面向基因数据分类的旋转森林算法研究
2015-03-23刘亚卿陆慧娟杜帮俊
刘亚卿,陆慧娟,杜帮俊,余 翠
(中国计量学院 信息工程学院,浙江 杭州 310018)
面向基因数据分类的旋转森林算法研究
刘亚卿,陆慧娟,杜帮俊,余 翠
(中国计量学院 信息工程学院,浙江 杭州 310018)
针对基因表达数据高维和小样本的特点,介绍一种基于主成分分析的决策树集成分类算法——旋转森林.首先通过对数据属性集的随机分割,再对子集进行主成分分析变换,保留全部的主成分系数,重新组成一个稀疏矩阵.然后对变换后的数据利用非剪枝决策树集成算法进行分类.再结合ReliefF算法,选用3组基因表达数据验证算法,对比Bagging决策树和随机森林两种集成方法.结果表明旋转森林算法对基因数据具有更好的分类精度,同时验证旋转森林在较低的集成数的情况下,可以取得良好的效果.
主成分分析;旋转森林;集成学习;ReliefF算法;决策树
在生物医学领域,基因芯片技术可以检测大规模的基因表达数据,可以实现基因检测的快速、高通量、敏感和高效率检测,将可能为临床疾病诊断和健康监测等领域,提供一种高通量和系统性的研究手段.因表达数据具有分布不平衡、样本小、维数高的特点,应该如何对基因表达数据进行分析,是当前机器学习和数据挖掘领域内的一个研究热点.目前已经有很多比较成熟的单分类器,比如贝叶斯、决策树、神经网络、支持向量机以及极限学习机等,但是有些单分类器由于存在随机赋值而具有分类不稳定的缺点,例如神经网络和极限学习机.同时集成学习在应对非平衡数据方面也表现良好.随着机器学习的发展,集成学习算法因为具有较高的稳定性和较强的泛化性能已经成为机器学习领域一个非常重要的研究方向.
Kearns和Valiant提出关于“弱可学习和强可学习等价性”的问题[1].意味着只要性能略好于“随机猜测”的弱分类器经过一定的手段可以实现强分类器.实现弱分类器代替强分类器的途径是集成学习[2],集成学习可以显著提高学习器的精度和泛化能力.集成分类器的预测误差是由两方面决定的,一方面是基分类器的强度(正相关),另一方面是分类器之间的相关度(反相关).分类器的差异性[3]是影响集成学习的重要因素,当基分类器的误差不关联时,集成学习器才可以达到更良好的效果.
Bagging和Boosting是两种知名的集成方法[4],由于其具有良好的理论支持和实验表现而受到关注.对于Bagging方法,训练集被随机混合,按照一定的比例有放回地抽样T次,产生T个样本集.最终的分类器是由这些样本训练出来的分类器的线性组合.Bagging方法的误分类概率与单独的自助法(Boostrap)重复实验相当,但是比Booststrap更稳定.Bootstrap方法可以提高小样本情况下的总体均值区间估计的精度.另一方面,boosting(提升)方法根据基分类器的精度自适应地改变训练集的分布权重,在迭代时更关注于被分错的样本,Boosting方法存在着多种优良的变体,其中的AdaBoost(Adaptive Boosting)算法[5]是最著名的一种,可以解决从二分类到多分类的问题.
本文介绍的旋转森林算法[6](Rotation Forest,RoF)是一种利用决策树作为基分类器的集成分类算法,对样本的属性集进行随机分割,利用某种变换手段,例如主成分分析(principal components analysis,PCA),对属性子集进行变换,以增加各子集之间的差异性.再利用变换后的属性子集来选择样本训练不同的分类器.通过与Bagging决策树以及随机森林RF方法相比较,验证了此方法良好的分类性能.
1 主成分分析理论
主成分分析[7]PCA是一种展现事物主要矛盾的统计分析方法,可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题.PCA理论用几个较少的综合指标来代替原来较多的指标,而这些较少的综合指标既能尽多地反映原来较多指标的有用信息,且相互之间又是无关的,也可以实现经过降维去除噪声.
PCA的思想是将原始的n维特征空间映射到k维上,k的大小按实际需求选定,通常k≤n.这k维特征是经过变换后的正交特征,被称为主元.主成分分析运算是一种确定一个坐标系统的正交变换,在新的坐标系统下,变换数据样本的方差在沿新的坐标轴方向上取得最大化,使得数据投影的方差依次按照从大到小排列.这种变换在无损或很少损失了数据集的信息的情况下降低数据集的维数.
PCA的基本原理如下:对于输入数据矩阵Xm×n(通常满足m>n),由一系列中心化的样本数据构成,其中xi∈Rn且满足

(1)
令U是一个n阶的正交矩阵,第i列Ui是样本的协方差矩阵的第i个特征向量.对输入数据样本xi通过变换成为一个新的向量:si=UTxi.主成分分析的主要步骤如下:
1)将所获得的n个指标(每一指标有m个样品)的一批数据写成一个(m×n)维数据矩阵A

(2)
并对A进行标准化处理,生成X.
2)计算X的协方差矩阵,得出一个n阶的矩阵S,计算出S的特征向量e1,e2,…,en,以及对应的特征值λi,I=1,2,…,N,并把特征值按大到小排序.
3)根据需要保留前k个较大的特征值,在本算法中,为了分类精度,保留全部的特征值.
4)计算已标准化的样本数据X在提取出的特征向量上的投影Y=X·Z.所得的Y即为进行特征变换后的数据.
5)对于n维的数据矩阵,经过主成分分析后会产生n个主成分.主成分是原变量的线性组合,既不会增加总信息量,也不减少总信息量.对于旋转森林算法,主成分分析本身并不是目的,而是一种手段[8].通过变换,可以使得训练得到的各基分类器的差异性增强.
2 旋转森林算法
旋转森林是一种运用线性分析理论和决策树分类算法,既可以用于分类也可以用于回归[9].旋转森林通过对坐标轴变换建立同种集成分类器.因此,基分类器必须对特征轴旋转敏感[10],决策树是一个通常的选择.旋转森林旨在建立一个精确的并且差异性强的集成分类器.旋转森林借助特征提取得到特征子空间,通过主成分分析变换后再重组为一个完整的属性集.
其算法描述如下:
令x=[x1,x2,…,xn]T为一个具有n个属性的样本点,X为一个包含N个训练样本的训练集,构成N×n的矩阵,同时令向量Y=[y1,y2,…,yN]是训练集X对应的类标,并且yi属于类标集合{w1,w2,…,wc}.D1,D2,…,DL为所选择的L个基分类器,F为完整的属性集.
为了训练各分类器,需要先选择好L的值,即存在D1,D2,…,DL为基分类器.与Bagging决策树、随机森林类似,各分类器也可以并行训练.具体的构建步骤如下:
1)随机将属性集F划分成K个不相交的子集,每个子集将包含M=n/K个属性.子集之间相互独立,以增加属性子集的差异性.对同一数据集,K的取值与分类器的精度并不存在单调对应关系,其精度也会随着训练数据集的不同而有所变化.但是实验发现,当K=1或者n,所得到的效果最差,其他取值时差别不大[10].主要原因是,构造稀疏矩阵是增强各分类器准确性的先决条件,K=1时没有对属性集进行分割,也无法形成稀疏矩阵;当K=n(n是特征数)时,经过变换和重组后,所有的基分类器都是一样的,因此相当于只得到了一个分类器,而非集成分类器.
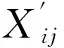
3)对每一个特征子集都进行步骤(2)的操作,将得到的所有的主成分系数存入一个系数矩阵Ri
(3)
Ri形成一个稀疏矩阵,其行数为n,列数为各子属性集变换后的列数之和∑jMj.

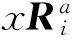
(4)
x=argmax(uw(x)),w∈C.
(5)
3 实验与分析
本实验所用的数据集有三个,分别为Leukemia(白血病)、Diabetes(糖尿病)和Heart Disease(心脏病)数据集.因为基因表达数据具有维度特别高的特点,直接用于分类存在着运算量大的问题,故首先运用ReliefF算法[11]先对实验数据进行处理,以降低复杂度.ReliefF算法是一种特征权重算法.根据各个特征和类别的相关性赋予特征不同的权重,权重小于某个阈值的特征将被移除.ReliefF算法中特征和类别的相关性是基于特征对近距离样本的区分能力.见表1.
表1 试验用数据集
其中Diabetes和Heart是二分类数据集,Leukemia是多分类数据集,各数据集均无缺失.参照用的分类算法为Bagging决策树(Bagging Tree)和随机森林算法[12](Random Forest).为了对比突出,基分类器均采用C4.5决策树算法,并且各实验结果均做了10次十折交叉验证,以保证实验结果的稳定性和准确性.
本实验将从精度和集成度两个方面体现旋转森林算法的优点.首先固定一个集成度,对每一组数据集,均采用三种不同的算法进行测试,得出结果进行对比;其次,再对每一组数据,均施以3种不同的算法,变动集成度,显示在不同集成度下,各算法的表现.

表2 不同分类器的分类精度和方差
表2是三组数据在不同的算法下所得到的分类精度以及方差.每种算法均在基分类器个数为10下进行试验.可以得到,每组数据的分类精度均在旋转森林时取得最佳.除第二组数据外,RF算法也是较好的结果.但是从方差分析,Bagging决策树的方差总是最小的,这也体现Bagging决策树是一种相对较稳定的算法.
图3是对每组的数据施以三种不同的算法进行分类测试.可以得出,随着集成数目的增加,旋转森林算法明显优于另外两种算法,随机森林其次,而Bagging决策树接近随机森林算法;同时也可以得出,随着集成度的上升,旋转森林算法很快
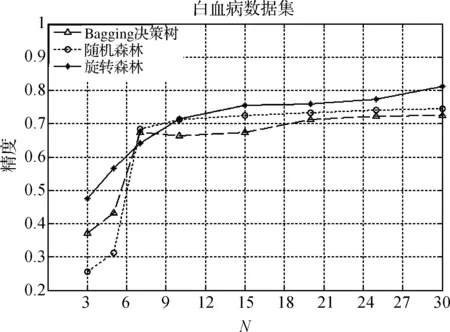
图1 Leukemia数据集在不同算法下的分类结果Figure 1 Classification result of Leukemia based on bifferent algorithms

图2 Heart数据集在不同算法下的分类结果Figure 2 Classification result of Heart based on different algorithms
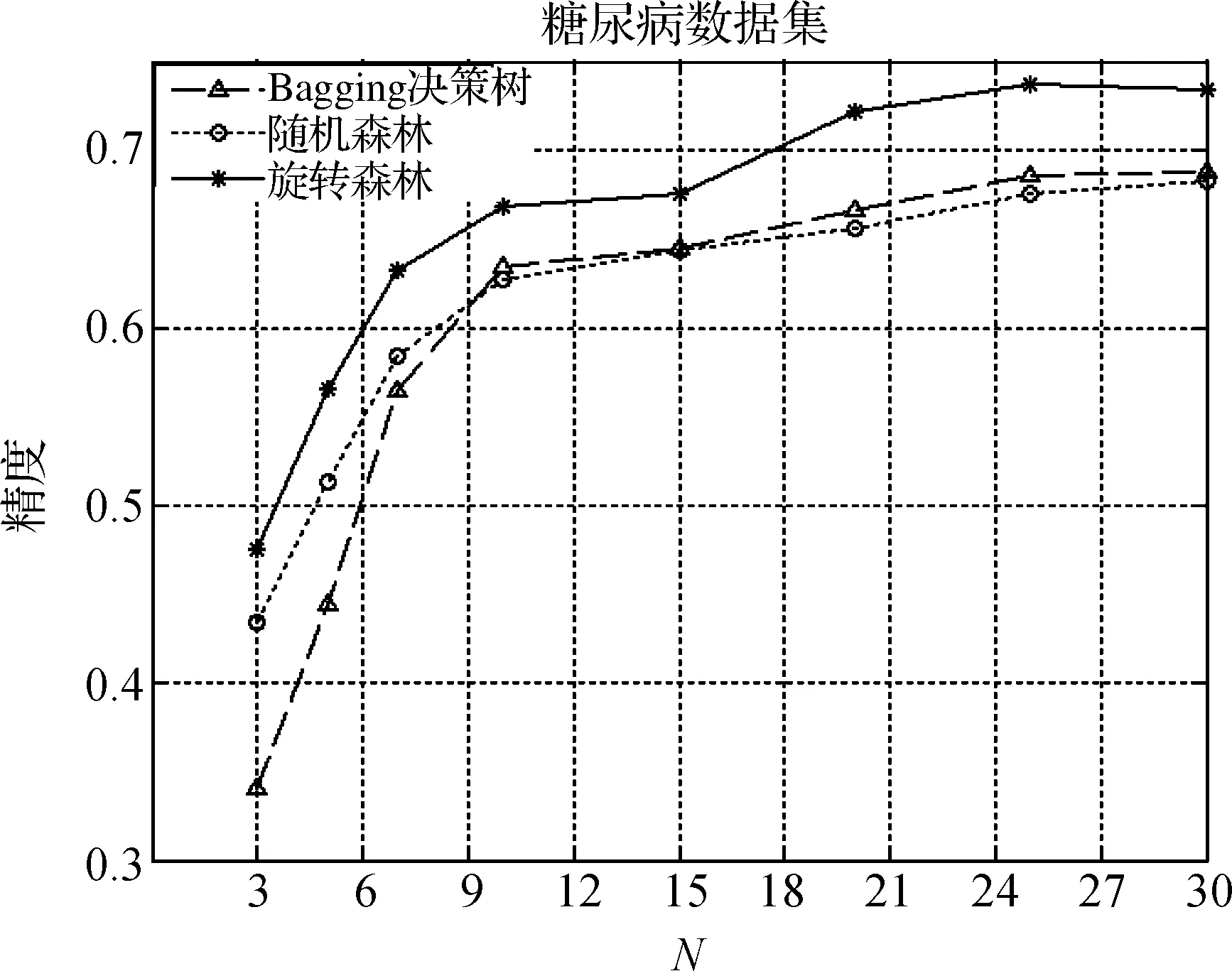
图3 Diabetes数据集在不同算法下的分类结果Figure 3 Classification result of Diabetes based on different algorithms
就可以达到不错的结果,在基分类器个数为10时,就相当于另外两种算法基分类器个数为30的效果.从图中可得出,Bagging决策树平稳的上升,之后几乎不变.
相比其他集成算法,旋转森林算法的核心在于运用主成分分析的特征子空间进行变换,再重组成完整的特征空间.依靠稀疏矩阵,在没有降低基分类器精度的同时,尽可能的差异化.旋转森林方法之所以在基因表达数据方面取得较好的表现,是因为本算法在基分类器的精度和差异性两方面做了很好的折衷.
4 结 语
旋转森林的基本思想是实现从输入空间到属性空间的映射,在变换过程中保持原有的维度而不降维,但是产生一个坐标轴旋转(axes rotation).本试验运用主成分分析对特征子空间进行变换,以决策树为基分类器,今后将从两个方面继续开展相关研究:
1)研究其它变换手段对旋转森林分类的影响.例如独立分量分析(independent component analysis,ICA)算法,线性判别式分析(linear discriminant analysis,LDA)算法等;以及运用非线性变化方法,例如将核主成分分析方法(kernel based principal component analysis,KPCA)[13]引入旋转森林算法,并且研究KPCA方法的适应性问题.
2)将研究对其它分类器[14]的集成效果,例如极限学习机(extreme learning machine,ELM),支持向量机(support vector machine,SVM)等,试图提高原算法的分类精度,以及增强其泛化能力.
[1] SCHAPIRE R E. The strength of weak learnability[J].Machine Learning,1990,5(2):197-227.
[2] ROBI P.Ensemble machine learning[M].USA: Springer,2012:1-34.
[3] 李凯,崔丽娟.集成学习算法的差异性及性能比较[J].计算机工程,2008,34(6):35-37.
LI Kai, CUI Lijuan. Diversity and performance comparison for ensemble learning algorithms[J].Computer Enginee-ring,2008,34(6):35-37.
[4] SOTIRIS B K. Bagging and boosting variants for handing classifications probelms:a survey[J].The Knowledge Engineering Review,2013,29(1):78-100.
[5] 曹莹,苗启广,刘家辰,等.AdaBoost算法研究进展与展望[J].自动化学报,2013,39(6):745-753. CAO Ying, MIAO Qiguang, LIU Jiachen, et al. Advance and prospects of adaBoost algorithm[J].Acta Automatica Sinica,2013,39(6):745-753.
[6] RODRIGUEZ J J, KUNCHEVA L I, ALONSO C J.Rotation forest: A new classifier ensemble method[J].IEEE Tranactions on Pattern Analysis and Machine Intelligence,2006,28(10):1619-1630.
[7] AKAMA Y. Realizability interpretation of PA by iterated limiting PCA[J].Mathematical Structures in Computer Science,2014,24(6):35-48.
[8] 刘敏,谢秋生.一种基于旋转森林的集成协同训练算法[J].计算机工程与应用,2011,47(30):172-175. LIU Min, XIE Qiusheng. Ensemble co-training algorithm based on ration forest[J].Computer Engineering and Applications,2011,47(30):172-175.
[9] CARLOS P. Rotation forests for regression[J].Applied Mathematics and Computation,2013,219(19):9914-9924.
[10] KUNCHEVA L I, RODRIGUEZ J J. An experimental study on rotation forest ensembles[G].Lecture Notes in Computer Science,2007:459-468.
[11] ROBNIK-SIKONJA M, KONONENKO I. Theoretical and empirical analysis of reliefF and rreliefF[J].Machine Learning,2003,53(1):23-69.
[12] ZHANG L, SUGANTHAN P N. Random forest with ensemble of feature spaces[J].Pattern Recognition,2014,47(10):3429-3437.
[13] SHAH J H, SHARIF M. A survey: linear and nonlinear pca based face recognition techniques[J].International Arab Journal of Information Technology,2013,10(6):536-545.
[14] 韩敏,刘贲.一种改进的旋转森林算法[J].电子与信息学报,2013,35(12):2896-2900. HAN Min, LIU Ben. An improved rotation forest classification algorithm[J].Journal of Electronisc & Information Technology,2013,35(12):2896-2900.
Study on classifier algorithm of genetic data based on rotation forest
LIU Yaqing, LU Huijuan, DU Bangjun, YU Cui
(College of Information Engineering, China Jiliang University, Hangzhou 310018, China)
Aiming at the character of high dimensions and small samples of gene expression data, an ensemble classification algorithm by the name of rotation forest based on decision tree was introduced. By splitting the feature set of data, applying the principal component analysis (PCA) on them and then reserving all the coefficients of the principal components, a sparse matrix was rebuilt up.Finally the unpruned decision tree ensemble algorithm was used to classify the transformed data set. Here, combined with the ReliefF algorithm,three groups of gene expression data were choosen to test the rotation forest algorithm, compared with two other ensemble methods: Bagging tree and random forest. The result indicates that the rotation forest has a higher classification accuracy and can get an excellent performance with a low ensemble size all the same.
principal components analysis; rotation forest; ensemble learning; reliefF; decision tree

1004-1540(2015)02-0227-05
10.3969/j.issn.1004-1540.2015.02.019
2015-02-06 《中国计量学院学报》网址:zgjl.cbpt.cnki.net
国家自然科学基金资助项目(No.61272315),浙江省自然科学基金资助项目(No.Y1110342).

TP391
A
