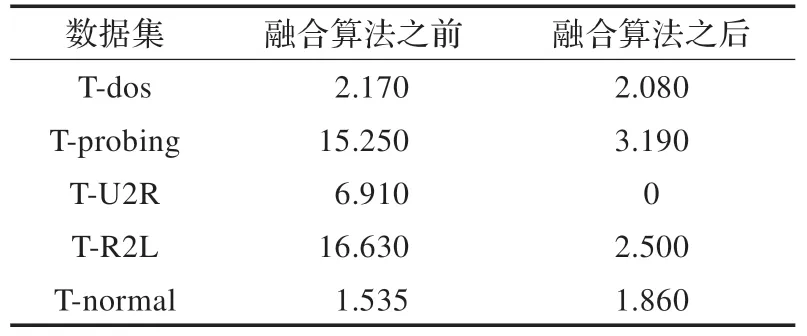
表5 融合前后模型的漏报率比较
7 结论及展望
本文提出了一种基于支持向量数据描述的报警融合方法,并且结合模拟退火的思想,能够根据不同的攻击类型,选择适合它本身的数据属性和核参数,建立的各个小模型再经过报警融合决策中心进行判断,最终确定是属于哪种攻击类型。这样通过分布式检测,最后经过决策融合中心得到最终的报警结果,不仅增加了报警的检测率,也在很大程度上减少了漏报率,弥补了普通报警融合算法中很少考虑这两方面的缺点。
当然,本文所提的方法也还是有缺陷的,由于训练数据选取的随机性以及数据本身的限制,所以建立的模型也不是非常完美的,对于像U2R 数据的模型,因为数据量小,就不是很理想。模拟退火的次数也是模型中一个人为控制的因素,这个只能通过大量的实验获得,没有统一的标准,并且针对不同的数据集可能取值也是不同的。但是无论如何,模型对于大量普遍存在的数据集如DOS 攻击和PROBING 攻击的检测还是很有效的。对于其他的数据集,将来也可以进行验证。
[1] Valdes A,Shinner K.Probabilistic alert correlation[C]//Proceedings of the 4th International Symposium on Recent Advances in Intrusion Detection,Davis,2001:54-68.
[2] Giacinto G,Roli F,Didaci L.Fusion of multiple classifiers for intrusion detection in computer networks[J].Pattern Recognit Lett,2003,24(12):1795-1803.
[3] 穆成坡,黄厚宽,田盛丰.基于模糊综合评判的入侵检测报警信息处理[J].计算机研究与发展,2005,42(10):1679-1685.
[4] 郭帆,余敏,叶继华.一种基于分类和相似度的报警聚合方法[J].计算机应用,2007,27(10):2446-2449.
[5] 姚程宽.SVM 在不平衡样本集中的应用研究[J].计算机与数字工程,2007(10).
[6] Vapnik V N.The nature of statistical learning theory[M].New York:Springer,1995.
[7] Tax D M J,Duin R.Support vector data description[J].Machine Learning,2004,54:45-66.
[8] Schölkopf B,Williamson R,Smola A,et al.Single-class support vector machine,Unsupervised Learning,Dagstuhl-Seminar-Report 235[R].1999:19-20.
[9] Muller K R,Mike S,Ratsch G,et al.An introduction to kernel-based learning algorithms[J].IEEE Trans on Neural Net,2001,12:181-201.
[10] Buhmann M D.Radial basis functions[M].Cambridge:Cambridge University Press,2000:1-38.
[11] Metropolis N,Rosenbluth A W,Rosenbluth M N,et al.Equation of state calculations by fast computing machines[J].The Journal of Chemical Physics,1953,21(6):1087-1092.
[12] Kirkpatrick S,Gelatt Jr C D,Vecchi M P.Optimization by simulated annealing[J].Science,1983,220:671-680.
[13] 曹薇薇,刘国华,陈国涛,等.模拟退火在支持向量数据描述的参数选取和特征选择中的应用[C]//第五届中国智能计算大会论文集,2011.
[14] Snapp S R.DIDS(Distributed Intrusion Detection System)-Motivation,architecture,and an early prototype[C]//Proceedings of the 14th National Computer Security Conference,1991:167-176.
[15] KDD Cup 1999 Data[EB/OL].[2013-09-15].http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html.
